







Dataset之IRIS:鸢尾花(Iris)数据集的简介、下载、使用方法之详细攻略
目录
莺尾花(Iris)数据集的简介
Iris数据集,也称鸢尾花数据集,是一类多重变量分析的数据集,于1988年公开,用于分类任务。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
数据集包含 3 个类别,每个类别 50 个实例,其中每个类别指的是一种鸢尾植物。一类与另一类线性可分;后者不能彼此线性分离。
| 英文 | 中文 | 备注 |
| sepal length | 萼片长度 | |
| sepal width | 萼片宽度 | |
| petal length | 花瓣长度 | |
| petal width | 花瓣宽度 | |
| class | 类别 | Iris Setosa、Iris Versicolour、 Iris Virginica |
feature_names = ['sepal length','sepal width','petal length','petal width']官网:UCI Machine Learning Repository: Iris Data Set
1、莺尾花(Iris)数据集可视化
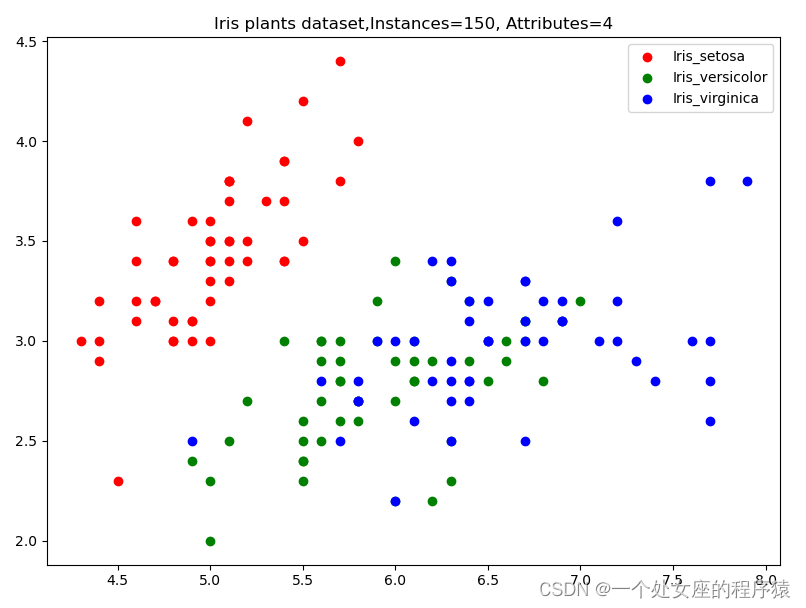
from sklearn import datasets
iris_data = datasets.load_iris()
print(iris_data.DESCR)
X_arr = iris_data.data
y_arr = iris_data.target
def iris_data_plot(X_arr, y_arr):
import matplotlib.pyplot as plt
plt.figure()
setosa_data = X_arr[y_arr == 0]
plt.scatter(setosa_data[:, 0], setosa_data[:, 1], color="r", label="Iris_setosa")
versicolor_data = X_arr[y_arr == 1]
plt.scatter(versicolor_data[:, 0], versicolor_data[:, 1], color="g", label="Iris_versicolor")
virginica_data = X_arr[y_arr == 2]
plt.scatter(virginica_data[:, 0], virginica_data[:, 1], color="b", label="Iris_virginica")
plt.legend()
plt.title('Iris plants dataset,Instances=150, Attributes=4')
plt.show()
iris_data_plot(X_arr, y_arr)莺尾花(Iris)数据集的下载
下载链接:UCI Machine Learning Repository: Iris Data Set
莺尾花(Iris)数据集的使用方法
相关文章
MAT之GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花(iris数据集)种类识别正确率、各个模型运行时间对比
MAT之ELM:ELM实现鸢尾花(iris数据集)种类测试集预测识别正确率(better)结果对比
ML之SVM:基于SVM(sklearn+subplot)的鸢尾花iris数据集的前两个特征(线性不可分的两个样本),判定鸢尾花是哪一种类型
ML之SVM:基于SVM(sklearn+subplot)的鸢尾花iris数据集的前两个特征(线性不可分的两个样本),判定鸢尾花是哪一种类型



















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











