







UniGoal的提出了一个通用的零样本目标导航框架,能够统一处理多种类型的导航任务。
支持 对象类别导航、实例图像目标导航和文本目标导航,而无需针对特定任务进行训练或微调。
本文分享UniGoal复现和模型推理的过程~
查找沙发,模型会根据输入的实例图片进行匹配的

目录
3.3 安装Grounded-Segment-Anything依赖
1、创建Conda环境
首先创建一个Conda环境,名字为unigoal,python版本为3.8
进行unigoal环境
conda create -n unigoal python=3.8
conda activate unigoal然后下载unigoal代码,并解压:https://github.com/bagh2178/UniGoal
2、 安装habitat仿真环境
执行下面命令进行安装
cd UniGoal
conda install habitat-sim==0.2.3 -c conda-forge -c aihabitat
pip install -e third_party/habitat-lab安装过程的打印信息:
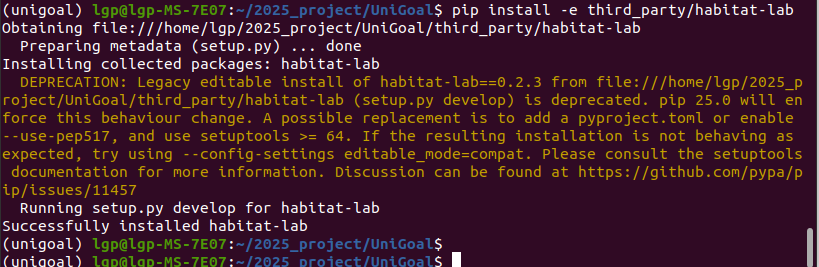
安装成功啦~
3、安装第三方的依赖库
3.1 安装LightGlue依赖
pip install git+https://github.com/cvg/LightGlue.git正常安装打印的信息:
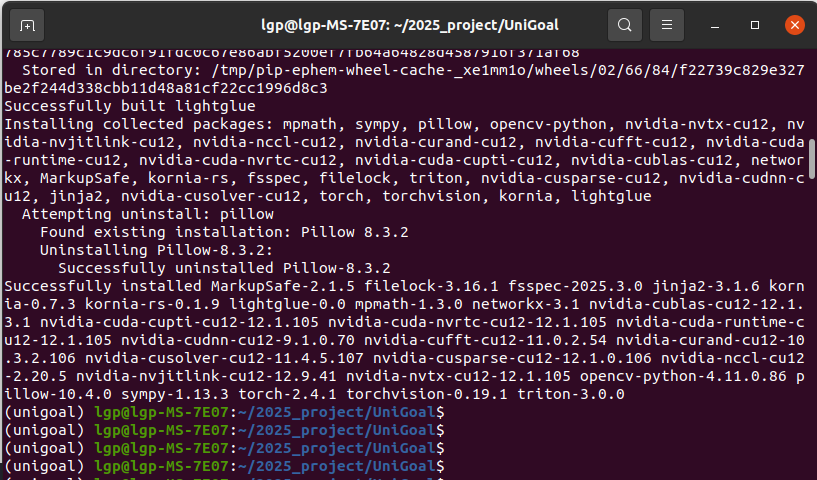
3.2 安装detectron2依赖
需要cuda>=12.1的,用nvcc --version查询
(unigoal) lgp@lgp-MS-7E07:~/2025_project/UniGoal$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
如果是cuda11.x或更底版本的,需要安装或切换为cuda>=12.1的
将以下内容添加到 ~/.bashrc
# 设置 CUDA 12.1 为默认版本
export CUDA_HOME=/usr/local/cuda-12.1
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH然后执行:
source ~/.bashrc再安装detectron2:
pip install git+https://github.com/facebookresearch/detectron2.git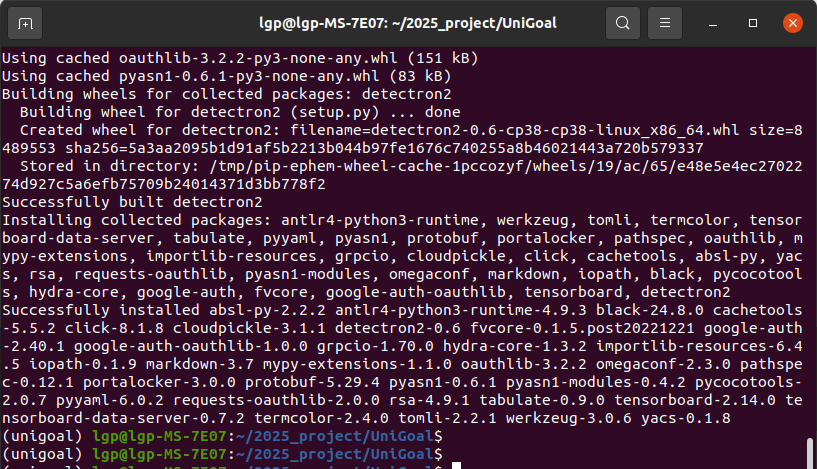
3.3 安装Grounded-Segment-Anything依赖
执行命令进行安装,等待安装完成~
git clone https://github.com/IDEA-Research/Grounded-Segment-Anything.git third_party/Grounded-Segment-Anything
cd third_party/Grounded-Segment-Anything
git checkout 5cb813f
pip install -e segment_anything
pip install --no-build-isolation -e GroundingDINO3.4 安装其他依赖库
先安装pytorch::faiss-gpu,等待安装完成~
conda install pytorch::faiss-gpu再安装安装其他依赖库
pip install -r requirements.txt2025/5/12 补丁安装:
pip install openai mkl faiss-gpu4、下载模型权重
分别下载sam_vit_h_4b8939.pth和groundingdino_swint_ogc.pth权重,放在data/models目录下
cd ../../
mkdir -p data/models
wget -O data/models/sam_vit_h_4b8939.pth https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
wget -O data/models/groundingdino_swint_ogc.pth https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
等待下载完成:

5、下载HM3D数据集
从这里下载 HM3D 场景数据集,从这里下载实例-图像-目标导航事件数据集。
数据集的结构概述如下:
UniGoal/
└── data/
├── datasets/
│ └── instance_imagenav/
│ └── hm3d/
│ └── v3/
│ └── val/
│ ├── content/
│ │ ├── 4ok3usBNeis.json.gz
│ │ ├── 5cdEh9F2hJL.json.gz
│ │ ├── ...
│ │ └── zt1RVoi7PcG.json.gz
│ └── val.json.gz
└── scene_datasets/
└── hm3d_v0.2/
└── val/
├── 00800-TEEsavR23oF/
│ ├── TEEsavR23oF.basis.glb
│ └── TEEsavR23oF.basis.navmesh
├── 00801-HaxA7YrQdEC/
├── ...
└── 00899-58NLZxWBSpk/
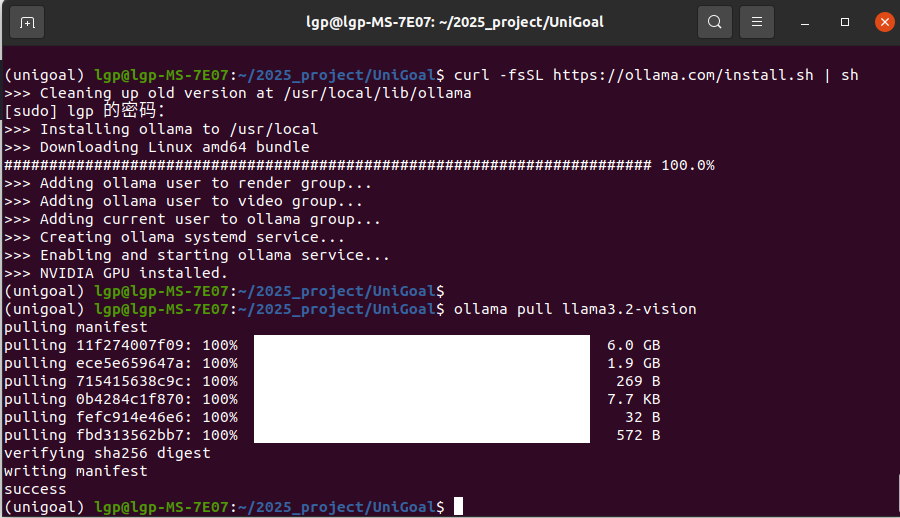
6、安装Ollama,配置LLM 和 VLM
分别执行下面命令:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull llama3.2-vision成功啦~
7、模型推理
运行main.py,就可以进行模型推理啦
python main.py 打印信息:
[22:03:27:032178]:[Assets] ResourceManager.cpp(2210)::loadMaterials : Idx 26:Flat.
[22:03:27:032183]:[Assets] ResourceManager.cpp(2210)::loadMaterials : Idx 27:Flat.
[22:03:27:062166]:[Sim] Simulator.cpp(442)::instanceStageForSceneAttributes : Successfully loaded stage named : data/scene_datasets/hm3d_v0.2/val/00877-4ok3usBNeis/4ok3usBNeis.basis.glb
[22:03:27:062184]:[Sim] Simulator.cpp(474)::instanceStageForSceneAttributes :
---
The active scene does not contain semantic annotations : activeSemanticSceneID_ = 0
---
[22:03:27:062207]:[Sim] Simulator.cpp(208)::reconfigure : CreateSceneInstance success == true for active scene name : data/scene_datasets/hm3d_v0.2/val/00877-4ok3usBNeis/4ok3usBNeis.basis.glb with renderer.
[22:03:27:067606]:[Nav] PathFinder.cpp(568)::build : Building navmesh with 222 x 162 cells
[22:03:27:121110]:[Nav] PathFinder.cpp(842)::build : Created navmesh with 340 vertices 163 polygons
[22:03:27:121130]:[Sim] Simulator.cpp(898)::recomputeNavMesh : reconstruct navmesh successful
2025-05-12 22:03:27,122 Initializing task InstanceImageNav-v1
[05/12 22:03:27 detectron2]: Arguments: Namespace(confidence_threshold=0.5, config_file='configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml', input=['input1.jpeg'], opts=['MODEL.WEIGHTS', 'detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl', 'MODEL.DEVICE', 'cuda:0'], output=None, video_input=None, webcam=False)
[05/12 22:03:27 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
[22:03:27:595720]:[Sensor] Sensor.cpp(69)::~Sensor : Deconstructing Sensor
Loading episodes from: data/datasets/instance_imagenav/hm3d/v3/val/content/4ok3usBNeis.json.gz
Changing scene: 0/data/scene_datasets/hm3d_v0.2/val/00877-4ok3usBNeis/4ok3usBNeis.basis.glb
rank:0, episode:1, cat_id:0, cat_name:chair看一下运行效果,查找椅子:
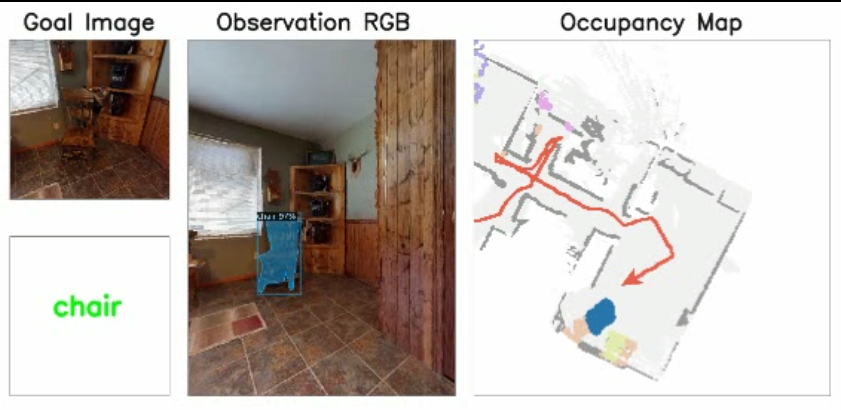
查找不同的椅子,模型会根据输入的实例图片进行匹配的
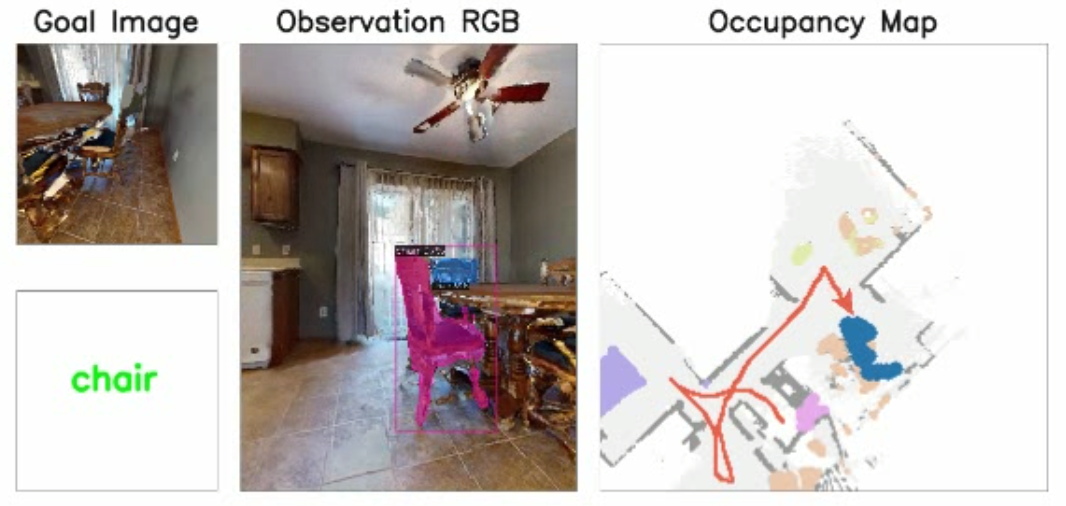
查找卫生间:

分享完成~
相关文章推荐:


















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











