







1 介绍
在本篇文章中,将介绍如何使用Transformer和LSTM模型进行时间序列预测。这两种模型分别擅长处理序列数据和捕捉时间序列中的长短期依赖关系。我们将结合这两种模型的优势,构建一个强大的预测模型。单输入单输出预测,适合风电预测,功率预测,负荷预测等等。
2 方法
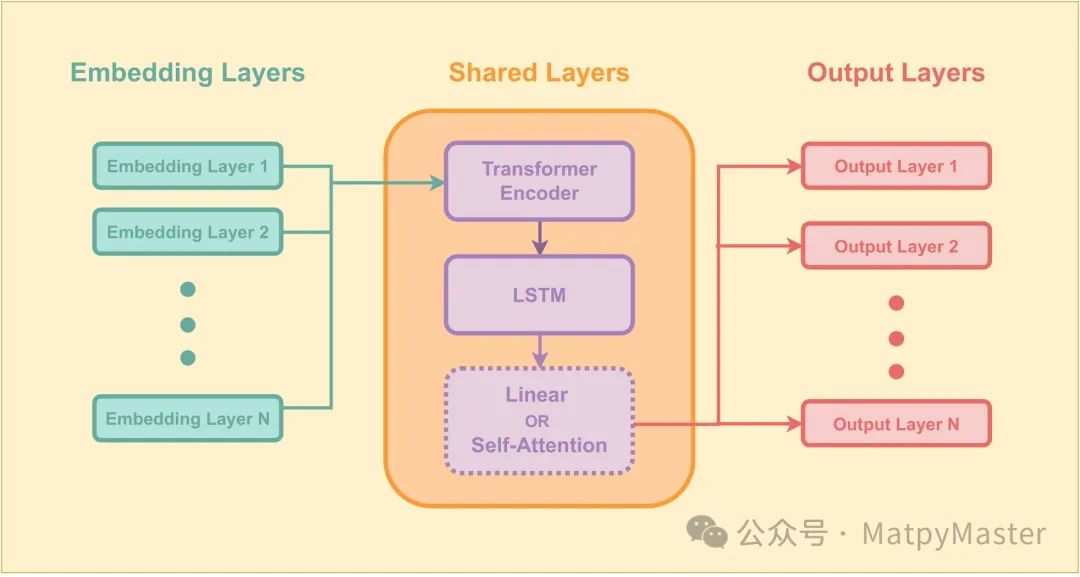
Transformer模型最初用于自然语言处理任务,但其强大的序列建模能力也适用于时间序列预测。在我们的模型中,我们使用了Transformer编码器来提取输入序列中的特征。Transformer的核心优势在于其自注意力机制,能够捕捉序列中不同位置之间的依赖关系。
由于Transformer本身不具备处理序列位置信息的能力,我们使用了位置编码来为每个输入数据点添加位置信息。这一过程涉及到对每个位置应用正弦和余弦函数,从而使模型能够区分序列中的不同位置。
长短期记忆(LSTM)网络是一种特殊类型的循环神经网络,能够有效地学习时间序列中的长期依赖关系。在我们的模型中,LSTM解码器负责根据Transformer编码器提取的特征进行预测。LSTM能够处理输入序列中的短期依赖,并通过注意力机制进一步增强对重要信息的关注。
3 结果
模型训练过程包括前向传播和反向传播。首先,输入序列通过Transformer编码器提取特征,然后传递给LSTM解码器进行预测。在训练过程中,我们使用均方误差(MSE)作为损失
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











