








1 数据集介绍
ETT(电变压器温度):由两个小时级数据集(ETTh)和两个 15 分钟级数据集(ETTm)组成。它们中的每一个都包含 2016 年 7 月至 2018 年 7 月的七种石油和电力变压器的负载特征。
traffic(交通) :描述了道路占用率。它包含 2015 年至 2016 年旧金山高速公路传感器记录的每小时数据
electrity(电力):从 2012 年到 2014 年收集了 321 个客户每小时电力消耗。
exchange_rate(汇率):收集了 1990 年至 2016 年 8 个国家的每日汇率。
Weather:包括 21 个天气指标,例如空气温度和湿度。它的数据在 2020 年的每 10 分钟记录一次。
ILLNESS:描述了患有流感疾病的患者与患者数量的比率。它包括 2002 年至 2021 年美国疾病控制和预防中心每周数据。
数据集链接:
https://drive.google.com/drive/folders/1ZOYpTUa82_jCcxIdTmyr0LXQfvaM9vIy
参考文献:
[1]https://browse.arxiv.org/pdf/2303.15446.pdf
[2]https://arxiv.org/pdf/2310.06625
2 处理方法
(1)方法
EAA(Efficient Additive Attention)有效附加注意力机制是视觉领域提出的一个注意力机制,lstm结合EAA进行特征提取,将提取的放入transformer进行预测。
·LSTM
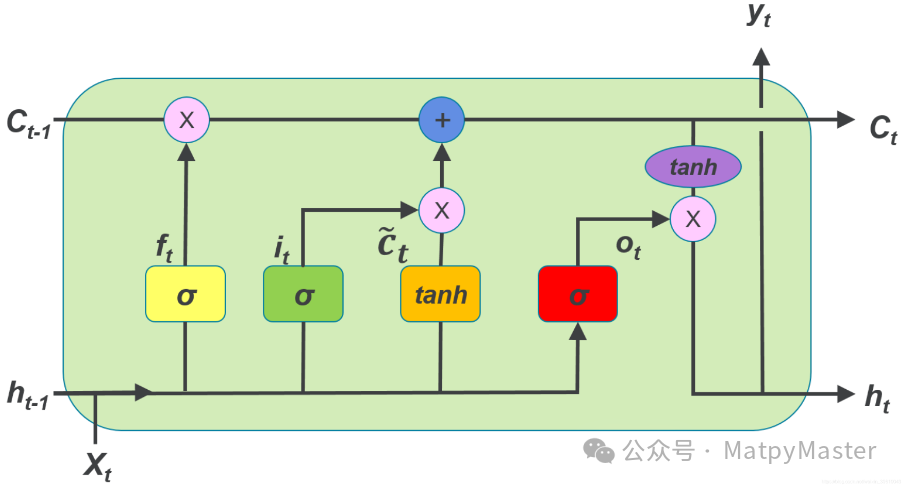
LSTM通过引入“门”结构和“细胞状态”来解决这个问题。门结构可以控制信息的流入和流出,细胞状态则可以长期存储状态。这使得LSTM能够在长序列中更好地捕捉依赖关系。LSTM的主要优点是能够有效地处理长序列数据。在传统的RNN中,由于梯度消失的问题,网络往往难以捕捉序列中的长期依赖关系。而LSTM通过引入门控机制和细胞状态,能够在较长的时间跨度上保持信息,从而捕捉到长期依赖关系。
·EAAtention
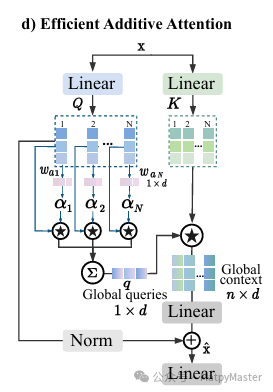
在自然语言处理(NLP)领域,传统的加性注意力机制通过元素乘法而非点积来捕捉令牌间的成对交互,以获取全局上下文信息。这种机制依赖于三个关键的注意力分量——查询(Q)、键(K)和值(V)——来编码输入序列中上下文信息的相关性得分。EAA方法在不损失性能的前提下,省略了键值交互。如图展示了通过仅合并线性投影层来有效地编码查询和键的交互,就足以学习令牌之间的关系。这种方法被称为有效的附加注意力,它不仅提高了推理速度,而且生成了更强大、更丰富的上下文表示。
(2)实验结果
训练集、验证集和测试集划分设置为6:2:2,实验参数设置如下:
parser = argparse.ArgumentParser(description='EAA')
parser.add_argument('--look_back', type=int, default='10', help='历史look_back步,修改这里也要修改model的look_back')
parser.add_argument('--T', type=int, default='1', help='预测未来的T步,修改这里也要修改model的T')
parser.add_argument('--epochs', type=int, default='300', help='训练轮数')
parser.add_argument('--batch_size', type=int, default='32', help='批大小')
parser.add_argument('--data_path', type=str, default='mydata/ETTm1.csv', help='文件路径')
parser.add_argument('--freq', type=str, default='15min', help='时间特征编码')
# freq选项:[s:秒,t:分钟,h:小时,d:每天,b:工作日,w:每周,m:每月],也可以使用更详细的频率,如'15min'或'3h'
parser.add_argument('--num_features', type=int, default='6', help='数据一共多少个特征')
parser.add_argument('--target', type=str, default='OT', help='预测的目标变量')
parser.add_argument('--embed_dim', type=int, default='32', help='嵌入维度')
parser.add_argument('--dense_dim', type=int, default='128', help='隐藏层神经元个数')
parser.add_argument('--num_heads', type=int, default='4', help='头数')
parser.add_argument('--dropout_rate', type=float, default='0.1', help='失活率')
parser.add_argument('--num_blocks', type=int, default='2', help='编码器解码器数')
parser.add_argument('--learn_rate', type=float, default='0.001', help='学习率')
args = parser.parse_args()注:需根据数据集的特征进一步探索最合适的参数组合,以提升模型性能。
本文方法ETTm1数据集:
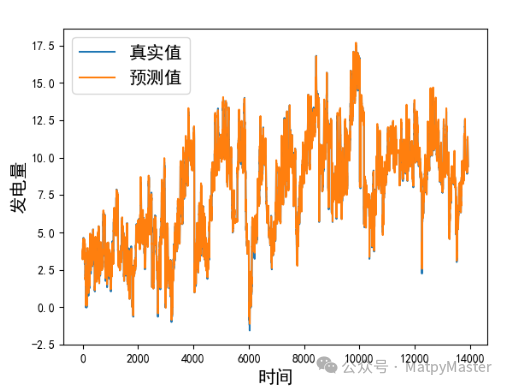

本文方法ETTh1数据集:
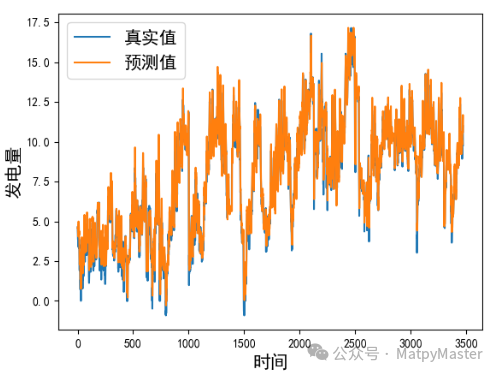
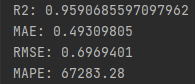
代码下载: LSTM-EAAtention-Transfomer——基于有效附加注意力的时间序列预测 (qq.com)
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!

















 4207
4207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











