









GraphRAG = 知识图谱 + RAG,优化全局搜索+局部搜索,以及部署指南
论文:From Local to Global: A Graph RAG Approach to Query-Focused Summarization
代码:https://github.com/microsoft/graphrag
提出背景
传统的RAG方法适用于局部文本检索任务,但不适用于全局性的查询聚焦摘要任务。
传统的RAG方法局部文本检索:
医生需要了解某个药物在治疗某种疾病时的具体副作用。使用RAG方法,系统会从数据库中检索相关的文档片段,然后生成一个包含这些副作用的回答。
这种方法非常有效,因为问题是具体的,答案可以从局部的文档片段中提取。
全局性的查询聚焦摘要任务:
医院希望对某种疾病的治疗效果进行全面评估,包括各种治疗方法的效果、副作用、患者满意度等信息。
这个任务需要从大量的文档中提取相关的信息,并对其进行整合和总结。
GraphRAG 是一种复杂的信息检索和生成方法,使用知识图谱和大型语言模型(LLM)来处理复杂查询。
GraphRAG的两个主要阶段:
-
构建图索引:
- 实体知识图谱:从源文档中提取重要的元素,如人物、地点、事件等,这些被称为“实体”。这些实体通过它们之间的关系(例如,“工作于”或“位于”)连接起来,形成一个网络或图。
- 图的其他元素:除了实体和关系,图还包括附加信息,如“声明”(即关于实体的陈述或属性),这有助于更好地理解和分类实体。
-
预生成社区摘要:
- 社区检测:使用算法(如Leiden算法)分析图,找出紧密相关的实体群体。这些群体被称为“社区”,在这里,社区意味着一组相互紧密联系的实体和信息。
- 生成社区摘要:每个社区的信息被提取并总结,这一步骤是自动完成的,利用大型语言模型来生成每个社区的摘要或概述。
查询处理:
- 当提出一个查询(即一个问题或信息需求)时,系统不仅查找与这个查询直接相关的单个实体,而是在与查询相关的各个社区上运行,汇总所有相关社区的信息,生成一个全面的、针对该查询的“全局答案”。
GraphRAG 通过创建一个从文档中派生的、结构化的信息图,自动组织和总结这些信息,然后在需要时提供详尽的、上下文丰富的回答。
解法拆解
首先构建一个结构化的知识图谱,然后将其聚类成语义社区,并生成针对查询的总结,从而提供更全面和多样化的答案。
Graph RAG的核心思想是利用知识图谱作为上下文或事实信息源,以支持LLM进行更准确的信息提取和生成。
此外,Graph RAG还能够将实体和关系以图的形式展示。
通过实体提取、子图构造和上下文学习,能够有效地处理复杂的多跳问题,从而更好地理解和处理复杂的多跳问题,改进RAG系统效果与效率。
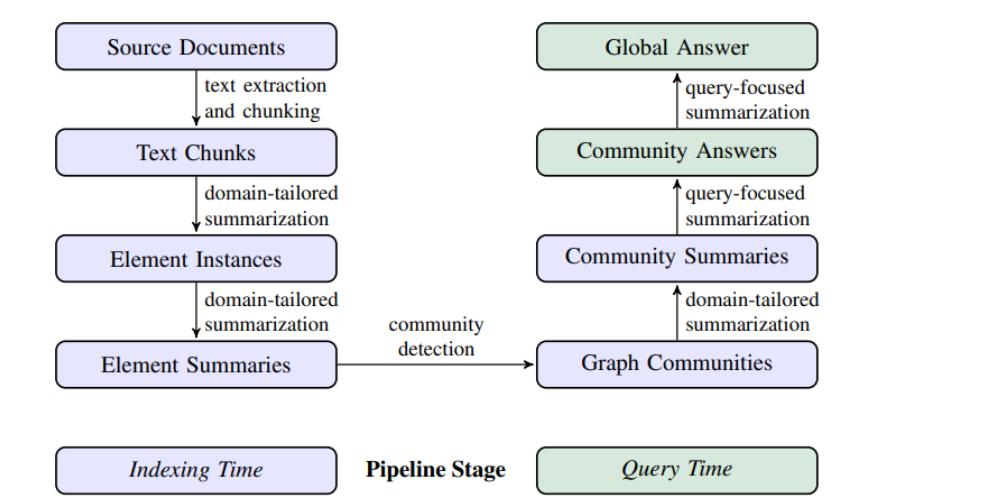
这幅图表概述了Graph RAG系统的工作流程:
-
源文档:
- 文档经过处理,提取文本并划分为易于管理的块。
-
文本块:
- 这些块经过针对领域的摘要处理,提炼出最相关的信息。
-
元素实例:
- 摘要后,识别出特定的元素,如实体、关系和协变量。
-
元素摘要:
- 这些元素再次进行领域定制的摘要。
-
社区检测:
- 检测到的元素基于它们的关系和相关性被聚类成图社区。
-
社区摘要:
- 对相关元素的每个社区进行摘要,提供简洁的概览。
-
社区答案:
- 这些摘要被用来回答专注于社区上下文的特定查询。
-
全局答案:
- 最终通过对社区答案进行摘要,产生一个全面的响应,提供对更广泛查询的综合回答。
医学应用场景:诊断罕见病症。
假设一个患者表现出一系列罕见且复杂的症状,医生需要对其进行详尽的诊断。
- 源文档:
- 医学数据库、病历档案、最新的医疗研究报告等文档被系统处理,从中提取关键文本,如症状描述、治疗历史、临床研究结果等。
- 文本块:
- 文本被划分为可管理的块,每块包含相关的医学信息,如具体症状、潜在诊断、治疗反应等。
- 元素实例:
- 从每个文本块中提取关键的医学实体(如特定症状、药物、疾病名称),以及实体之间的关系(如症状与疾病之间的联系)。
- 元素摘要:
- 对提取出的实体进行进一步的摘要处理,精炼信息以准备用于更高级的分析和推理。
- 社区检测:
- 通过算法检测实体间的关联性,将相关的症状、疾病、治疗方法等聚类成多个图社区,每个社区表示一组可能相互关联的医学概念。
- 社区摘要:
- 每个社区的实体和关系被总结,提供关于该社区主题的清晰概览,如一个社区可能聚焦于“自身免疫疾病”,而另一个可能聚焦于“遗传性疾病”。
- 社区答案:
- 针对特定的医学查询(例如,“这些症状可能指示哪种罕见病?”),系统利用相关社区的摘要生成详细的回答。
- 全局答案:
- 最后,系统整合各个社区答案的信息,生成一个全面的诊断报告,可能包括推荐的进一步检测、治疗方案及预后分析,为医生提供一份详细的临床决策支持文档。
通过这个流程,Graph RAG系统能够有效地从大量医学文本中提炼和总结关键信息,帮助医疗专业人员进行准确的诊断和治疗决策。
这种方法特别适用于那些涉及多系统症状或罕见疾病的复杂病例,需要综合广泛的医学知识和最新的研究数据。
目的: 支持对整个文本语料库的人类理解,用于医学研究和临床决策。
- 类比: 类似于医学图像诊断系统,Graph RAG旨在通过整合和解析大量的医学文本数据(如临床研究、病例报告等),来帮助医生和研究者迅速准确地把握疾病信息,提高诊断的准确性和研究的效率。
解法: 利用图形结构的数据索引、迭代和动态的检索生成循环以及多层次的社区摘要生成,来优化信息检索和生成文本摘要的过程。
子解法1:利用图索引的数据结构
- 特征: 自生成的图索引结构,有效组织数据。
- 类比: 如电子健康记录系统(EHR)中的患者信息索引,Graph RAG通过图索引结构系统地整合和分类大量医学数据,使得相关信息能够快速被检索和关联,提高信息检索的效率和准确性。
- 之所以使用图索引的数据结构,是因为图的模块化可以自然地组织复杂的医学数据,从而加快信息检索速度和提高信息关联度。
子解法2:迭代和动态的检索生成循环
- 特征: 模块化系统支持迭代循环,优化查询结果。
- 类比: 类似于医生对症状进行多轮诊断,每一轮诊断基于前一轮的检查结果深入探索,Graph RAG通过反复迭代生成和检索的循环,逐步优化和深化对查询问题的回答。
- 之所以使用迭代和动态的检索生成循环,是为了持续优化查询的相关性和信息的全面性,确保最终生成的摘要信息既全面又精确。
子解法3:多层次的社区摘要生成
- 特征: 基于社区的多层次摘要策略。
- 类比: 类似于医学综述文章,从概括性的疾病描述到具体的治疗案例详细讲述,Graph RAG通过从不同层次生成摘要,提供从广泛到具体的多维度信息视角。
- 之所以使用多层次的社区摘要生成,是因为不同层次的摘要可以满足从一般到特定的不同查询需求,提供不同深度的信息视角,帮助用户更好地理解复杂的医学问题。
这些子解法形成了一种链条的逻辑链,每个子解法都依赖于前一个解法的输出作为其输入,形成一个高效、层次分明的查询和分析流程,类似于医学诊断和研究中的步骤分解和逐级深入的方法。
Graph RAG 分析
问题1: 全局搜索与局部搜索的优化原理
全局搜索(Global Search)
-
目的:全局搜索是为了理解和回答关于整个文档集的综合性问题,如“数据中的前N个主题是什么?”这类需要跨文档聚合信息的查询。
-
优化原理:利用由大型语言模型(LLM)生成的社区报告,这些报告预先总结了数据集的语义结构。
映射-归约:通过先分解数据为小块进行独立处理(映射),然后将结果汇总以形成综合响应(归约),有效地组织和分析大量信息。
通过映射-归约(map-reduce)方式处理这些社区报告,先将它们分割为文本块(映射阶段),然后从这些块中选出重要点进行聚合(归约阶段),以形成对整体查询的响应。
这种方法优化了信息的聚合,使其能更有效地处理跨文档的复杂查询。
局部搜索(Local Search)
-
目的:局部搜索旨在理解和回答关于特定实体及其相关概念的详细问题。
-
优化原理:通过识别与查询语义相关的实体集,并将这些实体及其关联概念作为搜索的起点。
这种方法利用了知识图谱的结构化数据以及输入文档中的非结构化数据,为LLM在查询时提供更丰富的上下文。
这样的处理增强了对特定实体的理解和推理能力,优化了针对特定问题的搜索效率。
问题2: 实体识别、实体关系抽取、社区聚类的误差传播问题
实体识别、实体关系抽取与社区聚类的挑战
-
实体识别和实体关系抽取:这些步骤涉及从大量文本中自动识别出关键实体(如人名、地点等)以及它们之间的关系。
这个过程本质上依赖于语言模型的准确性,错误的实体识别或关系抽取会导致错误信息的累积,这种误差传播可能影响到最终生成的知识图谱的质量。
-
社区聚类:在构建图谱后,通过社区聚类来理解实体之间的关联和层次结构。
社区聚类的准确性直接影响到信息的结构化表示和后续的查询效率。
误差传播在这里指的是,如果前面的实体识别和关系抽取存在误差,那么这些误差会在社区聚类过程中被进一步放大,导致社区构建不准确。
解决方法:
- 提高实体识别和关系抽取的准确性是基本的解决方法,这通常需要更精细的模型训练和更好的训练数据。
- 在社区聚类阶段,可以引入更高级的算法和更多的人工审核,以减少自动化误差的影响。
我发现一个使用多智能发现和修订知识图谱错误的开源项目:
论文:BioKGBench: A Knowledge Graph Checking
Benchmark of AI Agent for Biomedical Science
代码:https://github.com/westlake-autolab/Agent4S-BioKG
总结
《从局部到全局:一种基于图的检索增强生成方法用于查询式摘要》论文:
- 召回方式选型:
- 主要采用了 子图检索增强生成方案, 从文章图1的处理流程可以看出, 通过社区检测算法(如莱顿算法)将知识图谱划分为不同的子图社区, 再基于子图生成摘要。
- 结合了探索链方案, 通过多级社区层次结构进行探索。
- 编排方式:
- 采用 重排与向量 - 文中提到使用社区检测和层次聚类进行重排
- 采用多级路由 - 通过不同层级的社区摘要进行路由
- 索引方式:
- 混合索引:同时使用了图索引(基于大模型方案生成知识图谱) 和 向量文本索引(用于检索相关文本块)
- 大语言模型方案: 利用大语言模型从源文档中抽取实体和关系, 构建知识图谱
- 检索查询:
- 检索器:采用语言模型检索器, 使用大模型进行查询理解和生成
- 检索方案:多阶段检索, 包括:
- 文本块 -> 元素实例
- 元素实例 -> 元素摘要
- 图社区 -> 社区摘要
- 社区摘要 -> 社区答案
- 检索颗粒度:子图级别, 通过社区检测识别相关子图
- 检索增强策略:使用映射-归约方式 聚合社区答案生成全局答案
- 增强生成:
- 图语言选择:采用了多种形式:
- 自然语言形式的社区摘要
- 结构化的图索引表示
- 层次化的社区层次结构表示
主要创新点:
- 提出了一个创新的图形检索增强生成框架, 能够处理全局性的查询问题
- 利用图的模块性特征进行社区检测, 实现高效的分布式处理
- 采用映射-归约方式聚合社区级别的答案, 提升了回答的全面性
- 在维持答案质量的同时大幅降低了令牌消耗
总的来说, 这是一个针对全局性查询问题的创新图形检索增强生成框架, 通过结合知识图谱的社区结构特征提升了系统性能。
GraphRAG 详细分析:代码流程、prompt 设计逻辑、源码分析
GraphRAG 详细分析:代码流程、prompt 设计逻辑、源码分析
内容太多,要单独写一篇,正在更新…
部署指南
#使用qwen灵积大模型平台运行graphrag
1、autodl上创建graph环境
conda init
bash
conda create -n graph python==3.10.14 -y
conda activate graph
2、安装graphrag
2.1 安装项目文件
pip install graphrag
2.2 创建工作目录
cd autodl-tmp
mkdir -p ./ragtest/input #ragtest是工作目录名,可以修改,修改后下面命令中工作目录都需要修改
把文档(txt格式或者csv格式)放入input目录中,注意文档编码为utf-8
2.3 配置文件初始化
python -m graphrag.index --init --root ./ragtest
#此命令会生成prompts文件夹,settings.yaml和.env 文件,settings文件为参数配置,.env文件为环境变量
2.4 修改配置文件
2.4.1修改settings.yaml文件,见项目中settings.yaml参数
主要修改项包括:
llm:
-model 修改为qwen 系列llm大模型,比如qwen-plus,qwen-turbo,qwen-max等等
-api_base 修改为qwen灵积平台地址:https://dashscope.aliyuncs.com/compatible-mode/v1
embeddings:
-model 修改为qwen 系列embedding模型,text-embedding-v2或者text-embedding-v1
-api_base 修改为qwen灵积平台地址:https://dashscope.aliyuncs.com/compatible-mode/v1
chunks:
size: 1200 #分割文本长度,如果需要更细的力度,可以改为500或者300,越小初始化消耗token越多
overlap: 100
2.4.2 修改.env环境变量
GRAPHRAG_API_KEY 修改为qwen大模型的api key
在 命令行 搜索 .env 文件
sudo find / -name ".env"
vi .env 修改自己的 qwen api
2.5 项目初始化
2.5.1 prompt调优,如果是专业领域,可以进行prompt调优(prompt tuning)
命令:
python -m graphrag.prompt_tune --root ./ragtest --config ./ragtest/settings.yaml --language English --domain "financial report" --no-entity-types --output ./prompt
主要参数:
-config 参数为setting.yaml目录
-language 语言chinese,English等
-domain 最重要的参数,领域名称,这里是inancial report金融报告
-output prompt输出目录
生成新的prompt文件后,覆盖prompts 目录下的文件
2.5.2 初始化
python -m graphrag.index --root ./ragtest
2.6 提问
2.6.1 global search
python -m graphrag.query --root ./ragtest --method global "What are the top themes in this story?"
双引号内为问题,主要用于全局搜索,对应文件为output目录下的社区报告,community report即create_final_community_reports.parquet
2.6.2 local search
python -m graphrag.query --root ./ragtest --method local "Who is Scrooge, and what are his main relationships?"
双引号内为问题,主要用于局部细节问题,会使用embedding模型进行文本相似性比较。
我跑了一下,19份PDF(45.9M),卡在最后一步。
Api 问题,承接不了这么大量的输入,得换本地部署 + 72B量化版。

















 1755
1755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









