









知识图谱 + 大模型知识整合:将知识图谱文本证据映射到大模型向量空间,解决N个同义词,增强深层语义理解和关联推理
论文:MEG: Medical Knowledge-Augmented Large Language Models for Question Answering
代码:https://github.com/lautel/MEG
理解
1、提出背景:
- 大类问题:在专业领域(如医学)中,大语言模型(LLM)难以准确理解概念之间的关系
2、MEG的性质:
- 使用轻量级映射网络将图谱嵌入(KGE)整合到LLM中,使其能够以低成本方式利用外部知识
3、对比:
- 正例:MEG在MedQA等测试集上比Mistral-Instruct基线提高了10.2%的准确率
- 反例:现有医学LLM如BioMistral虽然性能好,但需要在生物医学数据上进行昂贵的继续预训练
4、类比理解:
- MEG就像是给LLM配备了一个医学知识库的"翻译官"(映射网络),帮助LLM更好地理解和使用专业知识
5、主要创新:
- 首次提出通过轻量级映射网络注入预训练的知识图谱嵌入到LLM中
- 设计了两阶段训练策略,最小化模型参数更新
- 证明了在多个医学问答基准测试上的有效性
6、概念重组:
MEG(Medical Knowledge-Augmented LLM)是一个通过医学知识增强,来提升大语言模型在医疗领域问答能力的方法。
7、与上述其他系统相关性:
- 相比于其他需要大量预训练的方法,MEG提供了一种更轻量级的知识注入方案
- 保持了LLM的基础能力,同时增强了其在医疗领域的专业性
8、主要矛盾:
核心矛盾是如何在保持低计算成本的同时,提升LLM在专业医疗领域的表现。
9、功能分析:
MEG的核心功能是通过知识图谱增强来提升LLM在医疗问答中的表现,具体实现包括:
- 知识图谱编码器
- 指令调优的语言解码器
- 映射函数
- 知识图谱对齐模块
10、总结:
这是一篇探索如何高效地将结构化医学知识注入LLM的研究工作,通过设计轻量级架构和训练策略,在多个医学问答任务上取得了不错的效果。
MEG 的技术架构和工作原理
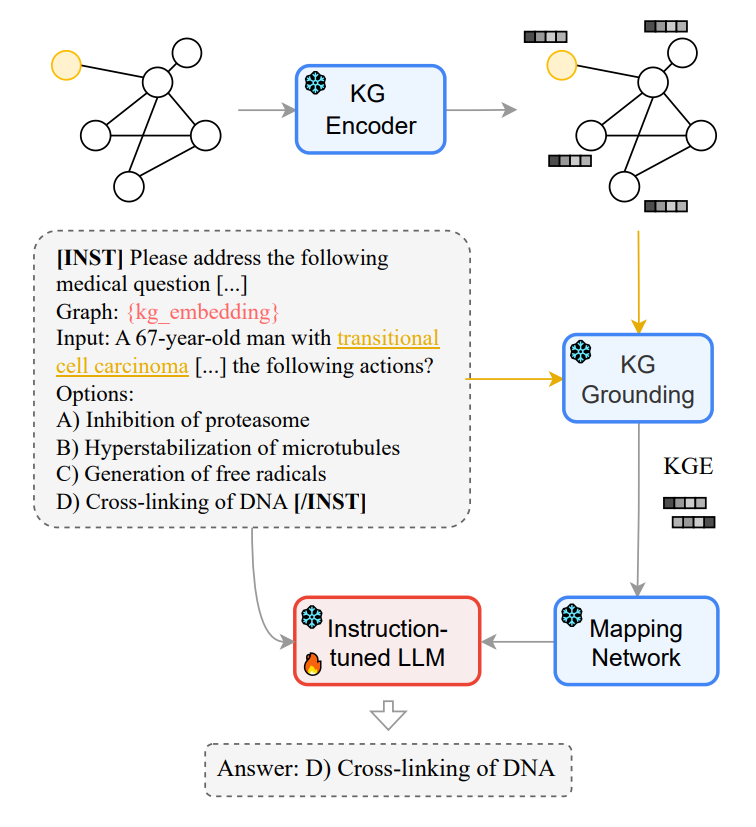
展示了MEG模型的整体架构和工作流程:
- KG Encoder: 将知识图谱编码成向量表示
- KG Grounding: 将文本实体与知识图谱中的实体对应
- Mapping Network: 将知识图谱的向量映射到语言模型可以使用的形式
- Instruction-tuned LLM: 基于指令微调的大语言模型,接收文本和映射后的知识图谱向量作为输入,生成答案
技术细节:
- 使用UMLS知识图谱(子表,约30万节点,100万边)
- 采用GraphSAGE作为图编码器
- 映射网络使用4层128维的MLP
核心组件:
- 知识图谱编码器 (KG Encoder)
- 使用 GraphSAGE 等图神经网络来处理医学知识图谱(UMLS)
- 将图中的实体和关系编码为向量表示(KG embeddings)
- 指令微调的语言模型 (Language Decoder)
- 基础模型是 Mistral-7B 或 Llama-3
- 能够生成自然语言答案
- 映射网络 (Mapping Network)
- 用 MLP(多层感知机)实现
- 将知识图谱的向量映射到语言模型的向量空间
- 保持语义信息的同时实现空间转换
- 知识对应模块 (Grounding Module)
- 检测文本中的医学实体
- 将实体链接到知识图谱中对应节点
训练流程:
- 第一阶段:嵌入迁移学习
- 学习最优的映射函数
- 使用对比学习和反向翻译损失
- 训练映射网络和语言模型
- 第二阶段:下游任务微调
- 冻结映射网络和词嵌入层
- 仅更新语言模型其他参数
- 针对具体医学问答任务优化
优势:
- 参数高效 - 只需训练少量参数
- 可扩展性好 - 易于整合新的医学知识
- 性能优异 - 在多个医学问答基准上超过现有模型
创新点:
- 首次通过轻量级映射网络整合知识图谱
- 设计了有效的两阶段训练策略
- 在保持模型轻量的同时提升了性能
假设输入问题是:
“一位患者出现持续性头痛,伴有恶心和对光敏感,最可能是什么疾病?”
选项:
A) 偏头痛
B) 普通感冒
C) 脑震荡
D) 颈椎病
MEG的处理流程:
- 知识对应(Grounding)阶段:
- 识别关键医学实体和症状:
"头痛" → UMLS:C0018681
"恶心" → UMLS:C0027497
"光敏感" → UMLS:C0234211
- 知识图谱编码(KG Encoding)阶段:
- 在UMLS中查找这些症状的相关疾病关联
- 获取症状组合模式与疾病的关系
- 编码相关节点:
- 症状节点
- 疾病节点
- 它们之间的关系(如"是症状的典型表现")
- 映射转换(Mapping)阶段:
- 将症状-疾病关系的图谱知识转换为语言模型可理解的表示
- 保留症状组合与疾病诊断之间的关联强度
使用多层感知机(MLP),将知识图谱的向量映射到语言模型的向量空间
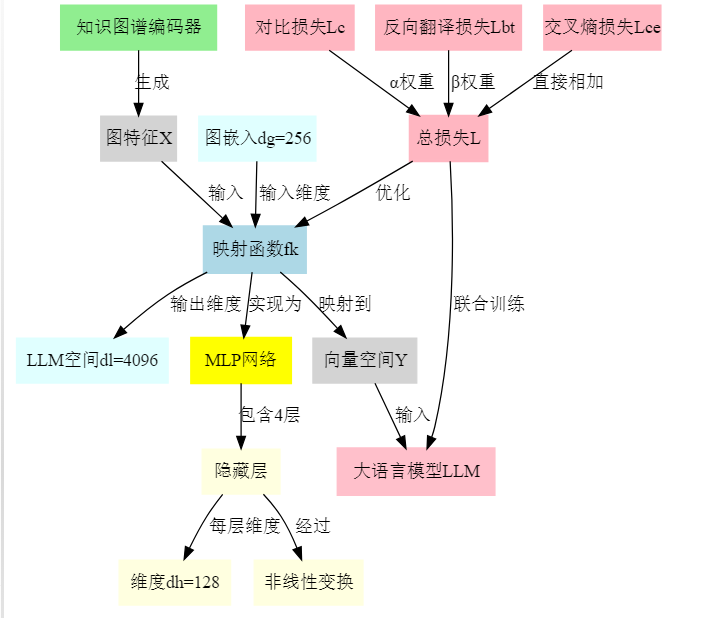
问题背景:
- 需要将知识图谱中的信息有效地融入大语言模型
- 两个空间的表示方式不同(维度不同,语义结构不同)
- 需要保持知识图谱中的结构化信息不被破坏
解决方案设计:
- 图特征获取阶段
- 使用知识图谱编码器处理原始知识图谱
- 生成256维的图特征向量
- 这些特征包含了实体间的结构化关系信息
- 映射转换阶段
- 设计了一个4层MLP作为映射函数fk
- 每层使用128维的隐藏层,通过非线性变换
- 最终将256维的图特征转换为4096维的LLM空间向量
- 这个维度变换使得特征可以被LLM使用
- 优化设计
设计了三重损失函数来保证映射质量:
- 对比损失(Lc): 确保相似实体在映射后仍然相近
- 反向翻译损失(Lbt): 保证映射不会丢失重要信息
- 交叉熵损失(Lce): 确保LLM能够有效利用映射后的特征
- 训练过程
- 联合训练策略:同时优化映射函数和LLM
- 通过权重α和β平衡各损失项的重要性
- 迭代优化直到模型收敛
最终效果:
- 实现了知识图谱到LLM空间的高质量转换
- 保持了原有的语义结构关系
- 使LLM能够有效利用知识图谱中的信息
这个设计的巧妙之处在于:
- 使用MLP实现了复杂的非线性映射
- 通过多重损失函数保证了映射质量
- 联合训练策略确保了整体优化效果
- 在保持语义信息的同时实现了维度转换
- 答案生成阶段:
模型整合:
- 患者描述的症状表现
- 知识图谱中的医学诊断知识
推理过程:
- 持续性头痛 + 恶心 + 光敏感 这个组合
- 在知识图谱中最强关联的是偏头痛
生成答案: "A) 偏头痛"
解释依据:
- 这三个症状的组合是偏头痛的典型特征
- 知识图谱帮助模型理解症状之间的关联模式
- 其他选项虽然可能有头痛症状,但不会同时具备这种特征组合
MEG的优势体现:
- 结构化的医学知识支持
- 症状组合的模式识别
- 可解释的诊断推理过程
这个例子展示了MEG如何:
- 利用知识图谱中的医学关系知识
- 进行类似医生思维的诊断推理
- 给出有依据的判断结果
论文大纲
├── 1 引言【问题背景】
│ ├── LLMs在医疗领域的应用【现状】
│ │ ├── 医疗执照考试【应用场景】
│ │ └── 临床诊断辅助【应用场景】
│ └── LLMs面临的挑战【问题描述】
│ ├── 复杂推理能力不足【技术限制】
│ ├── 可信度问题【技术限制】
│ └── 训练成本高【实践限制】
│
├── 2 MEG模型【解决方案】
│ ├── 核心组件【架构设计】
│ │ ├── KG编码器【功能模块】
│ │ ├── 指令调优语言解码器【功能模块】
│ │ ├── 映射网络【功能模块】
│ │ └── KG基础模块【功能模块】
│ └── 训练策略【实现方法】
│ ├── 嵌入迁移学习【阶段一】
│ └── 下游任务微调【阶段二】
│
├── 3 实验评估【验证效果】
│ ├── 数据集【评估基础】
│ │ ├── MedQA【测试数据】
│ │ ├── PubMedQA【测试数据】
│ │ ├── MedMCQA【测试数据】
│ │ └── MMLU-Medical【测试数据】
│ └── 性能表现【评估结果】
│ ├── 准确率提升【量化指标】
│ ├── 计算效率【量化指标】
│ └── 模型稳定性【质化指标】
│
└── 4 结论【研究成果】
├── 技术创新【贡献总结】
│ ├── 知识增强范式【创新点】
│ └── 轻量级设计【创新点】
└── 实践价值【应用意义】
├── 降低训练成本【价值体现】
└── 提高医疗问答准确性【价值体现】
├── 2 MEG模型【解决方案】
│ ├── 输入层【数据源】
│ │ ├── UMLS知识图谱【知识来源】
│ │ │ ├── 30万节点【图谱规模】
│ │ │ └── 100万边关系【图谱规模】
│ │ └── 医学文本【问题输入】
│ │ ├── 上下文【输入组成】
│ │ ├── 问题【输入组成】
│ │ └── 候选答案【输入组成】
│ │
│ ├── 处理层【核心组件】
│ │ ├── KG编码器【知识编码】
│ │ │ ├── GraphSAGE【编码方法】
│ │ │ └── 256维向量输出【编码结果】
│ │ │
│ │ ├── 映射网络【知识映射】
│ │ │ ├── 4层MLP【网络结构】
│ │ │ ├── 128维隐层【处理维度】
│ │ │ └── 4096维输出【映射结果】
│ │ │
│ │ ├── 语言解码器【答案生成】
│ │ │ ├── Mistral-7B【基础模型】
│ │ │ └── 指令微调【优化方法】
│ │ │
│ │ └── KG基础模块【实体链接】
│ │ ├── 实体检测【处理步骤】
│ │ └── 实体对齐【处理步骤】
│ │
│ ├── 训练过程【优化策略】
│ │ ├── 阶段一:嵌入迁移【初始训练】
│ │ │ ├── 对比损失【训练目标】
│ │ │ └── 反向翻译损失【训练目标】
│ │ │
│ │ └── 阶段二:任务微调【专业优化】
│ │ ├── LoRA适应【优化方法】
│ │ └── 交叉熵损失【训练目标】
│ │
│ └── 输出层【模型产出】
│ ├── 知识增强表示【中间结果】
│ │ ├── 文本嵌入【表示形式】
│ │ └── 图谱知识【表示形式】
│ │
│ └── 最终答案【输出结果】
│ ├── 多选题选择【输出类型】
│ └── 答案解释【输出类型】
为什么简单地把知识图谱信息作为文本加入,效果不够好?
知识图谱:就像一个巨大的医学百科全书,里面存储了大量医学概念和它们之间的关系
参数高效:指的是在不大量增加模型参数的情况下,使用一个轻量级的"转换器"(mapping network)
整合方式:把知识图谱中的信息"翻译"成语言模型的向量形式
实验数据:
Mistral-Instruct-v0.1 w/ graph 40.4±0.4 (零样本)
MEG-MISTRAL1 54.6±0.2 (相同基座模型)
两个实验的相同点:
- 都用了同样的基础模型 (Mistral-Instruct-v0.1)
- 都使用了UMLS知识图谱的信息
- 都是在做医疗问答任务
“w/ graph”:直接把知识图谱的信息作为文本加入
- 例如:"概念A 与 概念B 存在关系C"这样的文本形式
- 准确率只有40.4%
“MEG”:用映射网络转换成向量形式
- 把知识图谱信息转换成数学向量
- 准确率达到54.6%
- 提升了14.2个百分点
观察:仅仅是知识图谱信息的输入形式不同,性能差异如此显著。
都是在添加相同的知识,只是添加方式不同,但效果差异却很大(14.2%是很显著的提升)。
说明知识的"表达形式"非常重要,不是有知识就够了,还要用合适的方式表达,向量形式比文本形式更适合模型处理。
想象两个人学习医学知识:
-
第一个人拿到一本医学教材(文本形式)
- 需要先读懂文字
- 然后理解内容
- 再记忆知识
- 效率较低
-
第二个人拿到一个整理好的知识地图(向量形式)
- 直接看到概念间的关系
- 知识结构清晰
- 容易理解和记忆
- 效率更高
MEG就像是把"教科书"转换成了"知识地图",让模型能更好地理解和使用这些知识。
5 Why分析
Why 1: 为什么直接添加文本效果不好?
- 文本形式会占用大量的上下文窗口tokens
- 语言模型难以高效处理大量的文本三元组陈述
Why 2: 为什么占用tokens和处理文本三元组会是问题?
- 上下文窗口大小是有限的,被知识三元组占用后剩余空间减少
- 文本形式的关系表达冗长,如"A IS_A B"这样的形式效率低
Why 3: 为什么效率低下?
- 模型需要先理解文本形式的知识表达
- 然后再将这些文本知识转化为内部表示
- 这是一个额外的理解和转化过程
Why 4: 为什么需要这个额外的转化过程?
- 因为语言模型的内部运算是基于向量的
- 文本信息需要先被转换成向量形式才能参与计算
- 这个转换过程可能会丢失一些结构化信息
Why 5: 最根本的原因是什么?
- 文本是非结构化的表达方式
- 而知识图谱本质上是高度结构化的信息
- 用文本表达结构化信息会造成信息损失和处理效率降低
5 So分析
So 1: 如何改进?
- 直接使用向量形式表达知识图谱信息
- 设计专门的映射网络进行向量空间转换
So 2: 这个方案会带来什么结果?
- 更高效的信息编码(更少的空间占用)
- 保留了图谱的结构化特征
- 更直接的向量运算
So 3: 对系统有什么影响?
- 模型可以直接利用结构化的知识
- 减少了信息转换的损耗
- 提高了整体处理效率
So 4: 进一步的影响是?
- 回答准确率提升(+10.2%)
- 训练成本降低(只需几小时)
- 模型理解能力增强
So 5: 最终目标是什么?
- 构建一个既能保留知识图谱结构信息
- 又能高效整合到语言模型中
- 同时保持低计算成本的系统
问题的根本在于信息表达形式与计算模式的不匹配。
比如对于"头痛"这个概念,可能有几十个同义词。
但映射到 LLM 向量空间,只有一个,而且这个向量已经编码了所有相关的关系信息。
MEG通过向量映射的方式解决了这个根本问题,既保留了知识的结构性,又提高了计算效率。
这种方法不仅解决了当前问题,还为知识增强型语言模型提供了一个新的范式。
映射网络,为什么选择简单的 MLP,而不是更复杂的 Transformer?
映射网络的结构选择:
CopyMLP 4×128获得最佳效果,而不是更复杂的Transformer结构
观察:更简单的网络结构反而效果更好。
MLP比Transformer效果更好,可能存在某种自然的空间对应关系,过于复杂的映射反而会引入噪音。
"MEG-QA"提示词模板
[INST]标记 → 指令开始
Input/Context → 问题背景
Options → 选项列表
Graph → 知识图谱嵌入
Answer → 答案格式

[INST] 请根据输入的文本内容和医学知识图谱中的相关概念回答以下医学问题。
输入: 一位45岁的患者出现剧烈胸痛、呼吸短促和出汗症状。最可能的诊断是什么?
选项:
{% for option in options %}
A) 急性心肌梗死
B) 胃溃疡
C) 惊恐发作
D) 肺栓塞
{% endfor %}
请直接给出最佳选项作为答案,忽略无关信息。
图谱: {{kg_embeddings}} [/INST]
// 通过{{kg_embeddings}}引入知识图谱信息,将文本问题和结构化医学知识关联起来
答案: A) 急性心肌梗死
这个例子的结构包含:
- [INST]指令开始标记
- 患者症状描述作为问题背景
- 用循环列出4个可能的诊断选项
- 明确要求直接选择最佳答案
- 引入知识图谱信息(通过{{kg_embeddings}}标记)
- 给出最终诊断结果
这种标准格式帮助模型:
- 理解问题的清晰结构
- 利用医学知识图谱中的信息
- 根据症状表现和专业知识作出判断
- 直接给出最合理的诊断选项

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









