









KG-LLM:知识图谱 + 大模型 + 思维链 CoT 、指令微调 IFT 和上下文学习 ICL,解决图神经网络随着跳数增加会导致性能下降
论文:Knowledge Graph Large Language Model (KG-LLM) for Link Prediction
代码:https://anonymous.4open.science/r/KG-LLM-FED0
论文大纲
├── 1 研究背景及动机【论文总体框架】
│ ├── 知识图谱的应用【背景】
│ │ ├── 结构化数据表示【功能】
│ │ └── 近年受到广泛关注【现状】
│ ├── 多跳链接预测的挑战【问题】
│ │ ├── 需要推理中间连接【技术难点】
│ │ └── 缺乏解释性【局限性】
│ └── 现有方法的不足【研究缺口】
│ ├── 过度关注判别模型【局限】
│ ├── 缺乏多跳链接预测【不足】
│ └── 泛化能力有限【短板】
│
├── 2 KG-LLM框架【核心贡献】
│ ├── 框架设计【方法】
│ │ ├── 知识图谱转化为自然语言【数据处理】
│ │ └── 使用提示微调LLMs【模型训练】
│ ├── 技术创新【特点】
│ │ ├── 思维链提示【技术要素】
│ │ ├── 指令微调【技术要素】
│ │ └── 上下文学习【技术要素】
│ └── 实验验证【评估】
│ ├── 使用三种主流LLMs【实验设置】
│ └── 在四个数据集上测试【实验范围】
│
└── 3 实验结果【成果验证】
├── 模型性能【评估指标】
│ ├── F1分数【指标】
│ └── AUC值【指标】
├── 框架优势【结论】
│ ├── 提升预测准确性【成果】
│ ├── 增强泛化能力【成果】
│ └── 改善解释性【成果】
└── 未来展望【展望】
├── 优化指令过程【改进方向】
└── 提升预测可靠性【改进方向】
理解要点
- 背景和问题:
- 类别问题:知识图谱中的多跳链接预测问题
- 具体问题:
• 现有模型缺乏对中间节点关系的推理能力
• 预测结果缺乏可解释性
• 模型泛化能力不足,难以处理未见过的场景
- 概念性质分析:
- 性质:KG-LLM是一个将结构化知识转化为自然语言的框架
- 形成原因:传统方法过度依赖数学表示,缺乏语义理解,导致推理能力受限
- 对比案例:
- 正例:通过KG-LLM框架,可以理解"Miles Davis是爵士乐艺术家"这样的复杂关系推理
- 反例:传统方法可能只能识别直接连接的节点关系,无法进行多步推理
- 类比理解:
KG-LLM就像一个翻译官:
- 把知识图谱中的节点关系(相当于外语)
- 转换成大语言模型能理解的自然语言(相当于母语)
- 让模型能够像人类一样进行推理(相当于理解含义)
-
概念总结:
KG-LLM是一个结合知识图谱和大语言模型的框架,通过将结构化数据转换为自然语言,实现了更好的多跳关系推理和预测。 -
概念重组:
知识图谱大语言模型框架(KG-LLM)是把知识转化为语言,让图谱中的关系变得更容易理解和预测。 -
上下文关联:
文章通过介绍现有方法的局限性,引出KG-LLM框架的必要性,展示了其在解决多跳链接预测问题上的优势。 -
规律分析:
主要矛盾:如何提高模型的推理能力和可解释性
次要矛盾:- 数据表示形式的转换问题
- 计算资源的限制
- 模型训练效率问题
-
功能分析:
- 核心功能:实现多跳链接预测
- 定量指标:F1分数和AUC值
- 定性效果:提升模型解释性和泛化能力
- 来龙去脉梳理:
- 起因:传统知识图谱模型在多跳链接预测中存在局限性
- 发展:提出KG-LLM框架,将结构化知识转换为自然语言
- 结果:通过实验验证,在多个数据集上取得了优异成果
- 影响:为知识图谱分析提供了新的研究方向和解决方案
1. 主要目标
如何提高知识图谱中的多跳链接预测(multi-hop link prediction)准确率和泛化能力?
2. 问题分解
- 现有方法存在什么问题?
- 判别式模型缺乏推理过程的可解释性(黑盒,只给一个概率)
- 主要关注直接相连节点的预测, 忽视多跳关系
- 泛化能力不足, 难以处理未见场景
- 如何利用大语言模型解决这些问题?
- 将结构化的知识图谱数据转换为自然语言提示
- 使用思维链(Chain-of-Thought)增加推理过程的可解释性
- 通过指令微调(Instruction Fine-tuning)增强模型能力
- 引入上下文学习(In-Context Learning)提高泛化能力
3. 实现步骤
- 数据预处理
- 使用深度优先搜索提取所有可能路径
- 保留节点数在2-6之间的路径
- 平衡正负样本数量
- 模型训练
- 使用三种LLM:Flan-T5、Llama2、Gemma
- 对Flan-T5使用全局微调
- 对Llama2和Gemma使用4-bit量化的LoRA
- 评估方法
- 链接预测:使用AUC和F1分数
- 关系预测:使用准确率指标
- 对比分析有无ICL的效果
4. 效果展示
- 性能提升
- WN18RR数据集上F1分数达到98%
- 在未见场景中的准确率超过70%
- 关键发现
- KG-LLM框架显著优于传统方法
- 集成ICL后性能进一步提升
- 在高复杂度的多跳预测中仍保持良好表现
5. 金手指(核心优势)
本文的金手指是"将结构化知识转换为自然语言+思维链推理"的组合:
- 通过自然语言转换充分利用LLM的语义理解能力
- 思维链提供清晰的推理过程
- 指令微调确保模型关注关键信息
- ICL提供示例增强泛化能力
这个方法可以应用于:
- 复杂知识图谱推理
- 多跳关系预测
- 未见场景的知识发现
- 其他结构化数据的自然语言处理任务
核心信息提炼
核心创新: KG-LLM框架
- 目的:解决知识图谱中的多跳链接预测问题
- 方法:将结构化知识图谱转换为自然语言,用于LLM微调
- 优势:增强推理能力、提供解释性、改善泛化性
关键模式提炼:
- 转换模式
知识图谱 -> 自然语言提示 -> LLM训练数据
- 训练模式
输入: 节点关系链(Node_1 -> relation_x -> Node_2 -> relation_y -> Node_3)
输出: 起始与终点连接判断(Node_1是否与Node_3连接)
方法: 思维链(CoT) + 指令微调(IFT) + 上下文学习(ICL)
- 效果提升模式
基准模型 < 传统GNN < KG-LLM(无ICL) < KG-LLM(有ICL)
解法拆解
目的:提升知识图谱的多跳链接预测能力
问题:传统方法在多跳预测、推理解释和泛化性上表现不佳
主解法:KG-LLM框架
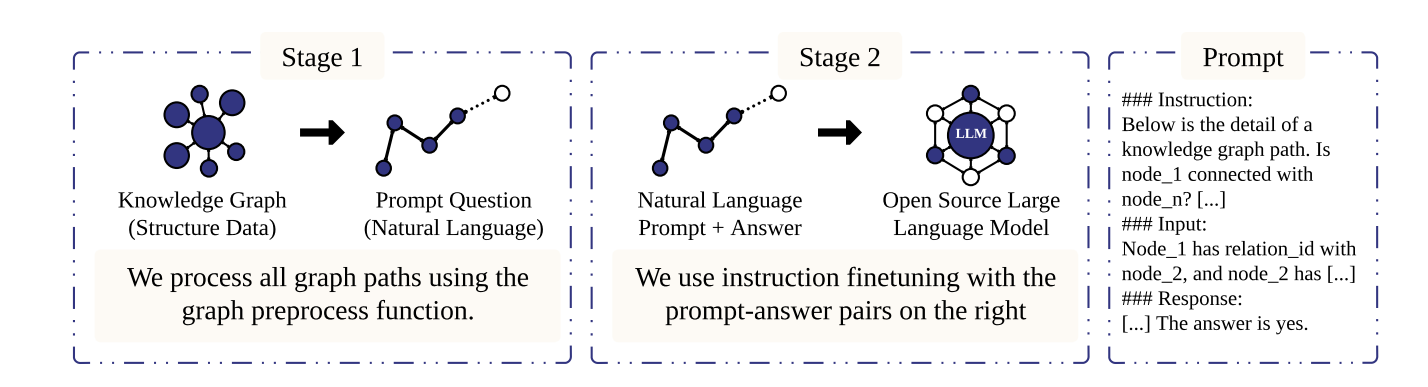
子解法拆解:
KG-LLM框架
├── 子解法1:结构化数据转换(特征:图谱数据难以直接被LLM理解)
│ ├── 路径提取:使用DFS提取2-6跳路径
│ └── 语言转换:将路径转换为自然语言描述
│
├── 子解法2:模型增强(特征:需要提升模型推理和泛化能力)
│ ├── 思维链(CoT):增加推理步骤说明
│ ├── 指令微调(IFT):针对性训练
│ └── 上下文学习(ICL):提供示例增强泛化
│
└── 子解法3:评估优化(特征:需要验证不同场景效果)
├── 多跳预测测试
├── 关系预测测试
└── 泛化能力测试
举例:
输入:Node_1 has relation_x with Node_2, Node_2 has relation_y with Node_3
子解法1输出:Jack bought Shampoo, Shampoo is related with Hair Conditioner
子解法2处理:通过思维链推理关联性,利用ICL提供类似例子
子解法3验证:测试预测准确性和泛化能力
2. 逻辑链分析
这是一个混合型逻辑结构:
- 主干是线性链条:数据转换 -> 模型处理 -> 效果验证
- 每个节点内部是网络结构:多个方法协同工作
- 存在反馈循环:验证结果会反馈影响模型调整
3. 隐性特征分析
发现的隐性特征:
- 语义对齐问题
- 特征:图谱节点与自然语言表达之间的映射关系
- 定义:语义一致性转换方法
- 知识迁移机制
- 特征:预训练知识如何辅助图谱推理
- 定义:跨域知识融合方法
- 错误累积效应
- 特征:多跳预测中的错误传播
- 定义:误差控制机制
4. 潜在局限性
- 计算复杂度问题
- 路径数量随跳数指数增长
- 处理长文本提示需要大量资源
- 语义表达限制
- 复杂关系可能难以准确转换为自然语言
- 不同语言和文化背景可能影响表达
- 模型依赖性
- 严重依赖大型语言模型的性能
- 小模型在处理复杂场景时表现不稳定
- 扩展性挑战
- 处理大规模知识图谱时效率问题
- 实时更新和动态图谱支持有限
为什么传统的图神经网络方法,在处理多跳预测时会遇到瓶颈?
5 Why 分析
Why 1: 为什么传统GNN在多跳预测时会遇到瓶颈?
- 从数据显示,GNN模型的性能随着跳数增加急剧下降
- 在5跳场景下,F1分数和AUC指标都降至接近随机预测水平
Why 2: 为什么跳数增加会导致性能下降?
- 每增加一跳,模型需要处理的节点和关系呈指数级增长
- 信息在传递过程中发生衰减和失真
- 路径越长,错误累积的风险越大
Why 3: 为什么会出现信息衰减和错误累积?
- GNN主要关注局部结构特征的聚合
- 缺乏对全局语义关系的理解能力
- 没有推理过程的可解释性支持
Why 4: 为什么缺乏全局语义理解?
- 传统GNN是基于纯结构化数据训练
- 无法利用预训练模型中的知识
- 推理过程是黑盒式的,缺乏中间步骤的验证
Why 5: 最根本的原因是什么?
- 传统GNN的设计范式限制了其处理复杂语义关系的能力
- 缺乏将结构化知识与语义理解相结合的机制
- 无法像人类那样进行显式的推理过程
5 So 分析
So 1: 如何解决这些问题?
- 将图结构转换为自然语言描述
- 引入大语言模型的语义理解能力
- 添加思维链等推理机制
So 2: 这些解决方案会带来什么结果?
- 模型能够理解更复杂的语义关系
- 推理过程变得可解释和可追踪
- 性能不会随跳数增加而急剧下降
So 3: 这些改进如何影响整个系统?
- 提高了多跳预测的准确性
- 增强了模型的泛化能力
- 改善了推理结果的可解释性
论文使用了思维链(CoT)、指令微调(IFT)和上下文学习(ICL)三种技术,这些方法之间是如何相互补充和增强的?
思维链(CoT)提供清晰的推理步骤、指令微调(IFT)优化任务执行、上下文学习(ICL)提供示例参考,三者协同工作形成了一个完整的推理和学习框架。
- 各自的核心功能
思维链(CoT)的作用:
- 将推理过程分解为可见的步骤
- 提供清晰的推理链路
- 增强结果的可解释性
指令微调(IFT)的作用:
- 调整模型以适应特定任务
- 规范输出格式和内容
- 提高模型对任务的理解
上下文学习(ICL)的作用:
- 提供具体的示例参考
- 增强模型的泛化能力
- 改善处理新情况的表现
- 协同增强关系
CoT 与 IFT 的协同:
CoT提供推理框架
↓
IFT优化这个框架的执行
↓
产生更规范和准确的推理过程
IFT 与 ICL 的协同:
IFT提供任务理解基础
↓
ICL提供具体示例补充
↓
增强模型处理新情况的能力
ICL 与 CoT 的协同:
ICL提供推理模式参考
↓
CoT将这些模式系统化
↓
形成可复制的推理方法
- 整体效果提升
通过三种技术的组合,实现了多重增强:
- 推理能力:CoT提供框架 → IFT优化执行
- 泛化能力:ICL提供示例 → IFT强化学习
- 准确性:三种技术共同提升输出质量
这种协同作用使得模型在处理复杂的多跳链接预测任务时:
- 有清晰的推理步骤(来自CoT)
- 规范的输出形式(来自IFT)
- 良好的泛化性能(来自ICL)
实验结果也证实了这种协同效应,在各项指标上都取得了显著提升。
患者:「我最近经常感到头晕、疲惫,而且睡眠质量很差」
医生的诊断过程:
思维链(CoT):
Step 1: 分析症状组合(头晕+疲惫+睡眠差)
Step 2: 考虑可能病因(贫血、焦虑、内分泌失调等)
Step 3: 评估症状特征和持续时间
Step 4: 得出初步诊断方向
指令微调(IFT)规范化问诊:
- 询问具体症状描述
- 了解症状持续时间
- 检查相关病史
- 评估生活习惯
上下文学习(ICL)参考类似案例:
"去年有一位相似症状的患者,经检查是因工作压力导致的焦虑症,通过调整作息和心理疏导得到改善"
综合应用效果:
通过三种技术的配合,医生能够系统地分析症状(CoT)、规范地进行问诊(IFT),并借鉴类似病例经验(ICL),从而更准确地作出诊断。
为什么研究者将路径长度限制在2-6跳之间?这个范围的选择背后有什么考虑?
研究者将路径长度限制在2-6跳之间的考虑:
- 论文中明确提到这个选择是基于"六度分离理论"(six degrees of separation theory)。
- 根据论文第5页的描述,这个理论认为任何两个个体之间平均最多通过6个中介者就能建立联系。
研究者使用这个理论作为设置多跳预测范围的理论基础:
2 跳代表最简单的情况(两个节点之间有一个中介节点)
6 跳代表最复杂的情况(符合六度分离理论的最大跳数)
这个范围既保证了预测任务的实用性,又避免了过长路径带来的计算复杂性
我觉得,医疗知识图谱需要建立自己的、基于科学证据的路径长度标准,而不是简单套用来自社交网络的理论
六度分离理论最初是用来描述社交网络中人与人之间的联系,其基本假设是基于人际关系网络的特性
医疗知识图谱中的关系可能是"药物-治疗-疾病"、"症状-指示-疾病"等专业关系
这些关系链的有效长度应该由领域知识决定,而不是社交网络的经验法则
提示词模版
- 多跳链接预测(消融研究)
### 输入:
节点[节点id1]与节点[节点id2]有关系[关系id]。
节点[节点id2]与节点[节点id3]有关系[关系id]。
[...]
节点[节点id1]与[最后一个节点]是否有连接?
### 预期输出:
### 响应:
[是/否]
- 多跳链接预测(基于知识图谱的大语言模型)
### 指令:
以下是一个知识图谱路径的详细信息。节点[节点id1]是否与节点[最后一个节点]连接?
请通过逐步推理来回答问题。从给定选项中选择: 1. 是 2. 否
### 输入:
节点[节点id1]与节点[节点id2]有关系[关系id]。
节点[节点id2]与节点[节点id3]有关系[关系id]。
[...]
### 预期输出:
### 响应:
节点[节点id1]与节点[节点id2]有关系[关系id]表示[节点文本1][关系文本][节点文本2]。[...]
所以[节点文本1][关系文本][最后节点文本]。
答案是是。
- 多跳关系预测(消融研究)
### 输入:
节点[节点id1]与节点[节点id2]有关系[关系id]。
节点[节点id2]与节点[节点id3]有关系[关系id]。
[...]
节点[节点id1]与[最后一个节点]之间的关系是什么?
### 预期输出:
### 响应:
[关系id]
- 多跳关系预测(基于知识图谱的大语言模型)
### 指令:
以下是一个知识图谱路径的详细信息。节点[节点id1]与[最后一个节点]之间的关系是什么?
请通过逐步推理来回答问题。从给定选项中选择: 1. [关系文本1] 2. [关系文本2] [...]
### 输入:
节点[节点id1]与节点[节点id2]有关系[关系id]。
节点[节点id2]与节点[节点id3]有关系[关系id]。
[...]
### 预期输出:
### 响应:
节点[节点id1]与节点[节点id2]有关系[关系id]表示[节点文本1][关系文本][节点文本2]。[...]
所以[节点文本1][关系文本][最后节点文本]。
答案是[关系文本]。
这四个模块展示了两种不同方法(消融研究和基于知识图谱的大语言模型)在处理多跳链接预测和多跳关系预测任务时的输入输出格式。

















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









