









代 码:https://github.com/KaiChenNJ/MDTeamGPT
这个研究想要解决什么现实问题?
-
研究要解决的类别问题:
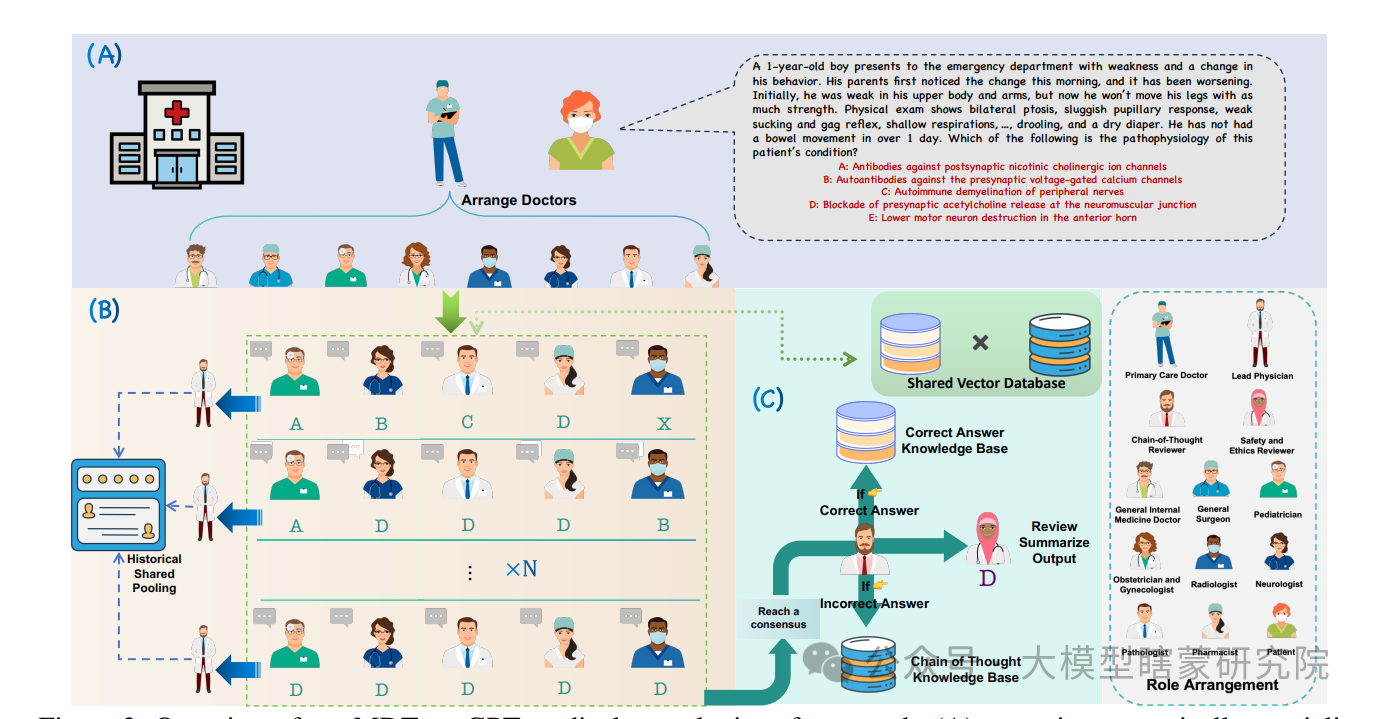
多学科团队医疗会诊中,常常存在沟通协调量巨大、诊断信息分散、意见冲突难以及时整合等情况,导致诊断质量与效率难以兼顾。 -
要解决的具体问题:
在多轮对话的复杂协作中,容易出现对话上下文过长、信息冗余及冲突得不到及时处理,还缺少能够积累先前诊断经验并持续改进的机制。尤其在真实医疗场景中,一旦诊断过程复杂耗时、信息组织混乱或错误累积,都可能影响患者的治疗质量与安全。
-
正例:
-
一家大型三甲医院定期开展“MDT会诊”,安排固定时间、场地,让各科室医生围绕疑难病例进行多轮讨论。
-
会后,由带头医生(Lead Physician)撰写汇总报告,记录每个专科的关键意见和最终统一结论,并把成功经验纳入医院内部的知识库。
-
这样,后续遇到相似情况的患者时,其他医生可迅速调阅之前的“成功诊断思路”进行参考,既避免重复劳动,又减少了漏诊风险。
-
2. 反例:
-
另一家医院没有完善的团队合作和记录机制。
-
患者往往被单一科室的医生独立诊断,或是在不同科室间自行求医,缺乏系统整合。
-
同样的罕见病例反复出现,但没有经验共享,也缺少“带头医生”统一把关,往往造成信息流失或重复检查。
Chain-of-Thought Knowledge Base 又是什么?
这是一个“思维链知识库”,存放系统在出错时的完整推理过程与反思。
也就是说,当诊断结果被证实是错误的,系统会把它的推理过程和错误原因记录下来,供之后参考和避免犯同样的错误。
关联:类似人类的“失败案例库”,可以从错误中学习并反省,以免再次犯错。
残差式讨论结构 是什么含义?
它是一种分轮“残差”策略(仅传递必要的结构化信息)。
在每一轮讨论结束后,用“简化/提炼”过的上轮结果作为背景给下一轮医生继续讨论,而不让后面的医生看见所有海量对话细节,只看“关键点”即可。
这样既减少信息污染,也减轻模型理解负担。
关联:好比写会议纪要:大家不会在下一次会议把前次所有原始冗长对话全搬出来,而是总结成“会议纪要”,让后续讨论效率更高。
文中多次提到的 自我进化 是如何实现的?
CorrectKB 与 ChainKB,分别存储“成功诊断经验”和“失败案例及反思”,从而让系统不断自我进化。
下一次遇到相似问题时,可以检索之前“正确路径”或“错误教训”,从而让每次新对话都建立在更丰富的经验之上,逐步“进化”。
Lead Physician机制:将每轮讨论内容分类为“一致、冲突、独立、整合”四部分,统一存储在“Historical Shared Pool”,使下一轮更有针对性地引用。
├── MDTeamGPT核心方法【多角色多轮会诊机制】
│
├── 输入【来自患者与场景】
│ ├── 患者背景信息B【采集病史、症状等】
│ │ └── 【B是诊断依据】
│ ├── 医疗问题Q【患者具体疑问】
│ │ └── 【Q决定诊断方向】
│ └── Primary Care Doctor进行角色分配【基于B与Q】
│ └── 【Primary Care Doctor→选择最适合的专科医生】代表角色选择关系
│
├── 处理过程【多轮协作与知识积累】
│ ├── 多角色设置【A与S】
│ │ ├── A:辅助角色集合【不直接诊断】
│ │ │ ├── Lead Physician【负责汇总与整合】
│ │ │ ├── Chain-of-Thought Reviewer【归纳正确/错误经验】
│ │ │ └── Safety and Ethics Reviewer【审查输出安全合规】
│ │ └── S:专家医生集合【直接诊断】
│ └── 【A与S相互配合】代表角色协同关系
│
│ ├── 多轮协作讨论【残余讨论结构】
│ │ ├── 专科医生独立给出意见【避免相互干扰】
│ │ │ └── 【同一轮内S中的每位医生只读患者信息,不读他人意见】
│ │ ├── Lead Physician分类聚合【一致、冲突、独立、整合】
│ │ │ └── 【将多位医生观点“聚合”并存入历史共享池H】代表信息汇总关系
│ │ ├── 决策:若未达成共识则进入下一轮【循环迭代】
│ │ │ └── 【参考上一轮聚合结果与知识库】代表信息回溯关系
│ │ └── 减少记忆负担并提高准确性【仅引用最近两轮摘要】
│
│ ├── 知识库引用与更新【自适应学习】
│ │ ├── CorrectKB【记录正确咨询案例】
│ │ │ └── 【为后续诊断提供成功经验】代表知识继承
│ │ ├── ChainKB【存储错误案例与反思】
│ │ │ └── 【帮助模型避免重复错误】代表错误反思
│ │ └── 检索相似案例【基于文本向量相似度】
│ └── 【CorrectKB与ChainKB→提供历史经验】代表知识迁移关系
│
│ └── 安全与伦理审查【最终把关】
│ └── Safety and Ethics Reviewer过滤不当诊疗意见【保证医疗安全】
│
├── 输出【最终诊断与治疗建议】
│ ├── 达成共识后由Lead Physician确认【最后汇总】
│ │ └── 【Lead Physician→输出结果R】代表决策发布
│ └── R:给出具体诊断与建议【解答患者问题】
│ └── 【R基于专家多轮讨论与知识库】代表整合产出
│
└── 整体流程衔接【技术与方法关联】
├── 多角色并行诊断【提升专业性】
├── 残余讨论结构【降低信息污染】
├── 知识库自适应更新【经验累积与错误反思】
└── 安全审查【保证医疗伦理合规】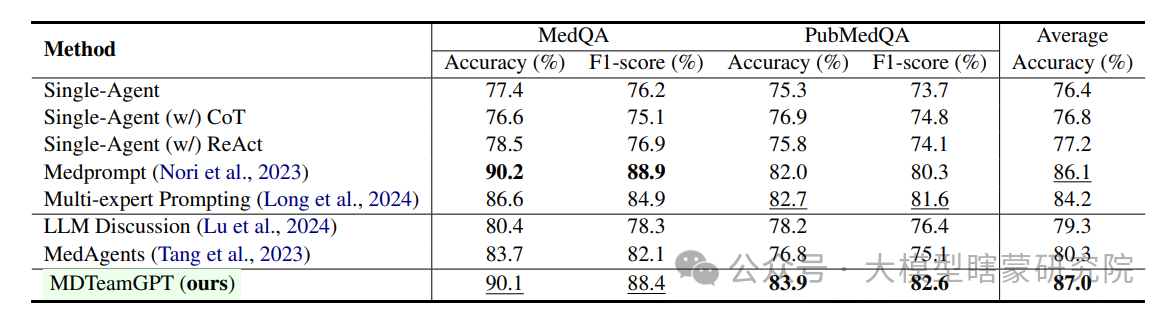
解法拆解

├── MDTeamGPT(核心解法)
│ ├── 多代理协作(信息分层处理)
│ │ ├── 设定不同医生角色,模拟专科诊断
│ │ └── Lead Physician 归纳信息,减少信息冲突
│
│ ├── 残余讨论(降低认知负担)
│ │ ├── 仅存储最近两轮讨论,减少信息冗余
│ │ ├── 避免 LLM 记忆过载,提高诊断效率
│ │ └── 通过 Lead Physician 进行最终整合
│
│ ├── 经验知识库(正确/错误案例积累)
│ │ ├── CorrectKB 存储正确案例,优化推理
│ │ ├── ChainKB 存储错误案例,并反思错误
│ │ └── 通过相似案例检索优化未来诊断
│
│ └── 安全审查(保证医疗伦理)
│ ├── Safety and Ethics Reviewer 过滤危险诊断
│ ├── 确保输出符合医疗安全要求
│ └── 保障患者安全,减少不良诊疗建议子解法 1:多代理协作(信息分层处理)
-
-
诊断过程通过角色分工,使各专科医生独立决策并互相补充。
-
-
采用该方法的特征:
-
医疗诊断涉及多学科知识,单一 LLM 难以胜任 → 需要多角色协作。
-
传统多代理方法难以协调,导致决策效率低 → 通过 Lead Physician 进行信息整合。
-
-
与同类算法的主要区别:
- 对比 MedAgents(Tang et al. 2023):
MedAgents 采用投票机制,而 MDTeamGPT 采用结构化讨论,并由 Lead Physician 归纳结果,提高信息整合能力。
- 对比 LLM Discussion(Lu et al. 2024):
LLM Discussion 仅依赖多轮会话优化推理,而 MDTeamGPT 结合了专家角色的专业性,使推理更具针对性。
- 对比 MedAgents(Tang et al. 2023):
子解法 2:残余讨论(降低认知负担)
-
采用该方法的特征:
-
多轮讨论会产生大量上下文,使 LLM 认知负担过重 → 仅引用最近两轮数据,提高效率。
-
长记忆可能导致错误信息积累 → 通过残余讨论结构,确保信息更新,减少认知污染。
-
-
与同类算法的主要区别:
- 对比 ChatDev(Qian et al. 2024):
ChatDev 采用层次化团队结构,但没有明确优化长上下文影响。
- 对比 MACNET(Qian et al. 2024):
MACNET 采用有向无环图推理,但仍依赖完整历史,MDTeamGPT 通过残余存储减少负担。
- 对比 ChatDev(Qian et al. 2024):
子解法 3:经验知识库(正确/错误案例积累)
-
采用该方法的特征:
-
传统方法仅存储诊断历史,无法总结经验 → 需要明确区分正确/错误案例,并存储推理路径。
-
需要自适应学习,提高诊断能力 → 通过 CorrectKB 和 ChainKB 进行知识积累。
-
-
与同类算法的主要区别:
- 对比 SelfEvolve(Jiang et al. 2023):
SelfEvolve 主要用于代码优化,而 MDTeamGPT 结合 ChainKB 进行错误反思,提高医学推理能力。
- 对比 ExpeL(Zhao et al. 2024):
ExpeL 仅存储成功经验,MDTeamGPT 额外存储错误推理路径,使模型避免重复错误。
- 对比 SelfEvolve(Jiang et al. 2023):
子解法 4:安全审查(保证医疗伦理)
-
采用该方法的特征:
-
医疗 AI 需要避免错误或不安全的建议 → 需要专门的伦理审查环节。
-
传统医疗 AI 可能会给出未经验证的诊断建议 → 通过独立审查减少风险。
-
-
与同类算法的主要区别:
- 对比 Medprompt(Nori et al. 2023):
Medprompt 仅增强推理提示,并未额外引入安全过滤。
- 对比 LLM Discussion(Lu et al. 2024):
该方法未专门考虑医疗伦理风险,而 MDTeamGPT 额外加入审查角色。
- 对比 Medprompt(Nori et al. 2023):

















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









