







摘要
最近,基于轻量化RGBD相机的单目视觉广泛用于各种领域。然而,受限于成像原理,通常使用的基于TOF,结构光或双目视觉的RGBD相机不可避免的会获取一些无效数据,例如弱反射,边界阴影和伪影,这些也许会给后续的工作带来消极的影响。在本文中,我们提出 了一个新的基于注意力指导的门卷积网络(AGG-Net)的深度图像补全模型,通过这种方法可以从原始的深度图像和对应的RGB图像获得更加准确和可靠的的深度图像。我们的模型使用了一个类U-Net架构,由两个平行的深度和颜色特征分支构成。在编码阶段,一个注意力指导的门卷积模块(AG-GConv)被提出来理解不同尺度下的颜色和深度特征的融合,这可以有效减少无效深度数据对重建的负面影响。在解码阶段,一个注意力指导的跳跃连接(AG-SC)模块被提出来避免在重建中引入太多与深度无关的特征。实验结果显示我们的方法在流行的基准NYU-Depth V2,DIML和SUN RGB-D上超越了最先进的方法。
1. 介绍
深度感知在一些应用中至关重要,例如自动驾驶,机器人导航和场景重建。常用的深度传感器有LiDAR,TIme-of-Fligh或者单目相机。然而大部分获取的深度图像都不可避免的伴随着许多由微弱或直接反射、远距离、强光和其他环境噪声所造成的无效的区域,如图1中所示。
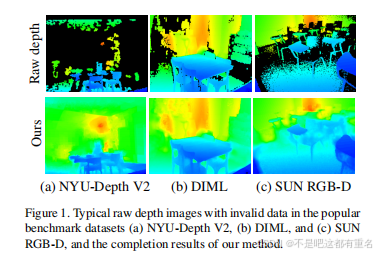
这些无效数据将会对随后的流程产生严重的影响。因此,深度的补全对于基于深度图像的大部分应用都是必要的。
尽管已经又许多基于单一的原始深度图像的方法被提出,但是由于无效数据的缺乏或者不确定它们的表现被严重的限制。因此,研究人员考虑通过两种典型的方式来引入RGB信息以指导深度补全。传统的方法基于有效的临近像素通过一些给定的规则来填充无效的像素,例如联合双边过滤器,快速行进算法和马尔可夫随机场。然而,这些方法通常不够快或者不够准确。其他的方法使用深度神经网路预测无效像素,通常使用一个自编码器来从RGB-D数据中提取深度和颜色特征,然后融合它们以实现深度图的补全。这种方法相比传统方法展现了非同寻常的提升而且在最近的工作中被广泛的使用。
然而,使用深度学习的方法有两个方面的挑战。首先,原始的卷积操作将所有的输入都视作有效数据。原始的深度图像包含许多无效数据,可能会污染卷积核提取的潜在特征,在重建的过程中导致多样的视觉伪影,例如,空洞,矛盾和模糊边界。为了改善限制,部分卷积被提出来自动区分无效像素,同时基于有效数据来计算输出。而且,当感受野中包含至少一个有效像素的时候输出像素将被标记为有效的。这种方法提高了特征的可靠性,但是这种方法仍然有不可调和的问题。例如,考虑一个3x3的卷积核,无论多少有效像素被这个区域覆盖,这个核的输出都会标记为有效。然而,事实上在不同的情况下的输出的置信度是完全不同的。进一步的,门卷积和反卷积被提出,可以通过一个额外的卷积核学习到一个门遮罩来一致无效特征加强可靠特征。这些操作对于从原始的带有无效像素的深度图像中提取特征是有效的但是很难去处理大面积的缺失区域,因此其深度补全结果仍然不可信。一种可行的填补大空洞的深度图像的方法是同时考虑颜色核深度信息。
另一个挑战是使用颜色信息对于深度补全来说有利有弊。现存的大部分的模型都是直接通过在自编码器的瓶颈部分直接通过连接潜在特征来实现颜色和深度的融合。然而,引入与深度无关的颜色特征也许误导深度预测结果,例如,相同颜色的临近表面和有丰富纹理的平面。因此,一种可以屏蔽来自深度和颜色特征融合导致的干扰的机制一定会对深度补全任务有效。不幸的是,大部分的相关研究并没有解决这个问题。
基于上面的观察,我们提出了一个新的基于类UNet架构的深度补全框架,该框架中深度和颜色特征通过两个并行的编码分支提取然后在编码阶段通过合并入一个带有跳跃连接的分支。具体来说,两个分支的融合是基于我们提出的注意力引导的门控卷积(AG-GConv)过程实现的,从颜色和深度值中学习联合上下文注意来指导深度特征的提取。进一步的,注意力引导的跳跃连接模块被设计用来过滤与深度重建无关的颜色特征。我们的主要贡献可以总结为如下几点:
- 我们提出了一个结合深度和颜色特征的双流多尺度编解码网络来实现高质量的深度图像补全。
- 提出了一个注意力引导的门控卷积模块可以缓解特征学习过程中的无效深度值的负面影响。
- 提出了一个新的注意力引导的跳跃连接模块可以减少解码过程中深度无关的颜色特征的干扰。
- 实验结果表明我们的方法在流行的基准NYU-Depth V2,DIML和SUN RGB-D上超越了最先进的方法。
2. 相关工作
深度补全近年来,由于CNN网络在非线性特征表示上的强大能力,越来越多的研究者逐渐将对深度补全的兴趣从手工特征转向深度学习特征。Cheng等提出了卷积空间传播网络(convolutional spatial propagation network, CSPN),其架构主要参考UNet和ResNet。它通过循环操作生成一个远程上下文,从而减少了重建过程中细节的丢失。Jaritz等人提出了一种基于著名的NASNet的自编码器框架,以获得对输入图像更大的接受野。Shivakumar等提出了基于空间金字塔池化模块的DFuseNet,从强度图像和深度特征中分别提取上下文线索,然后在网络中融合,有效地利用了两种模式之间的潜在关系。Huang等利用自注意机制和边界一致性模式来提高深度边界和图像质量。
然而,架构的修改和优化需要进一步研究。首先,CSPN设计中采用的UNet和ResNet最初分别用于语义分割和图像分类。事实证明,它们的结构善于捕捉语义感知特征,而由于池化操作而忽略了详细的回归,从而限制了它们准确预测缺失深度值的能力。虽然在DFuseNet等模型上采用了多尺度结构,但是编码过程中丢失的信息仍然难以恢复,因为解码过程完全依赖于模型的瓶颈层。其次,原始的卷积无法处理深度图像的无效区域,为了从含有无效像素的原始深度图像中提取鲁棒和自适应特征,需要一种新的卷积运算方式。Lee等人提出了与DFuseNet类似的CrossGuide网络,其编码器引入了传感模块,从RGB-D数据中学习多模态特征。Wang等人设计了一种RGB-D融合GAN来跨颜色和深度特征传播特征。在这项工作中,我们设计了AG-GConv模块,以便在颜色特征的指导下更好地捕获深度特征,特别是处理大面积缺失区域。
上下文注意力在图像处理中,注意力机制被广泛用于突出特征映射的本质部分。在深度补全任务中,FuseNet基于空间注意力机制对预测深度图使用全局置信度图和局部置信度图进行加权。邱进行了一项有益的尝试,名为“DeepLider”。[20]学习通道注意力,引导颜色特征与表面法向量映射的结合。Senushkin等人提出了一种新的解码器调制支路,该支路通过SPADE块控制深度重构,从而修改输出信号的空间分布。我们注意到不同的特征通道可能有不同的最优空间注意图,这需要一种新的上下文注意机制来安排不同特征通道的不同空间注意模式。因此,我们提出了AG-GConv和AG-SC两个新的模块,基于通道和空间位置的联合上下文关注来调节深度和颜色特征的融合。
3. 方法
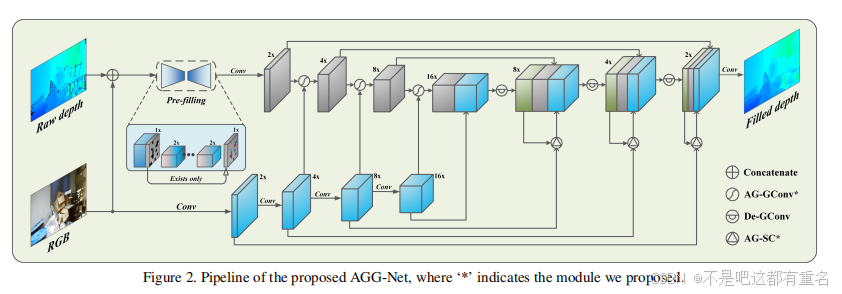
所提出的深度图像补全AGG-Net架构从概述到细节,如图2所示。本节介绍了整个模型的流水线,我们提出的注意力引导门控卷积(AGGConv)和注意力引导跳跃连接(AG-SC),以及一个多任务损失函数。
3.1架构
概览我们的模型的管道包括两个连续的网络:预填充网络和微调网络。前者将缺失的原始深度图像和相应的RGB图像作为输入,通过轻量级的自编码器粗略地填充所有缺失值,从而提供完整的深度图。微调网络采用双分支编码器从深度和颜色图像中提取特征。然后通过多尺度跳联解码器重构深度图像。此外,本文提出的AG-GConv和AG-SC模块分别嵌入到编码器和解码器层,更合理地加强了两种模式的融合,从而提高了重建深度图像的质量。整个管道将以端到端的方式进行训练。
pre-filling如图2所示,将原始深度图像和RGB图像直接合并为一个四通道多模态特征张量,并将其输入到具有两层原始卷积和反卷积的轻型自编码器中。预填充网络的输出用于填充原始深度图像的缺失区域,同时保持有效深度值不变。值得注意的是,卷积层采用了更大的核,以确保接收域足够大,覆盖大多数无效区域。因此,预填充网络可以提供无零值像素的粗填充深度图像。
微调如图2所示,微调网络采用双分支类unet结构,通过特征编码解码重建深度图。在每个编码层中,与普通卷积或门控卷积[30]不同,本文提出的AG-GConv模块在基于深度和颜色特征学习到的上下文注意(Contextual Attention, CA)的指导下,用一个元素掩模对深度特征张量进行门控。在每个解码层,除了De-GConv模块,AG-SC模块也被用来调制从颜色编码层到相应深度解码层的跳变连接,其中采用了不同的注意力机制来抑制与深度无关的颜色特征。
3.2AG-GConv编码
大多数传统的编码器网络使用多层香草卷积(VConv)来提取特征[30],如图3 (a)。不幸的是,预填充网络提供的深度图只是粗填充。
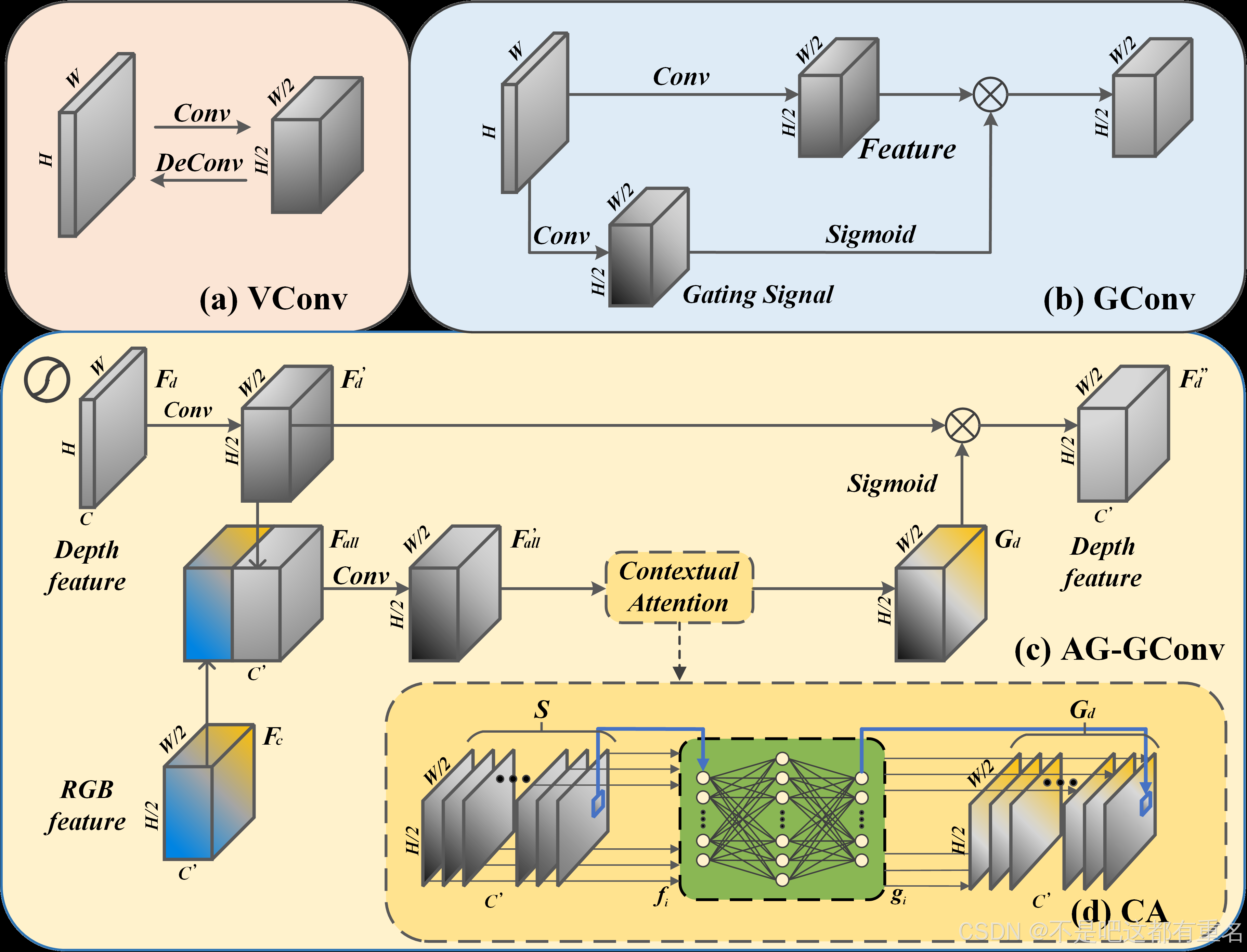
Figure 3. Details of VConv, GConv, AG-GConv and CA.
这些填充深度值是不可靠的,可以通过微调网络传递甚至放大,从而污染重建结果。 门控卷积(GConv)为这一问题提供了较好的解决方案,它生成一个门控信号来筛除这些不可靠的特征,如图3 (b)所示。然而,GConv仍然有一些缺点。一方面,它只考虑了深度特征,而忽略了隐藏在彩色图像中的有价值的信息。另一方面,它根据小的接受野的特征产生门控信号,这削弱了它填充大孔的能力。
为了克服上述限制,我们提出了一个新的模块,称为注意力引导门控卷积(AGGConv),在深度和颜色分支学习的上下文注意的指导下调节深度特征。对于AG-GConv模块,输入深度和颜色特征分别表示为Fd和Fc。通常,Fd的大小为H × W × C, Fc的大小为H/2 × w /2 × C’。
一个标准的VConv单元包含一个2d卷积层、一个批处理归一化层和一个leakyReLU激活层。首先,如图3 ©所示,将输入深度特征变换为
F
d
′
∈
R
H
/
2
x
w
/
2
x
C
F_d^{'}\in\mathfrak R^{H/2xw/2xC}
Fd′∈RH/2xw/2xC,分别通过stride=1和stride=2的两个连续的VConv单元。然后我们将
F
d
′
F_{d}^{'}
Fd′和
F
c
F_c
Fc沿着通道方向拼接为一个组合特征张量
F
a
l
l
=
[
F
d
′
,
F
c
]
F_{all}=[F_{d}^{'},F_{c}]
Fall=[Fd′,Fc],其尺寸为H/2xW/2x2C’.然后,我们将
F
a
l
l
F_{all}
Fall传入一个步长为1的VConv单元以获得一个新的尺寸为H/2xW/2xC’特征张量
F
a
l
l
′
F^{'}_{all}
Fall′.我们构建了CA模块来从
F
a
l
l
′
F^{'}_{all}
Fall′产生门控信号,通过学习空间和通道之间共同分布的语境注意力。首先,它会雁阵通道方向被分为切片
S
=
{
s
i
∈
R
H
/
2
x
w
/
2
∣
i
=
1
,
.
.
.
,
C
′
}
S=\{s_i\in\mathfrak R^{H/2xw/2}|i=1,...,C'\}
S={si∈RH/2xw/2∣i=1,...,C′},然后每个切片被展平为一个长向量
f
i
∈
R
L
f_i\in\mathfrak R^L
fi∈RL,其中L=H/2xW/2。所提出的CA网络由两个全连接层组成,用于学习全局上下文注意,如图3所示(d).值得注意的是,
F
a
′
l
l
F'_all
Fa′ll的所有切片
S
i
S_i
Si将共享相同的全连接层。它的隐藏层包含M个ReLU神经元(一般M = 4L),输出层包含L个Sigmoid神经元。输出向量
g
i
g_i
gi可以按照下式计算:
g
i
=
ϕ
c
a
(
f
i
;
θ
c
a
)
g_i=\phi_{ca}(f_i; \theta_{ca})
gi=ϕca(fi;θca)
ϕ
c
a
\phi_{ca}
ϕca是CA网络的映射函数,通常是ReLU函数,其权重参数为
θ
c
a
\theta_{ca}
θca。该网络考虑了所有空间位置来评估每个特定特征片的空间注意力。然后,输出向量
{
g
i
∈
R
L
∣
i
=
1
,
.
.
.
,
C
′
}
\{g_i \in \mathbb{R}^L | i = 1, ..., C' \}
{gi∈RL∣i=1,...,C′}将被重塑为
H
2
×
W
2
\frac{H}{2} \times \frac{W}{2}
2H×2W的大小,并打包成与特征张量
F
d
′
F_d'
Fd′大小相同的门控张量
G
d
G_d
Gd。最后,AG-GConv模块的输出可以通过将深度特征
F
d
′
F_d'
Fd′与门控张量
G
d
G_d
Gd相乘得到。
F
d
′
′
=
F
d
′
⊗
G
d
F_d'' = F_d' \otimes G_d
Fd′′=Fd′⊗Gd
其中⊗表示两个张量之间逐元素的乘法,当前AG-GConv模块的输出
F
d
′
′
F''_d
Fd′′将作为后面的编码层的输入。
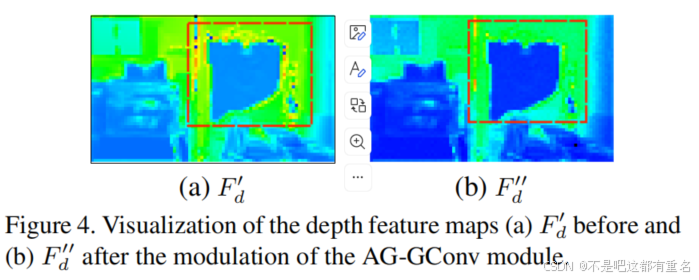
动机分析对于带有大面积空洞的原始深度图像,洞内像素的低级特征是不可靠的,因为它们的邻域也是无效的。然而,普通卷积无法区分这些无效的模式和正常模式,因为它在所有区域上以完全相同的方式实现空间卷积,而不考虑大规模的背景。这限制了填充深度图像中大空洞的能力。与上述两种方法相比,所提出的 AG-GConv 同时考虑了深度特征和颜色特征,并通过全连接层在空间和通道上生成联合的上下文注意力,因此门控信号被认为具有更高的可靠性。如图4所示,当应用所提出的 AG-GConv 时,大空洞周围的大部分分散无效特征(用红框标出)被消除。这意味着填充过程由可靠的特征主导,而不是无效的特征,从而有助于提高重建深度图像的质量和可靠性。
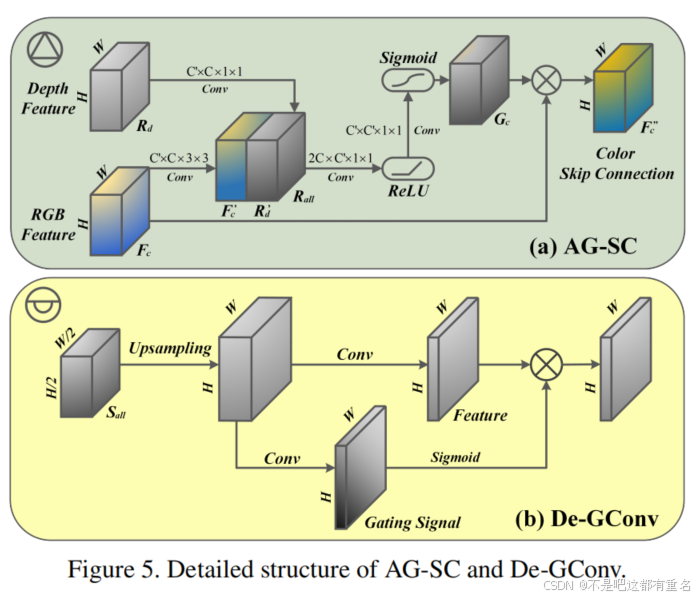
3.3AG-SC解码
大多数重建网络通过上采样和反卷积实现解码过程。然而,编码器和解码器之间的瓶颈可能导致细尺度特征的严重丢失。因此,通常使用从编码器到解码器的跳跃连接来补偿不同尺度的特征。此外,颜色特征在预测深度值方面是有益的,许多出色的单目深度恢复工作已经证明了这一点。基于上述分析,我们提出了一种新的解码方案,如图5所示。每个解码层从三个输入中收集特征:深度分支的前一层、来自深度编码器和颜色编码器的跳跃连接。由于来自主干的深度特征
F
d
F_d
Fd 和跳跃连接的特征已经通过 De-GConv 和 AG-GConv 模块进行了调制,因此提出的 AG-SC 模块仅用于改进来自颜色分支的跳跃连接。
将颜色跳跃连接的特征表示为
F
c
F_c
Fc,上一层的深度特征表示为
R
d
R_d
Rd,它们的大小相同,均为
H
×
W
×
C
H \times W \times C
H×W×C。通过一个核大小为
1
×
1
1 \times 1
1×1 的 VConv 单元和另一个核大小为
3
×
3
3 \times 3
3×3 的 VConv 单元,
R
d
R_d
Rd 和
F
c
F_c
Fc 分别被转换为
R
d
′
R_d'
Rd′ 和
F
c
′
F_c'
Fc′。如图 5(a) 所示,AG-SC 模块将它们连接为张量
R
a
l
l
′
=
[
R
d
′
;
F
c
′
]
R_{all}' = [R_d'; F_c']
Rall′=[Rd′;Fc′],其大小为
H
×
W
×
2
C
H \times W \times 2C
H×W×2C。然后,我们通过一个带有 ReLU 层和 Sigmoid 层的 VConv 单元学习门控信号
G
c
G_c
Gc。最后,AG-SC 模块的输出可以通过根据公式 3 实现逐元素相乘得到。
F
c
′
′
=
F
c
⊗
G
c
F_c'' = F_c \otimes G_c
Fc′′=Fc⊗Gc
我们将
R
d
R_d
Rd、
F
d
F_d
Fd 和
F
d
′
′
F_d''
Fd′′ 拼接起来构建一个组合特征张量
S
a
l
l
=
[
R
d
;
F
d
;
F
c
′
′
]
S_{all} = [R_d; F_d; F_c'']
Sall=[Rd;Fd;Fc′′],并将其输入到 De-GConv 模块【30】中,以生成当前解码层的输出,如图 5(b) 所示。
动机分析考虑到同一场景中的彩色图像和深度图像之间可能存在一些潜在的相关性,使用彩色特征来辅助深度预测已被证明是深度补全的有效方法。然而,颜色与深度之间的相关性是复杂且不确定的。在物体的边界处,颜色模式通常与深度变化密切相关。然而,在平坦表面上,深度通常保持不变,而颜色和纹理可能发生剧烈变化。如果平坦表面是具有强镜面反射的镜子,或是具有较低反射率的图案毯子,那么在深度图像的对应区域可能会出现大面积的空洞。在这些区域,颜色信息可能会严重误导深度预测。AG-SC 模块旨在通过学习颜色和深度的联合分布,建立一种局部注意机制,以抑制跳跃连接中与深度无关的颜色特征,并减少它们对重建深度图像的负面影响。在合并的张量
S
a
l
l
S_{all}
Sall 中,
R
d
R_d
Rd 可以提供较粗尺度的深度特征,来自深度跳跃连接的
F
d
F_d
Fd 可以提供较细尺度的深度特征,而来自 AG-SC 的张量
F
c
′
′
F_c''
Fc′′ 可以提供过滤后的颜色特征。可以想象,它们的集成仍可能引入一些不可靠的特征。De-GConv 模块可以通过将原始特征与门控信号相乘,部分过滤掉这些有害特征,保证下一解码层有更好的输入。总之,提出的 AG-SC 模块和典型的 De-GConv 模块都在精炼颜色和深度特征以实现深度补全方面发挥了作用。一项消融研究表明,AG-SC 和 De-GConv 模块的集成确实对提高重建深度图像的质量起到了积极作用。
3.4 损失函数
整个流程在所提出的损失函数的指导下,以端到端的方式进行训练。该损失函数包含两个项,如公式4所示。
L
total
=
λ
δ
L
δ
+
λ
p
L
p
\mathcal{L}_{\text{total}} = \lambda_{\delta} \mathcal{L}_{\delta} + \lambda_{p} \mathcal{L}_{p}
Ltotal=λδLδ+λpLp
其中,
L
δ
\mathcal{L}_{\delta}
Lδ 是重建错误的Huber损失,如式5所示:
L
δ
=
∑
i
=
1
M
∑
j
=
1
N
huber
(
d
^
i
,
j
,
d
i
,
j
)
\mathcal{L}_{\delta} = \sum_{i=1}^{M} \sum_{j=1}^{N} \text{huber} \left( \hat{d}_{i,j}, d_{i,j} \right)
Lδ=i=1∑Mj=1∑Nhuber(d^i,j,di,j)
其中,
d
^
i
,
j
\hat{d}_{i,j}
d^i,j 是位置
(
i
,
j
)
(i, j)
(i,j) 处的预测深度值,
d
i
,
j
d_{i,j}
di,j 是对应的真实值,
M
M
M 和
N
N
N 分别是重建图像的高度和宽度,通常取值为 5。Huber 损失函数能够为逐像素的重建误差提供一种鲁棒的度量,提高处理异常值的能力,从而实现更高精度的预测。
等式4中的
L
p
L_p
Lp表示边缘持久性损失,其定义为:
L
p
=
∑
i
=
1
M
∑
j
=
1
N
[
∣
g
v
(
d
^
i
,
j
)
−
g
v
(
d
i
,
j
)
∣
+
∣
g
h
(
d
^
i
,
j
)
−
g
h
(
d
i
,
j
)
∣
]
\mathcal{L}_{p} = \sum_{i=1}^{M} \sum_{j=1}^{N} \left[ \left| g_v(\hat{d}_{i,j}) - g_v(d_{i,j}) \right| + \left| g_h(\hat{d}_{i,j}) - g_h(d_{i,j}) \right| \right]
Lp=i=1∑Mj=1∑N[
gv(d^i,j)−gv(di,j)
+
gh(d^i,j)−gh(di,j)
]
其中,函数
g
v
g_v
gv 和
g
h
g_h
gh 分别用于计算深度图像的垂直和水平梯度。可以很容易理解,
L
p
\mathcal{L}_p
Lp 可用于保持重建深度图像与真实值之间的边界一致性,这对于边缘锐化、空间结构对齐以及其他后续视觉任务至关重要。Huber 损失
L
δ
\mathcal{L}_\delta
Lδ 和边缘保持损失
L
p
\mathcal{L}_p
Lp 的组合通过权重
λ
δ
\lambda_\delta
λδ 和
λ
p
\lambda_p
λp 共同加权,它们的设计目的是平衡对全局一致性和局部保真度的重视程度。
4. 实验
4.1数据集和评价指标
我们采用了流行的数据集,包括NYU-Depth V2、DIML和SUN RGB-D来进行所有的实验。
NYU-Depth是最常用的深度补全数据集,它包含了从464个不同的室内场景中收集到的1449个数据集。它可以作为一个基准来评估我们的模型和竞争的模型。我们将数据集随机分成420张图像用于训练,1029张图像用于测试。大小为640×480的原始图像被随机裁剪和调整大小到324×288。
DIML是一个最近发布的数据集,由 Kinect V2(室内)或 ZED 立体相机(室外)捕获的一系列 RGB-D 帧组成。除了典型的无效模式外,它还包含许多边缘阴影和不规则空洞,可用于评估模型对各种无效模式的适应能力。我们仅使用该数据集的室内部分,包括1609组用于训练,503组用于测试。原始图像尺寸为512 × 288,将随机裁剪并调整为320 × 192。
SUN RGB-D是一个大型数据集,它包含10,335个的RGB-D图像,由19个主要场景类别中的4个传感器捕获。作为模型泛化能力的测试。根据官方方案,我们使用了4845张图像进行训练,4659张图像进行测试。输入的大小为730×530的图像被随机裁剪,并调整大小为384×288。
Metrics采用了三个指标来评估深度补全结果:均方根误差(RMSE)、绝对相对误差(Rel),以及
δ
t
\delta_t
δt,即预测深度像素落入阈值范围内的百分比,阈值
t
t
t 为 1.10、1.25、1.25² 和 1.25³,用于更精细的评估。
4.2 消融实验
在本节中,我们将报告消融实验的结果,以分析我们提出的AGGNet框架的有效性。首先,对不同的管道方案上进行实验,验证我们的工作贡献,并为所提出的模型找到最佳方案。然后对一些重要的超参数进行了一系列的分析实验和优化。
设置我们的框架是在Pytorch中实现的,并使用SGD优化器进行训练。我们在训练和测试实验中都使用了批量大小为 8。初始学习率为
η
=
1
0
−
2
\eta = 10^{-2}
η=10−2,在达到平台期后下降到 30%,直到最小值
η
=
1
0
−
4
\eta = 10^{-4}
η=10−4。动量项设置为 0.95,权重衰减项为
1
0
−
4
10^{-4}
10−4。在参数消融研究中的模型设置为
m
=
3
,
k
=
3
,
r
=
1
m = 3, k = 3, r = 1
m=3,k=3,r=1,而在其他实验中的最佳设置为
m
=
4
,
k
=
3
,
r
=
4
m = 4, k = 3, r = 4
m=4,k=3,r=4。损失函数中的权重(见公式 4)经验设置为
λ
δ
=
0.7
,
λ
p
=
0.3
\lambda_\delta = 0.7, \lambda_p = 0.3
λδ=0.7,λp=0.3。所有对应的模型在 NYU-Depth v2 数据集上训练 120 个周期,并报告三个评估指标:RMSD、Rel 和
δ
t
\delta_t
δt。
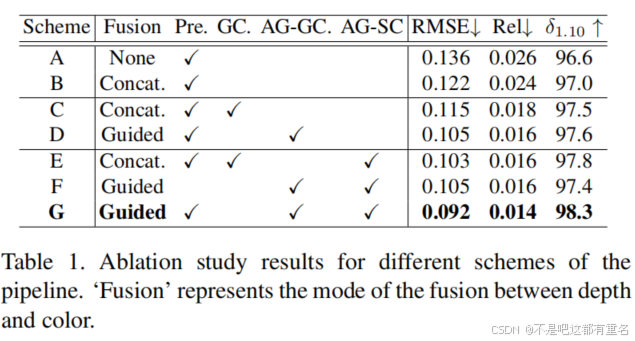
流程基准框架的流程采用类UNet的架构,只包含使用普通卷积和跳跃连接的深度分支(表1中的方案A)。随后,我们对基准模型和所提出模块的不同方案进行了一组消融实验。在方案B中,通过在每个编码器层直接拼接深度和颜色的特征张量来实现它们的融合。结果显示,添加颜色特征对深度补全有很大的帮助。方案C采用GConv和De-GConv模块代替普通卷积和反卷积,性能更好,因为门控信号有助于过滤掉不可靠的特征。在方案D中,我们将GConv替换为我们提出的AG-GConv。由于引入了上下文注意力,三个指标均显著提升。在方案E中,我们将颜色跳跃连接替换为我们提出的AG-SC模块,同时保留GConv和De-GConv模块。性能的提升证明了AG-SC模块的贡献。在方案F中,我们移除了预填充模块以研究其有效性。最后,在方案G中,我们将预填充、AG-GConv和AG-SC模块集成在一起,三个指标均达到最高分,证明了这三个模块都帮助模型提高了性能。
以上结果表明,提出的 AG-GConv 和 AG-SC 模块都对深度补全任务有所贡献。AG-GConv 相较于 GConv 的优势在于前者能够基于深度和颜色特征学习上下文注意力以生成门控信号,而后者仅使用带有局部注意力的深度特征。AG-SC 模块带来的改进表明,通过局部注意力净化颜色特征有助于深度图像的重建。此外,它们的结合可以进一步提升模型的最终性能。相比基准模型,最优方案的准确度显著提高,RMSE 和 Rel 值分别降低了约 32.4% 和 46.2%。根据结果,我们模型的最优方案是嵌入 AG-GConv 和 AG-SC 模块的双分支类似 UNet 的架构,如图2所示。
层编码器-解码器架构可以实现图像重建的多尺度特征提取,其尺度分布很大程度上取决于编码器和解码器的层数
m
m
m。如图6(a)所示,绘制了 RMSE、REL 和
δ
1.10
\delta_{1.10}
δ1.10 相对于不同层数
m
=
2
,
3
,
4
m = 2, 3, 4
m=2,3,4 和 5 的曲线。可以看到,所有三个指标在
m
=
4
m = 4
m=4 时达到饱和,因此
m
=
4
m = 4
m=4 被作为层数的默认设置。
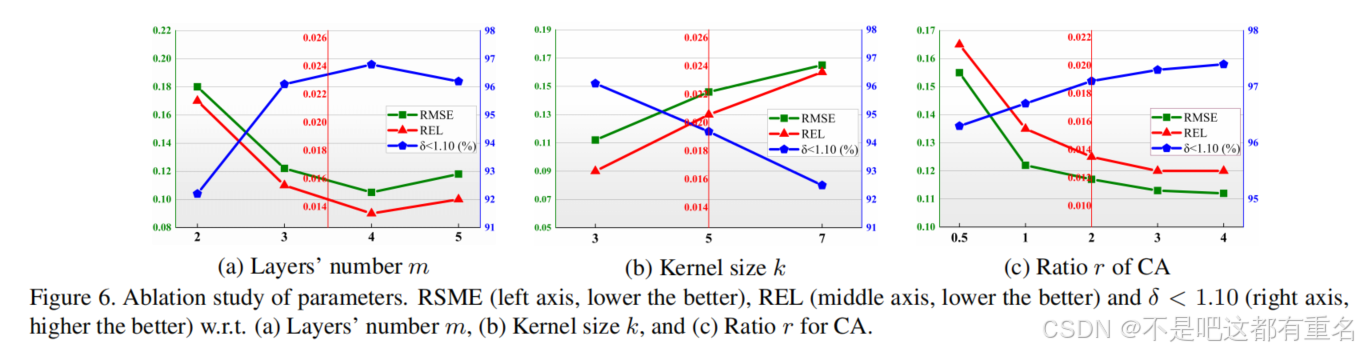
核大小卷积核的大小决定了神经元和门控信号的感受野,并对最终性能产生显著影响。如图6(b)所示,所有三个指标在
k
=
3
k = 3
k=3 时达到最佳。这是因为较大的感受野更可能包含无关的深度像素,尤其是在边界处。因此,我们为大多数卷积层设置卷积核大小
k
=
3
k = 3
k=3。
CA隐藏层上下文注意力模块(Contextual Attention module)中隐藏层神经元的数量显著影响了所提出的 AG-GConv 模块的能力。输入神经元与隐藏层神经元之间的比例
r
r
r 可以视为优化模型最终性能的重要参数。如图 6© 所示,绘制了三个指标相对于
r
=
2
,
3
,
4
,
5
r = 2, 3, 4, 5
r=2,3,4,5 的曲线,当比例增加到
r
=
4
r = 4
r=4 时性能达到饱和。这就是我们在 CA 模块中构建
4
×
H
×
W
4 \times H \times W
4×H×W 隐藏层神经元的原因。
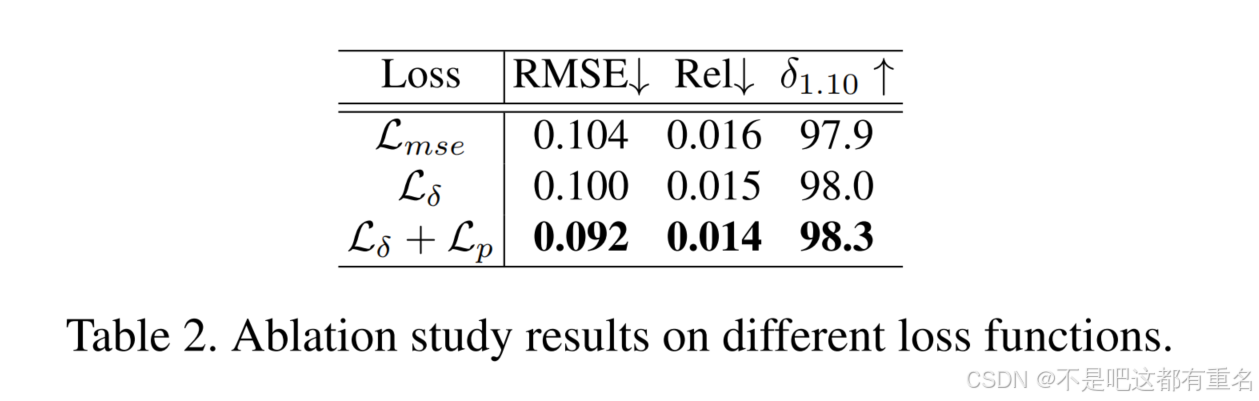
损失函数与基于均方误差(MSE)的传统重建损失不同,我们引入了 Huber 损失来适应重建深度图像中的异常像素,并提出了边缘保持损失,以强调不同表面的边界。如表2所示,Huber 损失相比 MSE 损失在所有三个指标上都有轻微的改进,而加入边缘保持损失则显著提升了性能。
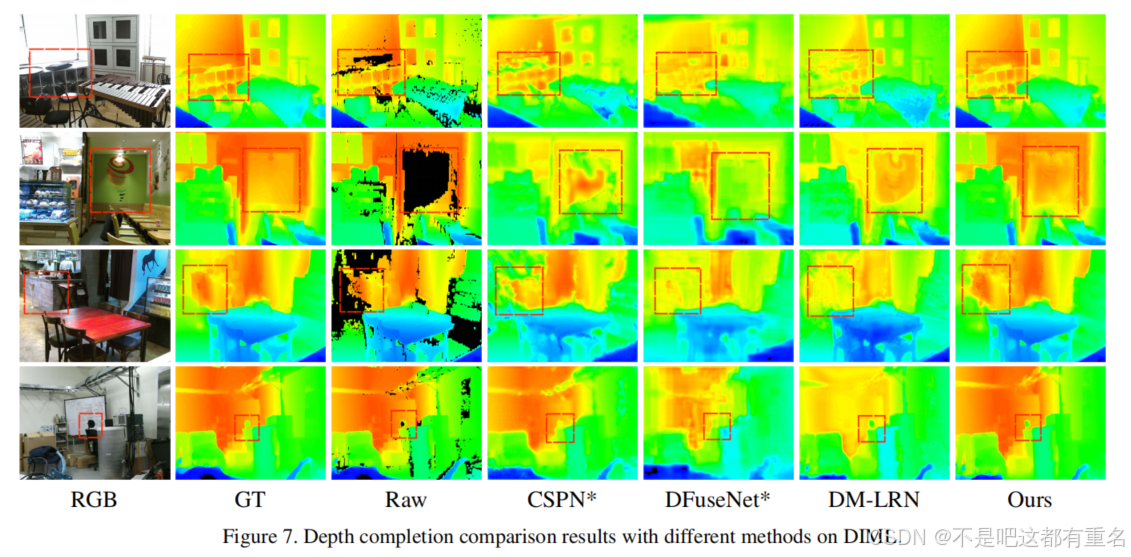
4.3与最先进技术的比较
为了验证我们提出的 AGG-Net 的性能,我们将其与经典的双边滤波方法【2】以及基于深度学习的各种最新的 SOTA 方法【18, 5, 25, 19, 28, 20】进行比较。我们的模型基于消融研究结果,按照最优方案和参数实现。竞争模型的性能测量值来自它们的原始论文,或通过在上述三个数据集上按照它们的默认设置应用模型得到。所有方法均基于原始深度图进行训练,并按照完全相同的协议进行测试。结果如表3所示。
在 NYU-Depth V2上在最流行的基准数据集 NYU-Depth V2 上,深度学习模型【18, 5, 25, 23, 28】明显优于传统的双边滤波方法【2】,因为深度学习在处理深度补全时比传统图像处理技术更为强大。在所有基于学习的方法中,我们的模型表现最佳,并在均方根误差(RMSE)上以显著的33.8%(0.092 对 0.139)优势领先于第二名。我们的模型在
δ
t
\delta_t
δt 指标上获得最高分,在阈值
t
=
1.2
5
3
t = 1.25^3
t=1.253 时达到了 100%。在相对误差(Rel)指标上,我们的模型几乎取得了最高分,仅比最高分低 0.001。鉴于 NYU-Depth V2 数据集是该领域中使用最广泛的基准,这些结果充分证明了我们的模型在平均性能上优于大多数现有的 SOTA 工作。我们提出的 AGG-Net 的整体优势来源于所提出的 AG-GConv 和 AG-SC 模块。
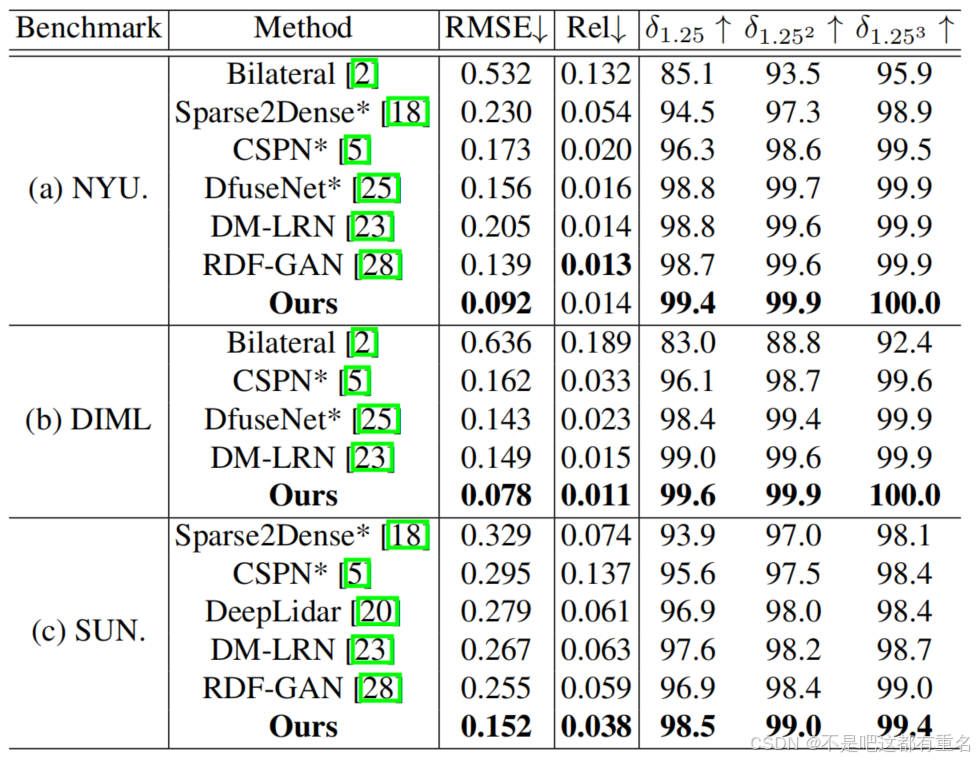
在 DIML上作为一个新数据集,DIML 的特点是包含一些新的无效区域模式,包括斑点块、边缘阴影和大面积不规则空洞。我们将模型与双边滤波法和其他三种最新的 SOTA 方法【5, 25, 23】在 DIML 数据集上使用相同的测试协议进行比较。结果表明,我们的模型在保持或扩大 RMSE 和
δ
t
\delta_t
δt 优势的同时,进一步提高了 Rel 指标分数。我们还在图 7 中展示了 DIML 数据集中的一些典型图像及其对应的补全结果。可以清楚地看到,尤其是在红框标记的部分,与其他竞争模型相比,我们的结果具有更生动的细节、更锐利的边缘以及与真实值(GT)更高的一致性,即使是那些具有大面积不规则空洞和密集斑点的非常具有挑战性的案例。这些结果表明,我们的模型对各种深度缺失模式具有更强的鲁棒性,这被认为得益于所提出的 AG-GConv 和 AG-SC 模块的更强学习能力。
在 SUN RGB-D上在大规模数据集 SUN RGB-D 上进行的实验旨在评估我们模型的泛化能力。如表3所示,我们的模型在所有指标上远远超越了其他 SOTA 方法。尤其是与排名第二的最新 SOTA 方法 RDF-GAN 相比,我们的模型将 RMSE 分数提升了 50%(0.128 对 0.256),相对误差(Rel)分数提升了约 40%(0.035 对 0.059)。这被认为是因为多尺度架构、深度与颜色的融合、AG-GConv 中的全局上下文注意力以及 AG-SC 模块的局部注意力共同增强了我们模型在各种场景中的泛化能力。
以上实验结果表明,该方法为深度补全提供了一个新的强基线。所提出的架构、AG-GConv和AG-SC模块对AGG-Net模型的推广做出了重大贡献,并使其在流行的基准测试和指标上优于大多数现有的深度补全方法。
5. 结论
我们提出的注意力引导门控卷积网络(AGG-Net)为深度补全任务提供了一个更加稳健的基准模型。它在双分支的类似UNet的架构中,嵌入了所提出的 AG-GConv 和 AG-SC 模块,兼顾特征提取和深度重建。所提出的 AG-GConv 通过学习全局上下文注意力来调节深度和颜色特征的融合。此外,所提出的 AG-SC 通过突出重要的颜色特征并抑制与深度无关的特征,促进了深度重建。实验结果表明,我们提出的 AGG-Net 在常用基准数据集 NYU-Depth V2、DIML 和 SUN RGB-D 上优于当前最先进的方法。


















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











