








本专栏将由浅入深的展开诊断实际开发与测试的数据库编辑,包含大量实际开发过程中的步骤、使用技巧与少量对Autosar标准的解读。希望能对大家有所帮助,与大家共同成长,早日成为一名车载诊断、通信全栈工程师。
本文介绍CDD在诊断开发中的作用,欢迎各位朋友订阅、评论,可以提出宝贵意见,以持续输出更好的作品,同时会根据评论、私信不定期更新文章内容,以及专栏目录。订阅该专栏的朋友可私信小编免费答疑解惑(^U^)ノ~YO
CANdelaStudio-从入门到深入目录
文章目录
1、通信数据库DBC文件
在通信领域大家耳熟能详的是CAN矩阵表衍生而来的dbc文件,也叫通信数据库。dbc(data base CAN)描述了单一CAN网络各节点信息,通过dbc文件可以监测和分析CAN总线上各个节点的运行状态。
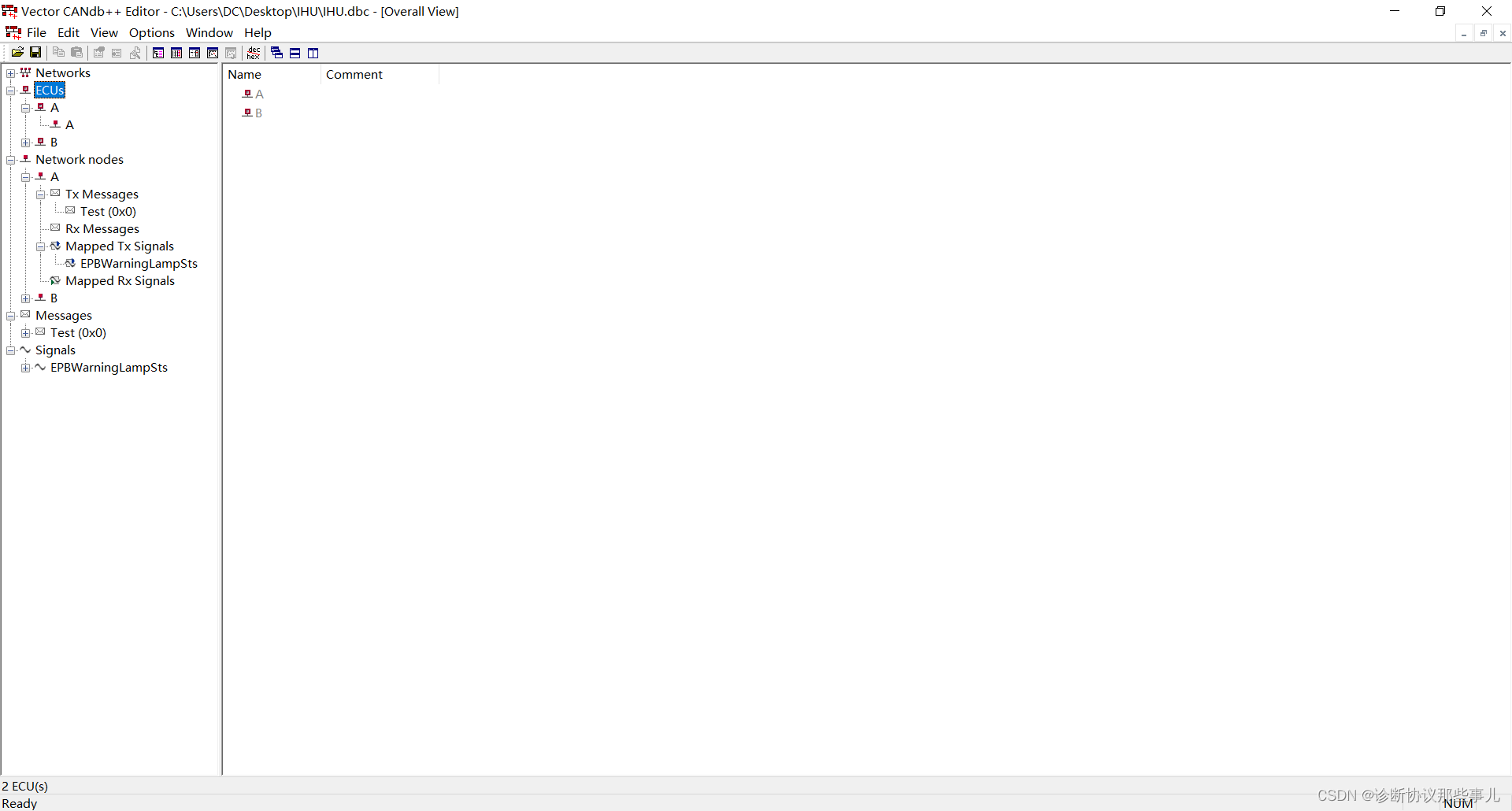
整车厂在研发新款车型时,会先确定网络中的Nodes、Messages、Signals,发布CAN矩阵表(Excel文件),这时可以通过CANdb++ Editor编辑,界面如下图,最终生成dbc文件。
诊断报文相关属性:
| AttributeName | 描述 |
|---|---|
| DiagState | 功能寻址请求报文,该项设置为Yes |
| DiagRequest | 物理寻址请求报文,该项设置为Yes |
| DiagResponse | 物理寻址响应报文,该项设置为Yes |
详情可查看:DBC概述
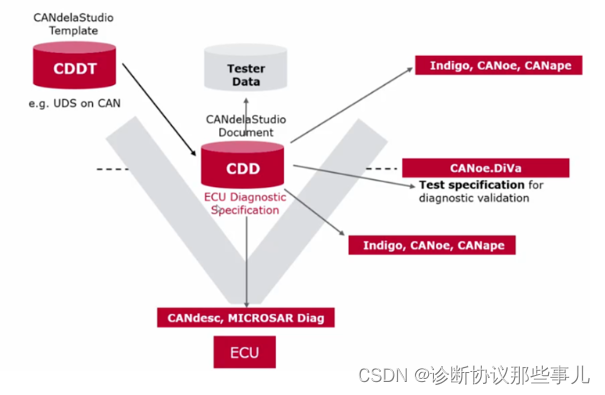
2、诊断数据库CDD
CDD是Vector标准数据库文件,全称为CANdela Diagnostic Description。通过CANdelaStudio工具编辑生成,描述了诊断应用的范围和数据格式,其作用贯穿整个开发V模型。
3、诊断开发V模型
3.1 传统的诊断开发流程
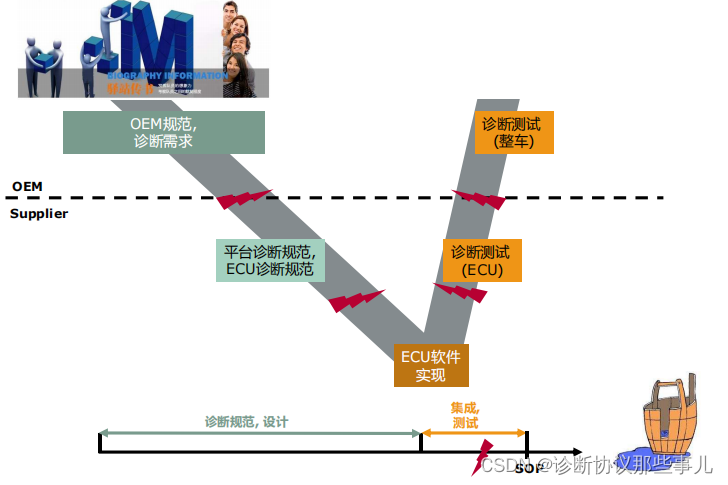
传统的诊断开发流程中,诊断数据的交互都是使用机器不可读的格式文件,比如Excel、word、pdf等,在整个开发流程中会涉及整车厂、系统供应商,不同的公司、不同的部门,每个工程师根据自己的经验对于同一份诊断需求文件的解读有很大可能产生偏差。
比如开发工程师和测试工程师对同一句话的理解不同,则会导致测试不通过,然后又需要重新回到需求定义的阶段去完善或者解释这条需求,从而导致需求定义的时间过长,致使整个开发周期延长。
3.2 基于数据库的Vector诊断解决方案
基于上述问题,Vector提出一种以机器可读的诊断数据库为核心的诊断开发全流程解决方案,不依赖经验,保证整个开发阶段的数据的一致性,同时有一些强制约束来保证有效性。在车载系统开发V模型中,CDD贯穿全流程,可以有效解决Excel、doc文本文档的错误解读、保证了诊断数据的一致性。
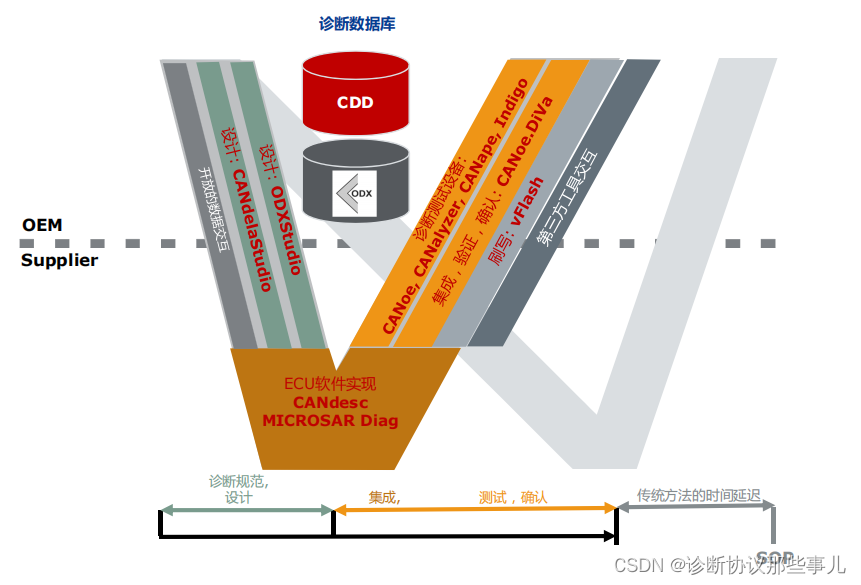
①在V模型左侧是需求侧:基于车型、项目需求,提出该ECU的诊断需求规范(服务、通信参数、DTC、DID、NRC等),并释放给供应商;
②在V模型底部是ECU诊断功能开发:Vector有CANdesc和MICROSAR两种解决方案(目前主流基于Autosar的Microsar diag软件架构解决方案,使用达芬奇配置工具,通过加载诊断数据库、通信数据库生成对应的诊断协议栈);
③在V模型右侧是测试侧:功能实现后,需要对功能进行检测,验证功能是否按照需求规范定义去实现。可以通过加载诊断数据库自动生成诊断测试用例并自动化执行,最终生成测试报告。
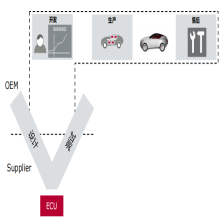
4、V-L模型
在汽车电子行业中,通常主机厂OEM会对供应商提出诊断需求规范,供应商基于其规范实现软件的功能,在功能实现后,再进行集成测试,以确认其功能是否满足需求规范的要求,这也是我们常说的V-L模型。
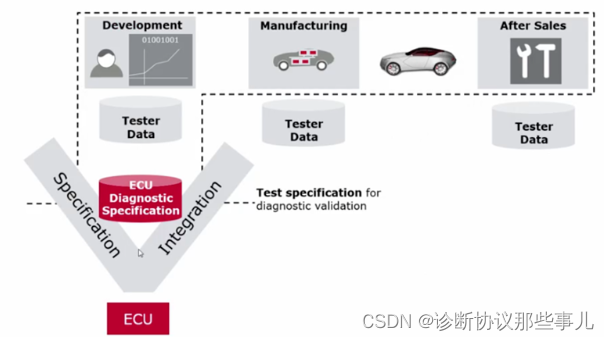
“V”是指开发阶段从需求定义(系统、架构、单元)到软件实现(Autosar、非Autosar),再到测试验证(单元验证、集成验证);
“L”是指生产售后阶段;
在研发、量产及售后阶段,使用的诊断需求规范都是一致的。
5、CANdelaStudio
主要特征:
①工具可读的数据库
②简洁的、用户友好的诊断数据描述
③数据库模板提高数据库创建效率和质量
④用户导向的界面,易用性高
⑤快速生成符合标准的ODX文件,支持的ODX格式:2.0.1、2.1.0和2.2.0
















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











