







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言

本文回顾了论文“Grounding DINO 1.5: Advance the ‘Edge’ of Open-Set Object Detection”中介绍的进展。我们将探讨所引入的方法,对开放集目标检测的影响,以及这项研究提出的潜在应用和未来方向。
近年来,零样本目标检测已成为计算机视觉进步的基石。创建多功能且高效的探测器一直是构建实际应用的重要焦点。IDEA Research 推出的 Grounding DINO 1.5 标志着该领域的重大飞跃,尤其是在开放式物体检测方面。
什么是GroundingDINO?
基于DINO的开放式检测器Grounding DINO不仅实现了最先进的物体检测性能,还通过Grounding预训练实现了多级文本信息的集成。与 GLIP 或接地语言图像预训练相比,GroundingDINO 具有多项优势。首先,其基于Transformer的架构,类似于语言模型,便于处理图像和语言数据。
GroundingDINO框架
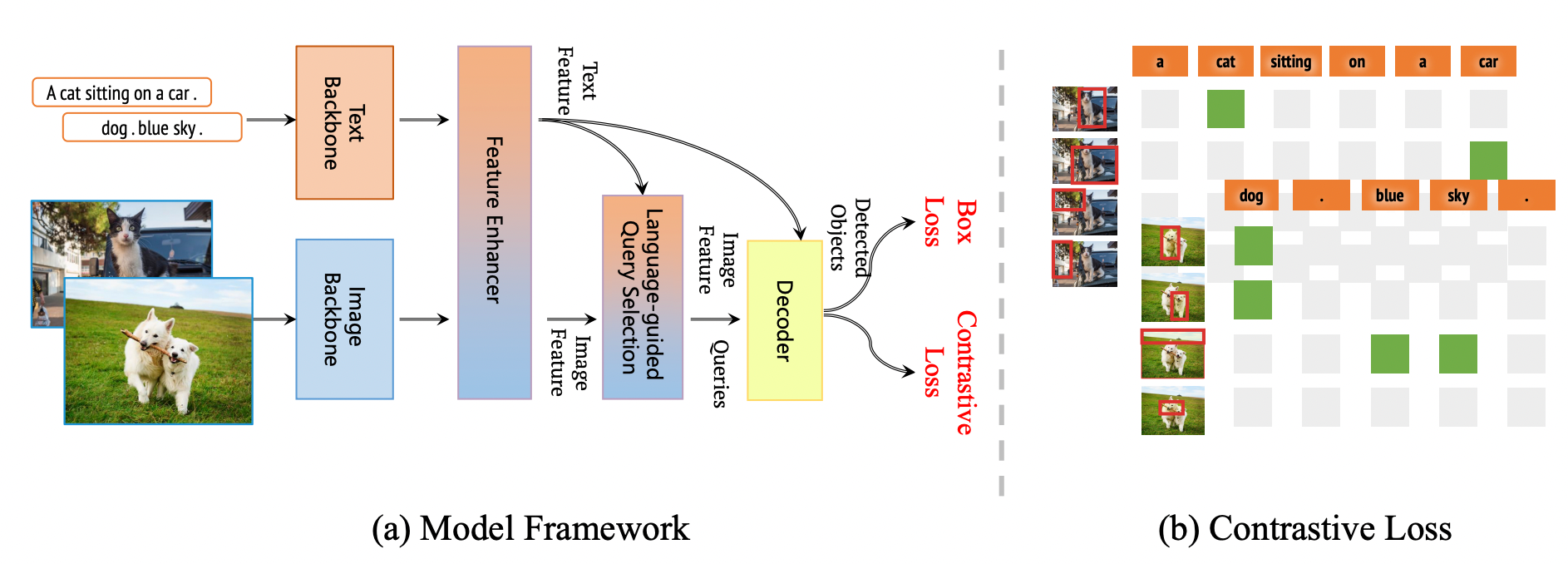
上图所示的框架是GroundingDINO 1.5 系列的整体框架。该框架保留了 Grounding DINO 的双编码器-单解码器结构。此外,该框架将其扩展到 Pro 和 Edge 型号的 Grounding DINO 1.5。
GroundingDINO 结合了 DINO 和 GLIP 的概念。DINO 是一种基于 Transformer 的方法,在对象检测方面表现出色,具有端到端优化功能,无需手动制作模块,如非最大抑制或 NMS。相反,GLIP 专注于短语基础,将文本中的单词或短语与图像或视频中的视觉元素联系起来。
GroundingDINO 的架构包括一个图像主干、一个文本主干、一个用于图像-文本融合的功能增强器、一个语言引导的查询选择模块和一个用于优化对象框的跨模态解码器。最初,它提取图像和文本特征,融合它们,从图像特征中选择查询,并在解码器中使用这些查询来预测对象框和相应的短语。
Grounding DINO 1.5 新功能
Grounding DINO 1.5 建立在其前身 Grounding DINO 奠定的基础之上,后者通过整合语言信息并将任务构建为短语接地来重新定义对象检测。这种创新方法利用了对不同数据集的大规模预训练,以及对来自大量图像-文本对的伪标记数据的自我训练。其结果是一个在开放世界场景中表现出色的模型,因为它具有强大的架构和语义丰富性。
GroundingDINO 1.5 进一步扩展了这些功能,引入了两种专用型号:Grounding DINO 1.5 Pro 和Grounding DINO 1.5 Edge。Pro 模型通过显着扩展模型的容量和数据集大小、整合 ViT-L 等高级架构并生成超过 2000 万张带注释的图像来增强检测性能。相比之下,边缘模型针对边缘设备进行了优化,强调计算效率,同时通过高级图像特征保持高检测质量。
实验结果强调了 Grounding DINO 1.5 的有效性,Pro 型号设定了新的性能标准,而 Edge 型号展示了令人印象深刻的速度和准确性,使其非常适合边缘计算应用。本文深入探讨了 Grounding DINO 1.5 带来的进步,探讨了其在开放式物体检测动态环境中的方法、影响和潜在的未来方向,从而突出了其在实际场景中的实际应用。
Grounding DINO 1.5 在 Grounding-20M 上进行了预训练,Grounding-20M 是一个包含来自公共来源的超过 2000 万张接地图像的数据集。在训练过程中,确保了具有完善的注释管道和后处理规则的高质量注释。
性能分析
下图显示了该模型识别 COCO 和 LVIS 等数据集中对象的能力,这些数据集包含许多类别。这表明 Grounding DINO 1.5 Pro 的性能明显优于以前的版本。与之前的特定型号相比,GroundingDINO 1.5 Pro显示出显着的改进。
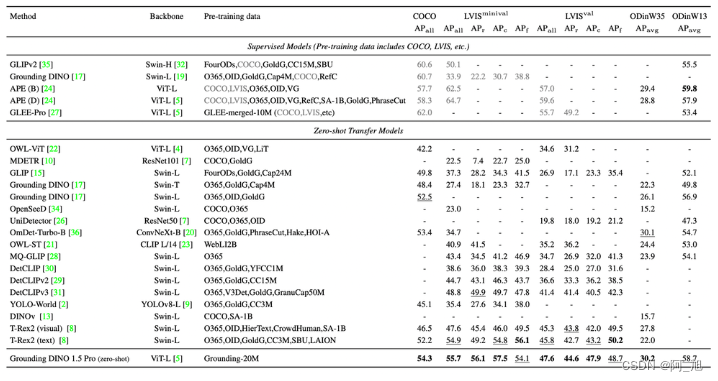
该模型使用 ODinW(野外目标检测)基准测试在各种实际场景中进行了测试,其中包括涵盖不同应用的 35 个数据集。与之前版本的 Grounding DINO 相比,Grounding DINO 1.5 Pro 的性能有了显着提高。
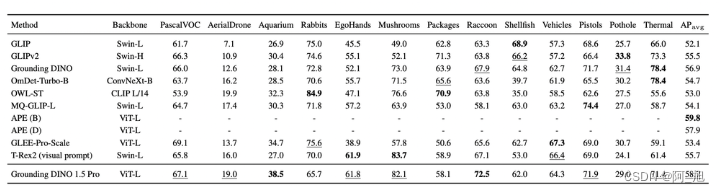
COCO 和 LVIS 上GroundingDINO1.5 Edge 的零拍摄结果使用 A100 GPU 以每秒帧数 (FPS) 为单位进行测量,以 PyTorch 速度/TensorRT FP32 速度报告。还提供 NVIDIA Orin NX 上的 FPS。GroundingDINO 1.5 Edge 实现了卓越的性能,也超越了所有其他最先进的算法(OmDet-Turbo-T 30.3 AP、YOLO-Worldv2-L 32.9 AP、YOLO-Worldv2-M 30.0 AP、YOLO-Worldv2-S 22.7 AP)。
GroundingDINO1.5 Pro 与GroundingDINO 1.5 Edge
GroundingDINO1.5 Pro
Grounding DINO 1.5 Pro 建立在 Grounding DINO 的核心架构之上,但通过更大的 Vision Transformer (ViT-L) 主干增强了模型架构。ViT-L 模型以其在各种任务中的卓越性能而闻名,基于 transformer 的设计有助于优化训练和推理。
Grounding DINO 1.5 Pro 采用的关键方法之一是用于特征提取的深度早期融合策略。这意味着在进入解码阶段之前,在特征提取过程中使用交叉注意力机制将语言和图像特征尽早组合在一起。这种早期整合可以更彻底地融合来自两种模式的信息。
在他们的研究中,该团队比较了早期核聚变与后期核聚变策略。在早期融合中,语言和图像特征在过程的早期被集成,从而实现更高的检测召回率和更准确的边界框预测。但是,这种方法有时会导致模型产生幻觉,这意味着它会预测图像中不存在的对象。
另一方面,后期融合将语言和图像特征分开,直到损失计算阶段,它们被整合。这种方法通常对幻觉更有力,但往往会导致较低的检测回忆,因为当视觉和语言特征仅在最后组合时,它们变得更具挑战性。
为了最大限度地发挥早期融合的优势,同时最大限度地减少其缺点,Grounding DINO 1.5 Pro 保留了早期融合设计,但采用了更全面的训练采样策略。这种策略增加了训练期间负样本(没有感兴趣对象的图像)的比例。通过这样做,该模型可以更好地区分相关和不相关的信息,从而减少幻觉,同时保持高检测召回率和准确性。
总之,Grounding DINO 1.5 Pro 通过将早期融合与改进的训练方法相结合,平衡了早期融合架构的优势和劣势,从而增强了其预测能力和鲁棒性。
GroundingDINO1.5 Edge
GroundingDINO 是检测图像中物体的强大模型,但它需要大量的计算能力。这使得在资源有限的小型设备(如汽车、医疗设备或智能手机中的设备)上使用具有挑战性。这些设备需要快速有效地实时处理图像。
在边缘设备上部署GroundingDINO对于许多应用(例如自动驾驶、医学图像处理和计算摄影)来说是非常理想的。
然而,开放式检测模型通常需要大量的计算资源,而边缘设备缺乏这些资源。最初的GroundingDINO模型使用多尺度图像特征和计算密集型特征增强器。虽然这提高了训练速度和性能,但对于边缘设备上的实时应用程序来说是不切实际的。
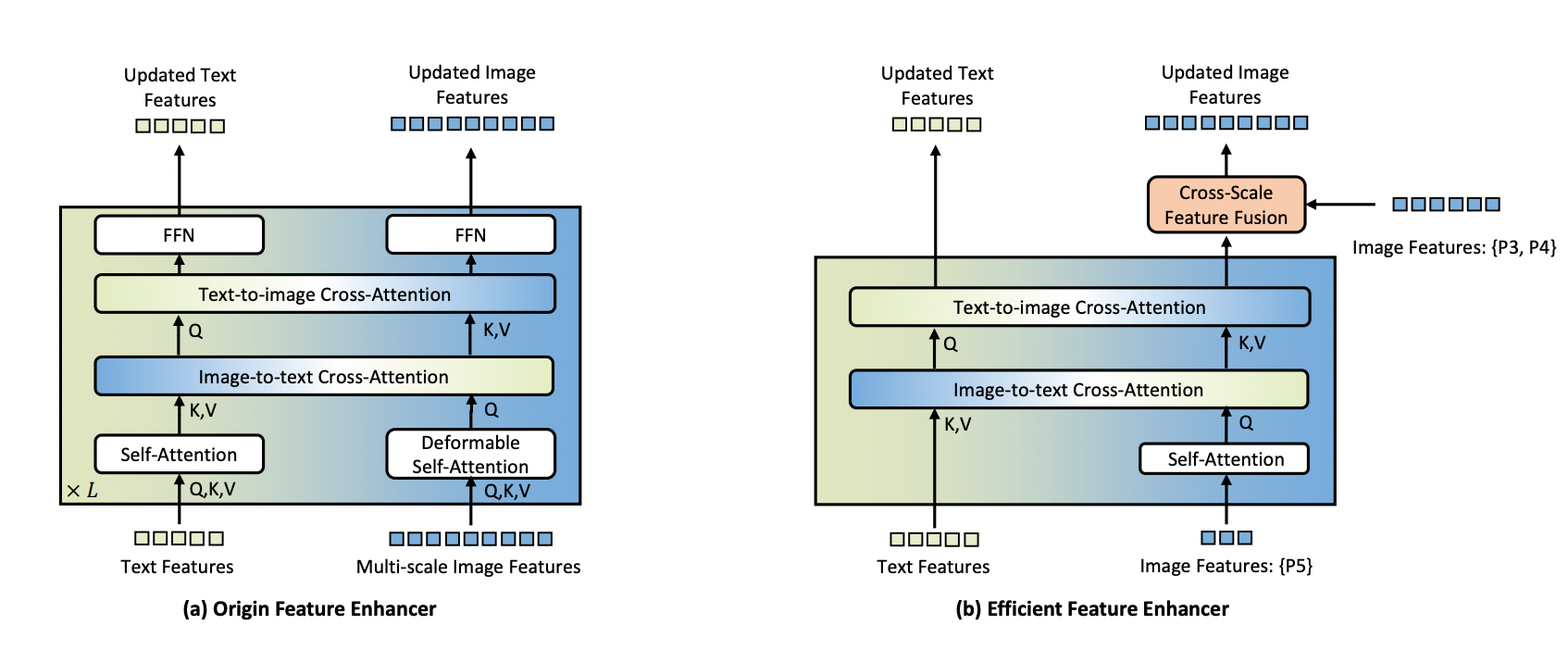
为了应对这一挑战,研究人员提出了一种用于边缘设备的高效功能增强器。他们的方法侧重于仅使用高级图像特征(P5 级别)进行跨模态融合,因为较低级别的特征缺乏语义信息并增加计算成本。这种方法大大减少了处理的令牌数量,从而减少了计算负载。
为了更好地集成在边缘设备上,该模型将可变形的自注意力替换为普通的自注意力,并引入了跨尺度特征融合模块来集成较低级别的图像特征(P3 和 P4 级别)。这种设计平衡了功能增强的需求和计算效率的需求。
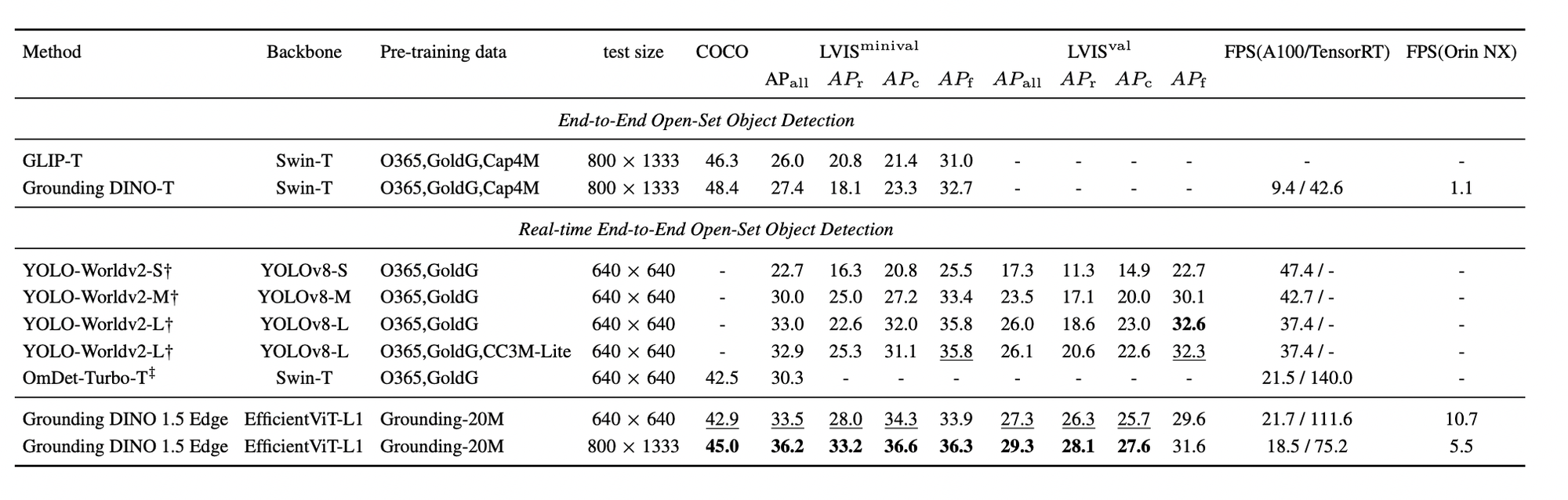
在 Grounding DINO 1.5 Edge 中,原来的特征增强器被这种新的高效增强器所取代,而 EfficientViT-L1 被用作快速多尺度特征提取的图像骨干。当部署在 NVIDIA Orin NX 平台上时,此优化模型的推理速度超过 10 FPS,输入大小为 640 × 640。这使得它适用于边缘设备上的实时应用程序,从而平衡性能和效率。
Origin Feature Enhancer 和 New Efficient Feature Enhancer 之间的比较:
NVIDIA Orin NX 上的 Grounding DINO 1.5 Edge 可视化功能显示在屏幕左上角的 FPS 和提示。右上角显示了录制场景的摄像机视图。

GroundingDINO目标检测演示
首先,我们将克隆存储库:
!git clone https://github.com/IDEA-Research/Grounding-DINO-1.5-API.git
接下来,我们将安装所需的软件包:
!pip install -v -e .
运行以下代码以生成链接:
!python gradio_app.py --token ad6dbcxxxxxxxxxx
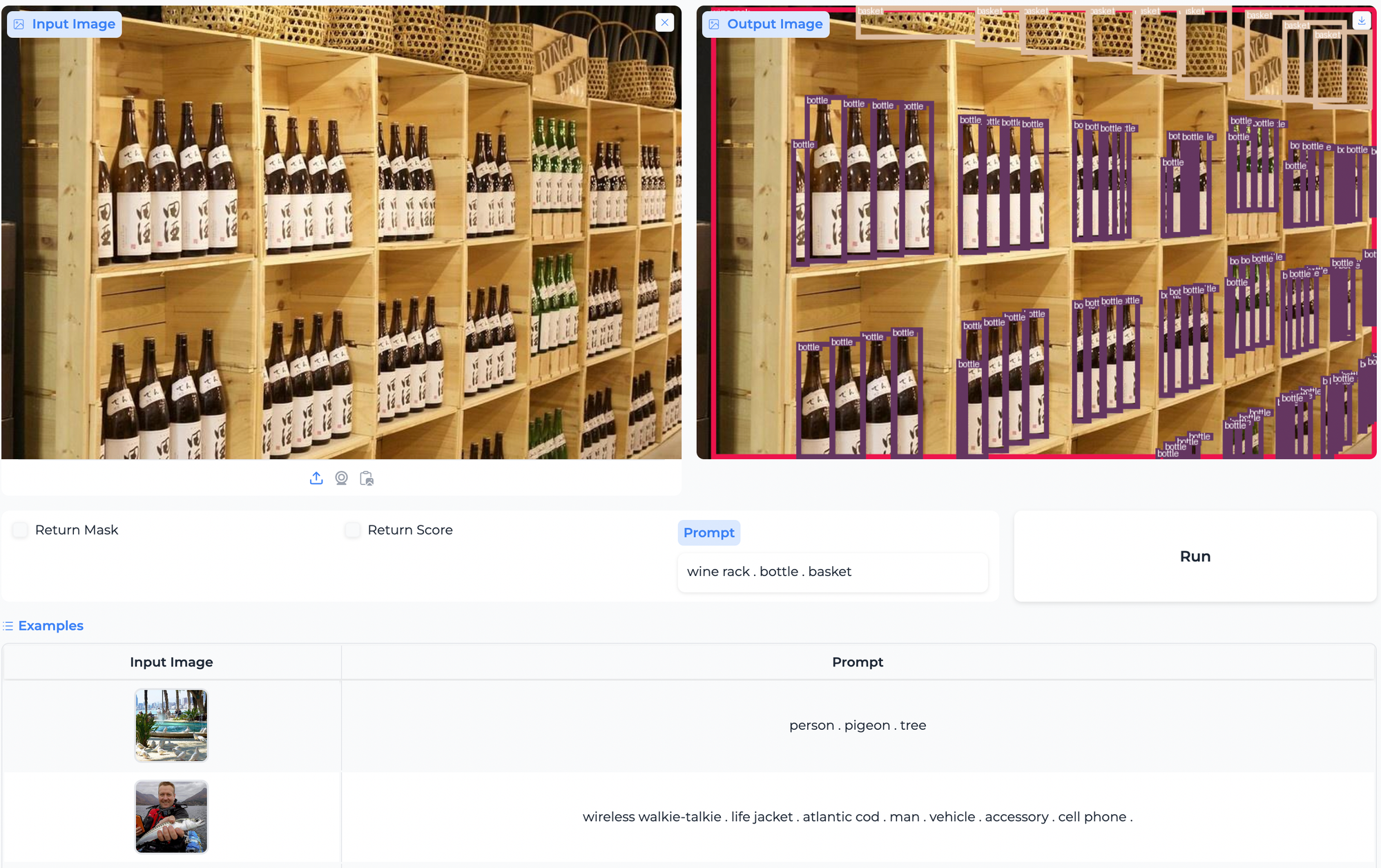
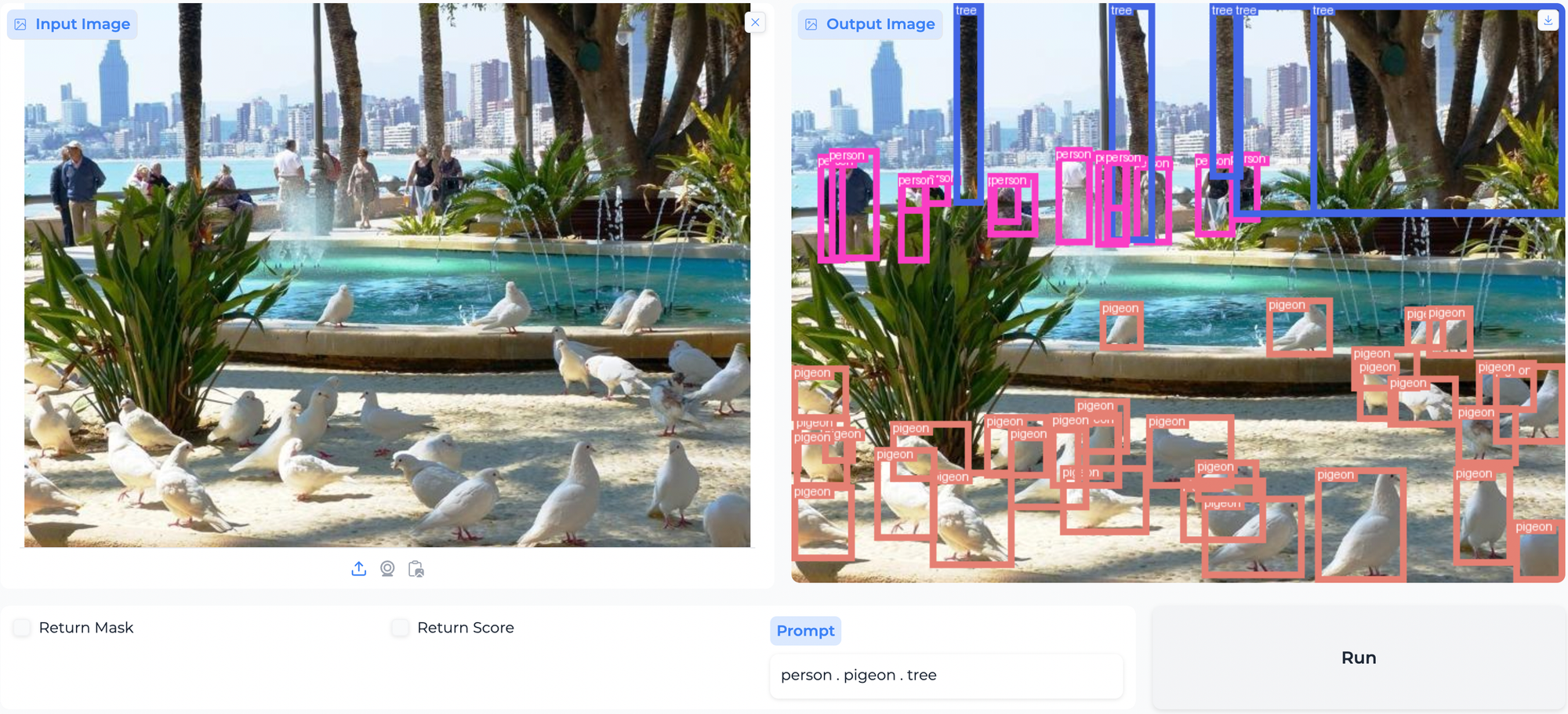
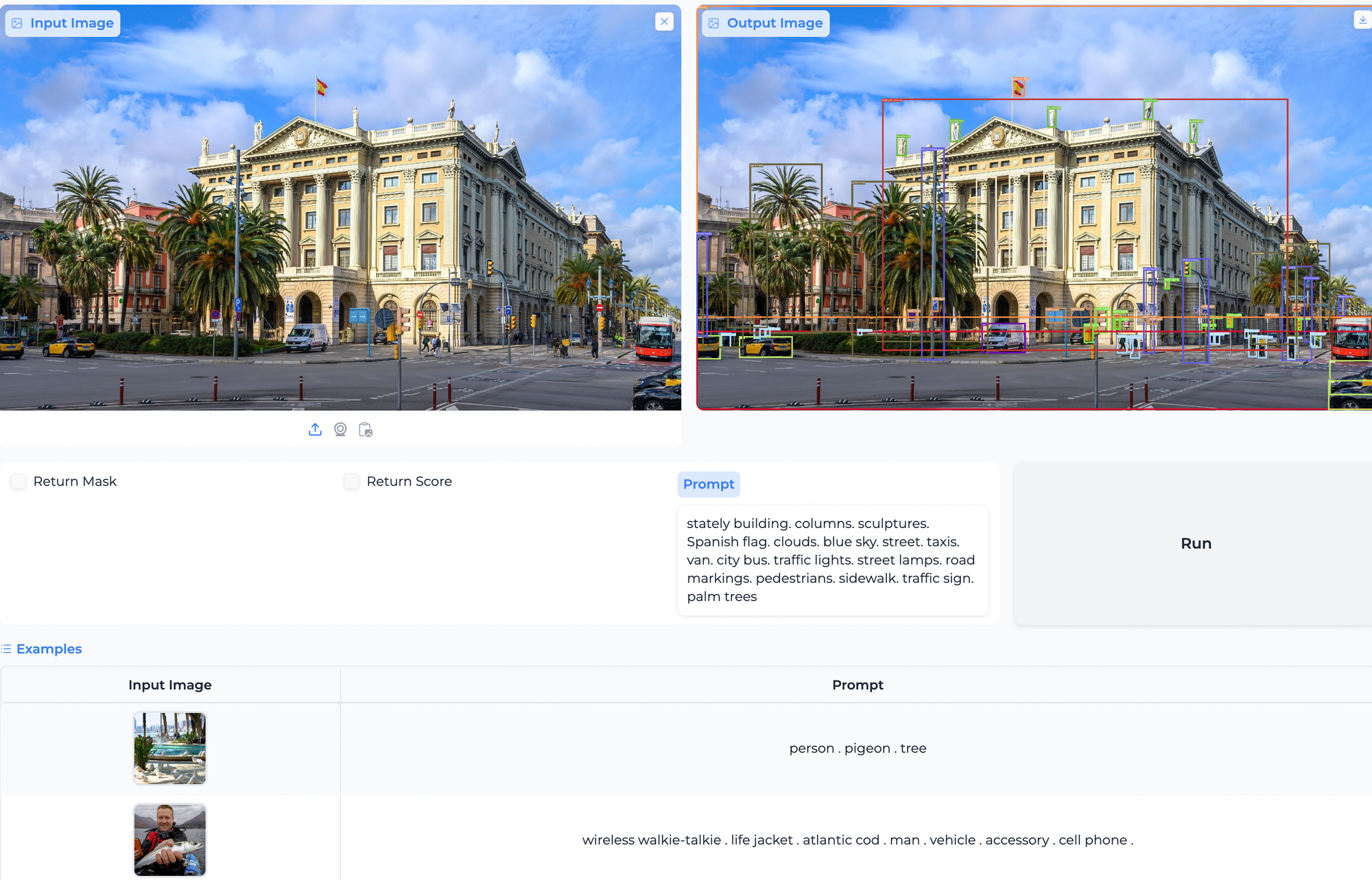
GroundingDINO1.5应用领域
自动驾驶汽车:
- 检测和识别道路上可能出现的已知交通标志和行人以及不熟悉的物体,确保更安全的导航。
- 识别训练数据中未预先标记的意外障碍物,例如碎片或动物。
监控和安全:
- 识别禁区内未经授权的个人或物体,即使他们以前从未见过。
- 在机场或火车站等公共场所检测废弃物体可能是潜在的安全威胁。
零售和库存管理:
- 识别和跟踪商店货架上的商品,包括可能不属于原始库存的新产品。
- 识别商店中可能表明入店行窃的异常活动或不熟悉的物品。
医疗:
- 检测医学扫描中的异常或不熟悉的模式,例如新型肿瘤或罕见病症。
- 识别患者的异常行为或动作,尤其是在长期护理或术后恢复中。
机器人:
- 通过识别和适应新物体或周围环境的变化,使机器人能够在动态和非结构化环境中运行。
- 在环境不可预测且充满陌生物体的受灾地区检测受害者或危险。
野生动物监测和保护:
- 在自然栖息地中发现和识别新的或稀有物种,以进行生物多样性研究和保护工作。
- 监测保护区是否有不熟悉的人类存在或可能表明非法偷猎活动的工具。
制造和质量控制:
- 识别生产线上产品中的缺陷或异常,包括以前未遇到的新型缺陷。
- 识别和分类各种物体,以提高制造过程的效率。
本文介绍了 Grounding DINO 1.5,旨在增强开放式物体检测。领先的型号 Grounding DINO 1.5 Pro 在 COCO 和 LVIS 零射测试中树立了新的标杆,标志着检测准确性和可靠性的重大进步。
好了,这篇文章就介绍到这里,感谢点赞关注,更多精彩内容持续更新中~


















 5486
5486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











