






一、 监督沟通基础内容
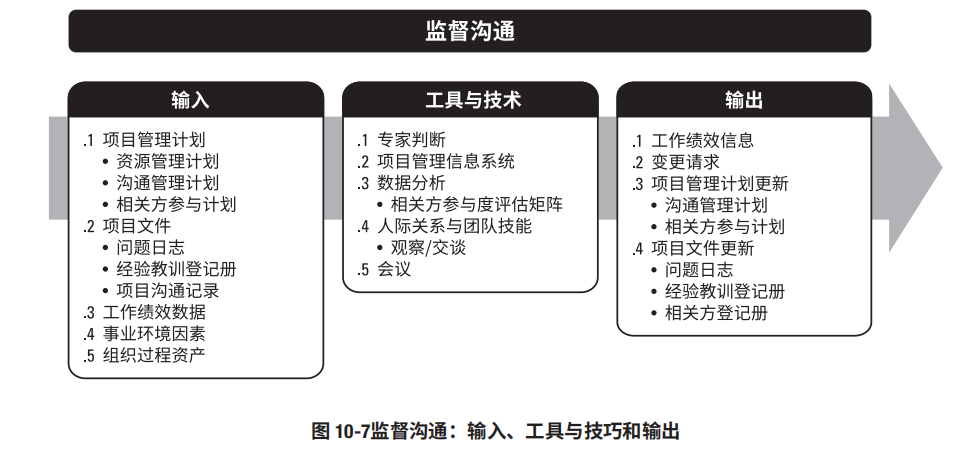
0. 涉及领域:
(1)资源管理计划
通过描述角色和职责,以及项目组织结构图,资源管理计划可用于理解实际的项目组织及其任何变更。
(2)沟通管理计划
沟通管理计划是关于及时收集、生成和发布信息的现行计划,它确定了沟通过程中的团队成员、相关方和有关工作。
(3)相关方参与计划
相关方参与计划确定了计划用以引导相关方参与的沟通策略.
1. 监督沟通阶段需参照文档
(1)问题日志
问题日志提供
<1> 项目的历史信息
<2> 相关方参与问题的记录
<3> 它们如何得以解决
(2)经验教训登记册
在项目早期获取的经验教训可用于项目后期阶段,以改进沟通效果。
(3)项目沟通记录
提供关于已开展的沟通的信息。
2. 监督沟通的定义
监督沟通是确保满足项目及其相关方的信息需求的过程。
3. 监督沟通的作用
本过程的主要作用是,按沟通管理计划和相关方参与计划的要求开展高效的信息传递。
4. 监督沟通的执行时间
本过程需要在整个项目期间开展。
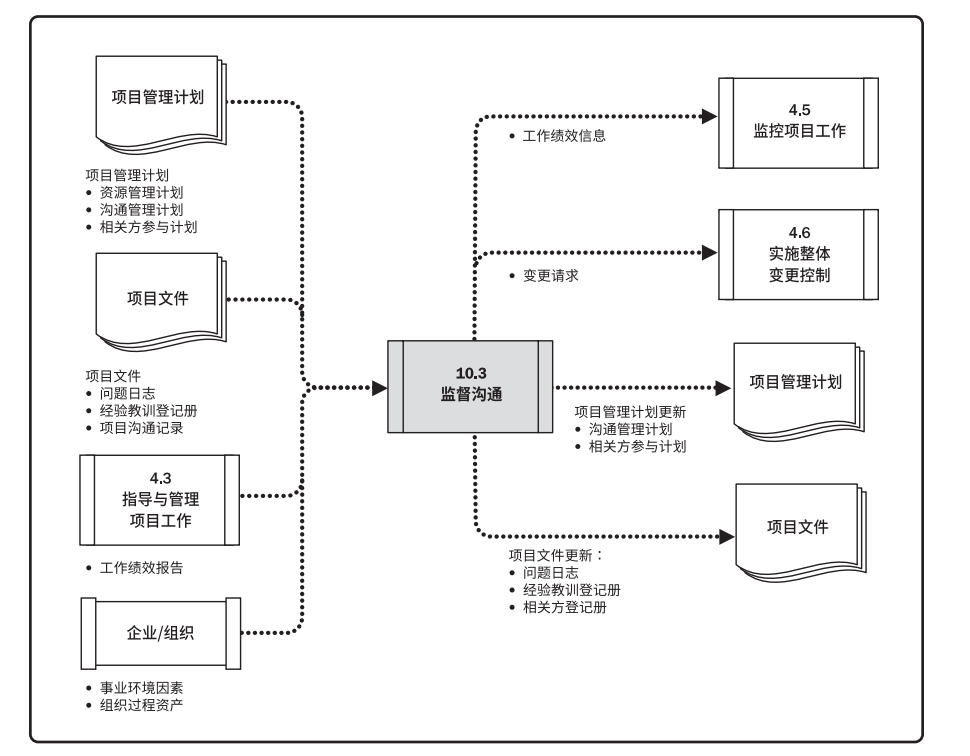
5. 监督沟通阶段可影响的领域/文件
领域
(1)沟通管理计划
需要更新沟通管理计划,记录能够让沟通更有效的新信息。
(2)相关方参与计划
需要更新相关方参与计划,反映相关方的实际情况、沟通需求和重要性。
文件
(1)问题日志
可能需要更新问题日志,记录与出现的问题及其处理进展和解决办法相关的新信息。
(2)经验教训登记册
可能需要更新经验教训登记册,记录问题的 <1> 原因 <2> 所选纠正措施的理由 <3> 其他与沟通有关的经验教训
(3)相关方登记册
可能需要更新相关方登记册,加入修订的相关方沟通要求。
二、沟通触发的变化与触发沟通更新的条件--执行时间
1. 监督沟通过程可能触发规划沟通管理和(或)管理沟通过程的迭代,以便修改沟通计划并开展额外的沟通活动,来提升沟通的效果。
2. 问题、关键绩效指标、风险或冲突,都可能立即触发重新开展规划和管理沟通过程。
三、监督沟通与规划沟通
通过监督沟通过程,来确定规划的沟通工件和沟通活动 。
1. 是否如预期提高或保持了相关方对项目可交付成果与预计结果的支持力度。
2. 项目沟通的影响和结果应该接受认真的评估和监督,以确保在
(1) 正确的时间
(2) 通过正确的渠道
(3) 将正确的内容(发送方和接收方对其理解一致)
(4) 传递给正确的受众
四、监督沟通方法**
1. 开展客户满意度调查
2. 整理经验教训
3. 开展团队观察
4. 审查问题日志中的数据
5. 评估相关方参与度评估矩阵中的变更。
五、 监督沟通过程
(一)输入-工作绩效报告
工作绩效数据包含关于实际已开展的沟通类型和数量的数据。
(二)工具与技术
1. 专家判断(关注点/会议点/讨论点)
(1)与公众、社区和媒体的沟通
(2)在国际环境中的沟通
(3)虚拟小组之间的沟通
(4)沟通和项目管理系统
2. 项目管理信息系统(PMIS)
项目管理信息系统为项目经理提供一系列标准化工具,以根据沟通计划为内部和外部的相关方
(1)收集、储存与发布所需的信息
(4)并监控该系统中的信息以评估其有效性和效果
3. 数据表现--相关方参与度评估矩阵
适用监督沟通的数据表现技术包括(但不限于):相关方参与度评估矩阵
它可以提供与沟通活动效果有关的信息。
应该检查相关方的期望与当前参与度的变化情况,并对沟通进行必要调整。
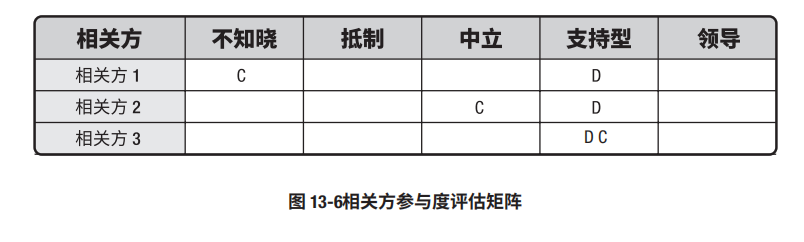
相关方参与度评估矩阵详见:https://www.cnblogs.com/hemukg/p/17438312.html
4. 人际关系与团队技能--观察和交谈
适用于教案都沟通过程的人际关系与团队技能包括(但不限于):观察和交谈。
与项目团队展开讨论和对话,有助于
(1)确定最合适的方法,用于更新和沟通项目绩效
(2)回应相关方的信息请求
(3)项目经理能够发现团队内的问题、人员间的冲突,或个人绩效问题
详见:https://www.cnblogs.com/hemukg/p/12579722.html
5. 会议
面对面或虚拟会议适用于制定决策,回应相关方请求,与提供方、供应方及其他项目相关方讨论
(三)输出
1. 工作绩效信息(对沟通的反馈)
工作绩效信息包括与计划相比较的沟通的实际开展情况(关于沟通效果的调查结果)。
2. 变更请求
监督沟通过程往往会导致需要对沟通管理计划所定义的沟通活动进行调整、采取行动和进行干预。
变更请求需要通过实施整体变更控制过程进行处理。
监督沟通 的变更请求可能导致:
(1)修正相关方的沟通要求
相关方对信息发布<1> 内容<2> 形式<3 >方式 的要求。
(2)建立消除瓶颈的新程序
#############################################
相关方参与度评估矩阵是个比较好用的工具,我们一般判断人基本都是主观的,通过相关方参与度评估矩阵,可以更加客观的分析人员的信息。
愿各位在进步中安心!
2024.02.01 禾木
#############################################
















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











