






Demand——Dynamic User Assignment
浅读一下Demand Dynamic User Assignment的文档,主要是了解sumo中DTA的基本原理,以及输入输出,其他细节自动忽略。下面上原地址:
https://sumo.dlr.de/docs/Demand/Dynamic_User_Assignment.html
1 Introduction
sumo在定义车流时生成所有od对。最简单的方法就是计算最短路,比如广度优先的dijkstra和启发式的A*。但这些算法需要很多的关于行程时间的强假设,但这些假设实际上在仿真前是存在很多的不确定因素的。
Caution
在交通仿真中存在一个非常常见的问题:车辆以原先生成的最短路径去行驶的情况下,经常会遇到交通瓶颈,然后被堵在路上。
怎么把用户以合理的路径分配到路网上,这个问题叫做用户分配。
sumo中有两种用户分配的方法。
1.1 迭代分配(动态用户均衡)
工具 duaIterate.py 可用于计算(近似的)动态用户均衡。
注意
该脚本将需要大量的磁盘空间。
python tools/assign/duaIterate.py -n <network-file> -t <trip-file> -l <nr-of-iterations>
duaIterate.py 支持与 sumo 相同的许多选项。任何在调用 duaIterate.py --help 时未列出的选项都可以通过在常规选项后添加
s
u
m
o
−
−
l
o
n
g
−
o
p
t
i
o
n
−
n
a
m
e
sumo--long-option-name
sumo−−long−option−name 参数传递给 sumo(例如 sumo–step-length 0.5)。类似地,duarouter 的选项也可以通过 duarouter–long-option-name 参数传递。注意,这些选项必须出现在常规选项之后。
该脚本尝试计算用户均衡,即它尝试为每个车辆(从上述行程文件中的每个行程)找到一条路径,使得每个车辆不能通过使用不同的路径来减少其旅行成本(通常是旅行时间)。这句话类似于用户平衡(UE)的定义。
它是通过迭代方式(因此得名)调用 duarouter 来在具有最后已知边成本的网络上为车辆规划路径(从空网络旅行时间开始),然后调用 sumo 来模拟计算出的路径的“真实”旅行时间结果。结果的边成本用于下一次路径规划步骤。
迭代次数可以设置为固定数值或根据使用的选项动态确定。为了确保收敛,使用了不同的方法来从路径成本计算路径选择概率(因此车辆并不总是选择“最便宜”的路径)。通常,新路径将由路由器在每次迭代中添加到每个车辆的路径集中(至少如果现有路径中没有一个是“最便宜”的),并可能根据下面描述的路径选择机制进行选择。
一开始,计算空网络上的路径成本,然后将上一次的结果作为下一次分配的依据。
在 duaIterate.py 脚本的运行过程中,duarouter 工具被多次调用,每次调用都会生成当前的最佳路径以及之前计算出的备选路径。这些路径信息以 *.rou.alt.xml 格式记录下来。
关键点
.rou.alt.xml格式:- 这种格式不仅记录当前的最佳路径,还记录了之前计算的备选路径。
- 这些路径被收集在一个路径分布(route distribution)中,用于决定下一次模拟步骤中实际行驶的路径。
- 路径选择:
- 在下一次模拟步骤中,实际选择的路径并不总是当前成本最低的那一条,而是从一个可配置的算法从备选路径分布中采样得到的。
- 这意味着路径选择是基于路径分布的概率,而不是简单地选择成本最低的路径。
- 可配置的算法:
- 路径选择的算法是可以配置的,文档中提到有一个可配置的算法,用于从备选路径分布中采样实际行驶的路径。
总结
在 duaIterate.py 脚本的迭代过程中,每次调用 duarouter 后,生成的路径信息被记录在 *.rou.alt.xml 文件中。这些信息不仅包括当前的最佳路径,还包括之前计算的备选路径。这些路径被收集在路径分布中,并且用于决定下一次模拟中实际行驶的路径。路径选择是通过一个可配置的算法从路径分布中采样得到的,而不是简单地选择成本最低的路径。这种方法使得路径选择更加灵活和多样化,有助于实现更接近实际交通行为的路径选择策略。
.rou.alt.xml不仅记录了当前的最优路径,还将每次迭代的最有路径计算并记录。这些记录可以为下一次路径决策提供参考。这是一种基于采样的路径选择方法。算法的描述如下:
2. 路径选择算法
在 SUMO 中,路径选择算法主要有两种实现方法:Gawron 和 Logit。这两种方法的输入是网络边上的权重或成本函数(
w
w
w),这些权重或成本可以来自模拟或默认成本(在第一步或对于尚未行驶的边),并且需要为每个路径计算新的成本和新概率。
2.1 Gawron(默认)
Gawron 算法计算每个驾驶员从一组备选路径中选择路径的概率。以下值用于计算这些概率:
- 在上一次模拟步骤中使用的路径的行程时间;
- 一组备选路径的边行程时间总和;
- 选择路径的先前概率。
每个旅行者的路径集中的路径数量:
用户可以定义路径的最大数量,默认值为 5。在每次迭代中,为每条路径计算使用概率。当路径数量超过定义的数量时,概率最小的路径将被删除。
行程时间的更新:
更新规则通过以下示例进行解释。驾驶员 d d d 在迭代 i i i 中选择路径 r r r。行程时间 τ d ( r , i + 1 ) \tau_d(r, i+1) τd(r,i+1) 根据迭代 i i i 中定义的时间间隔(默认:900 秒)内的聚合和平均链接行程时间来计算。驾驶员 d d d 在迭代 i + 1 i+1 i+1 中路径 r r r 的行程时间等于 τ d ( r , i ) \tau_d(r, i) τd(r,i),如公式 (1) 所示。然后,驾驶员 d d d 的路径集中的其他路径的行程时间分别用公式 (2) 更新,其中 τ d ( s , i ) \tau_d(s, i) τd(s,i) 是迭代 i i i 中在路径 s s s 上行驶所需的行程时间,计算方式与计算 τ d ( r , i ) \tau_d(r, i) τd(r,i) 相同, T d ( s , i − 1 ) T_d(s, i-1) Td(s,i−1) 是路径 s s s 在迭代 i − 1 i-1 i−1 中的成本。参数 β \beta β 是为了防止旅行者对其路径集中每条路径的最新行程时间有强烈的“记忆”。当前 β \beta β 的默认值为 0.3。
T
d
(
r
,
i
+
1
)
=
τ
d
(
r
,
i
)
T_d(r, i+1) = \tau_d(r, i)
Td(r,i+1)=τd(r,i)
T
d
(
s
,
i
+
1
)
=
β
∗
τ
d
(
s
,
i
)
+
(
1
−
β
)
∗
T
d
(
s
,
i
−
1
)
T_d(s, i+1) = \beta * \tau_d(s, i) + (1 - \beta) * T_d(s, i-1)
Td(s,i+1)=β∗τd(s,i)+(1−β)∗Td(s,i−1)
其中 s s s 是驾驶员 d d d 的路径集中未在迭代 i i i 中选择使用的路径。
上述更新规则也适用于使用其他旅行成本单位的情况。使用模拟链接成本计算路径成本的方式可能会导致成本低估,尤其是在只有部分交通流量(例如左转或右转)存在显著拥堵的情况下。现有的票证 #2566 处理此问题。
在公式 (1) 中,也可以使用驾驶员 d d d 在迭代 i i i 中的实际旅行成本作为 τ d ( r , i ) \tau_d(r, i) τd(r,i)。
2.2 Logit
Logit 机制为每条路径应用一个固定公式来计算新概率。它忽略旧成本和旧概率,并直接将路径成本作为上一次模拟中边成本的总和。
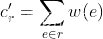
概率通过参数 θ \theta θ 缩放的指数函数计算,并通过对所有路径值的总和进行归一化:
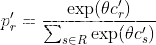
注意
建议设置选项 --convergence-steps(即设置为与 --last-step 相同的值)以确保收敛。否则,尤其是在较高的 --logit
θ
\theta
θ 值下,Logit 路径选择可能会保持振荡。
3. 终止
DuaIterate 的收敛性难以预测,即使在 1000 次迭代后,结果可能仍然会继续变化。在这方面有几种策略:
3.1 默认策略
默认情况下,执行一个固定的迭代次数,通过 --first-step 和 --last-step 配置(默认 50 次)。
3.2 平均旅行时间的偏差
可以使用选项 --max-convergence-deviation 来检测收敛并自动中止迭代。在每次迭代中,计算所有行程的平均旅行时间。从这些值的序列(每次迭代一个值)中,计算相对标准偏差。一旦计算了最小数量的迭代(--convergence-iterations,默认 10 次)并且该偏差低于 max-convergence-deviation 阈值,迭代就会中止。
3.3 强制收敛
可以使用选项 --convergence-steps 通过逐步减少可能改变路线的车辆的比例来强制收敛。
- 如果使用正值 x x x,保持其旧路线的车辆比例设置为 m a x ( 0 , m i n ( s t e p / x , 1 ) max(0, min(step / x, 1) max(0,min(step/x,1),这会在步骤 x x x 后阻止分配的变化。
- 如果使用负值 x x x,在 ∣ x ∣ |x| ∣x∣ 步之后的步骤中,保持其旧路线的车辆比例设置为 1 − 1.0 / ( s t e p − ∣ x ∣ ) 1 - 1.0 / (step - |x|) 1−1.0/(step−∣x∣),这会在 ∣ x ∣ |x| ∣x∣ 步后渐近地减少分配。
总结
duaIterate 脚本的收敛性难以预测,因此在迭代过程中有多种策略来控制迭代的终止。默认情况下,脚本执行固定次数的迭代。还可以通过计算平均旅行时间的相对标准偏差来检测收敛并自动中止迭代。此外,可以通过减少可能改变路线的车辆的比例来强制收敛,具体策略取决于所使用的参数值(正值或负值)。
加速迭代
目前没有通过并行化来加速 duaIterate.py 的方法。然而,duaIterate 的总运行时间主要受“拥堵”迭代的影响,这在早期迭代中很常见,许多车辆试图选择最快路线而忽略容量限制。有几种选项可以缓解这种情况:
-
逐步增加交通流量:
- 通过逐步增加交通流量,使前几次迭代的交通量较少(
--inc-start,--inc-base,--inc-max,--incrementation)。 - 这样可以使早期迭代中的拥堵情况减轻,从而加快整个过程。
- 通过逐步增加交通流量,使前几次迭代的交通量较少(
-
提前终止早期迭代:
- 通过提前终止早期迭代的运行时间(
--time-inc)来减少早期迭代的运行时间。 - 这样可以在拥堵情况明显时提前结束迭代,避免不必要的计算。
- 通过提前终止早期迭代的运行时间(
-
提供初始合理的起始解决方案:
- 通过使用
marouter计算并提供一个合理的初始需求和起始解决方案(--skip-first-routing)。 - 这样可以避免从零开始计算路径,减少早期迭代的拥堵情况。
- 通过使用
-
在运行之间传递更多信息:
- 通过在运行之间传递更多信息(
--weight-memory,--pessimism)来优化路径选择。 - 这些选项可以帮助车辆在后续迭代中更好地选择路径,减少拥堵情况。
- 通过在运行之间传递更多信息(
总结
虽然目前没有通过并行化来加速 duaIterate.py 的方法,但可以通过逐步增加交通流量、提前终止早期迭代、提供初始合理的起始解决方案以及在运行之间传递更多信息来缓解早期迭代的拥堵情况,从而加快整个迭代的运行时间。这些策略可以帮助优化迭代过程,减少不必要的计算,提高整体效率。
5 Usage Examples
5.1 Loading vehicle types from an additional file
By default, vehicle types are taken from the input trip file and are then propagated through duarouter iterations (always as part of the written route file).
In order to use vehicle type definitions from an additional-file, further options must be set
duaIterate.py -n ... -t ... -l ...
--additional-file <FILE_WITH_VTYPES>
duarouter--aditional-file <FILE_WITH_VTYPES>
duarouter--vtype-output dummy.xml
Options preceded by the string duarouter-- are passed directly to duarouter and the option vtype-output dummy.xmlmust be used to prevent duplicate definition of vehicle types in the generated output files.
6.oneShot-assignment 策略
作为上述迭代用户分配的替代方案,还有一种方法是增量分配(incremental assignment)。当在 SUMO 中直接使用 <trip> 输入而不是带有预定义路径的 <vehicles> 时,这种分配会自动发生。在这种情况下,每个车辆在其出发时都会计算一条最快的路径,从而防止所有车辆盲目驶入同一个拥堵路段,并且在较大规模场景中表现得非常好。
增量分配的路径计算使用自动路由/路由设备(Routing Device)机制。还可以启用定期重路由(periodic rerouting)以提高对发展中的拥堵的反应性。
由于自动重路由允许各种配置选项,可以使用脚本 Tools/Assign#one-shot.py 来自动尝试不同的参数设置。
总结
oneShot-assignment 是一种替代迭代用户分配的策略,通过在 SUMO 中直接使用 <trip> 输入,每个车辆在其出发时都会计算一条最快的路径,从而避免所有车辆盲目驶入同一个拥堵路段。这种方法在较大规模场景中表现良好。路径计算使用自动路由机制,并且可以启用定期重路由以提高对拥堵的反应性。由于自动重路由有多种配置选项,可以使用 Tools/Assign#one-shot.py 脚本来尝试不同的参数设置,以找到最适合的配置。
7. marouter 应用
marouter 应用程序计算经典的大尺度分配(classic macroscopic assignment)。它使用数学函数(阻抗函数)来近似旅行时间随流量增加而增加的情况。这使得可以在不需要耗时的微观模拟的情况下进行迭代分配。
解释
-
大尺度分配:
marouter通过宏观的角度来计算交通分配。与微观模拟不同,它不关注单个车辆的行驶行为,而是关注整个交通流的宏观特性。
-
阻抗函数:
marouter使用阻抗函数来近似旅行时间随流量增加而增加的情况。这些函数模拟了道路拥堵时的旅行时间变化,可以快速预测不同流量下的旅行时间。
-
迭代分配:
- 由于使用了阻抗函数,
marouter可以在不需要进行微观模拟的情况下进行迭代分配。这种方法减少了计算时间,适合处理大规模的交通网络。
- 由于使用了阻抗函数,
总结
marouter 是一个用于计算大尺度交通分配的应用程序。它通过使用阻抗函数来近似旅行时间随流量增加的情况,从而避免了耗时的微观模拟。这种方法允许在不需要详细模拟每个车辆行为的情况下,快速进行迭代分配,适用于处理大规模交通网络的需求。

















 6875
6875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









