







介绍
图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
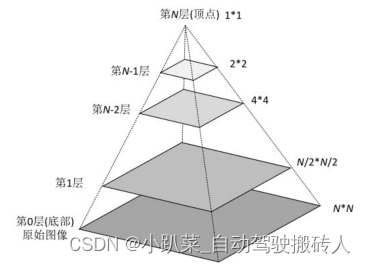
分类
高斯金字塔(向下采样)
高斯金字塔模仿的是图像的不同的尺度,尺度应该怎样理解?对于某个图像来讲,0.5米处观察图像与你在2米处观察的图像,所看到的效果是不同的。可以明确的是前者比较清晰,后者比较模糊,前者比较大,后者比较小。前者能看到图像中可以看到一些细节信息,后者能看到图像的一些轮廓的信息,这就是图像的尺度,图像的尺度是自然存在的,并不是人为创造的。其实以前对一幅图像的处理还是比较单调的,因为我们的关注点只落在二维空间,并没有考虑到“图像的纵深”这样一个概念,如果将这些内容考虑进去我们是不是会得到更多以前在二维空间中没有得到的信息呢?于是高斯金字塔横空出世了,它就是为了在二维图像的基础之上,榨取出图像中自然存在的另一个维度:尺度。因为高斯核是唯一的线性核,也就是说使用高斯核对图像模糊不会引入其他噪声,因此就选用了高斯核来构建图像的尺度。
构建步骤
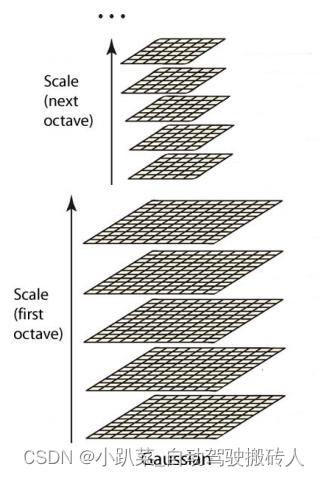
高斯金字塔构建过程中,通常首先将图像扩大一倍,在扩大的图像的基础之上构建高斯金字塔,然后对该尺寸下图像进行高斯模糊,几幅模糊之后的图像集合构成了一个八度,然后对该八度下的最模糊的一幅图像进行下采样的过程,长和宽分别缩短一倍,图像面积变为原来四分之一。这幅图像就是下一个八度的初始图像,在初始图像图像的基础上完成属于这个八度的高斯模糊处理,以此类推完成整个算法所需要的所有八度构建,这样这个高斯金字塔就构建出来了。构建出的金字塔如下图所示:
高斯卷积函数为:
G
(
x
,
y
)
=
1
2
π
σ
2
e
−
(
x
−
x
0
)
2
+
(
y
−
y
0
)
2
2
σ
2
G(x,y)=\frac{1}{2\pi\sigma^2}e^ -{\frac{(x-x_0)^2+(y-y_0)^2}{2\sigma^2}}
G(x,y)=2πσ21e−2σ2(x−x0)2+(y−y0)2
对于参数σ,在SIFT算子中取得固定值为1.6。将σ乘以一个比例系数k,等到一个新的平滑因子σ=k×σ,用它来平滑第1组第2层图像,结果图像作为第3层。如此这般重复,最后得到L层图像,在同一组中,每一层图像的尺寸都是一样的,只是平滑系数不一样。它们对应的平滑系数分别为:0,σ,kσ,
k
2
σ
k^2σ
k2σ,
k
3
σ
k^3σ
k3σ,……,
k
(
L
−
2
)
σ
k^(L-2)σ
k(L−2)σ。将第1组倒数第三层图像作比例因子为2的降采样,得到的图像作为第2组的第1层,然后对第2组的第1层图像做平滑因子为σ的高斯平滑,得到第2组的第2层,就像步骤2中一样,如此得到第2组的L层图像,同组内它们的尺寸是一样的,对应的平滑系数分别为:0,σ,kσ,
k
2
σ
k^2σ
k2σ,
k
3
σ
k^3σ
k3σ,……,
k
(
L
−
2
)
σ
k^(L-2)σ
k(L−2)σ。但是在尺寸方面第2组是第1组图像的一半。这样反复执行,就可以得到一共O组,每组L层,共计O*L个图像,这些图像一起就构成了高斯金字塔。在同一组内,不同层图像的尺寸是一样的,后一层图像的高斯平滑因子σ是前一层图像平滑因子的k倍;在不同组内,后一组第一个图像是前一组倒数第三个图像的二分之一采样,图像大小是前一组的一半;
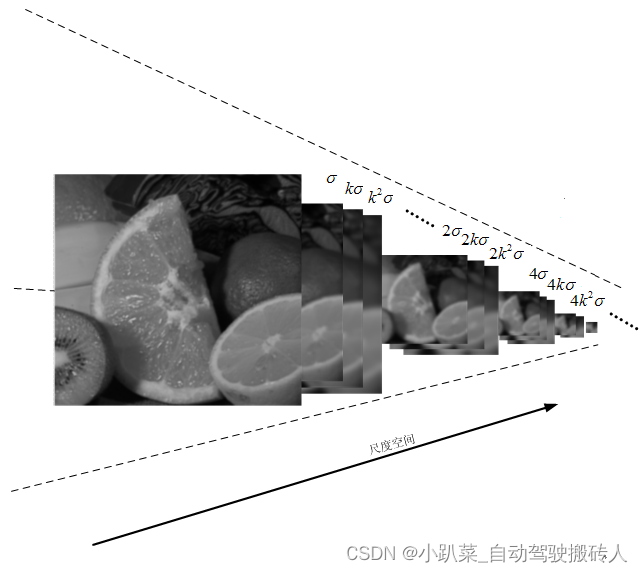
在高斯金字塔中一共生成O组L层不同尺度的图像,这两个量合起来(O,L)就构成了高斯金字塔的尺度空间,也就是说以高斯金字塔的组O作为二维坐标系的一个坐标,不同层L作为另一个坐标,则给定的一组坐标(O,L)就可以唯一确定高斯金字塔中的一幅图像。尺度空间的形象表述:
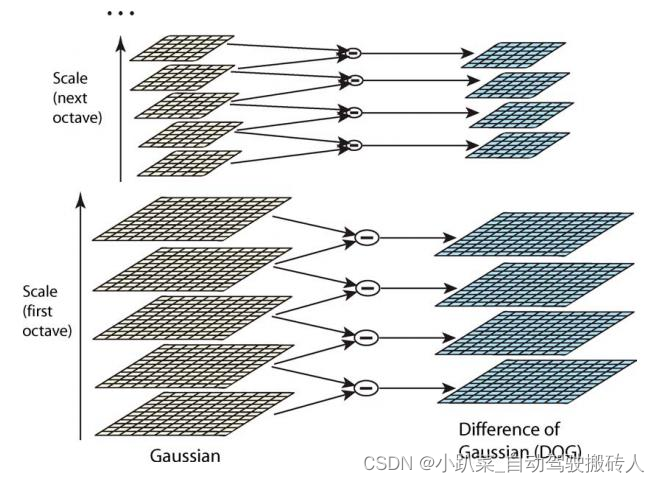
差分高斯金字塔
构建高斯金字塔是为了后续构建差分高斯金字塔。对同一个八度的两幅相邻的图像做差得到插值图像,所有八度的这些插值图像的集合,就构成了差分高斯金字塔。过程如下图所示,差分高斯金字塔的好处是为后续的特征点的提取提供了方便。到这里,高斯金字塔构建的主要部分、关键点都弄好了,一些非常重要的认知就要呼之欲出了,下面解释整个空间的尺度连续性!这是差分高斯金字塔的重中之重!
对于高斯差分函数,两个相邻的高斯空间的图像相减就得到了DoG的响应图像。也就是说DoG的数学定义为:
D
(
x
,
y
,
σ
)
=
[
G
(
x
,
y
.
k
σ
)
−
G
(
x
,
y
,
σ
)
]
∗
I
(
x
,
y
)
=
L
(
x
,
y
,
k
σ
)
−
L
(
x
,
y
,
σ
)
D(x,y,σ)=[G(x,y.kσ)-G(x,y,σ)] * I(x,y) = L(x,y,kσ) - L(x,y,σ)
D(x,y,σ)=[G(x,y.kσ)−G(x,y,σ)]∗I(x,y)=L(x,y,kσ)−L(x,y,σ)
其中L(x, y, σ)是图像的高斯尺度空间,而k是相邻的两个高斯尺度空间的比例因子。在构造尺度空间时,SIFT在降维采样点基础上加上高斯滤波实现。
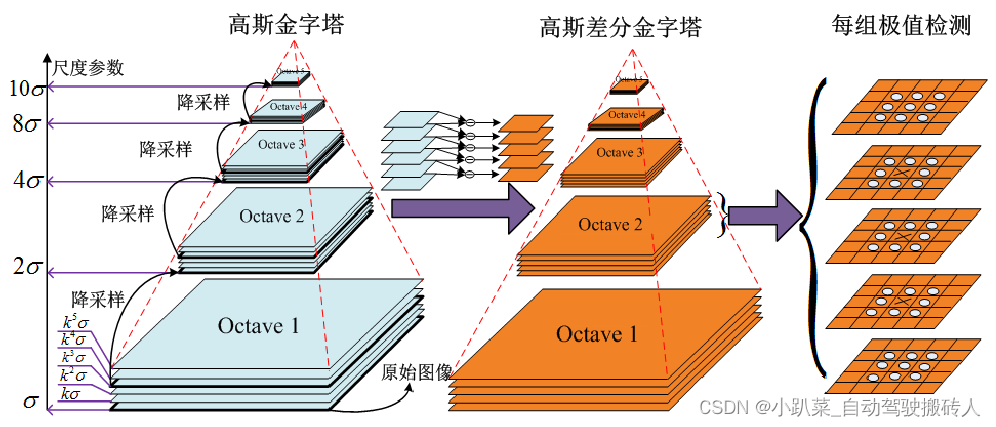
可知,高斯金字塔有多组,且每组有多层.其中的参数:
1. O:组数。一般组数(m为行数,n为列数)为:
O
=
log
2
(
m
i
n
(
m
.
n
)
−
a
)
O=\log_2(min(m.n) - a)
O=log2(min(m.n)−a)
2. S:每组层数
3. k:相邻高斯尺度的比例因子。其值为
k
=
2
1
s
k=2^\frac{1}{s}
k=2s1
4. σ:初始尺度。
s的意思是将来我们在差分高斯金字塔中求极值点的时候,我们要在每个八度中求s层点,通过lowe论文可知,每一层极值点是在三维空间(图像二维,尺度一维)中比较获得,因此为了获得s层点,那么在差分高斯金字塔中需要有s+2图像,好了,继续上溯,如果差分高斯金字塔中有s+2幅图像,那么高斯金字塔中就必须要有s+3幅图像了,因为差分高斯金字塔是由高斯金字塔相邻两层相减得到的。好了,到了这里似乎真相大白,但是我们上面的推导有一个致命的问题,我们上来就假设“我们要在每个八度中求s层点”,为什么要s层点呢?这才是这个小节的主题:是为了保持尺度的连续性!通过设置每一组的初始图像来保持的(也就是初始的尺度设置为上一层初始尺度的二倍)。而S是通过DoG金字塔中获取特征点的层数。这是一个实验值。在论文中,当S为3时,检测特征点最佳。比如如果要得到S层图像,那么DoG金字塔就需要S+2层,而高斯金字塔就需要S+3层。比如设置S为3,高斯金字塔为6, DoG金字塔为5,然后我们在求局部最大值时,没一组只需要比较三层。
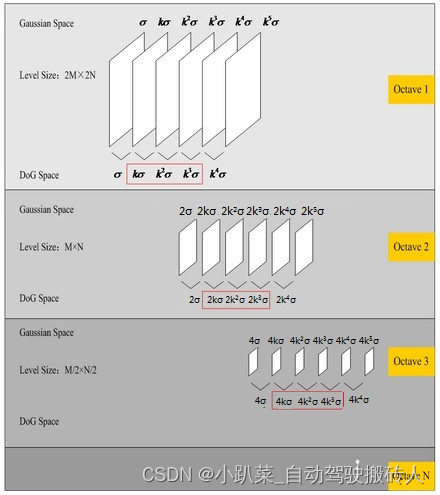
拉普拉斯金字塔
拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。高斯金字塔用来向下降采样图像,注意降采样其实是由金字塔底部向上采样,分辨率降低;而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像。拉普拉斯金字塔可以认为是残差金字塔,用来存储下采样后图片与原始图片的差异。我们知道,如果高斯金字塔中任意一张图Gi(比如G0为最初的高分辨率图像)先进行下采样得到图Down(Gi),再进行上采样得到图Up(Down(Gi)),得到的Up(Down(Gi))与Gi是存在差异的,因为下采样过程丢失的信息不能通过上采样来完全恢复,也就是说下采样是不可逆的。
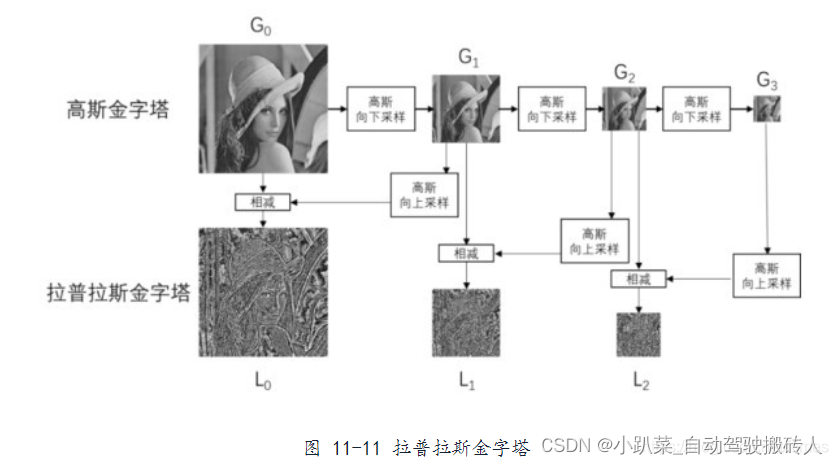
拉普拉斯金字塔的作用在于,能够恢复高分辨率的图像。下图演示了如何通过拉普拉斯金字塔恢复高分辨率图像。其中,右图是对左图的简化。
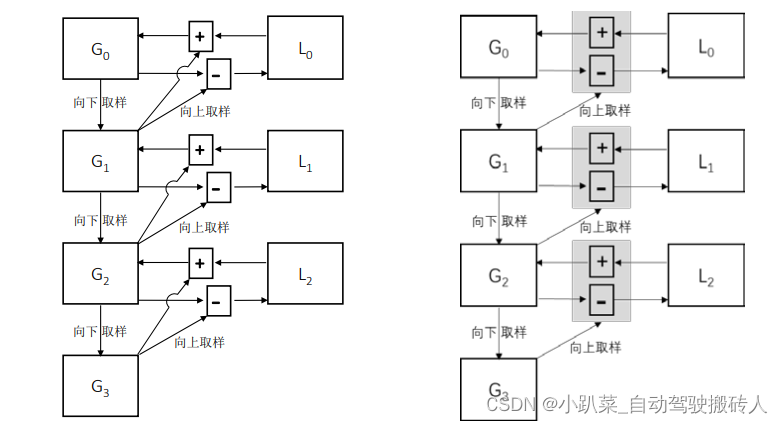
G
0
、
G
1
、
G
2
、
G
3
G_0、G_1、G_2、G_3
G0、G1、G2、G3分别是高斯金字塔的第 0 层、第 1 层、第 2 层、第 3 层。
L
0
、
L
1
、
L
2
L_0、L_1、L_2
L0、L1、L2分别是拉普拉斯金字塔的第 0 层、第 1 层、第 2 层。
↓
\downarrow
↓ 箭头表示向下采样操作。
向右上方的箭头表示向上采样操作(对应 cv2.pyrUp()函数)。
+ 表示加法操作。
- 表示减法操作


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











