









https://blog.csdn.net/qq_46105339/article/details/108491692
https://zhuanlan.zhihu.com/p/111598807
论文标题:PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/1911.04231
代码链接:https://github.com/ethnhe/PVN3D
3、拟议方法
6Dof位姿估计目的:通过RGBD图像,估计对象从对象世界坐标系到相机世界坐标系的刚性变换,包括3D rotation和3D translation。
3.1 总体方案

特点:全新的基于深度3D Hough投票网络的方法。
整个方案分两阶段:1、全新的基于深度3D Hough投票网络的方法,实现3D 关键点检测;2、最小二乘法姿态拟合。
M_k:检测3D关健点,预测从可见点到目标关键点的欧式偏移量。
目标关键点是每个物体预先选定的点吗?是
p
i
i
=
1
N
{{p_i}^N_{i=1}}
pii=1N为相机拍摄的可视点集合,
k
p
j
j
=
1
M
{{kp_j}^M_{j=1}}
kpjj=1M为预先选择的关键点集合。
p
i
=
[
x
i
,
f
i
]
p_i=[x_i,f_i]
pi=[xi,fi],
x
i
x_i
xi为点的三维坐标,
f
i
f_i
fi为对应的特征。
k
p
j
=
[
y
j
]
kp_j=[y_j]
kpj=[yj],
y
i
y_i
yi为点的三维坐标。
o f i j j = 1 M {of_i^j}_{j=1}^M ofijj=1M表示点i到关键点j的偏移,那么所投票出来的关键点的三维坐标表示: v k p i j = x i + o f i j vkp_i^j=x_i+of_i^j vkpij=xi+ofij
M_k网络的训练目的有两个,一个是相机中每个点对应的特征 f i f_i fi,另一个是相机中每个点相对关键点的偏移值 o f i j j = 1 M {of_i^j}_{j=1}^M ofijj=1M
损失函数如下:
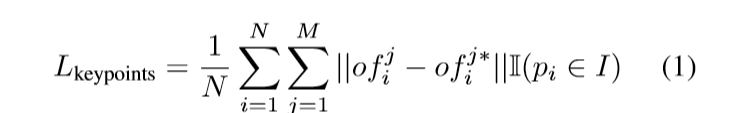
其中
o
f
i
j
of_i^j
ofij为网络得到是偏移,
o
f
i
j
∗
of_i^j*
ofij∗为实际的偏移。I取0 、1表示点p是否属于实例。
M_S 实例语义分割模块
以前的方法是:利用实例分割预处理图片,可以提供只包含单一目标的ROIS,这个ROIS作为输入,可以提供位姿估计的初始点。
但是,作者是先训练的网络去学习偏移信息,与实例分割不是先后顺序关系,作者认为,M_k模块和实例分割模块可以互补提高性能。
1、实例分割得到不同物体在图片中的范围,有利于关键点的定位。
2、M_k学到的偏移信息,有助于区分外形相似但尺寸不同的物体。
将分割网络M_s加到M_k网络中做联合优化??具体是怎么优化的?

同时,中心投票网络M_c投票不同物体的中心点,用来区分不同实例(相同语义?),中心点的预测与M_k相似,预测观察点到中心点的平移偏量。
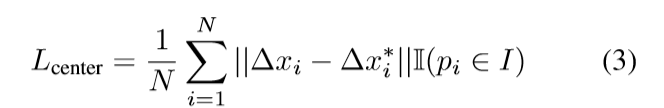
Δ
\Delta
Δ
x
i
x_i
xi为 每个点到中心点的偏移。
多任务学习
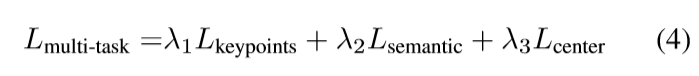
联合训练可以相互促进性能
3.3训练
网络结构

第一部分,ImageNet是ResNet34的PSPNet,提取RGB信息;PointNet++提取点云的几何信息及正则化映射。然后通过DenseFuson模块进行融合得到每个点的组合特征,每个点都获得c个维度的特征。后面的M_k,M_s,M_c用共享MLP来计算。每张RGBD图片都采样12288个像素点,并且
λ
\lambda
λ 123都取0.1
关键点选择
关键点是从模型中选择的,有些算法是用3D边框的八个角作为关键点,但是这些关键点不在物体上,且造成目标点距离过大,在物体表面选择关键点更好。采用最远点FPS选择关键点,具体方法为:
1、从模型中人为选择一个中心点。
2、从模型中寻找离中心点最远点作为第一个关键点,
3、依次选择离所有关键点最远的点作为关键点,直到获得M个点。
最小二乘法拟合
两个点集:一个是相机坐标系下预测得到的M个关键点,另一个是从目标物体中选择对应的关键点,然后采用最小二乘法拟合旋转和平移矩阵。
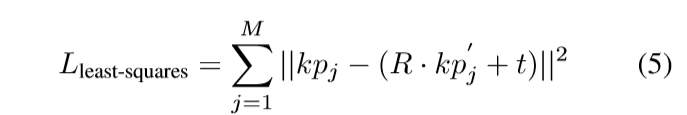
4、实验
4.1 数据集
两个数据集:YCB和LineMOD
YCB视频数据集包含21个形状和纹理变化的YCB [4]对象。捕获了对象子集的92个RGBD视频,并使用6D姿势和实例语义蒙版对其进行了注释。变化的光照条件,明显的图像噪声和遮挡使该数据集具有挑战性。我们遵循[52],将数据集分为80个视频进行训练,并从其余12个视频中选择另外2949个关键帧进行测试。按照[52],我们将合成图像添加到我们的训练集中。孔补全算法[25]也被用于改善深度图像的质量。
LineMOD数据集[18]由13个视频中的13个低纹理对象,带注释的6D姿势和实例蒙版组成。该数据集的主要挑战是混乱的场景,缺乏纹理的对象和照明变化。我们遵循先前的工作[52]来划分训练和测试集。同样,我们遵循[37],并将合成图像添加到我们的训练集中。
4.2 评估指标
1、平均距离(ADD)
真值和估计姿势中两个模型对应点的平均距离。均值小于模型直径的10%为准确。
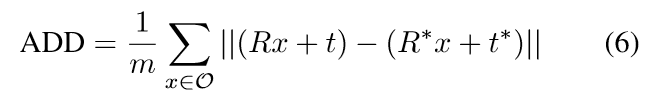
2、对称物体(ADD-S)
对称物体匹配不明确,使用最近点
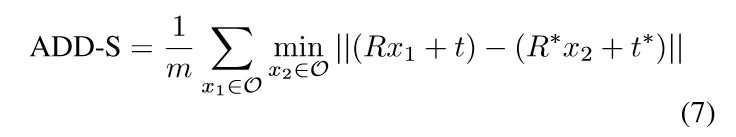
















 4623
4623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









