







基础知识
1. 什么是CLIP
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别,并且在计算效率更高的同时优于公开可用的最佳ImageNet模型。
2.CLIP的作用&意义
作为文生图模型,Stable Diffusion中的文本编码模块直接决定了语义信息的优良程度,从而影响到最后图片生成的质量和与文本的一致性。
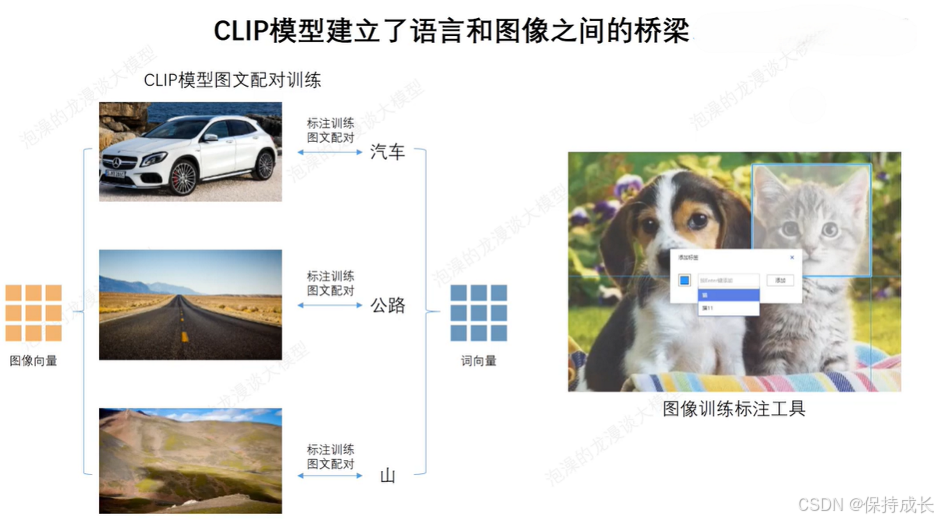
而clip模型的核心思想就是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系,是一种图像+语言的多模态模型,跨过了周期,从传统深度学习时代进入AIGC时代,成为了SD系列模型中文本和图像之间的“桥梁”。
它是Stabel Diffusion 文生图任务成功的基石。甚至从某种程度上讲:正是因为CLIP模型的前置出现,加速推动了AI绘画领域的繁荣。
灵活的结构,简洁的思想,让CLIP不仅仅是个模型,也给我们一个很好的借鉴,往往伟大的产品都是大道至简的。更重要的是,CLIP把自然语言领域的抽象概念带到了计算机视觉领域。
图一
3.浅谈CLIP的原理
CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
1. Text Encoder:用于将文本转换为低维向量表示-Embeding。可以使用NLP中常用的text transformer模型作为Text Encoder;
2. Image Encoder:用于将图像转换为类似的向量表示-Embedding。可以使用CNN/Vision transformer模型(ResNet和ViT等)作为Image Encoder;
图二
图三
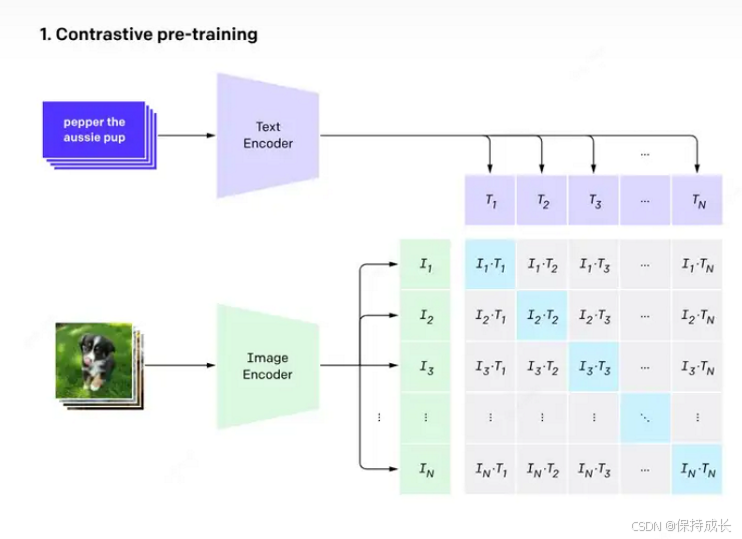
如图二所示,模型由两个编码器组成,紫色的梯形是文本编码器,绿色的梯形是图像编码器。使用大量匹配的图像和文本对,然后分别走各自的编码器得到各自的特征,再计算特征两两之间的cos相似度,让配对的特征相似度越近越好,不配对的相似度越远越好。这样就可以完成了CLIP的与训练。
现在CLIP模型需要将N个标签文本和N个图片的两两组合预测出N^2个可能的文本-图片对的余弦相似性,即上图左边所示的矩阵。这里共有N个正样本,即真正匹配的文本和图片(矩阵中的对角线元素),而剩余的N^2−N个文本-图片对为负样本,这时CLIP模型的训练目标就是最大化N个正样本的余弦相似性,同时最小化N^2−N个负样本的余弦相似性。
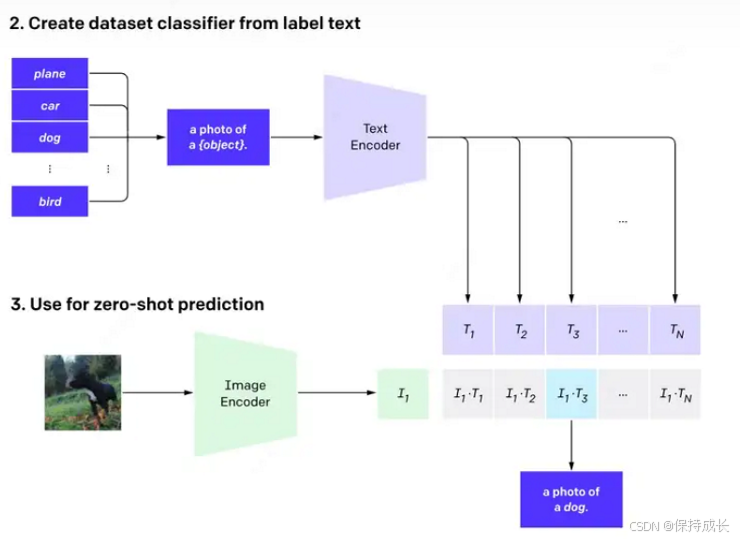
如图三,给一堆类别名,把类别名填到“A photo of a {object}.”里面然后编码。然后图像也做编码,编码完成后拿图像特征跟文本特征比cos相似度,跟哪个特征距离最近,我们就认为模型把这张图分到了哪个类别里;
4.训练流程
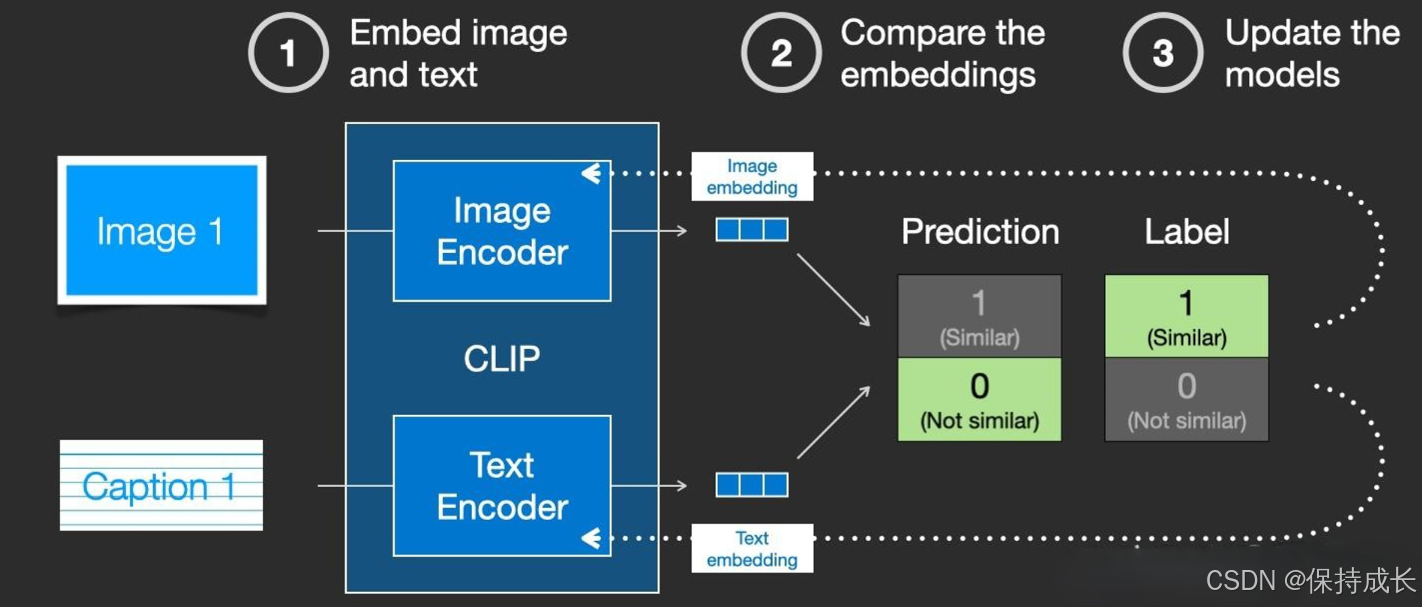
CLIP在训练时,从训练集中随机取出一张图片和标签文本,接着CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片提取embedding向量,然后用余弦相似度(cosine similarity)来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练。
5.总结
总的来说,根本用途就是:
把图片和文字编码到同一空间,计算图像和文本的语义相似度;
因此CLIP成为了计算机视觉和自然语言处理这两大AI方向的“桥梁”,从此AI领域的多模态应用有了经典的基石模型。


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











