







MVSNET论文&代码下载:
https://arxiv.org/abs/1804.02505
https://github.com/YoYo000/MVSNet
https://github.com/xy-guo/MVSNet_pytorch
这里有完整的MVSNet论文的翻译 https://blog.csdn.net/qq_43307074/article/details/127876458
这里看到部分翻译 https://www.codenong.com/cs106743671/
这个可以看看 基于平面扫描的多视角立体(MVS)深度学习综述-北大Zhu Qingtian 2021 https://zhuanlan.zhihu.com/p/601274355?utm_id=0
感觉把一些基础都讲到了,也合区3D视觉工坊里的MVSNET课程里的内容很相似。
MVS常用数据集:
DTU:室内数据集,124个场景,每个场景包含49或者64张图像(7种不同的光照条件),用机械臂拍摄,深度范围较小,提供gt的深度图和22个场景的gt点云 Tanks and Temples:主要是室外的数据集,训练集只有7个场景有ground-truth的点云,深度范围较大,一般用于测试模型在室外数据集中的泛化能力 BlendedMVS:合成数据集,既有室外也有室内场景,一共113个场景,17818张图像,用于finetune或者测试,提供gt的深度图,部分场景有gt的网格(Mesh) ETH3D:有多目和双目benchmark,提供gt的深度图,高分辨率多目有13个训练场景,12个测试场景;低分辨率多目有5个训练场景和6个训练场景的视频
MVSNET概括
下面这个感觉对MVSNET概括得挺到位的。 https://blog.csdn.net/weixin_44543463/article/details/125628192
MVSNet
你自己能把MVSNET的流程原理讲清楚,那就差不多了。
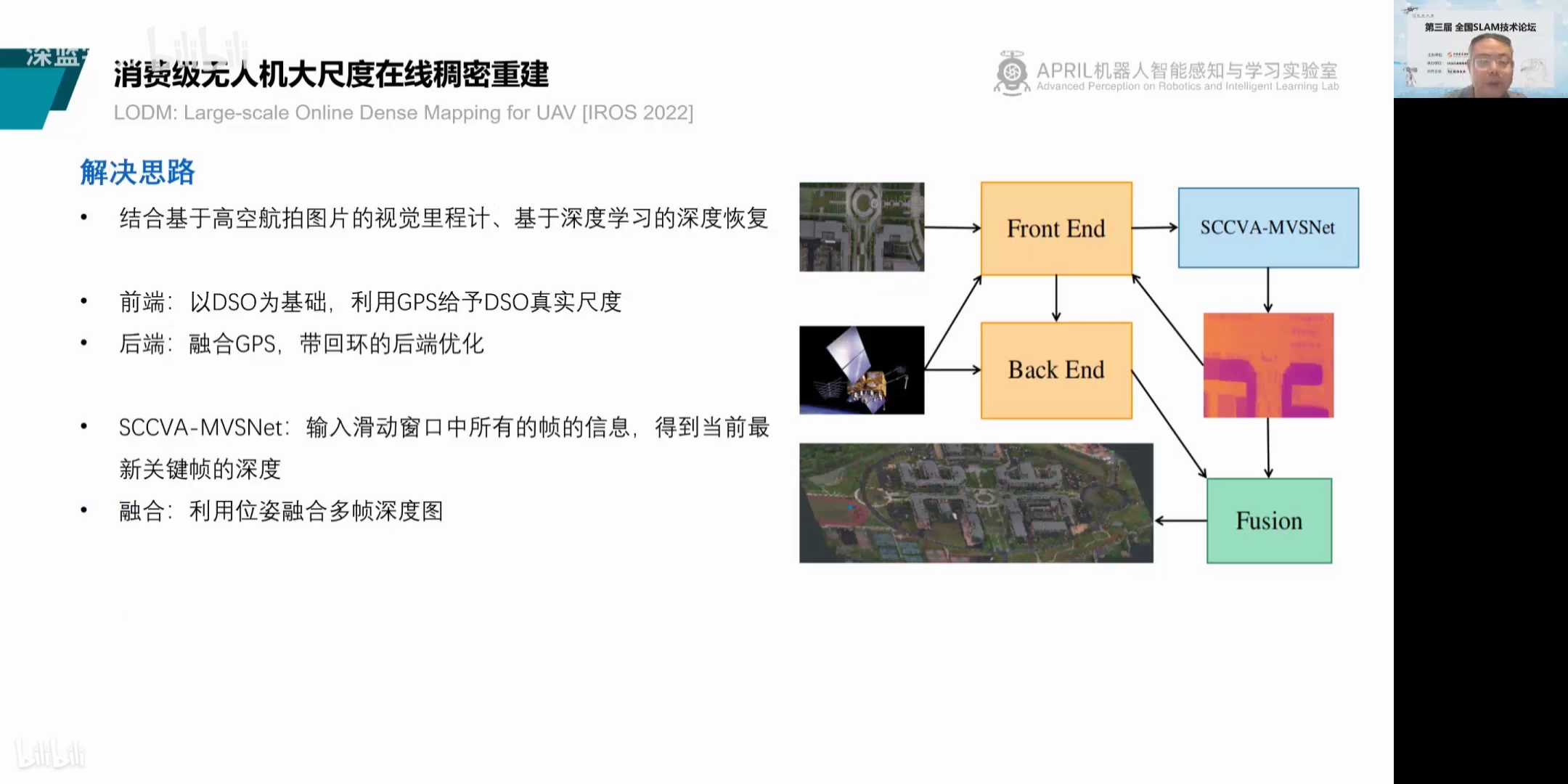
网络结构:输入是任意位姿的多张图像,且多张图片之间的关系需要被整体考虑。
MVSNet本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
过程:
(1)输入一张reference image(为主) 和几张source images(辅助);
(2)分别用网络提取出下采样四分之一的32通道的特征图;
(3)采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
(4)利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
(5)利用多张图片之间的重建约束(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。
MVSNET的变种 来自 https://mp.weixin.qq.com/s/cfnzxaFffNAX1Hcmzn5slQ
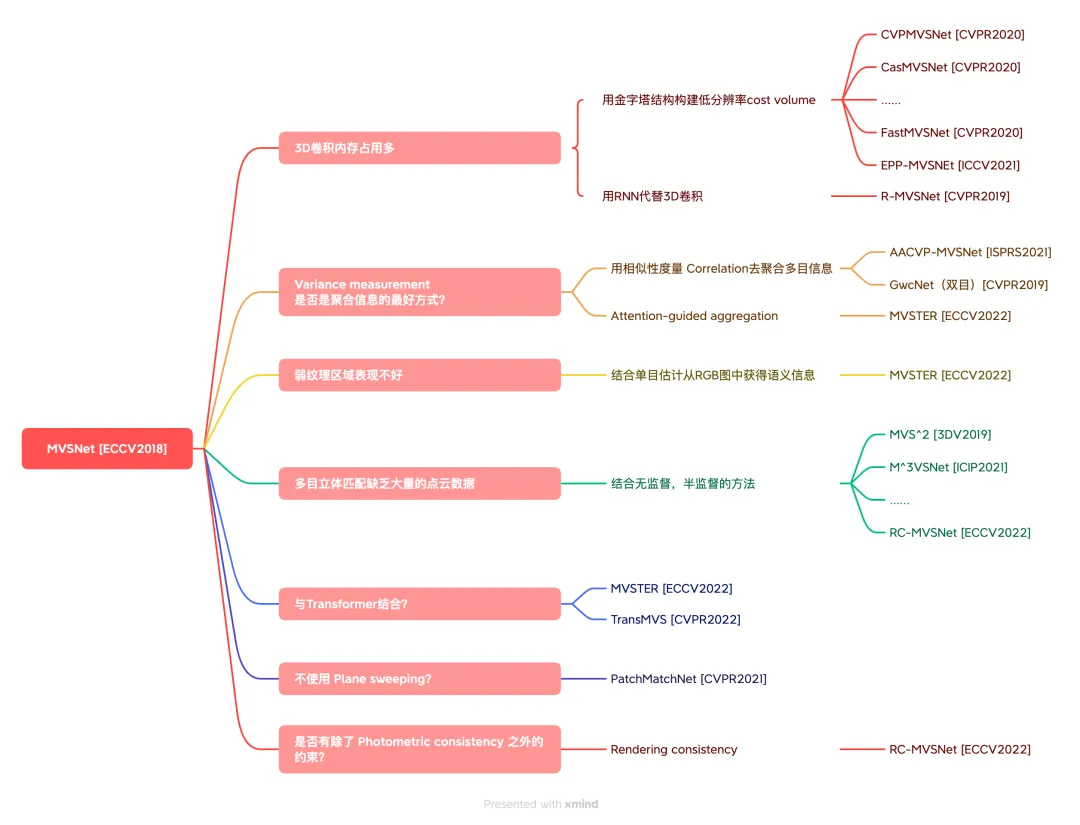
这篇博客对MVSNET的一些后续工作也总结得很到位 https://blog.csdn.net/qq_41794040/article/details/129223755
关于硬件运行平台,这里说i5+RTX3060可以实时运行,是ORB-SLAM2 + CVA-MVSNet的方案。
【视觉SLAM纯单目方案,实时重建湖南大学-哔哩哔哩】 https://b23.tv/PFhT0Kw
我看现在四千多就可以买到一个RTX3060显卡的笔记本了
MVSNet的效果比开源MVS方法(COLMAP)和商业软件(Pixel4D)要好。同样值得注意的是,在运行速度方面MVSNet比之前最好的方法要快几倍甚至几个数量级。(https://mp.weixin.qq.com/s/iCkHZUVTuPX7kHmoiacq-w )
但是3D视觉工坊的课里后来也说到,基于深度学习的MVS准确性上不如传统方法,但是完整性(召回率)比传统方法好,可能是一些低纹理或者反光不太好的地方传统方法处理不太好但是基于深度学习的MVS处理得相对好些。
基于深度学习的多视图立体重建一般由两部分组成,深度图重建、深度图融合为点云。(https://mp.weixin.qq.com/s/iCkHZUVTuPX7kHmoiacq-w )
关于MVSNET论文里公式的错误 https://zhuanlan.zhihu.com/p/363830541?utm_id=0
这里( https://zhuanlan.zhihu.com/p/601274355?utm_id=0 )说基于深度学习的MVS的CNN网络主要还是ResNet和UNet,基于深度学习的单目深度估计好像也是。
下面这是3D视觉工坊MVSNET课程北大的那个老师写的,https://mp.weixin.qq.com/s/ee7-jr8QN8D2MSTyDNeWWw
利用自己采集的数据进行MVSNET深度估计的步骤为:采集数据 -> 稀疏重建 -> COLMAP文件导出 -> 数据转换 -> 输入MVSNet -> 输出深度图 -> 深度融合,恢复点云。
关于从特征体到代价体到概率体
特征体通过特征聚合变为代价体
代价体通过正则化变为概率体
https://blog.csdn.net/qq_44708206/article/details/127420555
生成的概率体既可以用于逐像素的深度估计,同时可用于测量估计的置信度
https://m.sohu.com/a/313566626_715754
输入图像经过二维特征提取网络和可微单应变换生成代价体。最终的深度图输出从正则化的概率体中回归
https://blog.csdn.net/qq_41794040/article/details/129223755
Pipeline:特征提取(特征图) - 单应变换 - 特征体 - 代价体 - 正则化 - 深度推断 - 后处理
单应变换是由CNN提取出的特征图构建特征体的时候用的,特征图构建特征体就是,将所有特征图变换到参考相机的锥形立体空间,形成N+1个特征体Vi(1是指一张参考图像,N是指N张源图像)。https://blog.csdn.net/qq_43027065/article/details/116641932 ,这样可以理清楚了吧。有必要把每步的转换操作弄清楚 比如特征体到代价体是用特征聚合,代价体到概率体是正则化,现在叫你划分MVSNET的几个部分你也能像3D视觉工坊MVSNET课程讲师一样划分了吧。

这个总结得不错,这个也说清楚了特征图如何构建特征体的。
https://blog.csdn.net/qq_43307074/article/details/127876458

我刚刚看每个部分维度发现,特征聚合,是把几张图片合成一张图片,但是特征通道数还是在的,特征通道没有合并。 32通道合并为1通道是在正则化时,也就是概率体就是1通道了代价体还是32通道的。
但是3D视觉工坊MVSNET课程老师说正则化没有改变维度人,是这个意思:这个cost网络本身是不改变维度的 只是去除噪声更加抽象,真正把32拍成1的是最后一个prob层(soft argmin),最终的物理含义是 某一个pixel的某一个深度假设位置的概率值。所以不矛盾。
这个大体流程可能已经形成一种基于深度学习的MVS的范式了,大家都是在这个框架下进行创新。
从下面这看,似乎传统MVS方法也有正则化这步 https://blog.csdn.net/qq_41794040/article/details/127853045

https://zhuanlan.zhihu.com/p/646192961
无论是传统立体匹配算法,还是基于深度学习的分离式算法,以及我们现在在描述的端到端的立体匹配算法,代价立方体的估计与正则化都是我认为最重要的步骤之一。
MVSNET自己再整理
网络输入:1张参考图像+N张原图像(从其他视角观察同一物体的图像),每张图像对应的相机内参和外参
网络输出:概率图+优化深度图,在后处理中使用概率图对优化深度图进行过滤
具体流程也可以自己写清楚(有参考 https://blog.csdn.net/qq_43027065/article/details/116641932 )
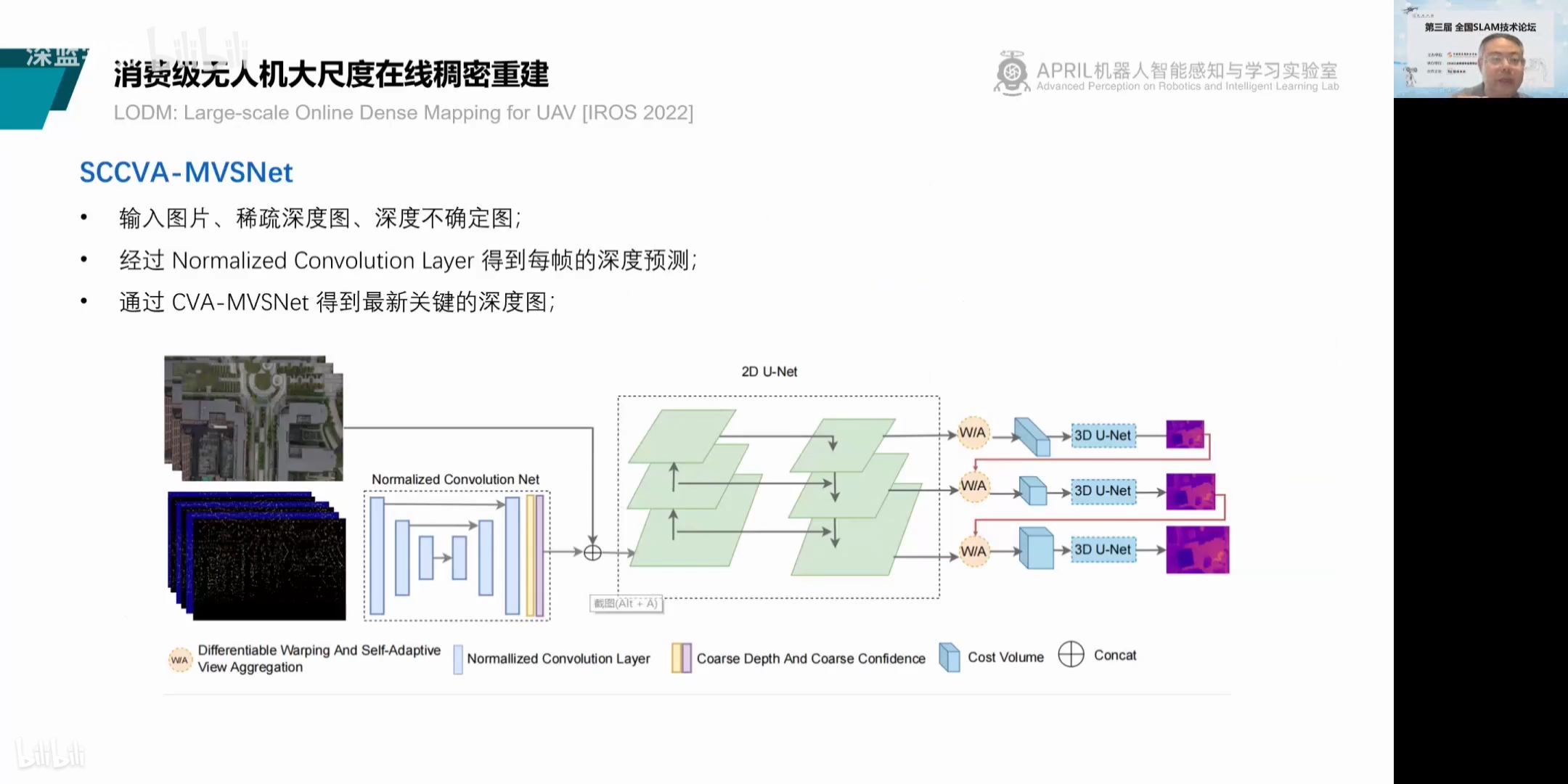
1.特征提取(构建特征图):提取每幅输入图像的特征,输入1个参考图像+N个原图像,输出N+1个32通道的特征图。
维度是[H/4,W/4,32]
2.构建特征体:将所有特征图变换到参考相机的锥形立体空间,形成N+1个特征体。单应变换是这里有用到。
关于锥形立体空间:虽然假设的空间是关于参考视角的锥形立体空间(可以理解为拍摄参考图像的相机所在的相机坐标系,沿Z轴方向由Z的范围(深度假设范围)确定的一个立体空间),但在每个深度平面上像素点数量是一样的,作为数据存放时是方形的立体空间。
将问题建模在相机视锥空间而非整个3D空间,降低内存消耗。
特征体的维度是包含了那些深度假设层(可能有的几十个,有的上百个)的,这个在特征图里面是没有的。
(讲道理这个锥形空间是不是应该只有N个而不是N+1个呀)
这里说清楚了,对于参考图像的特征图,变换到参考相机的锥形空间,就是直接复制假设平面对应个数就行了,不用做单应变换,这么来看还是有N+1个锥形空间也就是特征体的。
【MVSNet(Pytorch)核心代码和算法讲解(三维重建)-哔哩哔哩】 https://b23.tv/zVrE51u

3.构建代价体(特征聚合):将N+1个特征体聚合为一个代价体。
将N个特征体通过计算方差,聚合至一个代价体,方差越小,说明在该深度的概率越高。这个现在好理解了。
4.构建概率体(代价体正则化):特征通道会由32变为1
可微分单应变换 differentiable homography
对于MVSNET,似乎都提到了一个核心概念,可微分的单应变换。
现在单应变换是理解的,可微分怎么理解,differentiable可以翻译成可微分,也可以翻译成可区分,我怎么感觉理解成可区分好点,就是对应不同深度假设平面的单应变换。
可微分是否就是为了可以求导,可以求导就可以梯度优化,原本的平面扫描的深度切片是离散的,没法求导?
我也看到 https://blog.csdn.net/zhingzt/article/details/127938505 这里说,为什么要可微分,因为要做到端到端的深度学习训练。
关于可微的论述我看是在论文这里,说改为这样就可以反向传播可微了。
是否反向传播优化更新每个平面p的值,首先影响到估计的平面深度,进一步反向传播影响到每个平面p的值,,这么来看argmax确实不能反向传播。

关于单应性变换
homography warping指单应性变换,刚体、仿射、单应性(投影)、透视变换是图像几个基本变换之一,warp这个单词就是指这些变换。
https://blog.csdn.net/qq_50869289/article/details/125691034

这么看单应变换就是平面的投影变换,其实挺简单的,所以MVSNET在做单应变换,前提是做了平面假设,假设这张照片的点都在某个深度平面上,然后统一平面投影,这个操作还是很简单的。这有个用pytorch做投影变换的代码,https://blog.csdn.net/u012160945/article/details/131837308 ,应该用不上神经网络,基本的数学公式处理就行。
亚像素视差
看了下面这个图,就能比较好理解为什么亚像素视差这么重要了,没有亚像素视差 深度图真的理应是台阶状的!!!不可能那么光滑连续,而且越远可能产生的跳变越大!现在对D435I出现很多噪点也比较好理解了吧!
视差是离散的整数,换算出的深度也是离散的,同样是间隔一个视差,离这个相机越远,这个深度间隔就越来越大了。深度越大的时候,同样一个像素对应的深度范围越来越大。如果我的算法精度是一个像素,我稍微偏了一个像素,离相机越远,深度就会偏得越远,同样一个算法,离相机越远,空间精度就会越差。
【【3D视觉工坊】第八期公开课:立体视觉之立体匹配理论与实战-哔哩哔哩】 https://b23.tv/SHkJ8oQ

深度图融合点云生成(MVSNet只能生成深度图)
https://mp.weixin.qq.com/s/ee7-jr8QN8D2MSTyDNeWWw
MVSNet只能生成深度图,需要借助其他点云融合方法。这里Yaoyao(MVSNET的作者)给出了一种方法——fusible.可以直接利用生成的深度图和RGB图片,生成稠密点云。 安装fusible
git clone https://github.com/YoYo000/fusibile
cd fusible
mkdir build && cmake .
make .
运行代码
python depthfusion.py --dense_folder TEST_DATA_FOLDER --fusibile_exe_path FUSIBILE_EXE_PATH --prob_threshold 0.3
注意:每一个深度图在估计的时候,都有一个对应的概率图,及表示该像素沿深度方向不同的概率,所以flag –prob_threhold 表示用于过滤深度的概率阈值,即如果当前深度图的某个像素的深度对应的概率低于该阈值,则在点云融合的时候,该像素的深度不被使用,即该像素不会被投影到三维空间点。这样可以对稠密点云进行过滤优化。 在dense_folder中,之后会生成新的文件夹points_mvsnet。在该文件夹下,找到consisitency_Check-time/final3d_model.ply. 即为融合之后的三维点云,利用meshlab打开即可。
平面扫描和极线搜索是否本质是一样的?
都是已知两个相机帧相对位姿,都是有一个自由度需要估计。都是ill pose问题?
不同深度对应的投影点也都是在一个极线上吧?
传统的MVS里面为什么没有见到讲平面扫描的。
plane-sweeping算法在三维重建中非常重要,其特别适合并行计算,因此通过GPU加速后可以使复杂的稠密重建达到实时。大多实时三维重建的深度图生成部分采用plane-sweeping算法。而且plane-sweeping不用rectify,甚至radial distortion的图像也可以用。研究semantic 3D的Christian Hane直接利用鱼眼相机的图像planes-weeping也得到很好的效果。可以说plane-sweeping和patch-match为三维重建实时和非实时深度图估计的主要算法(摘自: https://blog.csdn.net/qq_28087491/article/details/107078207 )
https://zhuanlan.zhihu.com/p/369656798?utm_id=0
基于投影的技术也在深度图的重建中广泛应用。其中代表的方法就是平面扫描算法(Plane-Sweep)。平面扫描算法的发明者是Collins,他在1996年提出了这个算法,并且用于在输入图片上过滤检测到的边缘,以便于用这些灰度图片对场景进行立体三维重建。平面扫描的输入数据是一系列经过校准的照片。与其他的重建方法一样,平面扫描方法也假设场景中所有物体只有漫反射。平面扫描虚构了一个虚拟的摄像机,在面对这个虚拟摄像机的空间中选定一个远平面以及一个近平面,需要重建的场景的物体要位于这两个平面之间。
平面扫描感觉和这个立体匹配经典算法:PatchMatchStereo有点像 https://blog.csdn.net/Yong_Qi2015/article/details/126900009
能找到这个也是百度搜关键词 立体匹配 平面扫描,这么搜出来的。
PatchMatch与ADCensus等算法不一样的地方的地方在于,视差的计算不是直接进行的,而是通过平面参数计算而来的——立体匹配的过程不是在一维的水平极线上进行搜索得到视差值,而是在3D空间中搜索最佳平面,再通过平面参数反算出视差。这意味着在匹配过程中就可以得到亚像素精度的视差值和正确的平面。
讲平面扫描的这篇博客(https://blog.csdn.net/xuangenihao/article/details/81392684 )里面也说到了PatchMatchStereo,看来我的理解可能没错。
而且从这篇博客似乎可以看出,openmvs深度图估计方法也是平面扫描方法的改进。
从下面这段话似乎可以看出,平面扫描似乎是视差估计较早时候的方法。不过确实平面扫描96年就提出来了。
https://zhuanlan.zhihu.com/p/353854008?utm_id=0
PatchMatchStereo主要提出了更早以前的视差估计方法中的两种做法:
1)以前的视差平面采样都假设各个视差平面前向平行,并且垂直与深度维度,即以光心为原点,以光轴为法线方向垂直均匀采样。 2)视差采样是整数值采样。前向垂直的采样方式不能很好地贴合物体平面 以上两种做法虽然可以得到正确的视差估计结果,但会导致一下视差估计结果出现阶梯现象,视差结果断续不接,仿佛是上台阶一样。
我发现3D视觉工坊的视觉三维重建课程里面也有讲PMS方法也就是PatchMatchStereo,里面也说到了单应矩阵,这个课程是讲传统方法的三维重建的。

你看这个平面扫描的原理图,它移动的点在另一个成像平面上的投影不正就是极线么,上面的图也是的,所以平面扫描本质上是和极线搜索一个意思呀!所以本质还是极线搜索与块匹配的思路应该,此图取自https://blog.csdn.net/qq_41794040/article/details/128064576 ,是MVSNET改进工作的一篇论文里的配图。
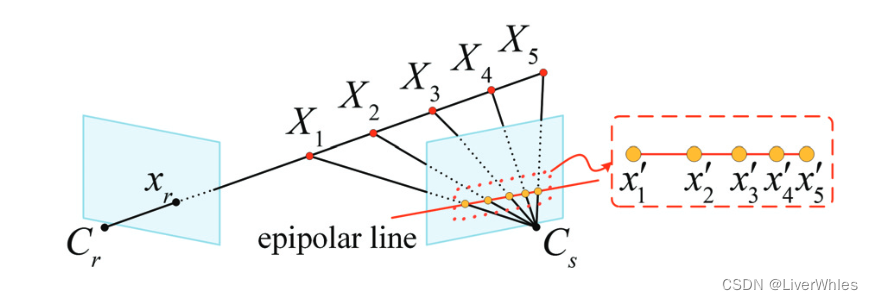
而MVSNET的平面扫描和传统的平面扫描的关系,MVSNET的论文里都有说。

这里也说了类似于极线搜索
https://blog.csdn.net/qq_43307074/article/details/127876458

3D视觉工坊MVSNET课程6.1节里面讲传统MVS流程式,讲师说传统MVS核心流程其实和深度学习MVS流程一样,PPT里传统MVS流程里也有平面扫描。

关于MVSNET中的正则化
下面摘自 https://zhuanlan.zhihu.com/p/646192961?utm_id=0 可以看出无论是在传统方法的立体匹配还是基于深度学习的立体匹配,都是有代价聚合这个步骤的,也叫代价立方体的正则化。
无论是传统立体匹配算法,还是基于深度学习的分离式算法,以及我们现在在描述的端到端的立体匹配算法,代价立方体的估计与正则化都是我认为最重要的步骤之一。
对任何一个像素点,理论上我们会取出代价最小的视差值作为最终的匹配视差,这就是所谓的WTA过程(Winner Take All) 不过,由于图像上的噪声和各种干扰(见70. 三维重建5-立体匹配1,立体匹配算法总体理解的第二节),直接进行WTA计算效果并不好。所以一般的做法是先进行代价聚合,或又称为代价立方体的正则化过程,减轻噪声和干扰的影响。我在文章71. 三维重建6-立体匹配2,立体匹配中的代价聚合中描述了很多传统的代价聚合方案。
所以这么来看,MVSNET的步骤其实可能和传统的立体匹配步骤差不多,只是这些步骤改为神经网络的方式实现。

cost volume regularization
这个cost网络本身是不改变维度的 只是去除噪声更加抽象,真正把32拍成1的是最后一个prob层(soft argmin),最终的物理含义是 某一个pixel的某一个深度假设位置的概率值
在3D视觉工坊的MVSNET课程的3.5节讲MVSNET正则化网络的代码时,doubleZ说到先一路下去,再一路上来,再中间加起来,这就是Unet的架构,这是一个3D的Unet,通过不同尺度的融合,可以让网络有更好的拟合能力。(是否就是这个原因这部分就叫正则化)
我发现基于深度学习点双目立体匹配里面也有代价体正则化这个概念
【从Block Matching到PSMnet:立体匹配算法的深度学习转型-哔哩哔哩】 https://b23.tv/kFpoINk
GC-Net也是用深度学习坐双目立体匹配的
https://blog.csdn.net/qq_43307074/article/details/127145142
GC-Net采用编码-解码结构融合了多尺度的特征信息以实现匹配代价体的正则化。
关于基于MVSNET构建SLAM
半年前计算机视觉life出了个项目课DSO+MVSNET的,但是作者说不能实时运行,我当时没有参加。现在熟悉了下MVSNET之后又有点想看。
现在你想弄我觉得可以去看TANDEM的代码,它似乎也是有点融合DSO+MVSNET的。而且还能输出TSDF形式的全局地图,那讲道理就可以直接进行路径规划了呀!
https://mp.weixin.qq.com/s/Ti3RlpA7LrveM6alDh4ncA
TANDEM论文翻译:https://blog.csdn.net/csjiangxiaoqi/article/details/124363464
github里也搜到一个老哥的 https://github.com/shuoyuanxu/Real-time-Pose-Estimation-and-Dense-Reconstruction-Based-on-DSO-and-MVSNet
我看了这个仓库给的框架图,应该是先通过FDSO获得几个关键帧的位姿,这样才能给MVSNET最终得到深度图,再基于这个深度图得到完整建图,感觉DSO就是起到一个替代colmap的作用?就类似于把前面的SFM跑了先?
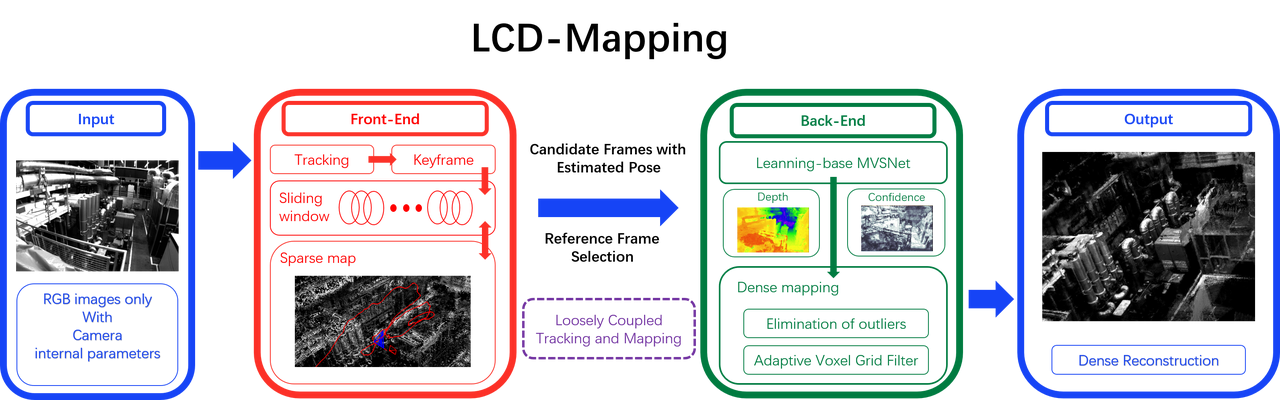
刚刚发现,这个仓库,这个图,就是计算机视觉life当初那个DSO+MVSNET项目的,而且刚刚我基于这个框架图对原理的理解是对的,DSO就是起到挑选几个关键帧而且估计这几个关键帧位姿,作为MVSNET的输入的作用。这个跟TANDEM没法比,更多是个工程化的项目,可能也发不了论文。
https://mp.weixin.qq.com/s/8kLsqiThTSOKCPTdaGyxug

这个也是和DSO结合
话说浙大这个会不会是基于TANDEM改的,因为TANDEM也是用的CVA-MVSNET,再进一步发现,CVA-MVSNET就是在TANDEM里面提出的,专门在TANDEM里面用的,似乎还不能单独像MVSNET一样用因为它还需要DSO输出的稀疏的深度图。 浙大这个论文里面结果也是和TANDEM做对比,https://mp.weixin.qq.com/s/L8w5alXYAySKzYwRhYm4Dw
【面向自主移动机器人的感知和规划前沿进展 | 刘勇-哔哩哔哩】 https://b23.tv/caRcGKw
为什么都喜欢拿DSO和MVSNET做结合
https://github.com/shuoyuanxu/Real-time-Pose-Estimation-and-Dense-Reconstruction-Based-on-DSO-and-MVSNet
Why DSO + MVSNET?:
DSO (Direct Sparse Odometry) uses a sliding window approach for Bundle Adjustment (BA), which makes it an ideal input for MVSNet. In contrast to keyframe-based methods like ORB-SLAM, where choosing the right images for processing can be tricky, DSO's sliding window naturally provides a continuous and optimised set of images. This makes it easier and more effective to integrate with MVSNet for real-time, high-quality 3D reconstruction.
DSO(Direct Sparse Odometry)使用滑动窗口方法进行光束调整(BA),这使其成为MVSNet的理想输入。与ORB-SLAM等基于关键帧的方法不同,在这种方法中,选择正确的图像进行处理可能很棘手,DSO的滑动窗口自然提供了一组连续且优化的图像。这使得与MVSNet集成更容易、更有效地进行实时、高质量的3D重建。
https://mp.weixin.qq.com/s/Ti3RlpA7LrveM6alDh4ncA

MVSNET和基于深度学习的双目立体匹配的关系
像这是GCNET的,它这个把argmin弄成可微分点操作,而且还什么亚像素,这不是和MVSNET说argmax不可微分不能反向传播一样么。这么合起来看,就好理解多了,可能是常规操作。
https://blog.csdn.net/weixin_43685557/article/details/112979972

这是MVSNET论文里说argmax不可微的描述
代价体正则化也都有 【从Block Matching到PSMnet:立体匹配算法的深度学习转型-哔哩哔哩】 https://b23.tv/kFpoINk
GC-Net是做深度学习坐双目立体匹配的
https://blog.csdn.net/qq_43307074/article/details/127145142
GC-Net采用编码-解码结构融合了多尺度的特征信息以实现匹配代价体的正则化。
都有cost volume这个概念
https://blog.csdn.net/weixin_44580210/article/details/125135961
可微分单应变换是MVSNET提出来的,我估计基于深度学习的立体匹配可能没有用到这个或者平面扫描方法?
我发现传统的双目立体匹配就有代价聚合这个概念,百度也能百度出。


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











