







1.补偿Cordic
Cordic技术的一个主要限制是旋转增益。如有必要,在Cordic计算之前或计算之后可以用乘法将该常数因子剔除。补偿Cordic算法是指以不同的方式将这种乘法操作整合到基本的Cordic算法中去。从概念上来说,最简单的方法(最初的步长Cordic算法)是在每步迭代中加入一个1± 2-i 形式的缩放因子。选择符号使得合并后的增益接近于1。这可以归纳为两种方式。第一种是在某些迭代中使用缩放因子,并且选择使增益为2的项,使其能用一个简单的移位移除。虽然电路复杂度会增加很多,但是由于符号是事先确定的,因此传播延迟仅仅增加了一点。
第二种是对于一些角度进行重复迭代来使得总增益G为2。这种方法与原始Cordic使用相同的硬件,仅仅需要增加一小块逻辑控制来代替。这种方法的缺点是比非补偿算法花费更长的时间。一种混合的方法同时使用额外的迭代和缩放因子项,以便减少总的逻辑需求。这种方法最好用于展开的Cordic来实现。
2.线性Cordic
目前对Cordic的讨论都是基于圆形坐标空间的。Cordic迭代也可以应用于线性空间:
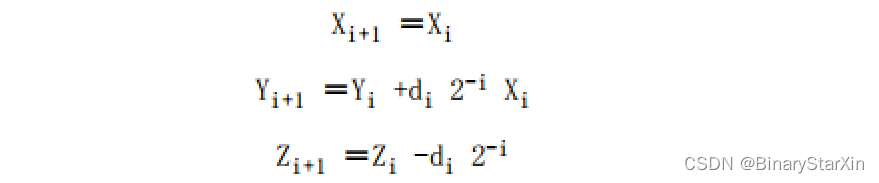
同样地,可以使用旋转模式或者向量化模式。旋转模式下的线性Cordic将Z减小到0。这样就可以替代乘法运算,结果为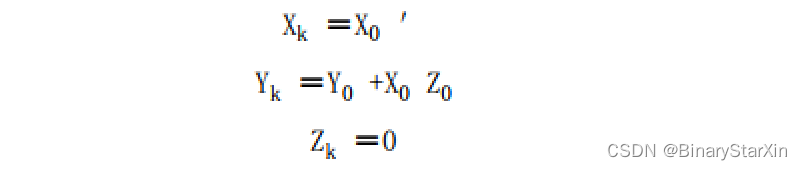
向量化模式则是将y减小到0,并且相当于执行除法运算,结果为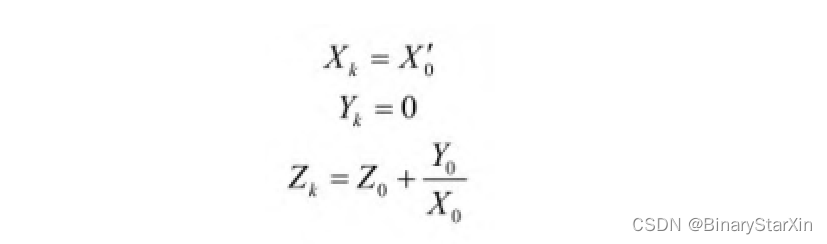
3.双曲Cordic
Cordic也可以用于双曲坐标空间,相关的迭代公式为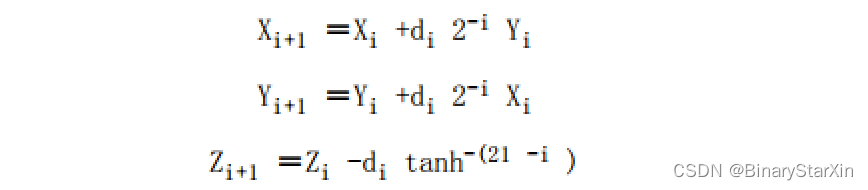
使用该迭代公式同样存在收敛问题,需要重复执行某些迭代。同样需要注意,由于-1﹤tanhx﹤1,因此迭代从i=1开始。由于这些限制,执行旋转模式得到如下结果: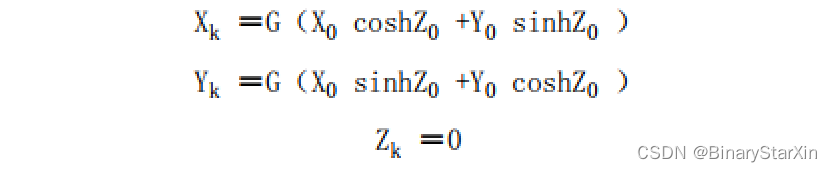
其中,增益因子为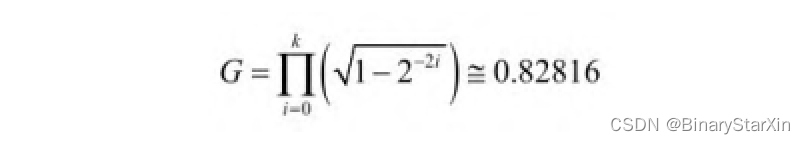
执行向量化的结果为
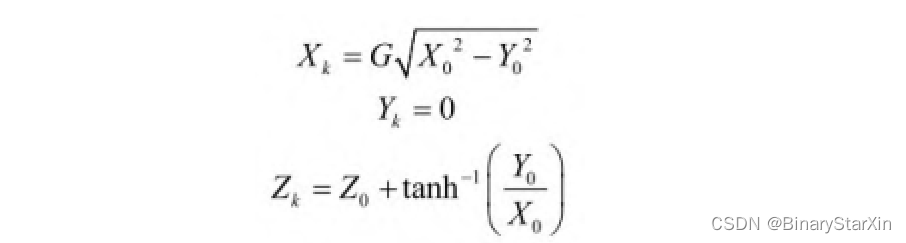
与圆形Cordic一样,可以通过选择合适的值初始化Y或者X寄存器(对于旋转模式)或者引入额外的补偿操作来补偿增益。上面讨论的很多补偿Cordic都适用于双曲坐标系统。
不同坐标系的Cordic迭代可以结合起来适用同一个硬件(多路复用器选择X寄存器的输入)。对于三种坐标空间都可以适用,当然也可以计算一些其他的常见函数,如下所示:

4.Cordic的变换和推广
Cordic的基础是通过的整数次幂来使能对一个任意的数进行移位从而减小乘法操作。这可以扩展到对其他函数的直接计算。关系式
lnx(1+2i )=lnx+ln(1+2i )
允许用移位和加法计算对数。其思想是用一系列乘法操作连续将x减小到1,并累加从一个小表中获取相关的对数项。迭代公式为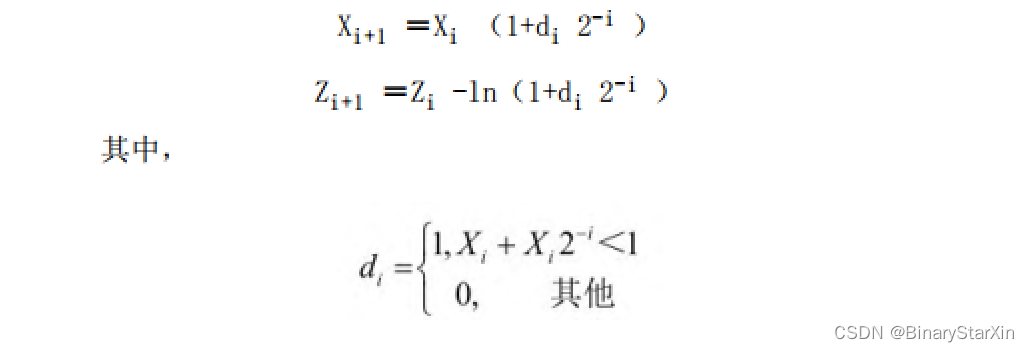
另外,若使用因子(1+di 2-i ),则迭代在=1≤X0 <3.4627时收敛。迭代公式也可以很容易通过改变累加到Z寄存器的常数表来求其他底数的对数。该算法也可以以其他方式运行,通过将Zi 减少到0,给出指数函数。
Muller(1985)支出该迭代与Cordic迭代具有相同的原理,并将它们置于同一个框架内。由于三角函数可以使用欧拉公式由复指数导出:

因此,可以把迭代公式推广到复数范围,使得计算三角函数无须与Cordic相关的增益因子。这种实现的另一个好处是它允许使用冗余运算,可以利用“若di ∈{-1,0,1},则di 的选择范围区间会有重叠”这一事实。这意味着只需要计算少量的高有效位就能确定下一个数字,这就减少了进位传播延时的影响。
虽然Cordic和其他基于一维和加法的算法都具有相对简单的电路,但是它们的主要缺点是收敛速度比较慢。每次迭代结果只改进了1位。还有一个缺点是它们仅能计算几个初等函数,更复杂的函数或者符合函数则需要对许多初等函数求值。
5.Cordic计算实例
本书将在第7.3.3章节中详细介绍Cordic的实现方法,这里仅列出利用Cordic计算正余弦函数的结果图,如图4-20所示(仅计算区间)。
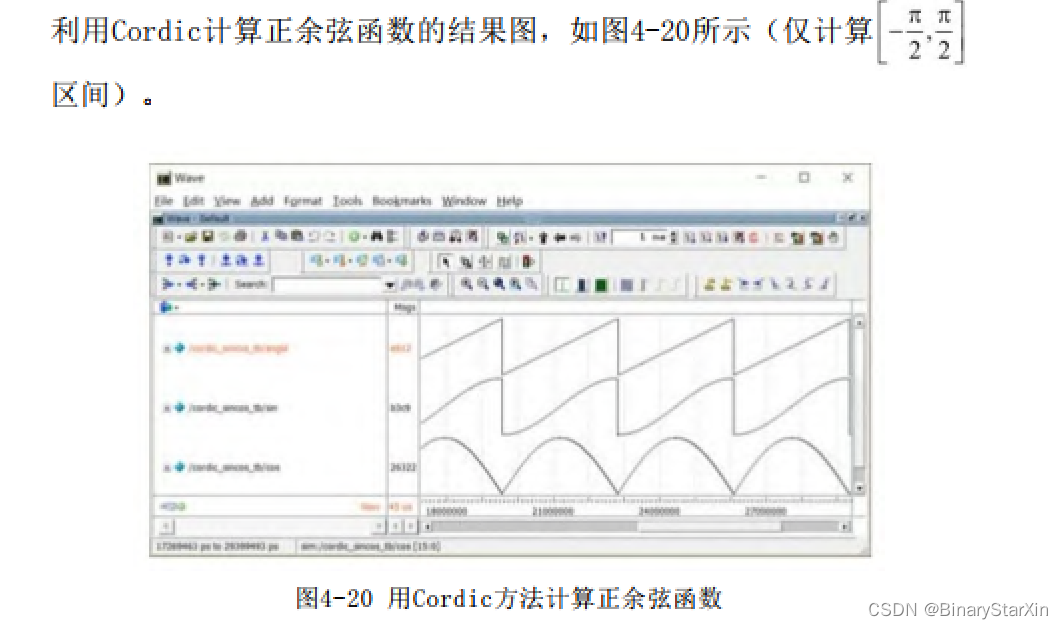
作为与浮点运算的对比,我们列出用Cordic计算正余弦的资源消耗情况,如图4-21所示。
Cordic内核仅需1056个逻辑单元就可以同时计算出正弦和余弦值,相对于浮点运算(包括定点与浮点的相互转换),可以节省90%以上的资源。
4.3 存储器映射
一般情况下,我们希望当数据流过FPGA时,FPGA尽可能多地处理数据,并且减少FPGA和外部设备之间的数据传输,采用流水线处理架构则可以很好地减少对存储器的频繁读写。然而在某些情况下,一个图像处理算法需要像素之间的行列同步或是帧同步,这个时候就必须要缓存部分图像或者是整幅图像。例如,在二维卷积运算的过程中,往往会缓存若干行图像,而在做直方图均衡或是连续帧求均值,带宽匹配的过程中,我们可能需要至少缓存若干帧图像。
在软件处理中,这个缓存通常情况下是放在内存中,需要的时候从内存进行读取。在FPGA中,可以选择将缓存放在FPGA内部或者外部。
以下是一个对连续三帧图像求均值的运算的结构图,电路采用了两个帧缓存电路FrameBuffer来实现前两帧的缓存,加上当前帧的像素值除以3即可得到最终的结果,如图4-22所示。
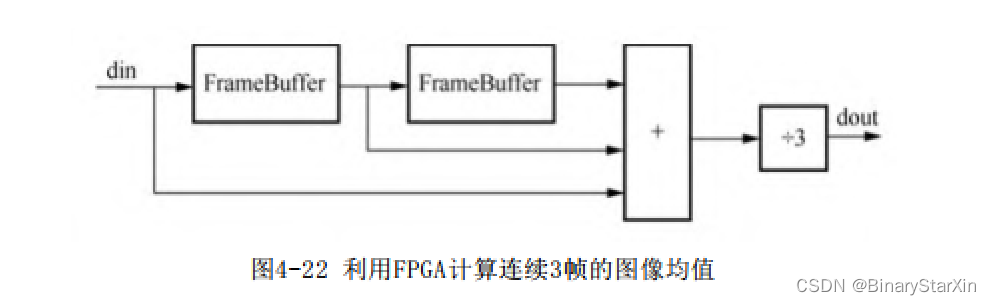
虽然现在的FPGA内部有足够大的存储器资源,但是存放若干幅分辨率比较高的图像会稍显浪费。如果担心整个系统的成本较高,而不愿投入太多,那么生产出来的FPGA内部存储器资源往往还不够存放一副图像。此外,在系统调试的过程中需要大量的存储器资源进行调试资源。鉴于以上原因,我们很少会把帧缓存放在FPGA内部(图像分辨率比较小的除外),而往往会将其存放在片外的静态存储器或动态存储器中。
以下是一个典型的二维3×3卷积运算的结构图(见图4-23)。二维卷积通常会对图像进行开窗,以3×3的窗口为例,至少需要得到当前窗口的9个像素值,卷积操作的流水线性质决定了一个时刻只能得到一个像素值。如果要得到前两行的像素,就必要对前两行的像素值进行缓存。
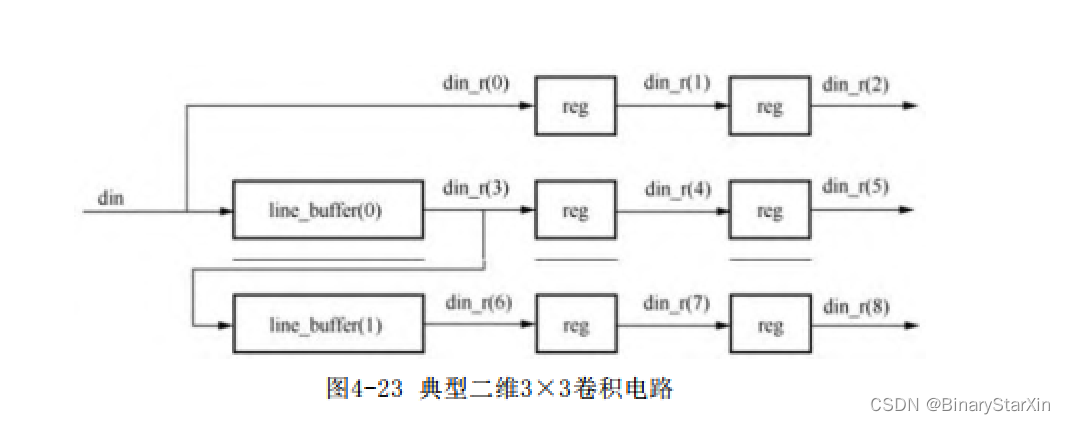
行缓存通常会放在FPGA片内,这是由于行缓存通常不会很大,对于一个确定的算法,窗口尺寸往往已经确定。实际上,对于一个窗口尺寸为3×3的二维卷积算法,我们至少需要2个行缓存。
4.3.1 帧缓存
在上面也提到,对于帧缓存,通常情况下会将其放在片外进行读写。对于帧缓存,在成本不够敏感的情况下,最好使用静态存储器(SRAM),尤其是用于需要频繁和随机地访问这些帧缓存的地方。静态存储器相对于动态存储器来说,通常情况下读写接口相对简单,读写速度要快,并且功耗相对较低。但是,由于静态存储器每一位要使用6个晶体管,而动态存储器每位只使用一个晶体管,因此静态存储器的价格要贵得多。这也限制了它在成本敏感场合的应用。由于静态存储器的读写时序比较简单,通常情况下会开发读写时序来实现最大的灵活性。
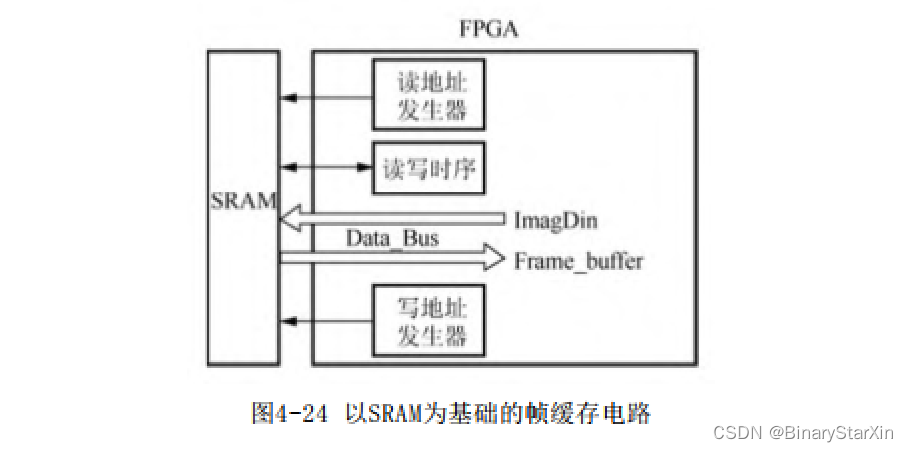
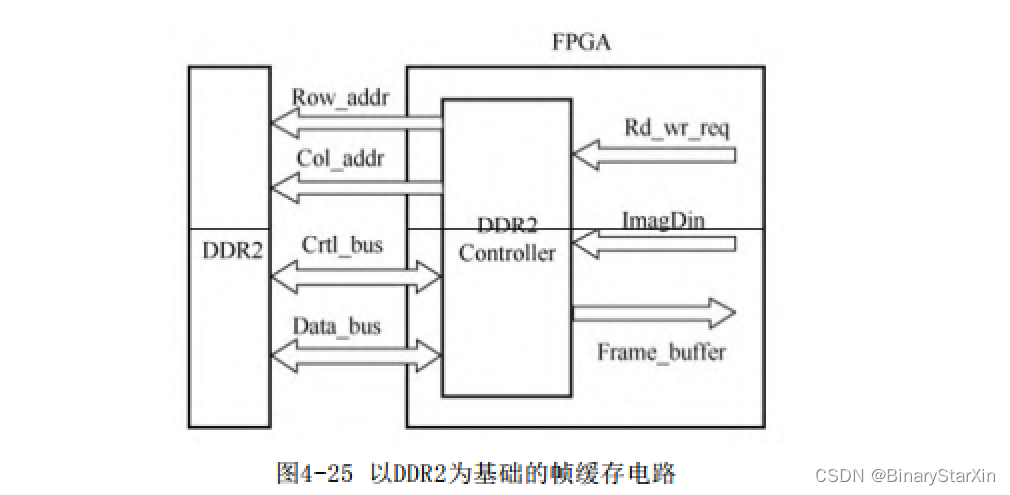
一个帧缓存控制电路要包括读地址发生器、写地址发生器及读写控制时序。一般情况下,这个写地址即为输入帧数据流ImageDin的行列地址,而读地址为输出流Frame_buffer的行列地址。以SRAM为基础的帧缓存电路如图4-24所示。
如果系统对于读取速度没有严格要求的缓存应用,那么动态存储器无疑是更好的选择。虽然动态存储器存取速度较慢,从主机提供地址到数据输出可能需要若干个时钟,但是当动态存储器工作在突发模式时,也可以提供较大的带宽,这对于图像处理这样的大数据应用场合非常有用。
动态存储器的接口设计相对比较复杂,这是由于动态存储器必须要间隔一段时间对其进行刷新来保持当前的存储器内容。此外,与静态存储器不同,动态存储器的行列地址通常是分开的。因此对动态存储器的寻址工作需要分别进行行列寻址工作。通常情况下,我们会直接采用FPGA厂家提供的IP核来实现外部的存储器驱动,这样可以大大提高开发的效率。
以动态存储器DDR2为基础的帧缓存电路如图4-25所示。
4.3.2 行缓存
正如前面所述,行缓存通常情况下会放在片内。每一个行缓存有效地将输入延迟了一行。用阶数为图像宽度的移位寄存器是可以方便地实现这种延迟。但是在FPGA里面实现这种操作有几个问题。首先,移位寄存器是由一连串的移位寄存器来实现的,每个位都适用一个寄存器,而每个逻辑单元都只有一个寄存器,因此,采用移位寄存器的方式将会占用大量的逻辑资源,特别是在图像宽度比较大的时候,用内部资源来实现行缓存往往是不明智的选择。设计行缓存时,通常会选择利用FPGA片内的RAM块来实现。
行缓存里面存放正好一行的图像数据,其深度应该至少为图像的宽度。行缓存的写入时刻是当前行(待写入缓存的图像行)有效的时候,写满一行后停止写入,等待读出信号。一般情况下,读出信号要在下次写入之前发出,否则就会出错。出错的一种情况是,存储器写满造成写入失败,这种情况是针对FIFO形式的行缓存而言;另外一种情况是,数据覆盖造成读出错误,这种主要是针对RAM形式的行缓存而言。
如果采用RAM作为行缓存,就需要设计写入和读出地址产生电路。写入地址就是输入图像行的列地址,读出地址就是输出图像行的列地址。若采用FIFO作为行缓存,则顺序写入与读出即可:行缓存不存在随机存取的情形。由于FIFO形式节省了一定的外围电路,相对RAM形式的缓存则可以节省一定的资源。如果外围已经有行列计数电路,那么采用RAM形式的行缓存也不会带来额外的资源开销。
行缓存的理想工作状态也是流状态:也就是除了缓存装载和卸载,缓存内部的数据流入和流出是平衡的,这样才不至于破坏系统的流水线。输入图像数据的到来时刻是由上一级时序所控制,输出图像的数据流则与行缓存息息相关。为了达到理想的流状态,缓存的打出时刻应该刚好在缓存装载完毕,也就是装载完一整行的时候,此刻将数据打出作为输出图像行数据,打出的时刻也就是输出图像行数据有效信号。这个时刻的输入数据流和输出数据流正好完成对齐,也就是在同一时刻得到了连续两行对齐的图像数据。同时,在接下来的数据流过程中,行缓存一直处于流状态,也可以把它看成一个阶数为图像宽度的移位寄存器组。
1.行缓存实例
图4-26所示是以FIFO作为行缓存的一个应用电路。
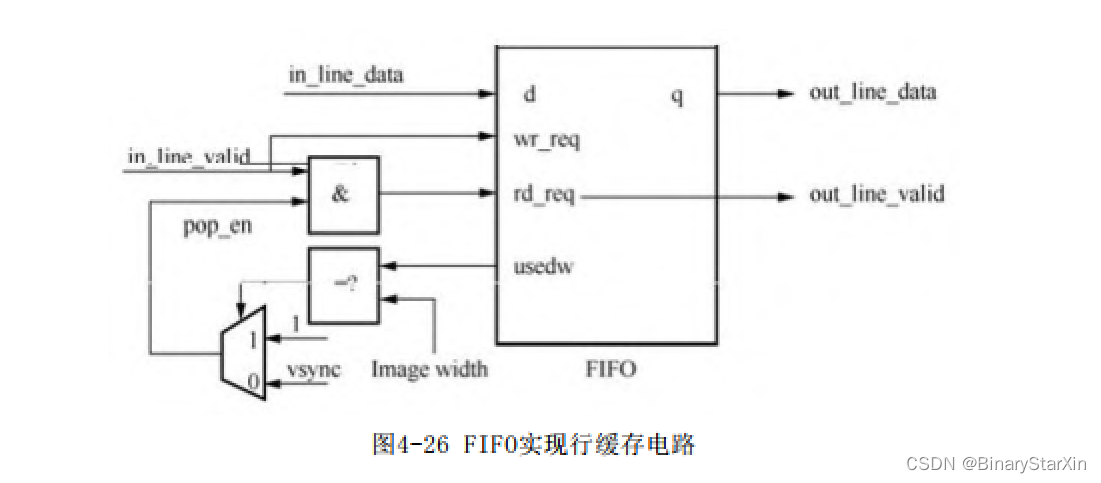
在构建内部缓存的时候要充分考虑FPGA厂家所提供的RAM块的物理结构,尽量做到资源利用最大化,有必要时可以将多个FIFO使用同一个RAM块来实现。同时结合所需位宽和深度进行综合考虑和设计,设计完成后可以根据实际的综合情况对其进行优化。以下是一个构建方法实例:
module line_buffer (
rst,
clk,
din,
dout,
wr_en,
rd_en,
empty,
full,
count
);
parameter DW = 14;parameter IW = 640;
parameter DEPTH = 1024;
parameter DW_DEPTH = 10;
localparam DW_PER_FIFO = 8;//用8位位宽的FIFO模块进行拼
接
localparam DW_PER_FIFO_LOG2 = 3;
localparam FIFO_NUM = ((DW+DW_PER_FIFO-1)>>
DW_PER_FIFO_LOG2);
//所需FIFO的数目
input rst;
input clk;
input [DW-1:0]din;
output [DW-1:0]dout;
input wr_en;
input rd_en;
output empty;
output full;
output [DW_DEPTH-1:0]count;
wire [DW_PER_FIFO-1:0]din_temp[0:FIFO_NUM-1];
wire [DW_PER_FIFO*FIFO_NUM-1:0]dout_temp;
assign din_temp[0]= din[DW_PER_FIFO-1-:DW_PER_FIFO];
altera_fifo_640 #(DW_PER_FIFO,DEPTH,DW_DEPTH)//例化低8
位
buf_lsb(
.aclr(rst),
.clock(clk),
.data(din_temp[0]),.rdreq(rd_en),
.wrreq(wr_en),
.q(dout_temp[DW_PER_FIFO-1:0]),
.usedw(count),
.empty(empty),
.full(full)
);
assign dout = dout_temp[DW-1:0];
generate
begin :fifo_generate
genvar i;
genvar j;
for (j = 1; j <= FIFO_NUM - 2; j = j + 1)
begin :xhdl1
assign din_temp[j]= din[DW_PER_FIFO*
(j+1)-1-:DW_PER_FIFO];
end
if(FIFO_NUM>1)
assign din_temp[FIFO_NUM - 1]=
{{DW_PER_FIFO*FIFO_NUMDW{1'b0}},din[DW-1:DW_PER_FIFO*(FIFO_NUM-
1)]};
for (i = 1; i <= FIFO_NUM - 1; i = i + 1)
begin :xhdl2
altera_fifo_640 #(DW_PER_FIFO,DEPTH,DW_DEPTH)
//参数分别为位宽,深度,深度的位宽
buf_others(.aclr(rst),
.clock(clk),
.data(din_temp[i]),
.rdreq(rd_en),
.wrreq(wr_en),
.q(dout_temp[DW_PER_FIFO*
(i+1)-1-:DW_PER_FIFO])
);
end
end
endgenerate
endmodule















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











