







目录
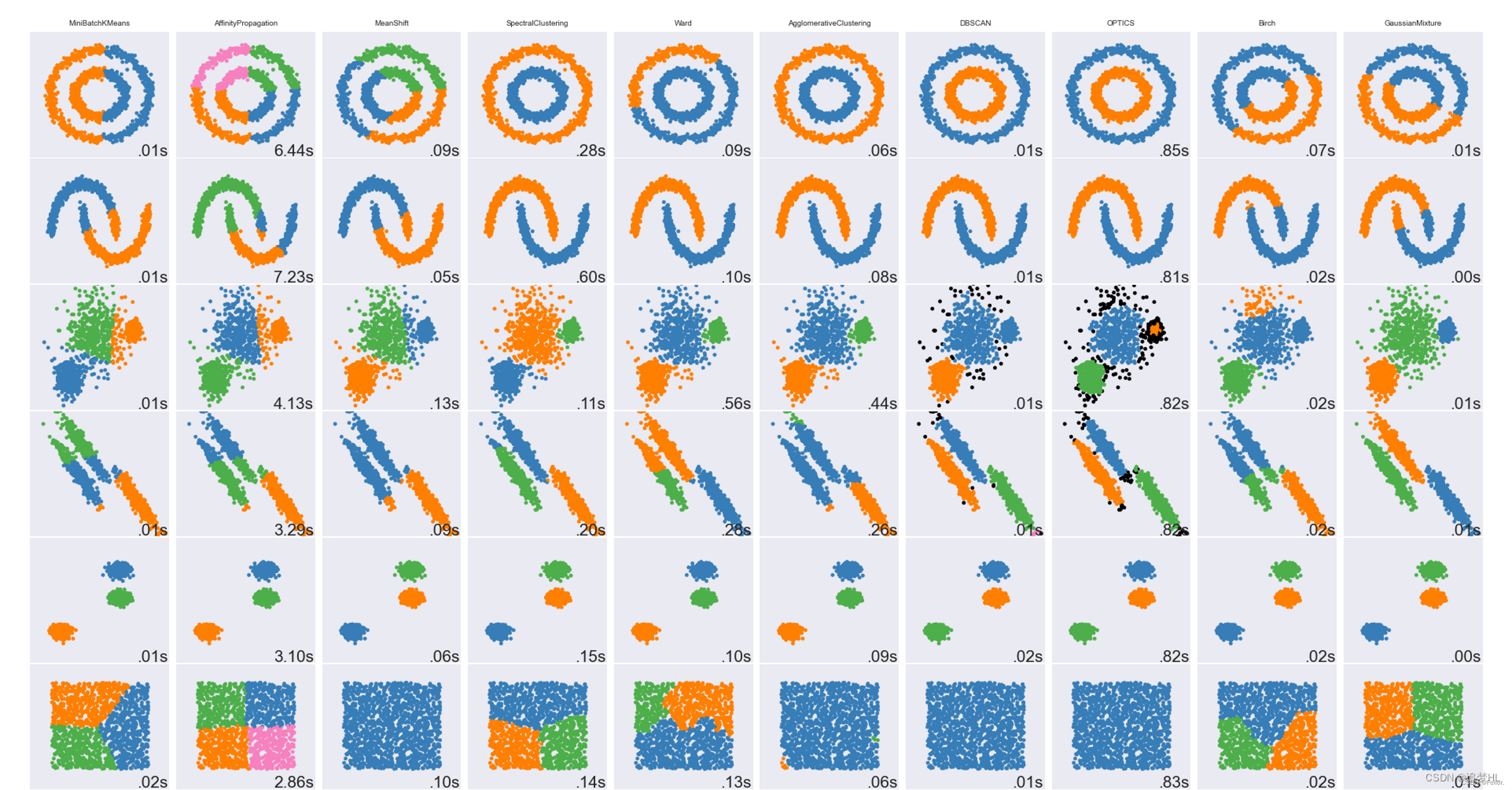
主要记录下在自动驾驶项目开发中用过的几类基础的、常用的点云聚类算法,主要应用方向是局部动态目标的识别处理。点云聚类常用的算法有k均值算法、高斯混合聚类、层次聚类、DBSCAN等。
下述算法主要转载自以下博文:
K均值算法
【K均值算法基本思想】K-means 是一种广泛使用的聚类算法,它的目标是将数据点分组到 K 个簇中,以使簇内的点尽可能相似,而簇间的点尽可能不同。它的核心思想是通过迭代优化簇中心的位置,以最小化簇内的平方误差总和。
【K均值算法步骤】
1、初始化:随机选择 K 个数据点作为初始簇中心;
2、分配:将每个数据点分配给最近的簇中心;
3、更新:重新计算每个簇的中心(即簇内所有点的均值);
4、迭代:重复步骤 2 和 3 直到簇中心不再发生变化或达到预设的迭代次数。
K-means目标函数是试图最小化簇内误差平方和,其公式为:
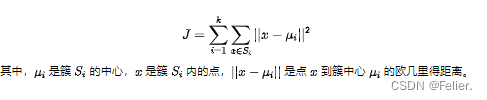
【K均值适用场景】K-means 算法简单高效,广泛应用于各种场景,特别是在需要快速、初步的数据分组时。然而,它也有局限性,比如对初始簇中心的选择敏感,可能会陷入局部最优,且假设簇是凸形的,对于复杂形状的数据可能不适用。
参考文献: 聚类算法全总结
DBSCAN算法
【DBSCAN算法基本思想】DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,特别适用于具有噪声的数据集和能够发现任意形状簇的情况。它不需要事先指定簇的数量,能有效处理异常点。
DBSCAN算法的核心思想是通过两个参数来定义数据点的密度:邻域半径(ε)和最小邻居数(minPts)。对于一个数据点,如果它的ε-邻域内包含至少minPts个数据点,则将其视为核心点(core point);如果一个点在另一个核心点的ε-邻域内,那么它也被视为核心点的一部分;剩下的既不是核心点也不在核心点的ε-邻域内的点则被视为噪声点(noise point)。基于这些定义,DBSCAN将数据点划分为核心点、边界点(border point)和噪声点。
【DBSCAN算法步骤】
1、选择一个未被访问的数据点;
2、检查该点的ε-邻域内是否包含至少minPts个数据点,若是,则将其标记为核心点,并将其密度直接可达的所有点归为同一簇;
3、若该点不是核心点,则继续选择下一个未被访问的数据点;
4、重复以上步骤,直到所有的数据点都被访问过。
【DBSCAN应用场景】DBSCAN算法具有以下优点:不需要预先指定簇的数量;能够发现任意形状的簇;对噪声点具有鲁棒性。缺点,对于高维数据集,由于维度灾难的影响,DBSCAN的性能可能会下降。
参考文献: 三维点云-聚类-CSDN博客
层次聚类算法
【层次聚类算法基本思想】层次聚类(Hierarchical Clustering)是通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。层次聚类算法分为两类:自上而下和自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并类,直到所有类合并成一个包含所有数据点的单一聚类。
【层次聚类算法步骤】
1.首先将每个数据点作为一个单个类,然后根据选择的度量方法计算两聚类之间的距离。
2.对所有数据点中最为相似的两个数据点进行组合,形成具有最小平均连接的组。
3.重复迭代步骤2直到只有一个包含所有数据点的聚类为止。
【层次聚类算法应用场景】
优点:无需指定聚类的数量;对距离度量的选择不敏感;当底层数据具有层次结构时,可以恢复层次结构
缺点:时间复杂度为O(n³)
参考文献: 聚类算法——层次聚类算法 - 知乎
高斯混合模型
【高斯混合模型的基本思想】高斯混合聚类是一种基于概率分布的聚类算法,它是首先假设每个簇符合不同的高斯分布,也就是多元正态分布,说白了就是每个簇内的数据会符合一定的数据分布。
它的大致流程就是首先假设k个高斯分布,然后判断每个样本符合各个分布的概率,将该样本划为概率最大的那个分布簇内,然后一轮后,进行更新我们的高斯分布参数,就会用到我们的极大似然估计,然后再基于新的分布去计算符合各个分布的概率,不断迭代更新,直至模型收敛达到局部最优解,常见的算法就是EM算法,它会同时估计出每个样本所属的簇类别以及每个簇的概率分布的参数。
【高斯混合模型的算法步骤】



















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











