










梯度下降算法 Gradient-Descend 数学推导与源码详解 深度学习 Pytorch笔记 B站刘二大人(2/10)
数学原理分析
在第一节中我们定义并构建了线性模型,即最简单的深度学习模型,但是深度学习通常是由四个环节构成,准备数据,构建模型,定义损失与优化函数,循环迭代训练。其中非常重要的就是让模型在每次的循环中进行自我优化,并将模型逐渐优化为理想中的高准确率模型。
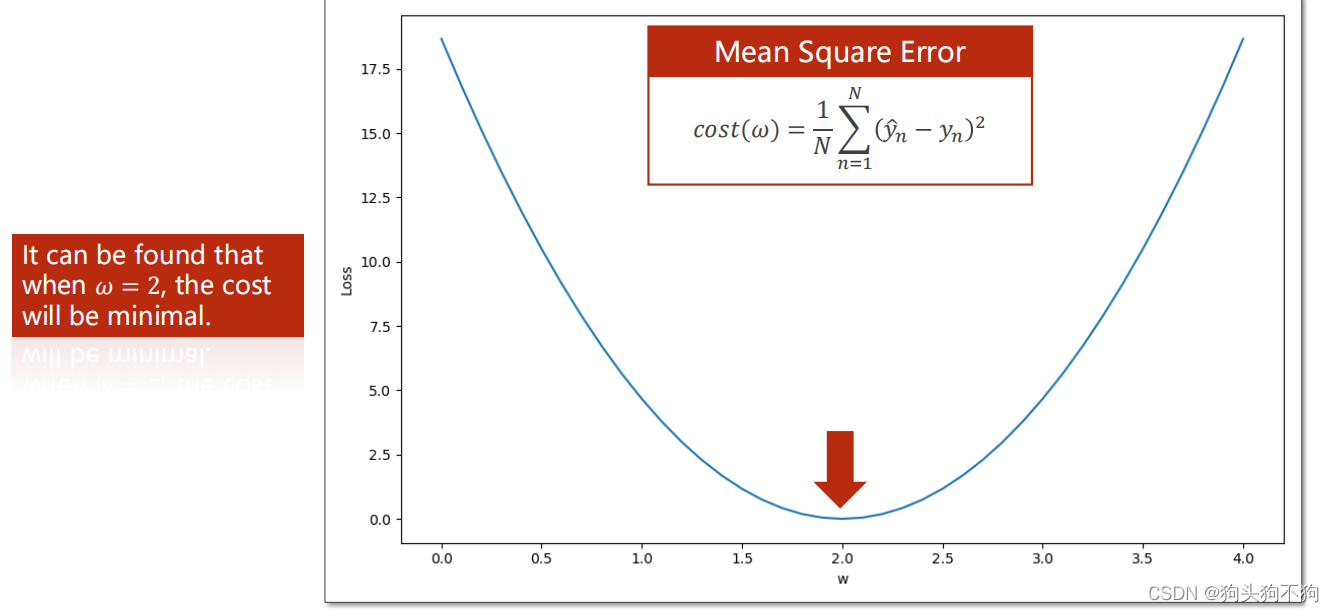
即我们要找到一种方法,使得模型的参数w不停逼近理想化的值w0,使得整体模型的训练损失loss最小,在(1/10)中可以具体体现为让权重参数w对应模型的loss停留在损失曲线谷底,使得训练结束后w尽可能靠近w=2.0
梯度下降法
梯度下降法是在寻优过程中最简单也是最普遍的应用方法,目的是沿着梯度的方向找到一个函数的局部最小值
通过梯度的概念我们知道,梯度表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。
显然我们知道如果按照一定的移动步长,沿梯度减小的方向,不断的进行更新。在越“陡峭”的地方,一次下降的距离越大;在越平缓,越接近谷底的位置,则一次下降的距离越小。这样在足够多此的迭代后,将接近该函数的局部最小值,这一方法也被称梯度下降法,是迭代法的一种,可以用于求解线性和非线性的最小二乘问题。
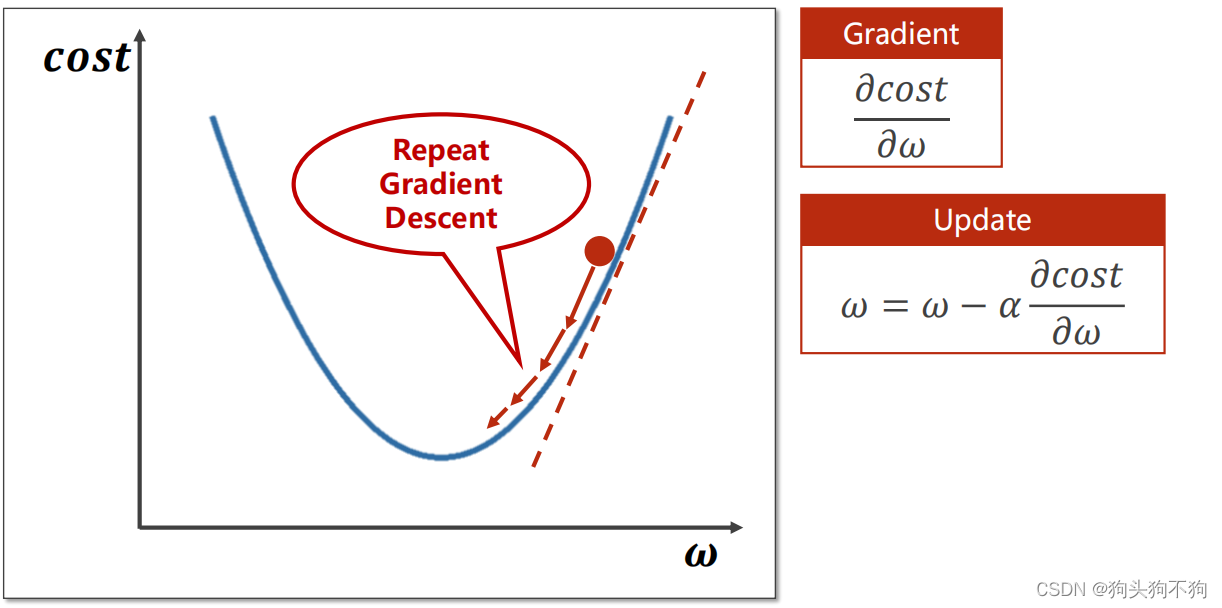
在上图中alpha即为每次的迭代步长,这样进行多次迭代,w的取值最终将趋于曲线谷底。
加上forward函数后的推导如图

其中xn×w-yn是之前定义的损失函数,最终将梯度公式求解得到只于x,w,y有关表达式
源码解读与实现
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0] # 定义原始数据集
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return w * x
def loss(xs, ys):
y_pred = forward(xs) # 定义损失函数
return (y_pred - ys) ** 2 # 返回损失平方
def gradient(xs,ys):
return 2 * x * (x * w - y) # 对单个数据取梯度,即上文推导表达式结果
print('Predict before training', 4, forward(4))
for epoch in range(100):
for x,y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad # 取步长alpha为0.01,即每一次训练梯度grad*0.01进行优化更新
print('\t grad: ', x, y, grad)
l = loss(x,y)
print('progress', epoch, 'w= ', w, 'loss= ', l)
print('Predict after training', 4, forward(4))















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











