







Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
我们提出了 Pathways (Dean, 2021) 自回归文本到图像 (Pathways Autoregressive Text-to-Image,Parti) 模型,该模型可生成高保真逼真图像,并支持涉及复杂构图和世界知识的内容丰富的合成。 Parti 将文本到图像的生成视为序列到序列的建模问题,类似于机器翻译,以图像标记序列作为目标输出,而不是另一种语言中的文本标记。 这种策略自然可以利用大型语言模型的丰富先前工作,这些模型通过扩展数据和模型大小在功能和性能方面不断取得进步。 我们的方法很简单:首先,Parti 使用基于 Transformer 的图像标记器(tokenizer) ViT-VQGAN 将图像编码为离散标记序列。 其次,我们通过将编码器-解码器 Transformer 模型扩展至 20B 参数来实现一致的质量改进,在 MS-COCO 上新的最先进的零样本 FID 得分为 7.23,微调后的 FID 得分为 3.22。 我们对 Localized Narratives 以及 PartiPrompts (P2)(超过 1600 个英语提示的新整体基准)进行了详细分析,证明了 Parti 在各种类别和难度方面的有效性。 我们还探索并强调我们模型的局限性,以便定义和举例说明进一步改进的重点关注领域。 请参阅 parti.research.google 以获取高分辨率图像。
1. 简介
人们通常能够通过书面或口头语言的描述来想象丰富而详细的场景。 支持基于此类描述生成图像的能力可能会解锁生活许多领域的创意应用,包括艺术、设计和多媒体内容创建。
- 最近关于文本到图像生成的研究,例如 DALL-E(Ramesh 等人,2021)和 CogView(Ding 等人,2021),在生成高保真图像和展示对未见过的对象和概念的组合的泛化能力方面取得了重大进展。 两者都将任务视为语言建模的一种形式,从文本描述到视觉单词,并使用 Transformers(Vaswani 等人,2017)等现代序列到序列架构来学习语言输入和视觉输出之间的关系。
- 这些方法的关键是通过使用 dVAE (Rolfe, 2017) 或 VQ-VAE (Van Den Oord et al., 2017) 等图像标记器(tokenizer)将每个图像转换为一系列离散单元。 视觉标记化本质上统一了文本和图像的视图,以便两者都可以被简单地视为离散标记的序列,从而适用于序列到序列模型。
- 为此,DALL-E 和 CogView 采用了类似于 GPT 的仅解码器语言模型(Radford 等人,2018 年),从大量潜在噪声文本图像对中学习(Changpinyo 等人,2021 年;Jia 等人,2021a)。
- Make-A-Scene(Gafni 等人,2022)进一步扩展了这种两阶段建模方法,以支持文本和场景引导图像生成。
另一条具有相当势头的研究涉及基于扩散的文本到图像模型,例如 GLIDE(Nichol 等人,2022)以及同期作品 DALL-E 2(Ramesh 等人,2022)(又名 unCLIP) 和 Imagen(Saharia 等人,2022)。
- 这些模型避免使用离散图像标记,而是使用扩散模型(Ho et al., 2020;Dhariwal & Nichol, 2021)来直接生成图像。
- 这些模型提高了 MS-COCO 上的零样本FID 分数(Lin 等人,2014),并且与之前的工作相比,生成的图像质量明显更高,更具美感。
- 即便如此,考虑到之前在扩展大型语言模型方面所做的大量工作(Brown 等人,2020;Cohen 等人,2022;Du 等人,2022;Chowdhery 等人, 2022a)以及离散化其他模态(例如图像和音频)方面的进步(以便这些输入模态可以被视为类似语言的标记),用于文本到图像生成的自回归模型仍然有吸引力。
- 本文工作提出了 Pathways 自回归文本到图像 (Pathways Autoregressive Text-to-Image,Parti) 模型,该模型根据文本描述生成高质量图像,包括逼真的图像、绘画、绘图等(见图 1 和图 2)。
- 我们证明,使用 ViT-VQGAN (Yu et al., 2022a) 图像标记器,扩展自回归模型是改进文本到图像生成的有效方法,使此类模型能够准确地集成和直观地传达世界知识。

Parti 是基于 Transformer 的序列到序列模型 (Vaswani et al., 2017),该架构对于许多任务的性能至关重要,包括机器翻译 (Vaswani et al., 2017)、语音识别 (Zhang et al., 2017;Gulati 等人,2020)、会话建模(Adiwardana 等人,2020)、图像标题(Yu 等人,2022b)等等。
- Parti 将文本标记作为编码器的输入,并使用解码器自回归地预测离散图像标记(参见图 3)。
- 图像标记由基于 Transformer 的 ViT-VQGAN 图像标记器生成(Yu et al., 2022a),与 dVAE (Rolfe, 2017)、VQ-VAE (Van Den Oord et al., 2017) 和 VQGAN (Esser et al., 2021) 相比,它可以产生更高保真度的重建输出,并且具有更好的码本利用率。
- Parti 在概念上很简单:它的所有组件 - 编码器、解码器和图像标记器 - 都基于标准 Transformer(Vaswani 等人,2017)。 这种简单性使得使用标准技术和现有基础设施可以直接扩展我们的模型(Shoeybi 等人,2019;Du 等人,2022;Chowdhery 等人,2022a;Xu 等人,2021)。
- 为了探索这种两阶段文本到图像框架的局限性,我们将 Parti 模型的参数大小扩展到 20B,并观察到文本图像对齐和图像质量方面的一致质量改进。 20B Parti 模型在 MS-COCO 上实现了新的最先进的零样本 FID 分数 7.23 和微调 FID 分数 3.22。


虽然最近的工作主要集中在 MS-COCO 基准测试上,但我们还表明,可以在 Localized Narratives 数据集上实现强大的零样本和微调结果(Pont-Tuset 等人,2020),该数据集的描述比 MS-COCO 的描述的平均长 4 倍。
- 这些结果证明了 Parti 对更长描述的强大泛化能力,使我们能够在模型探索中增加相当大的复杂性(参见图 2 和附录中的示例,以及第 6.2 节中种植樱桃树(Growing a Cherry Tree)的讨论)。
- 尽管如此,现有的标题/描述数据集仅限于照片及其内容的描述,但文本到图像模型的大部分吸引力在于它们可以为奇幻的提示产生新颖的输出。
- 鉴于此,我们引入了 PartiPrompts (P2),这是一组丰富的超过 1600 个(英语)提示,旨在衡量在各种类别和受控难度维度上的模型能力(Imagen(Saharia 等人,2022)出于类似目的在 DrawBench 中引入了 200 个提示(讨论见 4.3 节)。
- P2 中的每个提示都与一个广泛的类别(12 个类别,从抽象到动物、交通工具和世界知识)和一个挑战维度(11 个方面,从基本到数量、单词和符号、语言学和复杂)。
- 我们对 MS-COCO、Localized Narratives 和 P2 进行详细分析和人类评估,以及对 Parti 局限性的广泛讨论(第 6.3 节),全面了解 Parti 模型的优点和缺点,并建立自回归模型作为高质量、功能广泛、开放域的文本到图像生成模型的有力竞争者。
我们的主要贡献包括:
- 我们证明自回归模型可以实现最先进的性能:在 MS-COCO 上零样本和微调 FID 分别为 7.23 和 3.22,在 Localized Narratives 上零样本和微调 FID 分别为 15.97 和 8.39
- 规模很重要:我们最大的 Parti 模型 (20B) 最有能力生成高保真照片级真实感图像,并支持内容丰富的合成,特别是涉及复杂构图和世界知识的合成
- 我们还引入了一个整体基准,PartiPrompts(P2),提出了种植樱桃树(Growing a Cherry Tree)的新概念,建立了关于识别文本到图像生成模型的局限性的新先例,并针对我们观察到的错误类型,提供了详细的带有示例的细分(breakdown)。
2. Parti 模型
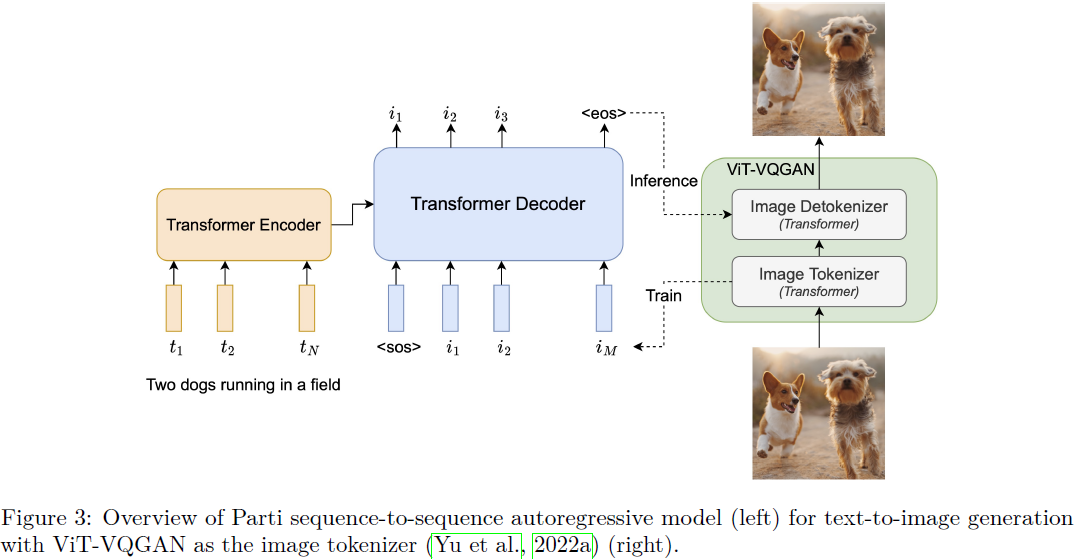
与 DALL-E(Ramesh 等人,2021)、CogView(Ding 等人,2021)和 Make-A-Scene(Gafni 等人,2022)类似,Parti 是一个两阶段模型,由图像标记器和自回归模型组成,如图 3 所示。
- 第一阶段涉及训练标记器,将图像转换为一系列离散视觉标记,用于训练并在推理时重建图像。
- 第二阶段训练自回归序列到序列模型,该模型从文本标记生成图像标记。
- 我们在下面描述这两个阶段的详细信息,以及用于构建高性能自回归文本到图像模型的其他技术,例如文本编码器预训练、无分类器指导和重新排名。
2.1 图像标记器(Tokenizer)
自回归文本到图像模型必须将 2D 图像线性化为补丁表示的 1D 序列。
- 在极限情况下,这些只是像素,就像 iGPT (Chen et al., 2020) 一样,但这需要对非常长的序列进行建模,即使对于小图像也是如此(例如,256×256×3 RGB 图像会产生 196,608 个光栅化(rasterized)值)。
- 更糟糕的是,它基于输入的非常低级的表示,而不是通过图像上下文中像素的位置来了解的更丰富的表示。 之前的工作(Van Den Oord 等人,2017;Ramesh 等人,2021;Yu 等人,2022a;Gafni 等人,2022)通过使用 dVAE,来学习原始图像集合上图像块的量化表示,从而解决这个问题。
- 学习量化表示不是学习可以在潜在空间中取任何值的表示,而是学习将补丁嵌入映射到其最近的码本条目的视觉码本,码本是在潜在空间中学到的且可索引的位置。 这些条目可以被认为是视觉单词类型(types),因此给定图像中的补丁中任何这些单词都是图像标记(token)。
为了对第二阶段模型最有用,图像标记器需要学习一个有效的视觉码本,该码本支持在广泛的图像中平衡使用其条目。
- 它还必须支持将一系列视觉标记重建为高质量的输出图像。 我们使用 ViT-VQGAN (Yu et al., 2022a) 以及 ℓ2-归一化码和分解码(factorized codes)等技术,这有助于训练稳定性、重建质量和码本使用。 ViT-VQGAN 图像标记器使用与(Yu 等人,2022a)相同的损失和超参数对我们的训练数据图像进行训练(参见第 4.1 节)。
- 我们首先训练一个 ViT-VQGAN-Small 配置(8 个块、8 个头、模型维度 512,隐维度 2048,如(Yu 等人,2022a)的表 2 所示,总参数约为 30M),并为码本学习 8192 个图像标记类别。
- 我们注意到,第二阶段自回归编码器-解码器训练仅依赖于编码器和学到的图像标记器的码本。 为了进一步提高第二阶段编码器-解码器训练后重建图像的视觉敏锐度,我们冻结了标记器的编码器和码本,并微调了更大尺寸的标记器解码器(32个块,16个头,模型维度 1280,隐维度 5120, 总参数约600M)。 我们对图像标记器的输入和输出使用 256×256 分辨率。
我们在放大时注意到 ViT-VQGAN 的一些输出图像中的视觉像素化图样(参见附录 H),并进一步发现 sigmoid 激活函数之前的输出投影层的病态权重矩阵。 作为修复,我们删除了最终的 sigmoid 激活层和 logit-laplace 损失,将原始值暴露为 RGB 像素值(范围 [0, 1])。 方便的是,通过微调解码器,此修复可以热插拔到已经训练好的图像标记器中。
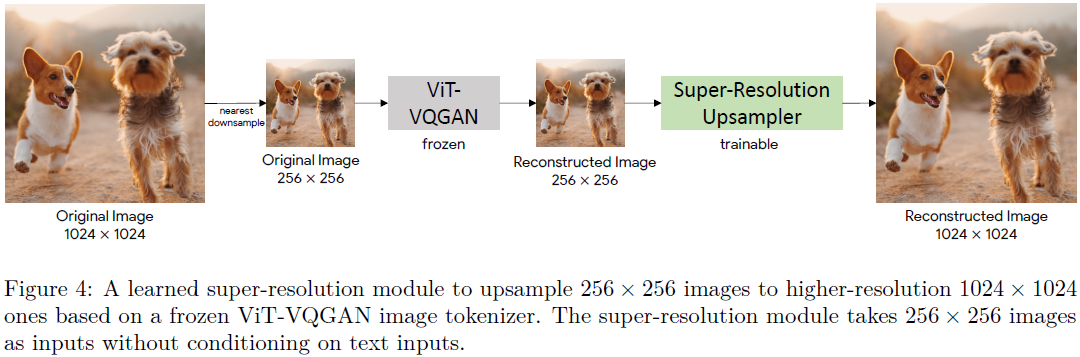
最后,虽然 256×256分 辨率的图像捕捉了大部分内容、结构和纹理,但更高分辨率的图像具有更大的视觉冲击力。 为此,我们在图像标记器之上采用了一个简单的超分辨率模块,如图 4 所示。遵循 WDSR(Yu et al., 2018)(12 个残差块,128 个通道),具有残差连接的堆叠卷积层被用作超分辨率网络模块。 它是通过与 ViT-VQGAN 相同的损失(感知损失、StyleGAN 损失和 ℓ2 损失,具有与(Yu 等人,2022a)中相同的损失权重)学习的,从重建图像映射到更高分辨率的重建图像。 超分辨率模块对于 512×512 版本有约 15M 参数,对于 1024×1024 版本有约 30M 参数。 我们注意到,扩散模型也可以在这里用作迭代细化(iterative refinement)超分辨率模块,正如 DALL-E 2(Ramesh 等人,2022)和 Imagen(Saharia 等人,2022)中所演示的那样,无论有或没有以文本输入为条件。
2.2 用于文本到图像生成的编码器-解码器
如图 3 所示,通过将文本到图像视为序列到序列建模问题,在第二阶段训练标准编码器-解码器 Transformer 模型。 该模型以文本作为输入,并使用第一阶段图像标记器生成的光栅化图像潜在编码的下一个标记预测进行训练。 对于文本编码,我们在训练数据的采样文本语料库上构建了词汇量为 16,000 的句子片段模型(Sennrich et al., 2016;Kudo & Richardson, 2018)(第 4.1 节)。 图像标记由学习的 ViT-VQGAN 图像标记器生成(参见第 2.1 节)。 在推理时,模型对图像标记进行自回归采样,随后使用 ViT-VQGAN 解码器将其解码为像素。
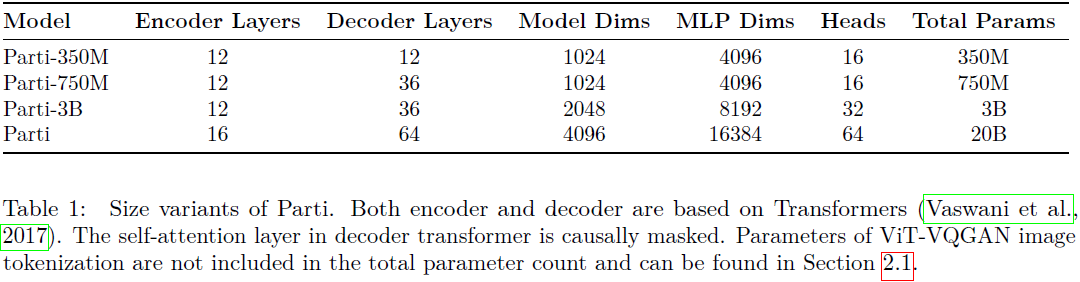
我们使用文本标记的最大长度为 128,图像标记的长度固定为 1024(即来自 256 × 256 输入图像的 32 × 32 潜在编码)。 例如,图 1 中给出的 Starry Night 提示的 67 个单词描述的总长度为 92 个文本标记。 所有解码器 transformers 都使用卷积形状的掩码稀疏注意力(masked sparse attention)(Child et al., 2019),并遵循 DALL-E 实现(Ramesh et al., 2021)(详细信息可以在(Ramesh et al., 2021)的附录 B.1 图 11 中找到)。 我们训练了四种大小变体,参数范围从 3.5 亿到 200 亿个参数不等,如表 1 所示。具体来说,我们按照之前扩展语言模型的实践来配置 Transformer,在 MLP 维度中默认扩展率为 4 倍。 当模型尺寸加倍时,我们将头(head)数量加倍。 在当前的扩展变体中,我们的配置更喜欢更大的解码器来建模图像标记,因此解码器具有更多层(例如,3B 模型中的 3 倍和 20B 模型中的 4 倍)。
大多数现有的两阶段文本到图像生成模型,包括 DALL-E (Ramesh et al., 2021)、CogView (Ding et al., 2021) 和 Make-A-Scene (Gafni et al., 2022) ),是仅解码器模型。 我们发现,在 3.5 亿到 7.5 亿个参数的模型规模下,Parti 的编码器-解码器变体在训练损失和文本到图像生成质量方面都优于纯解码器变体。 因此,我们选择专注于扩展编码器-解码器模型。
2.3 文本编码器预训练
编码器-解码器架构还解耦文本编码与图像标记生成,因此可以直接探索使用预训练文本编码器热启动模型。 直观地说,对于基于通用语言训练获得的表示,使用该表示的文本编码器应该更有能力处理基于视觉的提示(参见 Imagen)。 我们在两个数据集上对文本编码器进行预训练:具有 BERT(Devlin et al., 2019)预训练目标的 Colossal Clean Crawled Corpus (C4)(Raffel et al., 2020),以及具有对比学习目标(不使用对比预训练的图像编码器)的我们的图像文本数据(参见第 4.1 节) 。 预训练后,我们继续训练编码器和解码器,以在 8192 个离散图像标记的词汇表上使用 softmax 交叉熵损失来进行文本到图像生成。
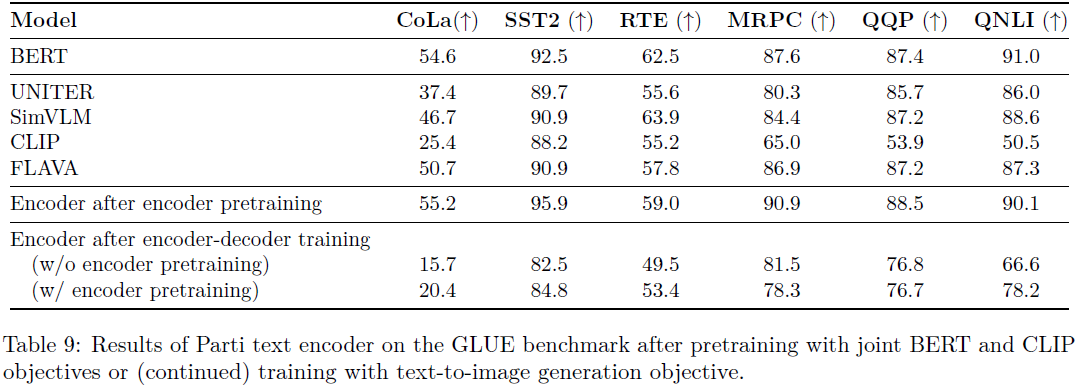
预训练后的文本编码器在 GLUE 上的性能与 BERT(Devlin 等人,2019)相当(参见附录 G,表 9); 然而,在文本到图像生成的完整编码器-解码器训练过程之后,文本编码器性能下降。 我们将此观察作为未来关于通用语言表示和基于视觉的语言表示的差异和统一的研究主题。 尽管如此,文本编码器预训练对 3B 参数 Parti 模型的文本到图像生成损失略有帮助,因此我们的 20B 模型默认使用预训练。 我们在附录 G 中提供了详细的训练损失、文本编码器的 GLUE 评估以及一些定性比较。
2.4 无分类器指导和重新排序
无分类器指导(Ho & Salimans,2021)(简称 CF-指导)对于提高没有预训练分类器的扩散模型的样本质量至关重要(Nichol 等人,2022 年;Ramesh 等人,2022 年;Saharia 等人,2022 年)。 在此设置中,生成模型 G 被训练为能够执行无条件生成 G(z)(其中 z 代表随机噪声)和条件生成 G(z, c)(其中 c 代表某些条件,例如语言描述)。 它被实现为以一定概率随机丢弃条件向量(掩蔽或切换到学到的嵌入)。 在推理过程中,输出 I 的采样是通过使用无条件和条件预测的线性组合来完成的:
![]()
其中 λ 是一个超参数,表示无分类器指导的权重。 直观上,它降低了样本的无条件似然,同时增加了条件似然,这可以被视为鼓励生成的样本和文本条件之间的对齐。
无分类器指导在文本到图像生成的自回归模型中也得到了类似的应用(Crowson,2021;Gafni 等人,2022),效果很好。 Make-A-Scene(Gafni 等人,2022)通过用填充标记随机替换文本提示来微调模型。 在推理过程中,标记是从无条件模型和以文本提示为条件的条件模型中采样的 logits 的线性组合中采样的。 我们还在 Parti 中应用了 CF-guidance,发现它在输出图像-文本对齐方面有显着改进,尤其是在具有挑战性的文本提示上。 对于无条件输入,我们简单地将文本标记 id 设置为零,将文本标记填充设置为 1。
对于每个文本提示的批量采样图像,DALL-E(Ramesh 等人,2021)中使用了对比重排序,它在生成后计算图像-文本对齐分数。 我们在工作中应用对比重排序,发现它是对无分类器指导的补充。 与 DALL-E(Ramesh 等人,2021)中使用的 512 个图像相比,我们在本文报告的实验中每个文本提示仅采样 16 个图像。 我们根据对比标题模型 (Contrastive Captioners model,CoCa) 的图像和文本嵌入的对齐分数对每个输出集进行重新排序(Yu 等人,2022b)。 CoCa 基本尺寸模型((Yu 等人,2022b)中的表 1)在相同的数据集上进行训练,详细信息请参见第 4.1 节。 我们注意到,在文本到图像采样过程中,对一小组批量采样图像进行重新排序计算量最小,并且在不同图像输出之间产生有用的图像文本对齐分数。
3. 扩展
我们在 Lingvo(Shen 等人,2019)中实现模型,并在 CloudTPUv4 硬件上使用 GSPMD(Xu 等人,2021)进行扩展,以进行训练和推理。 GSPMD 是一个基于 XLA 编译器的模型分区系统,它允许我们将 TPU 集群视为单个虚拟设备,并在几个张量上使用分片注释(sharding annotations)来指示编译器在数千个设备上自动分发数据和计算。
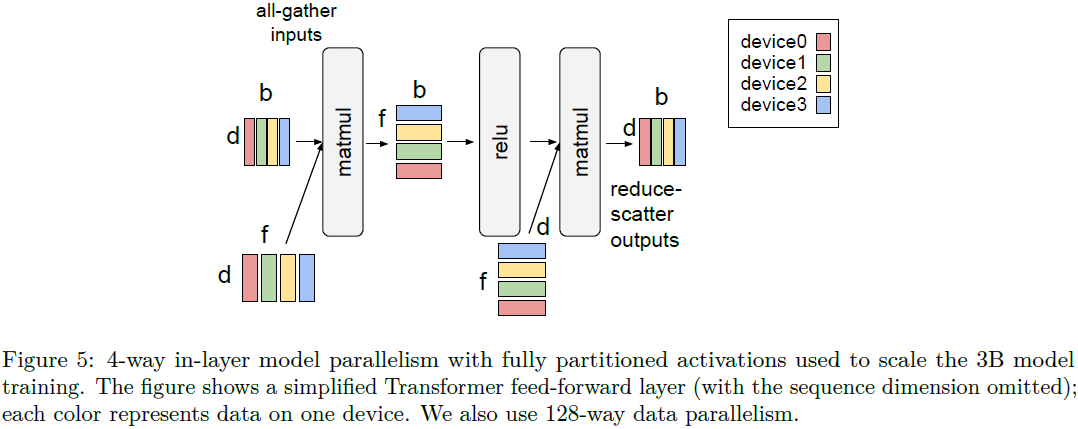
训练。 我们简单地使用数据并行性来训练 350M 和 750M 模型。 对于3B模型,我们使用 4 路层内模型并行(见图 5)和 128 路数据并行。 在每个张量中划分单个维度足以缩放 3B 模型。 模型权重根据前馈隐维度和注意力头数量维度进行划分; 前馈层和注意力层的内部激活张量也在隐层和头部维度上进行划分。 与 Megatron-LM(Shoeybi 等人,2019)的一个区别是,我们在不同维度上完全划分前馈层和注意力层的输出激活,详细信息如 GSPMD 工作中的 finalized 2d sharding 所示(Xu 等人, 2021)。 该策略将导致采用 ReduceScatter 和 AllGather 通信模式而不是AllReduce,从而显着减少峰值激活内存。
20B模型有 16 个编码器层和 64 个解码器层(见表1)。 每层权重的大小适中(而不是非常宽),这使得管道并行性(Huang et al., 2018)成为缩放的一个不错的选择。 我们使用通用的流水线包装层(wrapper layer),允许我们指定单阶段程序,稍后将自动转换为多阶段流水线程序; 包装层使用矢量化和移位缓冲区(shifting buffers)把流水线转换为张量划分问题(参见 (Xu et al., 2021) 的第 3.3 节)。 因此,在流水线中,所有较低级别的基础设施都可以复用。 采用 GSPMD 流水线还有两个额外的好处:1)它允许我们在模型子组件中方便地配置流水线,从而简化编码器-解码器模型的整体复杂性;2)由于流水线是作为矢量化程序上的张量分区来实现的,因此我们可以将同一组设备复用于 transformer 层之外的其他类型的并行性。
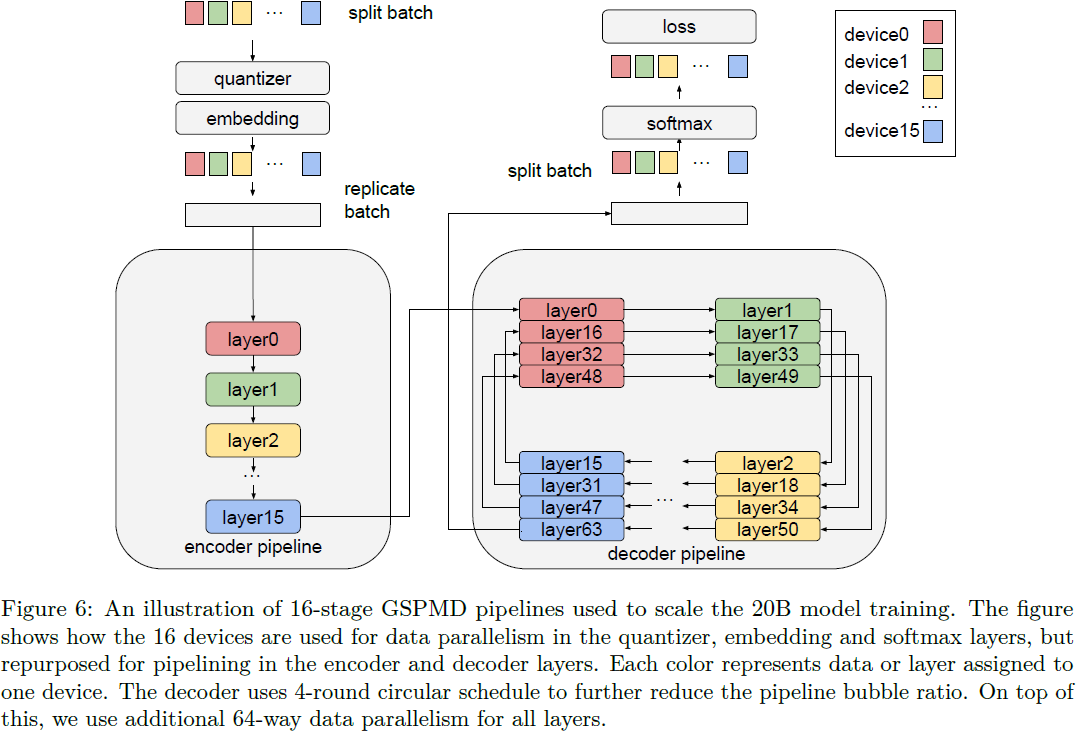
我们将模型配置为具有独立的编码器和解码器管道,每个管道有 16 个阶段。 除了流水线之外,我们还使用 64 路数据并行。 然而,这使得每个核心的批量大小变小,从而暴露出由于级间数据依赖性(称为管道并行性中的气泡(Huang et al., 2018))而导致管道过度停顿的额外挑战。 为了减少气泡的比例,我们在解码器管道中采用了 (Xu et al., 2021) 中描述的循环调度((Narayanan et al., 2021) 中也提出了类似的技术),其中每个阶段的 4 层都按循环顺序执行。 在编码器和解码器之外,我们使用同一组设备来实现数据并行,而不是使用嵌入、softmax 和图像标记器层的流水线。 图 6 说明了总体分布式训练策略。
在训练过程中,使用 Adafactor (Shazeer & Stern, 2018) 优化器来节省内存,β1 = 0.9,β2 = 0.96,解耦 weight decay 值为 4.5 × 10−2。 优化器间隙变量(optimizer slot variables)的一阶矩也从 float32 量化为 int8。 我们对编码器和解码器中的所有模型使用默认的 dropout ratio 0.1。 20B 模型中使用了确定性版本的 Dropout 层以及矢量化版本的 Adafactor 优化器,以支持训练流水线模型。 注意力投影和前馈变压器层的数据类型被转换为 bfloat16,而所有层规范和模型输出都保留为 float32。 我们使用 4.5e-5 的默认学习率和具有 5,000 个预热步骤的指数学习率计划。 指数衰减从训练步数 85,000 开始,总共 450,000 步,最终比率为 0.025。 我们在训练期间使用全局批量大小 8192。 我们不使用模型权重的指数移动平均值,从而节省设备内存。 解码器 transformer 中使用了卷积形稀疏注意力,类似于DALL-E(Ramesh等人,2021)(附录B.1.架构,图11)。 我们另外将梯度范数修剪为 4.0 以稳定训练,尤其是在开始时。 在编码器和解码器的输出处,我们应用了附加层归一化。
推理。 我们推理优化的主要目标是加速小批量图像生成。 我们为 3B 和 20B 模型选择层内模型并行性。 与训练相反,我们没有完全划分前馈层和注意层的输出激活以进行推理; 这是因为 1) 自回归解码的每一步都会产生更小的张量,并且 AllReduce 目前(at the time of writing)在小数据上表现更好,2) 推理过程中无需考虑激活内存,因为推理过程没有向后传递。
4. 训练和评估数据集
4.1 训练数据集
我们对所有 Parti 模型的图像文本数据集组合进行训练。数据包括公开可用的 LAION-400M 数据集(Schuhmann 等人,2021); FIT400M,用于训练 ALIGN 模型(Jia 等人,2021a)的完整 18 亿个示例的过滤子集; JFT-4B 数据集(Zhai et al., 2022),其中包含带有文本注释标签的图像。 对于 JFT 的文本描述,我们在原始标签作为文本(如果图像有多个标签则连接)或来自 SimVLM-Huge 模型(Wang 等人,2022)的机器生成的标题之间进行随机切换。 我们在第 8 节中讨论数据的局限性。对于所有图像输入,我们遵循 DALL-E dVAE 输入处理((Ramesh 等人,2021)中的第 A.2 节,训练)进行图像标记器训练和 DALL- E Transformer 输入处理((Ramesh 等人,2021)中的第 B.2 节,训练)用于编码器-解码器训练。
4.2 评估数据集
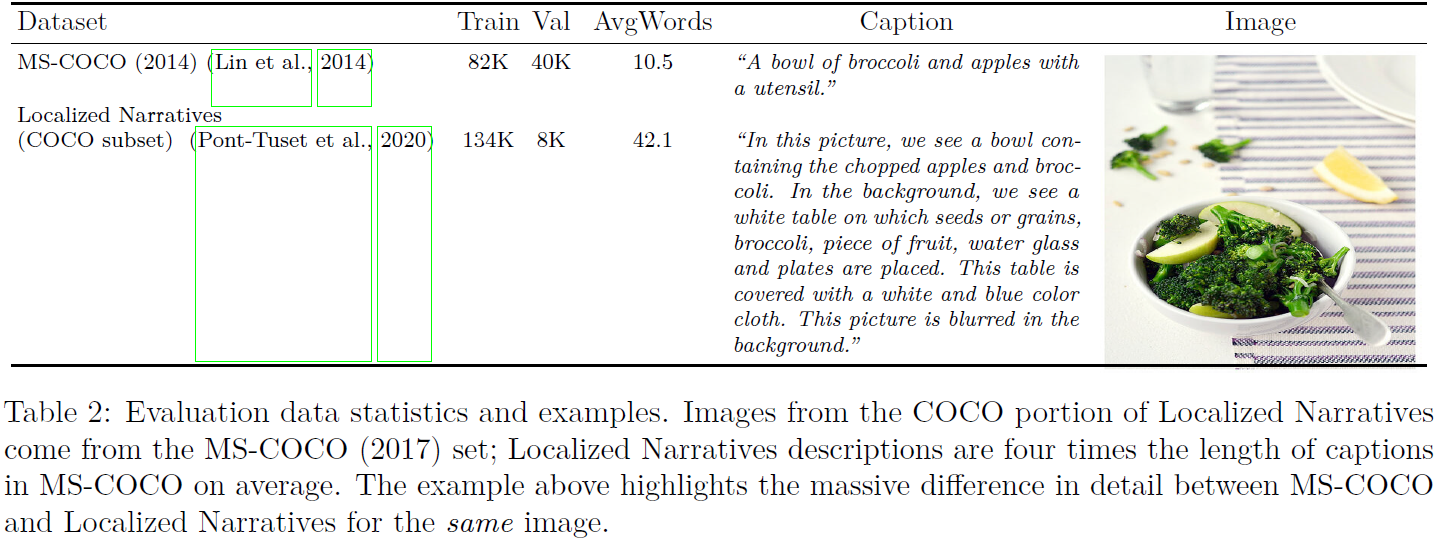
我们在 MS-COCO (2014) (Lin et al., 2014) 和 Localized Narratives (Pont-Tuset et al., 2020) 上评估我们的模型,总结在表 2 中。MS-COCO 是当前用于测量零样本和微调的文本到图像生成性能的标准数据集,这使其成为与之前的工作进行比较的一致点。 然而,MS-COCO 标题是对其相应图像的简短、高级的表征。 为了进行更全面的评估,我们还使用 Localized Narratives (LN-COCO) 的 COCO 部分,它提供了与 MS-COCO (2017) 数据集相对应的图像的更长、更详细的描述,并对比 Parti 与 ( Koh 等人,2021;Zhang 等人,2021) 在 LN-COCO 上的性能。 这些长格式描述通常与用于训练大型文本到图像生成模型的描述有很大不同。 这提供了对域外分布的泛化度量,以及这些模型的微调能力。 无论社区当前对零样本性能的关注如何,有效微调的能力对于调整开放域文本到图像生成模型以适应特定应用或领域也很重要。
4.3 PartiPrompts
MS-COCO(Lin 等人,2014)和 Localized Narratives(Pont-Tuset 等人,2020)等现有基准对于衡量文本到图像合成系统的进度显然很有用,但其中可用的描述通常仅限于自然图像中的日常场景和物体。 这限制了它们对广泛提示的表示 - 特别是,它们缺乏允许我们更好地探索开放域文本到图像生成的模型功能的提示。 例如,MS-COCO 标题是图像中高级的参与者和动作的简要表征; 这些通常涵盖常见场景并面向对象。Localized Narratives 具有高度详细的描述,但也强调自然场景和物体。 最近,(Park et al., 2021)的工作重点是文本到图像的生成任务,但仅限于两种场景,未见过的对象颜色(例如“蓝色花瓣”)和对象形状(例如“长喙”)。 受这些缺点的启发,我们提出了 PartiPrompts (P2),这是一组 1600 种不同的英语提示,使我们能够更全面地评估和测试文本到图像合成模型的极限。


P2 基准测试中的每个提示都与两个标签相关联:(1) 类别,指示提示所属的广泛组;(2) 挑战,突出显示使提示变得困难的方面。 表 3 提供了 P2 中使用的一些类别示例(共 12 个选项),范围从 “黄金比例” 等抽象概念到 “纽约市天际线” 等具体的世界知识概念。 类似地,表 4 列出了挑战方面的样本(共 11 个),从基本的 “兔子” 到复杂的例如《星夜》这幅画的完整描述(“蓝色夜空的布面油画 ……一座教堂拔地而起,就像一座灯塔,映衬着连绵起伏的蓝色山丘。”) 例如,提示 “宁静的湖边风景,蜥脚类恐龙正在迁徙” 被归类为 “户外场景”,而其挑战方面则是 “想象力”。 类似地,提示 “7 只狗坐在扑克桌周围,其中两只正在转过身” 将动物作为类别,将数量作为挑战方面。 提示的这两个视图使我们能够从两个方面分析模型的功能——生成的整体内容和捕获的微妙细节。
我们通过思考新颖的提示以及从最近的论文(Ramesh 等人,2021;Ding 等人,2021;Gu 等人,2022;Nichol 等人,2022;Ramesh 等人, 2022)中手动策划和采样提示(约占 P2 中提示的 7%)来创建 PartiPrompts。
虽然可以为提示分配多个类别和挑战方面,但我们选择通过手动决定每个提示的单个主要类别和挑战方面来降低模型分析的复杂性。
- 例如,当有一个专有名词时,我们更愿意将提示标记为 “World Knowledge”(例如“巴黎街头的一幅画”),而不是其他类别,例如 “Arts”。
- 我们还优先考虑示例较少的类别(例如 Arts),而不是示例较多的类别(例如 Animals),例如提示“浣熊穿着正式衣服,戴着礼帽,拿着拐杖。 浣熊拿着一个垃圾袋。 文森特·梵高风格的油画。”
- People 类别始终优先,例如,“在海滩打棒球的球队” 被标记为 People 而不是 Outdoor Scenes; 我们这样做是为了简化未来对使用 PartiPrompts 感兴趣的公平性和偏见方面的工作,因为它可以轻松地拆分以包含或排除涉及人员的提示。
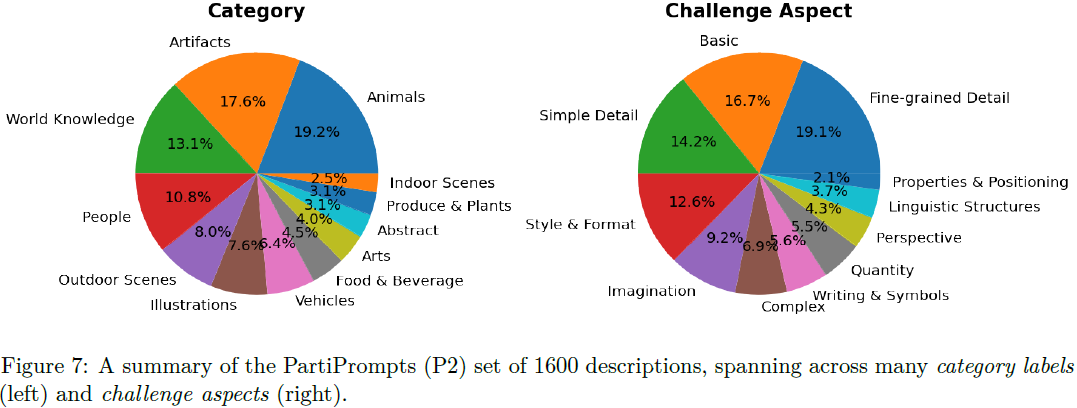
图 7 突出显示了 1600 个提示中类别标签和挑战方面的分布。 人们可以根据挑战方面将这些提示分为不同的难度级别:标准包括 Basic 和 Simple Detail(约占提示的 1/3); 中级包括 Fine-grained Detail 和 Style & Format(也是约 1/3 的提示); 挑战包括 Imagination,Quantity,
Complex,和 Linguistic Structures 等其余 7 个挑战方面。
还值得一提的是 DrawBench,这是一个同时期开发的包含 200 个提示的基准(Saharia et al., 2022)。 它有 11 个标签,混合了类别(例如“DALL-E”)和具有挑战性的方面(例如“计数”)。 相比之下,PartiPrompts 将这两个维度分开,有 12 个类别和 11 个具有挑战性的方面,允许更丰富的提示分类和更细粒度的分析,以及 8 倍以上的提示。 这两个基准测试都包含对当前最佳模型(包括 DALL-E2、Imagen 和 Parti)提出强大挑战的提示,并希望能够激发进一步的基准,以随着未来模型的不断改进而增加难度。
5. 实验
我们对 MS-COCO 和 Localized Narratives 进行自动评估,以与之前的工作进行比较。 在 MS-COCO 和 PartiPrompts 上,我们还获得了对 Parti 20B 的人类并行评估,以与强大的检索基线以及 XMC-GAN 模型(Zhang 等人,2021)进行比较。XMC-GAN 模型在目前(at the time of writing)所有公开可用的模型中具有最佳 FID。 我们还在 PartiPrompts 上对参数为 3B 和 20B 的两个 Parti 模型进行了人工评估,并提供了详细的类别细分。 默认情况下,Parti 对每个文本提示采样 16 个图像,并使用 CoCa 模型对输出进行排名(参见第 2.4 节)。
5.1 检索基线
也许文本到图像生成模型最引人注目的用途是为从未描述过的情况创建新颖的图像。 因此,强大的模型应该比简单地从大型数据集中检索候选图像的方法更有效。 我们按如下方式实现检索基线。
- 对于每个训练数据示例,我们从基于 EfficientNet-L2 ALIGN 的模型计算图像嵌入(Jia 等人,2021b)。
- 然后,给定文本提示,我们通过基于 ALIGN 的模型的文本提示嵌入与图像嵌入之间的对齐来确定最近的训练图像。 这可以通过使用 ScaNN(Guo et al., 2020)等高效的相似性搜索库在我们的数据规模上完成。
- 然后将这些检索到的示例(来自训练集)作为基线的输出,以通过我们的模型实际生成的图像进行评估。
- 我们根据文本提示手动可视化检索到的图像,并观察到这种检索方法代表了高质量的基线,特别是对于常见的文本描述。
为了与 Parti 生成的图像进行比较,我们在两种设置下报告检索基线结果,我们将其描述为零样本和微调以与模型评估术语保持一致。 对于 MS-COCO,对我们的训练数据的检索是“零样本”,而对 MS-COCO 的训练分割的检索是“微调的”——分别对应于数据集外和数据集内的检索。 我们使用自动测量和人工评估将 Parti 生成的图像与检索到的图像进行图像真实性和图像文本对齐的比较。
5.2 评估指标
我们使用两个主轴进行评估:(1) 生成的图像质量,以及 (2) 生成的图像与输入文本的对齐情况。 我们报告自动定量指标和人工评估结果。 此外,我们还展示了用于定性评估和比较的示例模型输出。
自动图像质量。与文本到图像生成方面的先前工作类似,我们使用 Fréchet Inception Distance (FID)(Heusel 等人,2017)作为测量图像质量的主要自动化指标。
- FID 是通过运行生成的图像和真实图像来计算的 Inception v3 (Szegedy et al., 2016) 模型,并从模型的最后一个池化层中提取特征。 生成的图像和真实图像的 Inception 特征用于拟合两个独立的多元高斯函数。 最后,通过测量两个多元高斯分布之间的 Fréchet 距离来计算 FID 分数。
- 遵循(Xu et al., 2018;Zhang et al., 2021;Ramesh et al., 2021),我们使用 30,000 个生成的真实图像样本,使用与 DALL-E 相同的 256×256 图像分辨率输入预处理( 在(Ramesh 等人,2021)中的 B.2 节,训练)对 MS-COCO (2014) 进行评估。
- Localized Narratives COCO split 的验证集仅包含 5,000 个唯一图像,因此我们遵循(Zhang et al., 2021)对标题进行过采样以获取 30,000 个生成的图像。
自动图像文本对齐。遵循 DALL-Eval(Cho 等人,2022),我们还通过自动标题评估(或标题器评估)来测量文本图像拟合:模型输出的图像使用预训练的 VL-T5 模型(Cho 等人, 2021)获取标题,然后通过 BLEU (Papineni et al., 2002)、CIDEr (Vedantam et al., 2015)、METEOR (Denkowski & Lavie, 2014) 和 SPICE (Anderson 等人,2016) 评估输入提示和生成的标题的相似性。
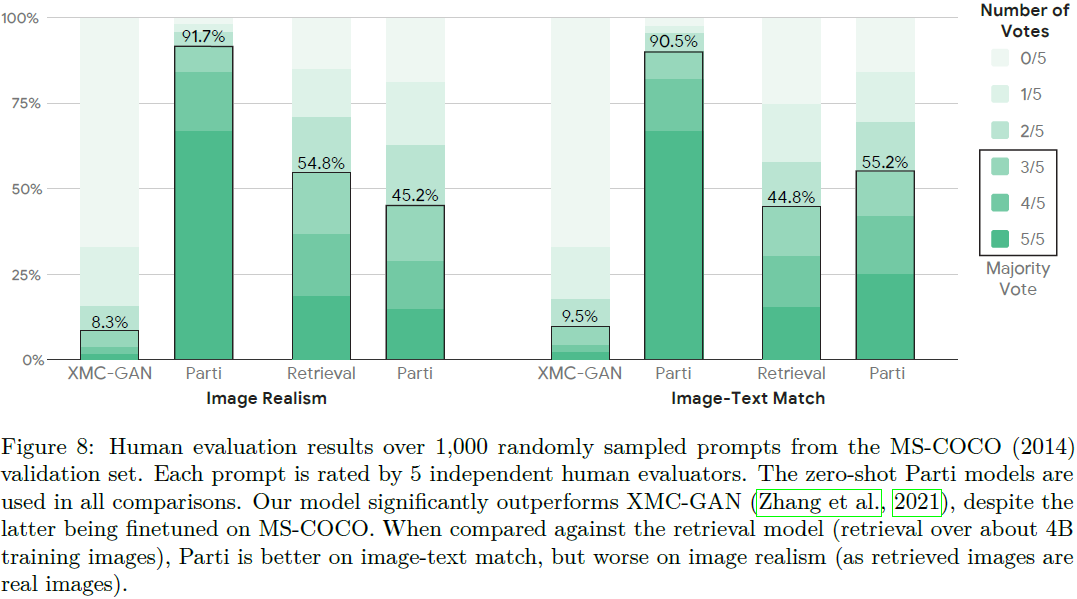
人类并排评估。 我们遵循之前的工作(Zhang et al., 2021;Ramesh et al., 2021)进行并行评估,其中人类注释者会针对同一提示提供两个输出,并被要求选择哪个输出图像质量更高(通常,图像真实感更好)并且与输入提示更匹配(图像文本对齐)。 这些模型是匿名的,每次向注释者呈现时,模型对都是随机排序的(左与右),每对模型都由五个独立的注释者进行判断。 我们以图形方式显示每个模型根据获得 0、1、2、3、4 或 5 票的示例数量逐步细分的结果。 此外,我们突出显示每个模型获得多数票(三票或更多票)的示例百分比,作为比较的总结。 请参阅附录 E 查看我们的注释器界面的屏幕截图。
5.3 主要结果
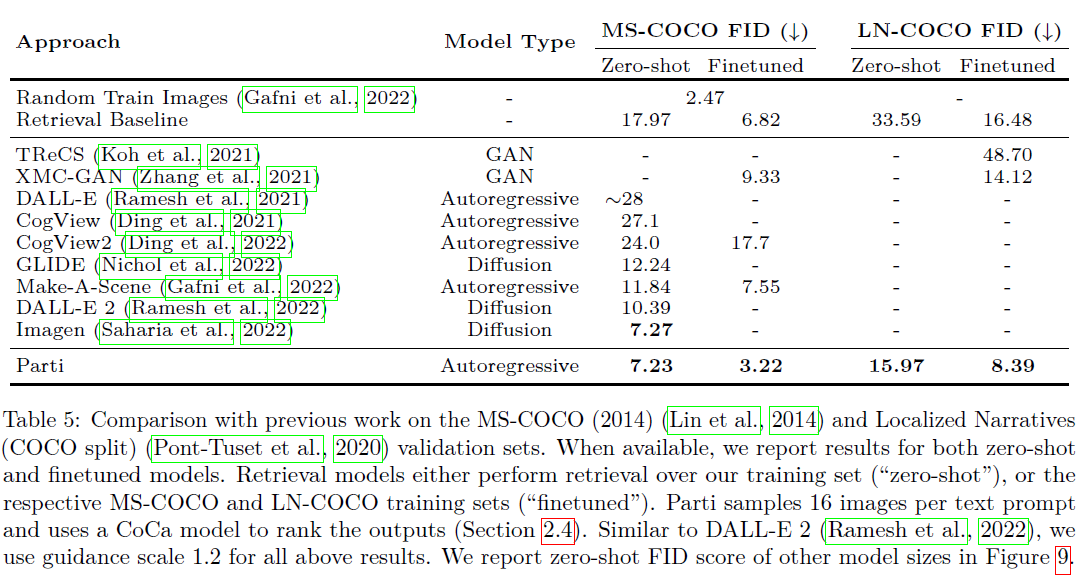
表 5 展示了我们自动图像质量评估的主要结果。
- 与基于扩散的模型 Imagen(Saharia 等人,2022)相比,Parti 实现了可比的零样本 FID 分数 7.23。
- 经过微调后,Parti 达到了最先进的 FID 分数 3.22,比之前自回归模型 Make-a-Scene (Gafni 等人,2022 年)的最佳微调 FID 7.55 有了显着提高。
- 它也优于数据集中检索基线,FID 得分为 6.82。 我们注意到,检索基线比使用 MS-COCO 真实训练集图像中的 30,000 个随机样本要差,后者的 FID 为 2.47。 根本原因是检索模型经常为相似类型的提示选择相同的图像,导致检索到的图像中有重复的图像进行评估。 例如,对于 30,000 个验证文本提示,仅检索到 17,782 个唯一的 MS-COCO 训练图像,与训练集中的 30,000 个随机样本相比,多样性和 FID 得分更差。
- 给定 MS-COCO 提示,我们还展示了非精挑细选的 Parti 采样图像与其他方法(Ramesh 等人,2021 年;Nichol 等人,2022 年;Gafni 等人,2022 年;Ramesh 等人, 2022)的输出的定性比较(附录 C,图 24)。 Parti 展示了很强的泛化能力,无需像 MS-COCO 这样的特定领域进行微调,并且它实现了高度的图像真实感——通常非常接近真实图像。
对于 LN-COCO,Parti 的微调 FID 得分为 8.29,这比 XMC-GAN 的微调结果 14.12 和检索基线 16.48 有了巨大的进步。 此外,Parti 的零样本 FID 分数为 15.97,几乎与 XMC-GAN 的微调分数(在 LN-COCO 集上训练)相匹配。 我们与 XMC-GAN 进行可视化并进行并排比较,发现与 XMC-GAN 生成的图像相比,Parti 生成的零样本图像在真实性和图像文本拟合方面质量要好得多,我们将其作为警示故事提供:研究人员不应仅仅依赖 FID 来比较文本到图像生成模型。
5.4 MS-COCO 上的更多结果
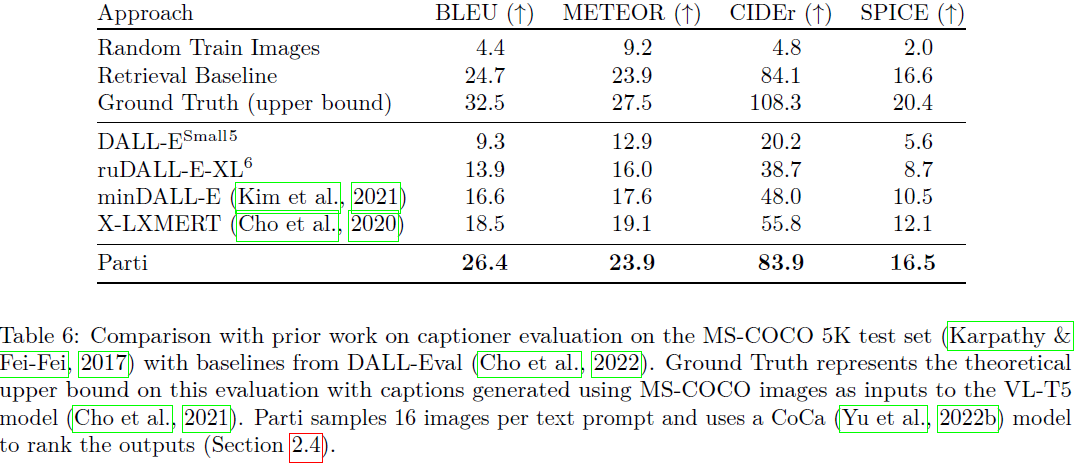
自动图像文本对齐评估。 表 6 提供了 Parti 对标题器评估(Cho 等人,2022)作为自动图像文本对齐措施的结果。
- Parti 在这项指标上优于其他模型,并且它缩小了与从真实图像(ground truth)生成的标题获得的分数的大部分差距。
- 检索基线(retrieval baseline)的性能与 Parti 相当。
- 与 FID 分数不同,正如预期的那样,随机训练图像(random train images)在标题评估中的表现要差得多。
- 标题评估器评估作为文本到图像生成模型的自动图像文本对齐测量补充了 FID 分数评估; 然而,我们还注意到这些结果受到标题生成器模型(Cho et al., 2021)区分不同方法输出的能力的限制。
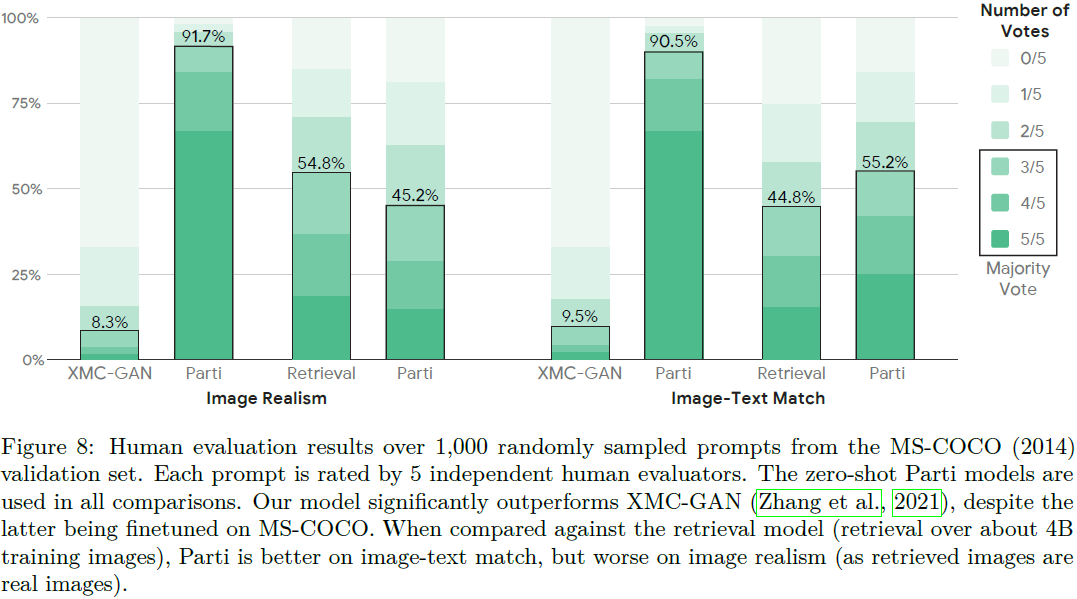
人类评价。 对于 MS-COCO,我们将零样本生成结果与微调的 XMC-GAN(Zhang 等人,2021)模型进行比较,该模型在具有相同 MS-COCO 提示的可用图像的所有目前公开可用模型中,具有最佳的 FID。
- 对于每个提示,Parti 和 XMC-GAN 的输出都是匿名的,并向 1,000 名独立的人类评估者显示。
- 结果如图 8 所示。
- 尽管 Parti 没有接受 MS-COCO 标题或图像的训练,但与 XMC-GAN 输出相比,人类注释者绝大多数更喜欢我们的结果:图像真实性的偏好得分为 91.7%,图像-文本匹配的偏好得分为 90.5% 。(我们分析了 XMC-GAN 被评为比 Parti 更真实的案例,发现这些例子大多数是由于 Parti 制作了插图或卡通,而不是照片般真实的图像。 虽然这些通常与给定的提示非常一致,但评估可能对 Parti 不利,因为 MS-COCO 完全专注于照片和它们的描述)
- 与 MS-COCO 上的检索模型相比,Parti 在图像真实性方面被评估为稍差(45.2% 与 54.8%),但在图像文本匹配方面被评估为更好(55.2% 与 44.8%) 。 这表明,在 Parti 的输出与真实图像的比较中,近一半的人认为前者生成的图像更真实,这有力地说明了模型生成的图像的视觉质量。 Parti 输出更适合图像文本匹配这一事实表明,生成是产生准确视觉描述的重要手段,甚至可以对 MS-COCO 标题中描述的大多数日常场景进行准确的视觉描述。
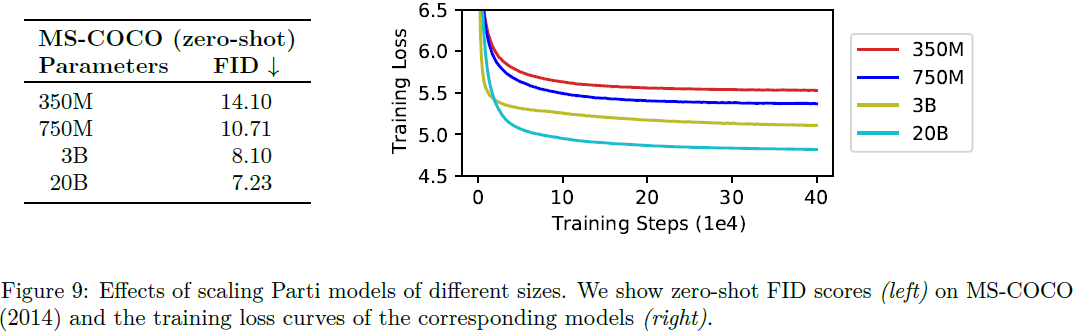
模型扩展比较。我们比较了 Parti 的四种不同模型大小,参数计数范围从 350M、750M 到 3B 和 20B,如表 1 所示。所有四个模型均在相同混合数据集上进行训练,且具有第 2.4 节描述的相同图像标记器和 CoCa 重排序模型。
- 图 9 总结了 MS-COCO (2014) 上相应的零样本 FID 分数。
- 通过在 8192 个词汇的图像码本上使用 softmax 交叉熵损失,来使用用于文本到图像生成的下一个标记预测损失训练 Parti 模型。 每个示例的损失由1024 个(总输出长度)图像标记平均。
- 当我们扩大模型规模时,我们在 MS-COCO 上观察到更好的训练损失和零样本 FID。 具体来说,通过将模型从 750M 扩展到 3B,实现了显着的质量跳跃; 此外,20B 模型在更具挑战性的提示(例如文本渲染)中优于 3B 模型。
- 我们使用 P2 基准测试中具有挑战性的提示(参见第 5.5 节),在图 10 和 13 中定性地强调了这些模型如何在视觉上表现。


5.5 PartiPrompts 上的结果
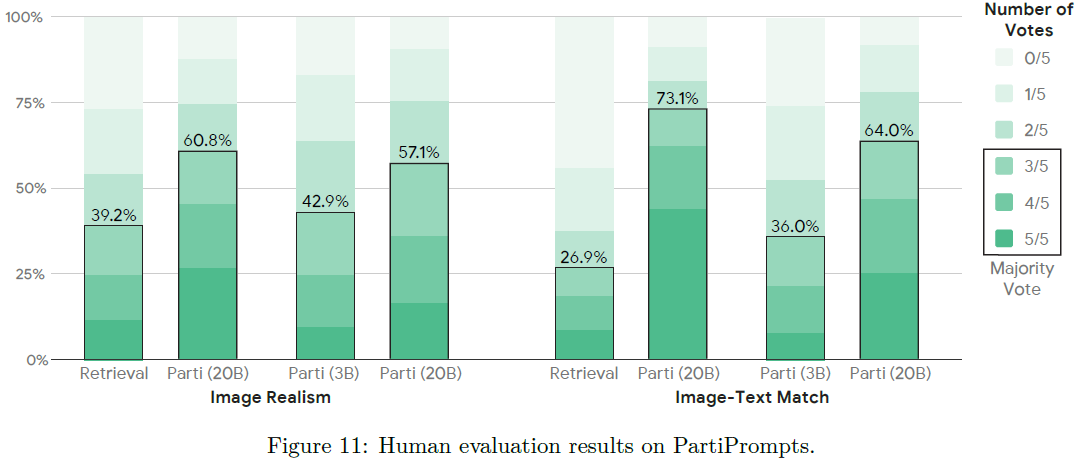
人类评估。 除了 MS-COCO 之外,我们还对 P2 基准进行人类评估,将我们的 20B 模型与 3B 变体和检索基线进行比较。
- 图 11 显示,在图像真实性 (63.2%) 和图像文本匹配 (75.9%) 方面,注释者显然更喜欢 20B 模型,而不是检索基线。这些结果为图 8 中的比较提供了补充:在更具挑战性的 P2 基准(第 4.3 节)上,检索基线无法为许多提示生成匹配的输出。
- 3B 模型缩小了差距,但在图像真实感 (56.8%) 和图文匹配 (62.7%) 方面,20B 仍然是首选。

为了更好地理解 20B 相对于 3B 模型的改进,图 12 在跨 P2 类别(左)和挑战方面(右)的图像文本匹配方面进一步细分了 20B 模型的人类偏好。
- 就类别而言,20B 模型显然在大多数类别占优,尤其是 Abstract、World Knowledge、Vehicles 和 Arts。 20B 和 3B 模型在 Produce & Plants 处于同等水平。
- 在挑战方面,20B模型在所有维度上都更好,尤其是 Writing & Symbols、Perspective 和 Imagination。
- 有关检索基线和 3B 模型的图像真实性和图像文本匹配的完整详细信息,请参阅附录 F。
定性比较。
- 为了定性地了解扩展的效果,我们在图 10 和 13 中展示了从尺寸不断增加的 Parti 模型(350M、750M、3B、20B)中采样的非精选 top-1 图像。
- 所有模型变体都使用相同的图像标记器和 CoCa 重新排序模型,如第 2.4 节所述,每个文本提示采样 16 个图像。
- 我们使用 P2 基准测试的提示来测试模型在一系列类别和具有挑战性的方面的能力。
图 10 清楚地显示了当我们扩大模型尺寸时质量的提高。
- 有时,3B 模型在视觉质量和 Fine-grained Detail 提示(例如“骑马的宇航员”和“睡莲”)的图像文本对齐方面与 20B 模型一样好。
- “黄色砖墙” 前的 “蓝色保时捷 356” 是对 World Knowledge 的强烈考验:只有 20B 模型才能正确。 3B 模型生产了一辆视觉上干净的汽车,但它是一辆从未存在过的汽车——它似乎融合了 20 世纪 60 年代多种两座跑车的特征。
- 当涉及到更具挑战性的提示时,例如测试 World Knowledge 和 Writing & Symbols 的提示,20B 模型能够产生更好的构图,例如 “悉尼歌剧院” 前的 “穿着橙色连帽衫和蓝色太阳镜的袋鼠” 和 寿司制作的 “美国地图”(有趣的是,20B 型号的地图上有芥末),以及与 3B 模型相比精确的文本输出,例如 “Welcome Friends!” 和 “Very Deep Learning”。
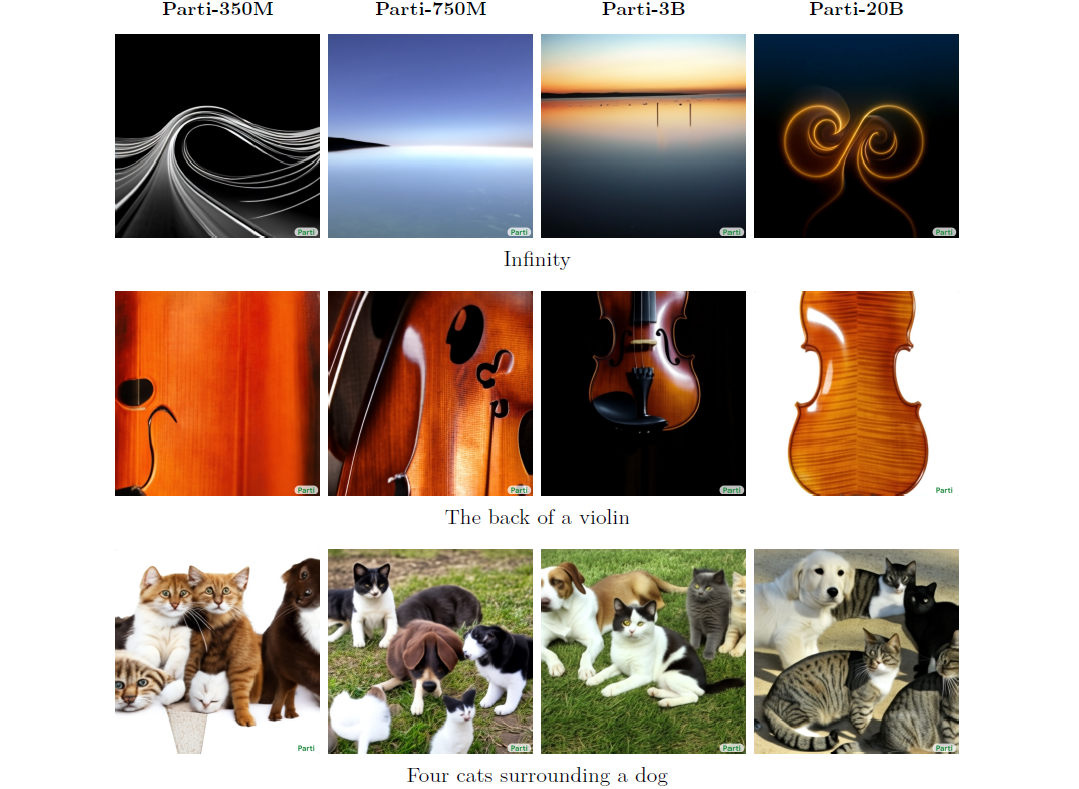
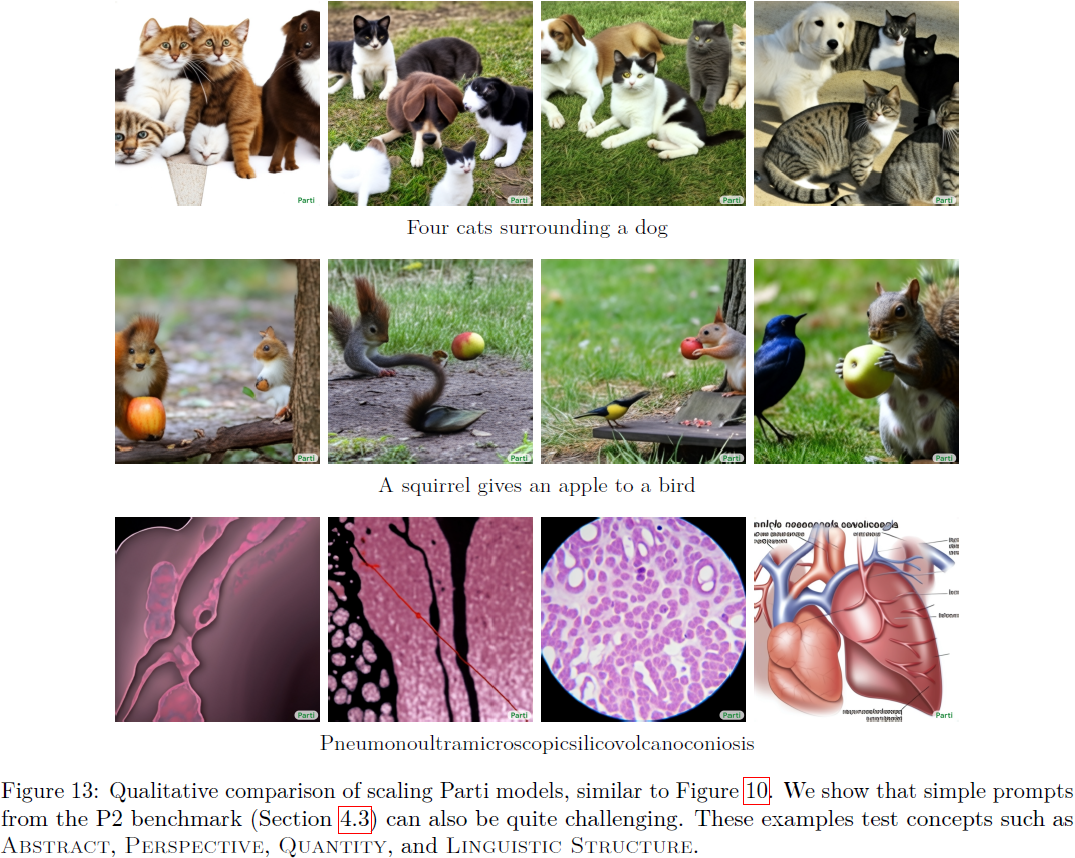
图 13 从不同的角度检查了模型,证明 P2 中的简短提示也可能非常具有挑战性。
- 20B模型在生成抽象(Abstract)概念(例如 “无穷大” 符号)和非典型视角(Perspective)(例如 “小提琴的背面”)时显示了其强大的视觉能力。
- 虽然 3B 和 20B 模型都能很好地生成动物,但 20B 模型的输出更加逼真,例如,对于提示 “松鼠给鸟喂苹果”,以及在 “四只猫围着一只狗” 的情况下正确的数量(Quantity)。
- 最后,对于 “Pneumonoultramicrooscopysilicovolcanoconiosis” 的语言结构(Linguistic Structure)示例(被认为是最长的英语单词(与肺部疾病相关)),20B 模型生成了肺部的合理图示。
6. 讨论
在本节中,我们将讨论我们选择的示例,然后逐步介绍如何使用复杂的提示,最后提供 Parti 限制的详细说明(带有示例)。
6.1 选择的样本
在图 1 和图 2 中(以及附录中图 16、图 17 和图 19 中的其他示例),我们希望具体传达 Parti 的一些优势,包括处理复杂提示、多种视觉风格、图像中的文字、世界知识等等。
图 1 的顶行显示了包含梵高画作《星夜》的非常长且复杂的描述的模型 - 输出全部来自同一批次,并显示出相当大的视觉多样性。 其他行表明该模型可以将著名的地标放在共同的场景中并调整风格。
图 2 显示了用于棘手或复杂提示的单个图像:
- (A) 很短,但包括故意拼写错误的单词 “toaday” (toad-ay) 以及成功执行的图像中的图像;
- (B) 有一个复杂的提示,需要了解阿努比斯和洛杉矶天际线的知识;
- (C) 具有广泛的视觉复杂性,涵盖多个实体及其细节以及墙上的(字面)书写,具有照片般的真实感。
- (D) 显示了简单但有效的概念组合。
- (E) 提供同一批次的四个输出,显示复杂提示的多个输出的多样性和质量。
- (F) 演示了相当长的表达以及其他复杂细节的文本渲染,包括跟随浮木的轮廓、文字的褪色及其在水中的倒影,以及将单词整合到彩色玻璃中;
- (G) 表明模型可以重现与几十年来存在和变化的三辆车的多个变体的精确视觉细节相关的世界知识,同时还融入额外的场景细节和颜色规格,并产生照片级逼真的输出。
- (H) 详细描述了各种艺术家和艺术运动的风格。
- (I)展示了动物和运动对埃及象形文字风格的适应,并附加放置在雅典花瓶上(具有不同的艺术风格),包括使绘画与花瓶的轮廓相符。
6.2 种植樱桃树(Cherry Tree)
与最近关于文本到图像生成的其他工作一样,本文包括新颖的图像以及为模型生成图像提供的复杂提示,如上一小节所述。 当然,如标题中所述的最具挑战性和最令人印象深刻的例子会被选择(即精心挑选(cherry picked))。 因此,它们通常不代表,例如,单次交互,其中模型直接生成这样的图像作为其排名最高的输出。 正如第 8 节所述,我们无法直接向公众发布我们的模型,因此在本节中,我们希望提供一个简短的窗口,了解 Parti 增加描述性和视觉复杂性的过程,包括事情如何沿着进展顺利进行,或者不能立即发挥作用。
我们想在这项工作中引入的一个关键概念是种植樱桃树(growing the cherry tree)——我们相信这个概念将在这个领域的发展中发挥作用。
- 说得更清楚一点,图 2 和附录中的其他内容(标记为“selected”)中的许多提示和生成的图像不仅是精心挑选的(cherry picked):它们是探索和探测模型功能的结果 – 交互过程的产物,其中提示者测试提示思想(prompt idea)、整体评估输出、修改提示并重复该过程。
- 有时,所有输出都很棒,提示者希望进一步推动模型。 其他时候,没有一个输出是理想的,因此采用改变或重新措辞提示的策略。 通过这种方式,人们在与模型交互时逐步开发提示,以便产生一棵樱桃树,提供一些最终可以采摘的出色输出。
- 虽然普通用户提出的许多(也许是大多数)提示会相当简单,但这就是我们找到突破点并确定下一个需要关注的机会和挑战的方式。 我们还期望设计师、艺术家和其他创意人士同样希望突破这些限制; 有趣的是,这就是一些艺术家描述的如何使用当前可供公众使用的文本到图像模型的方式。
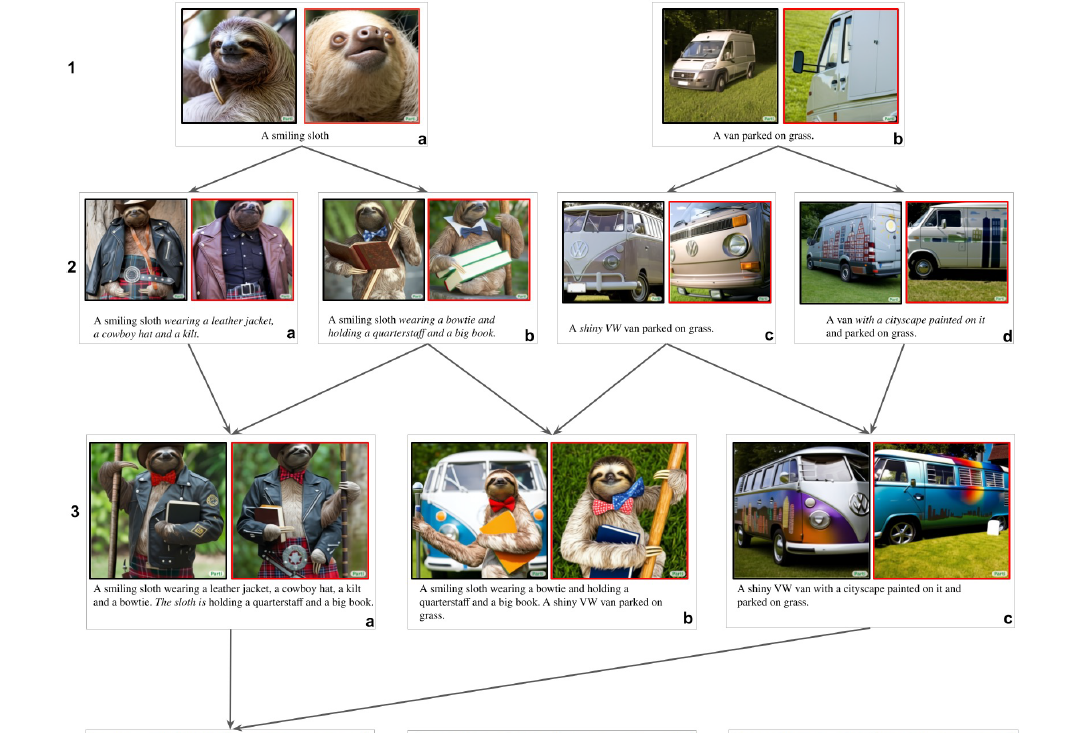

作为一个具体示例,考虑开发复杂提示的过程,如图 14 所示。这显示了创建提示变体的分支和合并过程,每个提示有两个输出。 在带有提示的每个框中,左侧给出前八个 20B Parti 输出中最好的(按所有输出排名),右侧给出前八个中最差的。
- 我们从第 1 行的两个核心实体开始,即树懒和货车。
- 第 2 行添加了每个的具体细节; 总体而言,该模型很好地适应了这一点,但请注意,框 2(b) 有一个树懒,拿着两本书和一个奇怪的领结,这是八个中最差的结果。
- 第 3 行显示了第一个主要问题:方框 3(a) 上有树懒的两条左臂,方框 3(b) 中有一只树懒,但完全缺少提示中提到的货车。
- 第 4 行显示了事情开始变得特别棘手的地方:4(a) 是树懒和货车与所有细节的完整组合,尽管只是通过各自提示的简单串联而实现。 最好的(左)输出设法使事情在技术上正确,但货车不在画面中; 然而,最糟糕的(右)输出是一团混乱。 4(b) 尝试通过定位将树懒和货车联系起来(树懒站在一辆闪亮的大众货车前几英尺处)来改善问题,但这最终会产生卡通输出,即使是最好的输出也会将城市景观置于背景而不是货车上。 图4(c)显示了一种修复方法,即在货车上改用鲜花; 这样,模型就可以产生与提示很好地对应的强烈、逼真的输出。
- 第二个修复在 5(b) 中给出,其中货车和照片被移动到提示的前部(重新措辞);不幸的是,树懒在最好的输出中缺少了它的四分杆(quarterstaff),而最差的输出是卡通的并且缺乏关键细节。 图 5(a) 显示,通过采用非照片格式可以解决一些视角和表示问题(但城市又不在货车上)。 图 5(c) 显示格式更改(变为墨水草图)和将城市景观替换为花卉,再次挽救了构图以获得最佳输出; 然而,最糟糕的输出又是一辆混乱的货车,它戴着牛仔帽,用树懒的手臂拿着一根木棍。
我们希望此图及其描述能够让您了解这样的模型在添加细节和改写提示时如何响应。 从某种意义上说,这是模型暗中流传(whispering)的一种形式,因为人们将这些模型延伸到了极限。 也就是说,模型可以轻松容纳多少描述性的复杂性和多样性,这通常是值得注意的。 在下一节中,我们将指出 Parti 模型仍然系统性地遇到困难的特定领域,因此是需要改进的关键领域。
6.3 限制


目前,Parti 在许多情况下处理得不好或不一致,或者导致输出中出现有趣的模式,甚至产生一些错误(有时可能会令人愉快)。 所有这些错误的可能性随着复杂性的增加而增加。 图 15 提供了示例提示和图像,并提及了它们所例证的特定故障模式。 请注意,这些示例不是精选的,它们通常在输出中排名较低,并且在许多情况下(尽管不是全部)模型会为提示生成排名较高且高质量的输出。我们列出了故障模式并在此处进行讨论。 除非另有说明,均参考图 15,并以面板(大写字母)和图像 (a-d) 形式给出。
注:有些提示无法在图中显示。 他们是:
- H(a,b) 一个机器人在砖墙上涂鸦。 墙上写着“驾驶飞机”。 墙前有一条人行道,混凝土的裂缝里长出了青草。
- I(a,b) 月球表面拉着马车的马,背景是自由女神像和大金字塔。 在天空中可以看到地球。 单反照片。
- I(c) 一个穿着赛车服、戴着黑色面罩、闪闪发亮的机器人自豪地站在一辆 F1 赛车前。 太阳正在落山,背景是城市景观。 漫画书插图。
- I(d) 在一面粗糙的墙上写着 “BE EXCELLENT TO EACH OTHER”,上面有一个穿着燕尾服的绿色外星人的涂鸦图像。
颜色渗漏。 当在描述中为一个对象提供颜色或颜色与该对象本身密切相关,但未为其他对象指定颜色时,它通常会蔓延到未指定的对象。 例如,棒球在有网球的情况下会变成黄色 (A(b,c)),或者皇冠会被赋予衬衫的颜色 (D(a,d))。
特征混合。 类似地,当两个所描述的对象具有某些相似性时,它们可以融合为一个对象或合并另一个对象的属性。 例子包括带有网球绒毛的棒球 (A(b,c))、大金字塔和珠穆朗玛峰的混合体而不是并置 (B(c,d)),以及将大众车标融合到苏格兰裙的毛皮袋中 ( 图 14,方框 4b、4c、5a)。
细节的遗漏、幻象或重复。 特别是在复杂的场景中,模型有时会忽略一些提到的细节、重复它们或产生未提到的幻象的事物。 例如,A(d) 中丢失的棒球、D(a,c) 中丢失的航天飞机、I(b) 中丢失的马车和雕像以及 H(d) 中包含的眼镜(幻象)。
偏移的位置或交互。 对象有时会被放置在错误的位置(尤其是在提示复杂性增加的情况下)。 示例包括 C(a,c,d) 中未与飞机缠斗的甲虫、D(b,d) 中的航天飞机和航天飞机图、H(a) 中的草和裂缝以及地球在 I(b) 中的位置。
计数。Parti 可以可靠地生成最多七个相同类型的对象(当没有像面板 A 中那样指定其他对象或混合其他细节时)。 除此之外,它大多是不精确的。
- 当存在多种类型实体的计数时,就会出现近乎完全失败的情况,如 A(a-d) 所示。
- 有趣的是,重新排名似乎有助于计数; 例如,对于五个红苹果,前六张图像都有五个苹果,但此后计数从四个到六个不等。
- 对于 10 个红苹果(参见 E(c,d)),一批中排名最高的 8 个图像的计数为 8、10、9、9、9、8、11、6。
空间关系。 虽然模型通常正确地描绘了指定为彼此上方或下方的对象,但它仍然不一致,并且通常是随机的左侧与右侧。 当涉及对象组(例如 A(a) 和 F(a,b))之间的空间关系时,这些失败尤其复杂。
否定和缺失。Parti 倾向于绘制提到的物品,即使提示说缺少某样东西。
- 例如,F(c,d) 显示包含香蕉和橙汁的输出,即使提示是 “Aplate that has no Bananas”(A 盘子上没有香蕉)。 旁边有一个没有橙汁的玻璃杯。
- F(d) 有不在盘子中的香蕉,但这只是一个偶然有趣的例子,并不是很好地处理缺席的指标。
- 我们确实发现一些没有香蕉的例子排名非常低,因此在这种情况下,生成器和重新排名器似乎也存在复合效应。
视觉外观和媒体混合不正确。特别是在涉及混合媒体类型的场景中,例如照片般逼真的物体以及墙上的文字和绘画,某些物品将从被描绘为物体跳到被描绘为绘画,反之亦然。
- 例子包括 D(a) 中阿努比斯的绘制形式、D(b) 中作为物体的航天飞机以及 H(a) 中绘制在墙上的草。
- 我们还看到媒体混合,其中物体的连贯性丢失,从物体过渡到绘画,例如 D(c) 中绘制的阿努比斯头部与身体的混合,以及 I(d) 中外星人的顶部是连接到未绘制的腿一幅画。
- 虽然这些是有趣的视觉效果,但它们没有在提示中指定,因此表明在这种情况下缺乏对对象连贯性和外观的控制。
强烈的视觉先验。某些配置和视觉特征密切相关,以至于很难将模型推离它们,特别是在面对描述中的其他复杂性时。
- 例如,面板 C 显示了创建坦克大小的犀牛甲虫的失败尝试 - 在大多数情况下,模型缩小了场景(例如使用玩具飞机)或尝试使用透视使甲虫在视觉上显得更大。 这是制造巨型甲虫的唯一成功尝试,但错误地包括了一个真正的坦克。
- 我们还发现,该模型非常难以扭转马和骑手的情况:让马骑在宇航员身上的唯一方法是避免骑马,而是将其改写为类似于马坐在宇航员的肩膀上; 这会产生一些给出所请求配置的示例 (G(a)),但大多数输出都包含错误,包括骑马的宇航员、马旁边的宇航员,甚至将骑手描绘成马宇航员 (G(b) )。 在某些情况下,一匹马被放在宇航员身上,模型中还包括另一名宇航员骑在马上。
- 另一个例子,当生成亚伯拉罕·林肯雕像穿着马球衫和棒球帽等服装的图像时,模型可以可靠地做到这一点,但许多输出仍然让他穿着著名的林肯雕像和绘画中的服装 。
强烈的语言先验。某些术语与特定实体或词义高度相关。
- 例如,一个足球飞过林肯,就显示了一个球飞过亚伯拉罕·林肯的雕像。汽车林肯可以通过添加汽车、SUV 等来引入。同样,足球飞过球棒(bat)会产生棒球棒(baseball bats)的图像; 同样,这个问题可以通过添加动物蝙蝠(bat)的属性来解决。
- 甚至可以在诸如天文学家与明星结婚这样的例子中探索相互竞争的词义之间的紧张关系,其中天文学家的存在唤起了明星的天体感,但结婚的行为唤起了(更合理的)电影明星的感觉 (埃尔克和赫伯洛特,2021)。 当看到天文学家与明星结婚的插图时,Parti 会选择天体的描述,即使将其拍成电影明星也是如此。
- 切换到政治家而不是天文学家会导致输出显示一个男人和一个女人,但图像中还包括一颗星星(五星图标)。
- 即使有更多细节,例如穿着燕尾服的天文学家与美丽的电影明星结婚的照片。 这位明星穿着白色连衣裙。该模型产生了一些与新婚夫妇的输出,但以宇宙图像为背景。
- 视觉训练数据中以天体或图标形式出现的恒星似乎压倒性地存在,创造了一种非常强大的组合语言和视觉先验,模型很难改变这种先验。
文本渲染错误。
- 值得注意的是,像 Parti 和 Imagen 这样的文本到图像模型可以在图像上以多种且适合上下文的方式渲染文本(例如,参见图 2,F 组中的示例),即使没有明确策划或创建的训练 学习这种能力的数据。
- 然而,文本渲染常常是偶然的。 即使在简单的提示中,缺少几个字符也是很常见的。 对于更复杂的提示,渲染文本的错误随着场景和描述的复杂性而增加,如面板 H 所示。
- 渲染文本的能力也可能导致模型基本上尝试渲染图像中的整个提示文本的情况,例如,作为一本书的标题。 这种情况通常发生在没有视觉描述性的提示上(例如,如何在生活中取得成功),并且有必要明确调用油画或插图等格式,以便这些格式产生非文本输出。
使用提及错误。 该模型可以在图像上渲染文本,但有时它会生成图像(使用)而不是文本(提及)(例如,H(b) 中的飞机图),反之亦然(在 T 恤上渲染航天飞机而不是绘制一个- 与 D 相关的另一个输出,但未显示)。
解耦多个实体。 该模型通常能够将大量细节打包到包含单个实体的图像中,但当存在多个关键实体时,会面临更大的挑战。
- 这可以从图 14 的树懒和货车示例中看出,其中模型在它们的组合(第 3 行,框 b)方面陷入困境,并且随后增加的复杂性导致良好输出减少。
- 然而,当实体属于同一类型时,例如两只动物,如 E(a,b) 所示,即使相当简单的细节也分布在实体之间,这通常会更加困难。
风格丢失。Parti 可以可靠地产生多种风格,例如点画派(pointillism)和木刻,但立体主义和超现实主义等其他风格往往会丢失更深层次的风格,特别是当应用于复杂的场景时。
- 有些特定画家的风格可以很好地模仿,比如梵高和伦勃朗,但其他画家要么缺乏,要么很随意,比如米开朗基罗(看起来大多与添加油画相同)。
- 有趣的是,扩展与特定画家相互作用:例如,应用梵高的风格实际上会产生与 Parti-3B 模型风格一致的更多样化的输出,而输出几乎以 Parti-20B 模型的星夜为主。
不可能的场景。
- 一些输出(通常是排名很低的输出)显示集成不一致的实体,例如 I(c),其中机器人以无意义的方式跨坐在汽车上。
- 其他涉及混合媒体的案例也会导致类似的怪异输出,包括在类似照片的身体上画出阿努比斯的头部(D(c)),以及在地面上描绘真实的脚的涂鸦外星人(I(d)) 。 (请注意,在这两种情况下,如果提示明确指定需要这些效果,这些输出将是很好的输出。)
- 在尝试构建复杂的奇幻场景时会出现其他挑战,例如 I(a,b) 输出中的马车、月亮和地球,其中雕像、月球和地球的光照完全不一致 (a),并且地球看起来坐在月球上 (b)。
缩放和透视。 Parti 经常产生过于放大的输出,例如,仅显示车辆或主题的一部分。 虽然它可以响应缩小、四分之三视图、广角镜头等指令,但这仍然经常导致拍摄对象被裁剪。 为了确保更广阔的视野,通常需要使用其他细节,例如在主题上添加鞋子以获取脚或添加对田野和花朵的描述以获取整个长颈鹿(如 G(c,d) 中所做的那样)。
动物主角。
- 由于第 8 节中讨论的问题,我们实验了许多动物作为描述中主角的替身。事实证明,有些动物比其他动物更容易处理。
- 例如,爪子与人手更相似的哺乳动物(如熊、袋熊和浣熊)比壁虎、昆虫和鱼更可靠地产生更好的图像。 这可能是由于它们与人类在视觉和形态上的相似性,以及它们在更广泛的视觉世界(例如,在卡通中)中更常被用作类人主角。
- 通常还需要在提示中包含 “照片”,以推动模型制作类似照片的图像,即使如此,它通常也会产生类似卡通的输出——尤其是随着描述复杂性的增加。
详细或棘手的视觉效果。 让模型对提示做出反应是非常困难的,例如来自拼图(及其变体)的一只熊:人们可能想要一个熊的一部分像埃舍尔(Escher)的看起来真实图像,而其他部分则是拼图的一部分。 一般来说,控制这种细粒度的规范似乎超出了当前的模型,并且可能在交互式编辑设置中得到更好的服务。
常见的误解。一些视觉世界知识在更广阔的世界中被错误地理解,这部分反映在数据中,然后反映在模型中。
- 例如,人们普遍认为吉萨建筑群的中央金字塔是大金字塔,但实际上是海夫拉(Khafre)金字塔。真正的大金字塔是胡夫(Khufu)金字塔,位于北部。
- 海夫拉金字塔经常被错误地认为是伟大的金字塔,因为它坐落在稍高的地面上(但实际上比胡夫金字塔的 146.6 米要低,为 136.4 米),而且它位于大狮身人面像后面的显着位置。 这种错误的归因反映在与大金字塔一词相关的图像中,并且出现在 Parti 的许多大金字塔输出中(包括 B(d))。
我们希望这些观察和对限制和错误类型的细分,以及它们在许多 PartiPrompt 中的对应关系,对于我们在本文展示的结合强大功能以及启发未来改进文本到图像生成模型的工作都是有用的。 从这个角度来看,还值得回顾一下 WordsEye (Coyne & Sproat, 2001),这是一个 2001 年构建的自动文本到场景系统。
- 它从提示中导出依存结构,将其转换为语义结构,然后使用它们来选择、 在所描述的场景中定位和缩放对象和参与者。
- 尽管它在开放领域、广泛的功能(包括世界知识)方面无法与当前的文本到图像(例如 Parti)相媲美,但它实际上可以精确地管理上述几个限制,包括计数、否定、相对尺度和位置 – 这样它就可以生成与复杂提示相对应的计算机图形视觉效果(基于显式 3D 表示),例如: “约翰使用十字弓。 他骑马经过商店。商店在大柳树下。 小异特龙在马的前面。 恐龙面对约翰。 店前有一个巨大的茶杯。 恐龙在马前面。 巨大的蘑菇在茶杯里。 城堡位于商店的右侧。”
- WordsEye 还可以处理长度和高度等测量规格,并对输出图像进行正确的视觉调整,例如,针对诸如割草机高 5 英尺之类的提示。 约翰推着割草机。 猫在约翰身后 5 英尺处。 这只猫有 10 英尺高。
- 随着 Dall-E 2、Imagen 和 Parti 等功能广泛但通常不精确的模型的出现,这应该会激励我们重新审视 WordsEye 等早期系统的想法和功能,并渴望将广度、视觉质量和控制结合起来的模型。
7. 相关工作
文本到图像的生成。 文本到图像生成的任务解决了从自然语言描述合成真实图像的问题。 成功的模型可以实现许多创造性的应用。
- WordsEye(Coyne & Sproat,2001)是一种基于规则的方法和显式 3D 表示的开创性方法。
- 最早的基于深度学习的模型之一(Reed et al., 2016a)提出使用条件 GAN 根据语言描述生成鸟和花的图像。
- 后来的工作通过引入渐进式细化(Zhang et al., 2017; 2018a)和使用跨模态注意机制(Xu et al., 2018;Zhang et al., 2021)来提高生成质量。
- 其他几项工作提出使用分层模型,通过显式建模对象的位置和语义来生成图像(Reed et al., 2016b; Hong et al., 2018; Hinz et al., 2019; Koh et al., 2021)。
- 通过将文本到图像的生成视为序列建模问题(Esser 等人,2021;Ding 等人,2021;Ramesh 等人,2021;Gafni 等人,2022;Dayma 等人 ., 2021),对大规模图像文本对进行训练,已经取得了显着的改进。 通常采用两阶段框架(Yu et al., 2022a;Chang et al., 2022),其中在第一阶段将图像标记为离散的潜在变量。 通过图像标记化和去标记化,文本到图像的生成被视为适合带有 transformer 的语言模型的序列到序列问题,这提供了通过应用大型语言模型的技术和观察来扩展此类模型的机会(Radford 等人,2018;Du 等人,2022;Chowdhery 等人,2022b;Hoffmann 等人,2022)。
- 最近令人印象深刻的结果是通过扩散模型取得的(Nichol 等人,2022 年;Ramesh 等人,2022 年;Saharia 等人,2022 年),其中,对于 CLIP(Radford et al., 2021)图像文本模型的文本编码器,或通过语言自监督预训练的冻结文本编码器(如 T5 (Raffel et al., 2020)),模型以它们为条件进行学习。 扩散模型的工作原理是提出一个向图像迭代添加噪声的过程,然后学习根据文本输入或特征反转该噪声。 当与扩散模型级联一起使用时(Ho 等人,2022),这些模型已被证明可以有效地根据文本提示生成高保真图像,并实现了最先进的零样本 MS-COCO FID 分数(Saharia 等人) 等,2022)。
图像标记器。之前的工作探索了通过学到的深度神经网络将图像标记为离散的潜在变量。
- 离散变分自动编码器 (dVAE)(Rolfe,2017)等早期工作使用离散潜在变量优化概率模型,以捕获由离散类组成的数据集。 然而,dVAE 在应用于自然图像时通常会生成模糊像素。
- 最近的工作,如 VQGAN(Esser 等人,2021)(基于 VQVAE(Van Den Oord 等人,2017))进一步应用对抗性损失(Karras 等人,2020)和感知损失(Johnson 等人,2016; 张等人,2018b)使用具有自注意力模块的卷积神经网络合成图像。
- ViT-VQGAN(Yu et al., 2022a)建立在 VQGAN 的基础上,在架构和码本学习方面都有改进。
- Transformer(Vaswani 等人,2017)用于将图像编码为潜在变量并将其解码回图像。
- 我们使用稍微修改过的 ViT-VQGAN(Yu et al., 2022a)(参见第 2.1 节)作为我们的图像标记器。
8. 更广泛的影响
除了上面介绍的模型功能和评估之外,用于文本到图像生成的大型模型还需要考虑更广泛的问题。
- 其中一些问题与开发过程本身有关,包括使用从网络获得的大型图像训练数据集,这些图像大多是未经整理的,几乎没有监督(也在(Saharia 等人,2022 年)中讨论过),或者在任务制定中围绕构造的概念模糊性 (Hutchinson 等人,2022)。
- 由于大型文本到图像模型是基础模型(Bommasani 等人,2021)——既支持一系列系统应用,也支持针对特定图像生成任务的微调——它们充当基础设施的一种形式,塑造了我们对什么既是可能的,也是可取的的概念(Hutchinson 等人,2021;Denton 等人,2021)。
- 预测基础设施的所有可能用途和后果即使不是不可能也是很困难的,因此强调透明地记录和共享有关数据集和模型的信息的负责任的人工智能实践至关重要(Mitchell 等人,2019;Gebru 等人,2021;Pushkarna 等人, 2022)。
- 尽管应用超出了本文的范围,但我们在这里讨论一些可以预见的可能的机会和风险。
创造力和艺术。 机器学习模型能够使用语言描述生成新颖、高质量的图像,为人们创造独特且美观的图像(包括艺术图像)开辟了许多新的可能性。
- 就像画笔一样,这些模型是一种工具,它们本身并不能产生艺术,而是人们使用这些工具来发展概念并推动他们的创意愿景向前发展。
- 对于艺术家来说,此类模型可以提供新的创新和探索手段,包括创造动态生成艺术的机会,在响应观众交互的同时设定主题或风格,或者在视频游戏环境中生成新颖且独特的视觉交互 。
- 对于非艺术家来说,这些功能提供了一个通过自然语言界面探索视觉创造力的机会,而无需技术艺术能力。
- 文本到图像系统还可以帮助残疾人发挥创造力(参见(El-Nouby 等人,2019 年;Sharma 等人,2018 年)),但我们警告不要在不采取参与性方法的情况下这样做,以增加满足实际需求的可能性并避免对残疾的误解(Mankoff 等,2010)。
评估使用机器学习模型创作的作品的设计优点或艺术优点(或缺乏)需要对多年来基于算法的艺术、模型本身、涉及的人员以及更广泛的艺术环境有细致的了解(Browne,2022)。 模型的艺术输出范围取决于训练数据,这可能对西方图像存在文化偏见,并且可能阻止模型像人类艺术家那样展示全新的艺术风格(Srinivasan & Uchino,2021)。
视觉(错误)沟通。
- 文本到图像的前机器学习历史主要包括协助与不识字群体的沟通,包括语言学习者(包括儿童,例如故事书插图)、低识字社会群体(例如,直到现代晚期,为低识字率教会绘制的宗教插图)和其他语言的使用者。
- Parti 使用的架构和策略直接连接到用于机器翻译的神经序列到序列模型(Wu 等人,2016)和其他通信辅助工具,例如句子简化(Alva-Manchego 等人,2020)和释义(Zhou & Bhat,2021)。 这可能会增强使用大型文本到图像模型来协助通信的诱惑。
- 然而,我们警告不要使用文本到图像模型作为交流辅助工具,包括用于教育(参见(El-Nouby 等人,2019)),直到进一步的研究检验了功效和实用性问题,因为文本和图像以不同的方式传达意义,并具有明显的局限性。
- 跨文化因素尤其值得关注,因为很少有研究考虑非西方文化成员能否获取计算机生成图像的问题。 不仅视觉风格在跨文化中存在差异,而且类别实例的形式和外观在不同文化中也可能存在根本差异(例如婚礼服装、食物等)(Shankar et al., 2017;De Vries et al., 2019) )可能会导致沟通不畅。
深度造假(Deepfake)和虚假信息。 鉴于模型输出的质量足以与真实照片相混淆,而且由于输出质量和真实感正在迅速提高,因此使用此类技术来创建深度造假显然令人担忧。 缓解这个问题的一种方法是对每个生成的图像应用人们无法感知的水印(Luo et al., 2020),这样就可以验证任何给定的图像是否是由特定模型(例如 Parti)生成的。 虽然这种方法可以减轻虚假信息的风险,但当未经个人同意而复制个人肖像时,仍然可能会造成伤害。
偏见和安全。
- GLIDE、DALL-E 2、Imagen、Make-a-Scene、CogView 和 Parti 等文本到图像生成模型都是在大型且通常有噪声的图像文本数据集上进行训练,这些数据集已知包含针对不同背景的人的偏见 。
- Birhane 等人(Birhane 等人,2021)对 LAION-400M 数据集(Schuhmann 等人,2021)的分析尤其强调了这一点:他们对该数据集的研究暴露了许多与刻板印象、色情、暴力等有关的问题 。
- 其他偏见包括对律师、空乘人员、家庭主妇等的刻板印象。
- 在没有缓解策略的情况下对此类数据进行训练的模型因此存在反射和扩大潜在问题的风险。
- 我们的主要训练数据经过精心挑选和严格过滤,以最大程度地减少 NSFW 内容的存在; 然而,我们在微调过程中结合了 LAION-400M 和无分类器指导——这提高了模型性能,但也导致在某些情况下生成 NSFW 图像。
- 其他偏见包括通过使用主要有英文文本的示例而引入的偏见,并且可能会世界的某些地区有偏见。 例如,在非正式测试中,我们注意到,提及婚礼服装的提示似乎会产生偏向于刻板女性和西方服装的图像。
预期用途。 由于上述影响和限制,以及需要进一步探索的担忧,Parti 是一个研究原型。 它不适用于高风险或敏感领域,也不适用于生成人物图像。
这些考虑因素都促使我们决定目前不发布我们的模型、代码或数据。 相反,我们将在后续工作中重点关注进一步仔细测量模型偏差,以及缓解策略,例如提示过滤、输出过滤和模型重新校准。 我们还相信,可以使用文本到图像生成模型作为工具来大规模理解大型图像文本数据集中的偏差,通过明确地探测它们是否存在一系列已知类型的偏差,并尝试发现其他形式 隐藏的偏见。 我们还将与艺术家协调,将高性能文本到图像生成模型的功能应用到他们的作品中,无论是出于纯粹的创意目的还是艺术品出租。 考虑到许多研究小组的强烈兴趣以及随之而来的模型和训练数据的快速发展,这一点变得更加重要。 理想情况下,这些模型将增强(而不是取代)人类的创造力和生产力,以便我们所有人都能享受一个充满新的、多样化的和负责任的审美视觉体验的世界。
9. 结论
在这项工作中,我们证明像 Parti 这样的自回归模型可以根据文本提示生成多样化的高质量图像,而且它们具有明显的缩放优势。 尤其是,Parti 能够代表广泛的视觉世界知识,例如地标、特定年份、车辆的品牌和型号、陶器类型、视觉风格,并将这些集成到新颖的设置和配置中。 我们还对局限性进行了广泛的讨论,包括对多种模型错误和挑战的细分,我们希望这对于了解模型的功能和强调未来研究的机会都是有用的。 为此,我们在这项工作中发布的 PartiPrompts (P2) 基准测试是有意设计的,以引发许多此类错误类型。
还有机会将扩展的自回归模型与扩散模型集成,首先让自回归模型生成初始低分辨率图像,然后使用扩散模块迭代细化和超分辨率图像(Gu 等人,2022 年;Ramesh 等人,2022 年;Saharia 等人,2022 年)。 在文本到图像生成模型的许多重要评估和负责任的人工智能需求方面取得进展也至关重要。 为此,我们将对自回归模型和扩散模型进行更多的实验和比较,以了解它们的相对能力,解决两类模型和缓解策略中的公平性和偏见的关键问题,并确定结合他们优势的最佳机会。
参考
Yu J, Xu Y, Koh J Y, et al. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation[J]. Transactions on Machine Learning Research, 2022.
附录
C. MS-COCO 上的定性比较


给定 MS-COCO 提示,图 24 显示了非精挑细选的 Parti 采样图像与其他方法(Ramesh 等人,2021;Nichol 等人,2022;Gafni 等人,2022;Ramesh 等人,2022)的输出的定性比较。 Parti 展示了很强的泛化能力,无需像 MS-COCO 这样在特定领域进行微调,并且它实现了高度的图像真实感,通常非常接近真实图像。
G. 编码器预训练

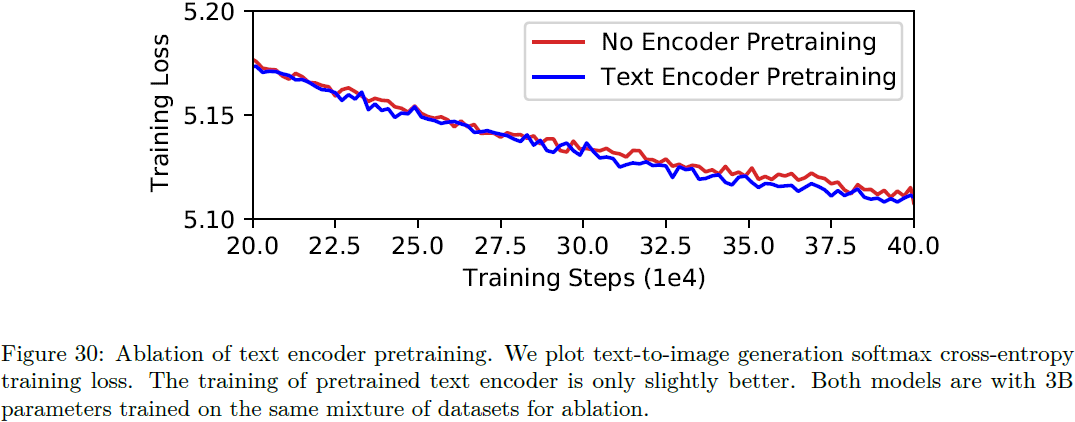
虽然使用预训练文本编码器热启动模型很简单,但我们观察到文本编码器预训练对 3B 参数 Parti 模型的文本到图像生成损失的帮助非常小。 定性示例如图 29 所示,定量损失比较如图 30 所示。我们将此观察结果作为未来关于通用语言理解和基于视觉的语言理解的差异和统一的研究主题。
H. ViT-VQGAN 的像素化图样

我们在放大时注意到 ViT-VQGAN 的一些输出图像中的视觉像素化图样,并进一步发现 sigmoid 激活函数之前的输出投影层的病态权重矩阵。 作为修复,我们删除了最终的 sigmoid 激活层和 logit-laplace 损失,将原始值暴露为 RGB 像素值(范围 [0, 1])。 方便的是,此修复可以热插拔到已经通过微调解码器训练好的图像标记器中。
S. 总结
S.1 主要贡献
本文提出了 Pathways 自回归文本到图像 (Pathways Autoregressive Text-to-Image,Parti) 模型,证实自回归模型可以实现最先进的性能。
- Parti 将文本到图像的生成视为序列到序列的建模问题,类似于机器翻译
- 首先,将文本标记作为编码器的输入,并使用基于 Transformer 的图像标记器 ViT-VQGAN 将图像自回归地编码为离散标记序列。
- 其次,通过将编码器-解码器 Transformer 模型扩展至 20B 参数来实现一致的质量改进。
规模很重要:最大的 Parti 模型 (20B) 最有能力生成逼真图像,并支持内容丰富的合成,特别是涉及复杂构图和世界知识的合成。
引入了一个整体基准,PartiPrompts(P2),这是一组丰富的超过 1600 个(英语)提示,旨在衡量在各种类别和受控难度维度上的模型能力。
Parti 对更长描述有强大的泛化能力,从而能够在模型探索中增加相当大的复杂性。本文提出了种植樱桃树(Growing a Cherry Tree)的新概念,帮助人们了解 Parti 增加描述性和视觉复杂性的过程。
建立了关于识别文本到图像生成模型的局限性的新先例,并针对观察到的错误类型,提供了详细的带有示例的细分(breakdown)。
S.2 Parti 架构和方法
Parti 是一个两阶段模型,由图像标记器和自回归模型组成,如图 3 所示。
第一阶段:训练标记器,将图像转换为一系列离散视觉标记,用于训练并在推理时重建图像。
- 使用 ViT-VQGAN 作为图像标记器。
- 首先训练一个 ViT-VQGAN-Small 配置,并为码本学习 8192 个图像标记类别。学习量化表示不是学习可以在潜在空间中取任何值的表示,而是学习将补丁嵌入映射到其最近的码本条目的视觉码本,码本是在潜在空间中学到的且可索引的位置。
- 为了进一步提高第二阶段编码器-解码器训练后重建图像的视觉敏锐度,冻结了标记器的编码器和码本,并微调了更大尺寸的标记器解码器。
- 此外,为获得更高分辨率的图像,在图像标记器之上采用了一个简单的超分辨率模块
第二阶段:训练标准自回归编码器-解码器 Transformer 模型。
- 该模型以文本作为输入,从文本标记生成图像标记。
- 在推理时,模型对图像标记进行自回归采样,随后使用 ViT-VQGAN 解码器将其解码为像素。
文本编码器预训练。编码器-解码器架构还解耦文本编码与图像标记生成,因此可以直接使用预训练文本编码器。
- 在两个数据集上对文本编码器进行预训练。
- 预训练后,我们继续训练编码器和解码器,以在 8192 个离散图像标记的词汇表上使用 softmax 交叉熵损失来进行文本到图像生成。
此外,还使用无分类器指导和重排序提升最终的生成性能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









