







ALIGNVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding


目录
1. 概述
该论文提出了一种新的视觉-文本对齐方法 ALIGNVLM,用于提高视觉语言模型(VLMs)的多模态理解能力。核心思想是通过 ALIGN 模块,将视觉特征映射到大型语言模型(LLM)的文本嵌入空间,使得视觉输入更符合 LLM 预训练时的语义结构。这种方法主要应用于 文档理解任务,如扫描文档的解析、信息提取、表格理解等,并在多个基准测试中实现了 SOTA(最先进)性能。
2. 研究背景与动机
- VLMs 需要将 视觉特征 转换为 语言特征,以便 LLM 处理文本信息。
- 传统的 多层感知机(MLP) 连接器易产生 噪声或分布外(OOD)输入,导致文本和视觉信息对齐不良。
- 现有方法(如深度融合方法和浅层融合方法)虽然有效,但计算成本高、效率低或对齐机制不足。
- 本文提出 ALIGNVLM,通过概率加权 LLM 的文本嵌入,使视觉信息更符合 LLM 的理解能力,减少噪声输入,提高对齐效果。
3. 方法
3.1 架构
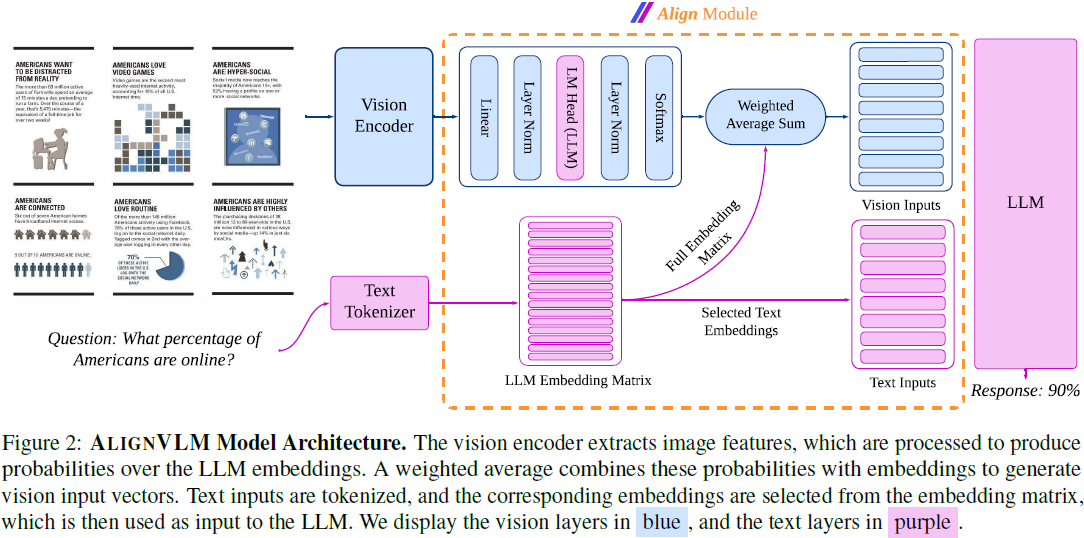
ALIGNVLM 由 三个核心模块 组成:
1)视觉编码器(Vision Encoder):使用 SigLip-400M 视觉编码器,将图像分割成 块(tiles)和 补丁(patches),提取视觉特征。
2)ALIGN 对齐模块(ALIGN Module):该模块用于将视觉特征与大型语言模型(LLM)对齐。
首先,线性层将视觉特征 F 投影到 LLM 的 token 嵌入空间,使每个 token 对应一个向量。
然后,第二个线性层 与 softmax 归一化 共同生成 LLM 词汇表(V 个 token)的概率分布:
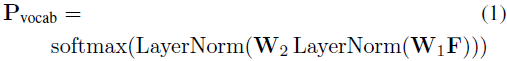
接着,利用 LLM 预训练的文本嵌入计算加权和,得到 对齐的视觉特征表示:
![]()
最后,将 对齐的视觉特征 与 文本输入的 token 嵌入 连接,形成 LLM 的最终输入:
![]()
其中,E_text(x) 通过对输入文本 x 进行 token 化,并从 E_text 中选取相应嵌入:
![]()
3)大型语言模型(LLM):采用 Llama 3.2 系列(1B、3B、8B 参数规模),处理文本输入和 ALIGN 模块输出。
3.2 训练流程
阶段 1:视觉-文本对齐训练(使用 CC-12M 数据集,增强视觉特征与 LLM 词汇嵌入的一致性)。
阶段 2:文档理解任务训练(使用 BigDocs-7.5M 数据集,提升 OCR、文档结构解析能力)。
阶段 3:指令微调(Instruction Tuning)(使用 DocDownstream 数据集,优化任务理解和问答能力)。
4. 实验结果
4.1 任务基准测试
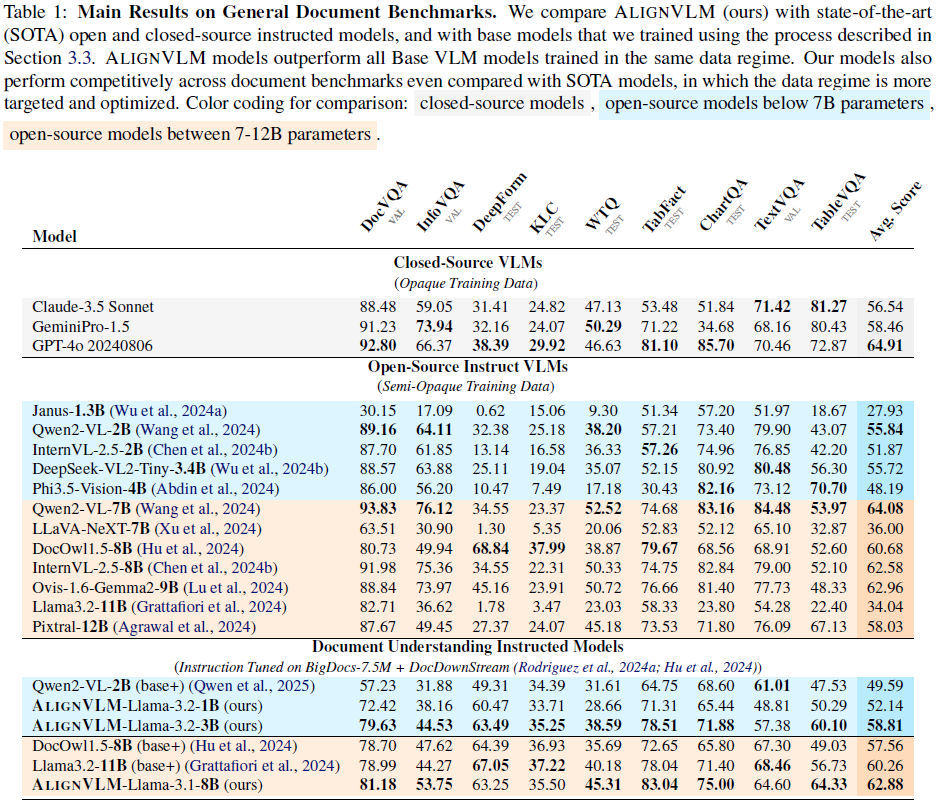
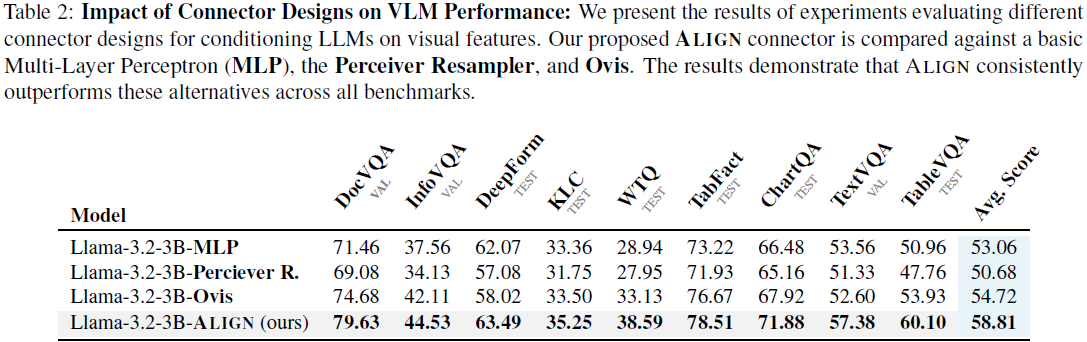
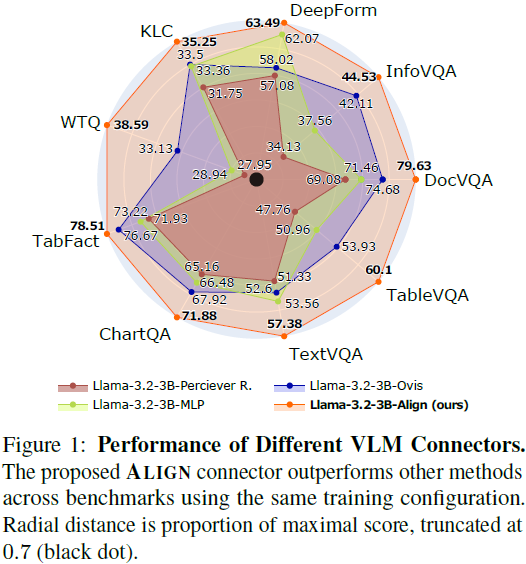
ALIGNVLM 在多个文档理解任务中表现优异:
- DocVQA(文档问答)、InfoVQA(信息提取)、TableVQA(表格问答) 等任务上,ALIGNVLM 超越了多个 SOTA 模型。
- 在 ALIGNVLM(Llama-3.2-3B) 对比中,ALIGN 连接器比 MLP、Perceiver Resampler、Ovis 等连接器的平均得分提高 约 5%~8%。

4.2 噪声鲁棒性和视觉-文本对齐分析
ALIGNVLM 显著 减少了视觉特征投影的噪声,提高了文本对齐能力。向视觉特征添加 高斯噪声(σ=3) 后:
- MLP 连接器 性能下降 25.54%。
- ALIGN 连接器 仅下降 1.67%,证明其对噪声具有更高的鲁棒性。
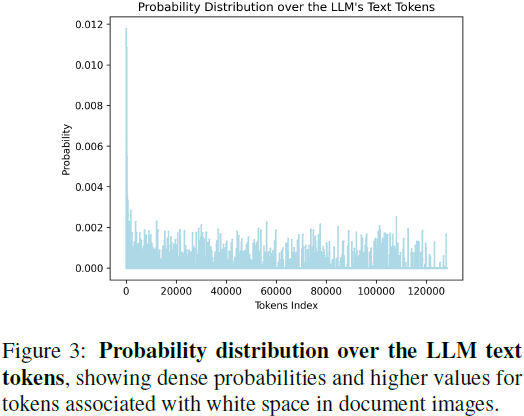
ALIGNVLM 的 视觉特征概率分布更密集,比 MLP 连接器的对齐效果更优。
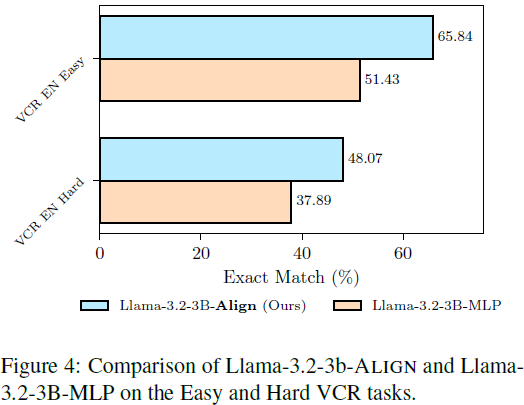
4.3 细粒度视觉任务(VCR 任务)
- VCR 任务考察模型的 像素级视觉和文本对齐能力。
- ALIGNVLM 在 遮挡文本恢复任务 上 比 MLP 连接器高 10%~14%,表明 ALIGN 连接器能更有效地利用视觉线索。

5. 结论
ALIGNVLM 通过 ALIGN 连接器 改进了视觉特征与 LLM 语义空间的对齐,避免了传统方法的 噪声问题,同时提高了 跨模态任务的性能。实验结果证明,该方法在多个基准任务中超越现有模型,是多模态文档理解的前沿技术。
论文地址:https://www.arxiv.org/abs/2502.01341
进 Q 学术交流群:922230617

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









