







小罗碎碎念
2025-01-08,Nature在线发表了一篇聚焦精准肿瘤学领域的论文,文中提出了一种名为MUSK的视觉 - 语言基础模型,旨在有效整合多模态数据,辅助临床决策。
如果之前看过CHIEF这篇文章的,今天这篇文章的作者们大家应该也会比较熟悉,因为前者的一作&通讯也都是这篇文章的作者,Ruijiang Li之前的一篇胃癌相关的三级淋巴结文章,我也在推送中分享过,所以也算是比较熟悉了。文章在线发表后,通讯作者给我转发了链接,但是前段时间感冒发烧,所以就拖到今天才和大家分享。
临床决策依赖多模态数据,而现有医学视觉 - 语言基础模型因依赖对比学习所需的配对数据且应用任务局限,发展受限。为此,研究团队开发了MUSK模型。该模型基于多模态transformer架构,通过统一掩码建模,在大规模未配对的5000万病理图像(patches,不是WSI)和10亿文本标记上预训练,并利用100万图像 - 文本对进行对比学习以对齐模态。

| 作者类型 | 姓名 | 单位 | 单位中文 |
|---|---|---|---|
| 第一作者 | Jinxi Xiang、Xiyue Wang | Department of Radiation Oncology, Stanford University School of Medicine, Stanford, CA, USA | 美国加利福尼亚州斯坦福大学医学院放射肿瘤学系 |
| 通讯作者 | Sen Yang | Department of Radiation Oncology, Stanford University School of Medicine, Stanford, CA, USA Stanford Institute for Human-Centered Artificial Intelligence, Stanford, CA, USA | 美国加利福尼亚州斯坦福大学医学院放射肿瘤学系 美国加利福尼亚州斯坦福大学人工智能研究所 |
| 通讯作者 | Ruijiang Li | Department of Radiation Oncology, Stanford University School of Medicine, Stanford, CA, USA Stanford Institute for Human-Centered Artificial Intelligence, Stanford, CA, USA | 美国加利福尼亚州斯坦福大学医学院放射肿瘤学系 美国加利福尼亚州斯坦福大学人工智能研究所 |
在23个下游任务的广泛基准评估中,MUSK表现卓越。在跨模态检索、视觉问答、图像检索与分类、分子生物标志物预测等任务上超越了现有基础模型。尤其在临床结果预测方面,MUSK在黑色素瘤复发预测、泛癌预后预测以及肺癌和胃食管癌免疫治疗反应预测中,显著提高了预测的准确性,充分展现了其多模态融合的优势。
MUSK为精准肿瘤学提供了有效的多模态数据整合方法,有助于提升癌症诊断和治疗的精准度。然而,该模型在临床应用前,需在更大规模、多机构的队列中进行验证,并获得监管批准。未来,随着模型的进一步优化和验证,有望推动临床实践的变革,为癌症患者提供更精准的医疗服务 。
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
一、文献速览
1-1:研究背景
- 临床决策与多模态数据临床决策依赖多模态数据,人工智能整合多模态数据有望推动临床医疗发展,但临床中注释良好的多模态数据集稀缺阻碍了模型开发。
- 基础模型的发展与挑战基础模型在医学AI领域兴起,然而多模态AI模型因缺乏注释良好的数据集发展受限。当前医学视觉语言基础模型存在依赖对比学习需大量配对数据、应用任务简单且未涉及治疗反应和结果预测等问题。
1-2:MUSK模型设计与训练
- 模型架构基于多模态transformer,含共享自注意力块及独立视觉和语言专家模块,通过统一掩码建模和对比学习进行预训练。
- 预训练数据使用11,577名患者的5000万张病理图像(patches,不是WSI)和10亿个病理相关文本标记进行统一掩码学习,利用100万图像 - 文本对进行对比学习,提升模态对齐。
- 预训练步骤先通过掩码语言建模和掩码图像建模对大规模未配对图像和文本进行统一掩码预训练,再用对比学习在图像 - 文本对上进一步训练以对齐模态。
- 消融实验通过对病理特定增强、特定tokenizer、细粒度解码器和引导对比学习等关键改进进行消融实验,证明其对模型性能优化至关重要。
1-3:实验评估与结果
- 跨模态检索在BookSet和PathMMU数据集上,MUSK在零样本跨模态检索任务中表现优异,图像到文本和文本到图像检索的Recall@50指标优于其他模型。
- 视觉问答在PathVQA数据集上,MUSK准确率达73.2%,超越其他视觉语言基础模型,比专为视觉问答设计的K - PathVQA模型准确率高7%。
- 图像检索与分类在图像检索和分类任务中,MUSK在零样本、少样本和有监督学习场景下,于多个基准数据集上均取得出色成绩,证明其作为图像编码器的强大能力。
- 分子生物标志物预测在预测乳腺癌受体状态和脑肿瘤IDH突变状态时,MUSK性能显著优于其他病理基础模型。
- 临床结果预测在黑色素瘤复发预测、泛癌预后预测以及肺癌和胃食管癌免疫治疗反应预测任务中,MUSK均表现出色,能有效整合多模态数据提升预测准确性。
1-4:研究结论
- 模型优势MUSK在多种下游任务中性能超越现有基础模型,有效整合临床报告和图像的互补信息,提升结果预测准确性。
- 临床意义为精准肿瘤学提供有效工具,可辅助医生进行疾病诊断、风险评估和治疗决策,有望改善癌症治疗效果。
- 未来展望需在更大规模多机构队列中验证模型,获取监管批准以用于临床实践,推动临床指南和实践变革。
二、模型背景介绍
2-1:MUSK模型的预训练过程
MUSK模型的预训练过程,包括模型所基于的架构、预训练的数据来源以及预训练的两个阶段。
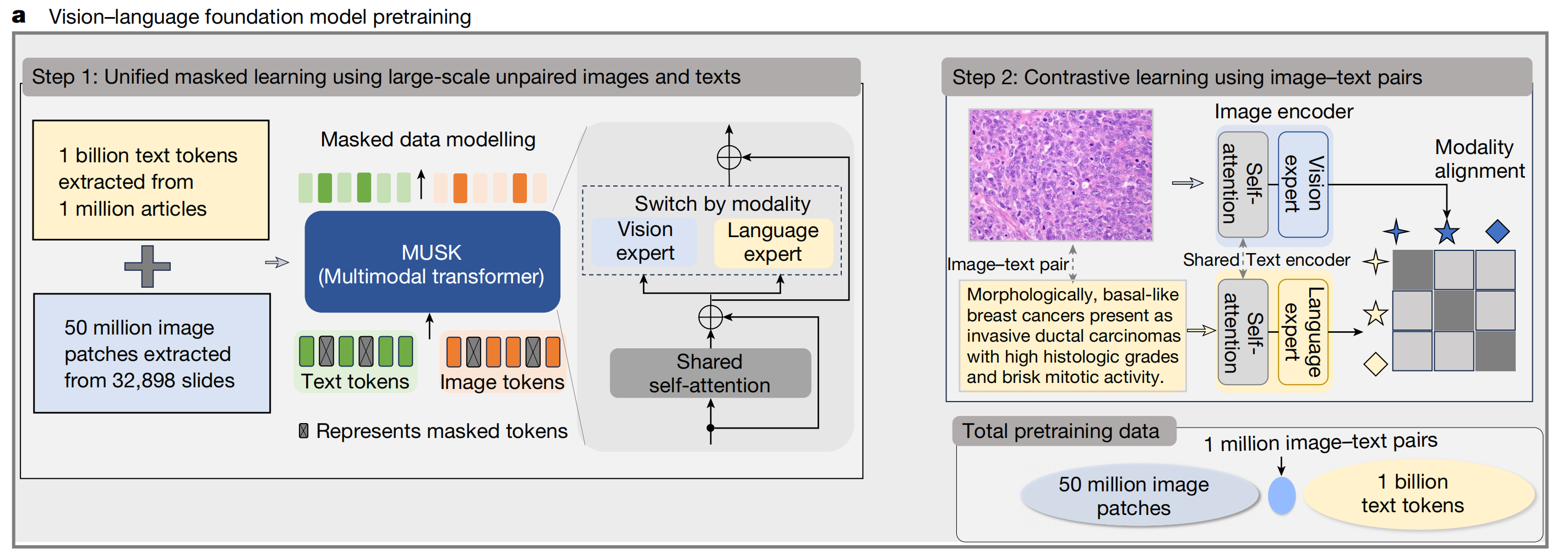
模型架构
MUSK模型是基于多模态Transformer架构构建的,该架构作为网络的主干。
模型由共享的自注意力块以及两个分别处理视觉和语言输入的独立专家模块组成。这种架构设计使得模型能够有效地处理和融合视觉和语言两种不同模态的信息。
预训练数据
数据来源丰富,包括从11,577名患者的近33,000张全切片组织病理学扫描图像中提取的5000万张病理图像(patches,不是WSI),这些图像涵盖了33种肿瘤类型;以及从100万篇文章中提取的10亿个病理相关文本标记。
预训练阶段
第一阶段:统一掩码学习
- MUSK首先在5000万张病理图像(patches,不是WSI)和10亿个病理相关文本标记上进行预训练。
- 预训练方法采用了掩码建模,即对文本标记和图像标记中的部分内容进行掩码处理,然后让模型去预测这些被掩码的内容。
- 通过这种方式,模型能够学习到文本和图像的内在特征和表示,以及它们之间的潜在关系。
第二阶段:对比学习
- 之后,MUSK在来自QUILT - 1M模型的100万对图像 - 文本对上进行预训练。
- 此次预训练使用对比学习的方法,目的是实现多模态的对齐。对比学习通过拉近正样本(匹配的图像 - 文本对)之间的距离,同时推远负样本(不匹配的图像 - 文本对)之间的距离,使模型能够更好地理解图像和文本在语义上的对应关系,从而增强模型在处理多模态数据时的能力和准确性。
2-2:通用临床应用
通用临床应用(General-purpose clinical applications)的相关内容,主要涉及癌症检测与诊断(Cancer detection and diagnosis)以及结果预测(Outcome prediction)两大部分。
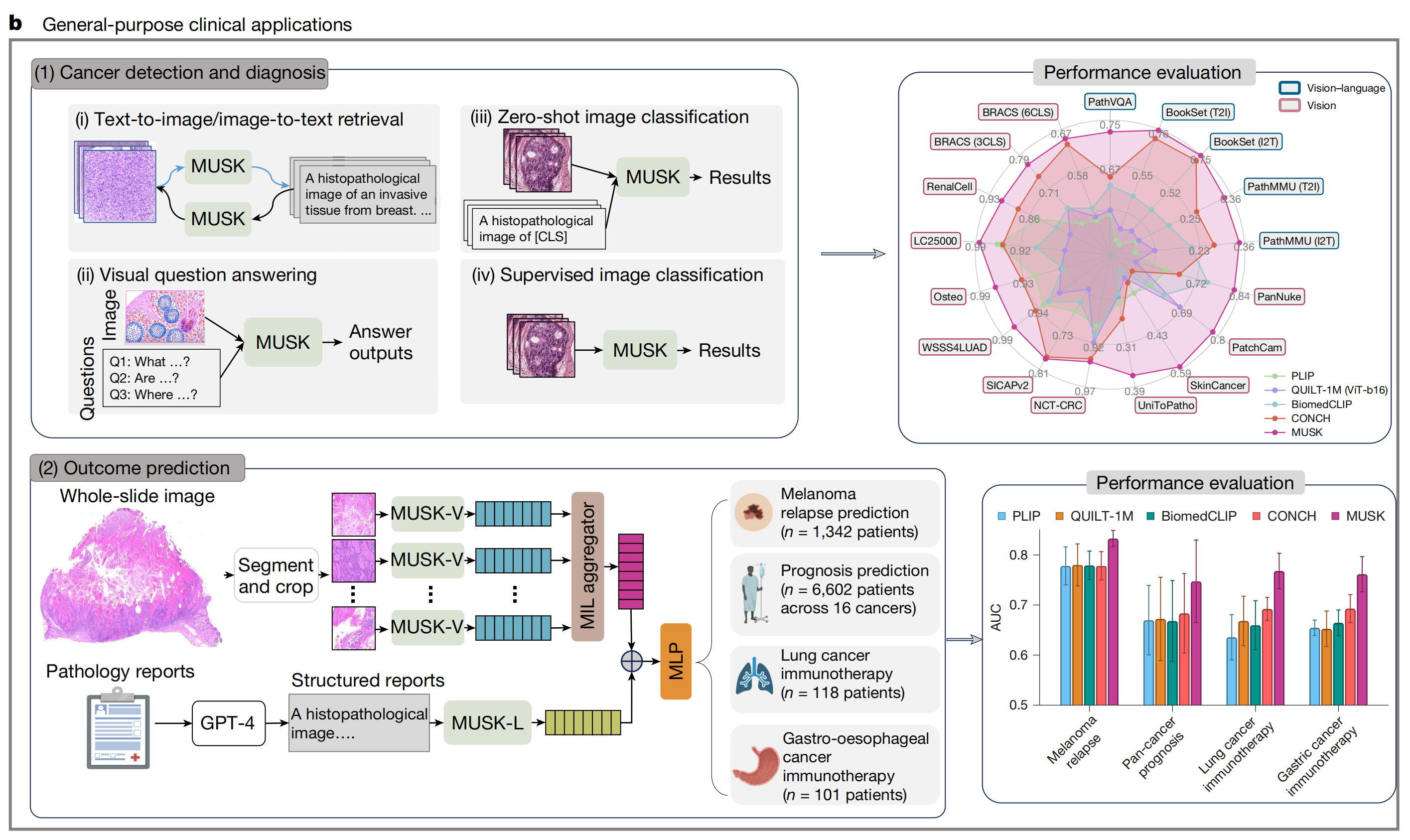
癌症检测与诊断部分
- 文本到图像/图像到文本检索(Text-to-image/image-to-text retrieval):展示了将组织病理图像(如乳腺癌的侵袭性组织病理图像)通过MUSK模型进行文本到图像或图像到文本的检索过程。
- 视觉问答(Visual question answering):针对图像提出问题(如What…? Are…? Where…?),然后通过MUSK模型得到答案输出。
- 零样本图像分类(Zero-shot image classification):输入一张病理图像(如[CLS]的病理图像),通过MUSK模型得到分类结果。
- 有监督图像分类(Supervised image classification):同样是输入病理图像,由MUSK模型给出分类结果。
结果预测部分
- 全切片图像(Whole-slide image):先对全切片图像进行分割和裁剪(Segment and crop),然后将分割后的图像通过MUSK-V模型处理,再经过多实例学习聚合器(MIL aggregator)。
- 病理报告(Pathology reports):将结构化的病理报告通过GPT-4处理,生成病理图像相关内容,再由MUSK-L模型处理。
性能评估部分
- 右侧上方是一个雷达图,展示了不同模型(包括MUSK、PLIP、QUILT-1M、BiomedCLIP、CONCH等)在多个数据集(如BRACS、PathVQA、BookSet、RenalCell等)上的性能表现,分为视觉语言(Vision-language)和视觉(Vision)两类。
- 右侧下方是柱状图,展示了不同模型在黑色素瘤复发预测(Melanoma relapse prediction,n = 1,342 patients)、16种癌症的预后预测(Prognosis prediction across 16 cancers,n = 6,602 patients)、肺癌免疫治疗(Lung cancer immunotherapy,n = 118 patients)、胃食管癌免疫治疗(Gastro-oesophageal cancer immunotherapy,n = 101 patients)等方面的性能(以AUC值衡量),其中MUSK模型在多个方面表现较好。
整体来看,这张图展示了MUSK模型在癌症临床应用中的多种功能及其相对其他模型的性能优势,涉及从图像和文本的交互处理到结果预测等多个方面,为癌症的检测、诊断和预后评估提供了一种新的技术思路和性能参考。
2-3:视觉问答测试
这部分主要展示了视觉问答(Visual question answering)相关的内容,包括不同模型在该任务上的准确率对比以及一些具体的视觉问答结果示例。
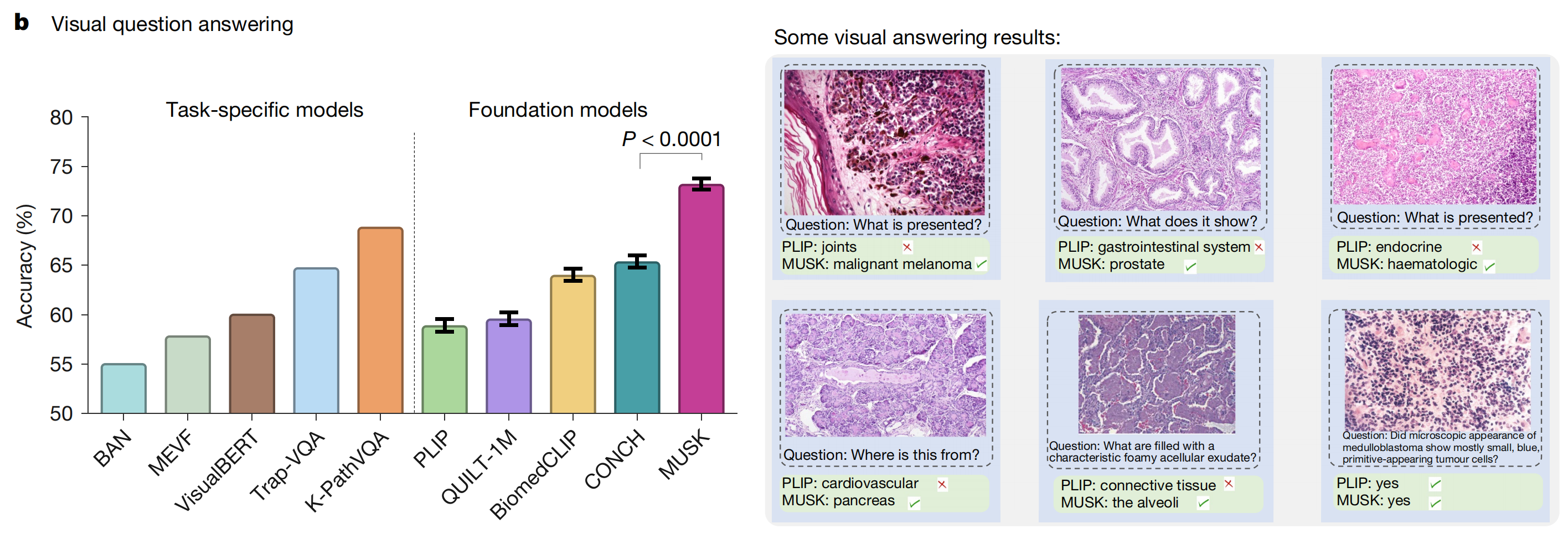
左侧部分:不同模型的准确率对比
分为任务特定模型(Task-specific models)和基础模型(Foundation models)两类。
右侧部分:一些视觉问答结果示例
示例展示:展示了六张病理组织图像,并针对每张图像提出了一个问题,同时给出了PLIP模型和MUSK模型的回答及正误判断。
- 第一张图像:问题是“What is presented?”,PLIP回答“joints”(错误),MUSK回答“malignant melanoma”(正确)。
- 第二张图像:问题是“What does it show?”,PLIP回答“gastrointestinal system”(错误),MUSK回答“prostate”(正确)。
- 第三张图像:问题是“What is presented?”,PLIP回答“endocrine”(错误),MUSK回答“haematologic”(正确)。
- 第四张图像:问题是“Where is this from?”,PLIP回答“cardiovascular”(错误),MUSK回答“pancreas”(正确)。
- 第五张图像:问题是“What are filled with a characteristic foamy acellular exudate?”,PLIP回答“connective tissue”(错误),MUSK回答“the alveoli”(正确)。
- 第六张图像:问题是“Did microscopic appearance of medulloblastoma show mostly small, blue, primitive-appearing tumour cells?”,PLIP回答“yes”(正确),MUSK回答“yes”(正确)。
整体来看,这张图通过数据和实例展示了MUSK模型在视觉问答任务上相对于其他模型的优越性,尤其是在病理组织图像相关的视觉问答方面,MUSK模型能够更准确地回答问题,具有较高的应用价值和潜力。
2-4:免疫疗效预测
这张图片(图d)展示了肺癌病例中对免疫疗法有客观反应和无客观反应的两个示例。
这张图片(图d)展示了肺癌病例中对免疫疗法有客观反应和无客观反应的两个示例。
-
有反应的病例(Responder):
- 原始WSI(全切片图像):左侧图像是原始的全切片图像,呈现出肺癌组织的形态,图像主要为紫色调,下方标注有“5 mm”的比例尺。可以看到组织的整体结构和分布。
- 热图(Heat map):中间图像是对应的热图,热图使用红、橙、黄、蓝等颜色来突出显示模型在全切片图像中关注的区域,比例尺同样为“5 mm”。热图能够直观地展示模型认为重要的区域分布情况。
- 关注区域放大图(ROI 1和ROI 2):右侧的图像是模型最关注区域的放大视图,比例尺为“200 µm”。可以更清晰地看到这些区域的细节,该有反应的病例显示出淋巴细胞大量浸润且间质极少的特征。
-
无反应的病例(Non-responder):
- 原始WSI(全切片图像):左侧是原始全切片图像,呈现出肺癌组织的样子,图像为紫色调,下方标注有“2 mm”的比例尺。
- 热图(Heat map):中间是对应的热图,使用类似的颜色编码,比例尺为“2 mm”,显示模型关注的区域。
- 关注区域放大图(ROI 1和ROI 2):右侧是模型最关注区域的放大图像,比例尺为“200 µm”,该无反应的病例显示出淋巴细胞浸润极少且间质丰富的特征。
通过对比这两个病例,包括原始全切片图像、热图以及关注区域的放大图,可以清晰地看到有反应和无反应病例在病理组织特征上的差异,有反应的病例淋巴细胞浸润多、间质少,而无反应的病例则相反,这些信息对于研究肺癌对免疫疗法的反应机制以及寻找可能的诊断和预后标志物等方面具有重要意义。
热图则帮助我们了解模型在分析这些病理图像时所关注的重点区域,为进一步的研究和分析提供了有价值的参考。
2-5:MUSK的模型结构及其参数信息
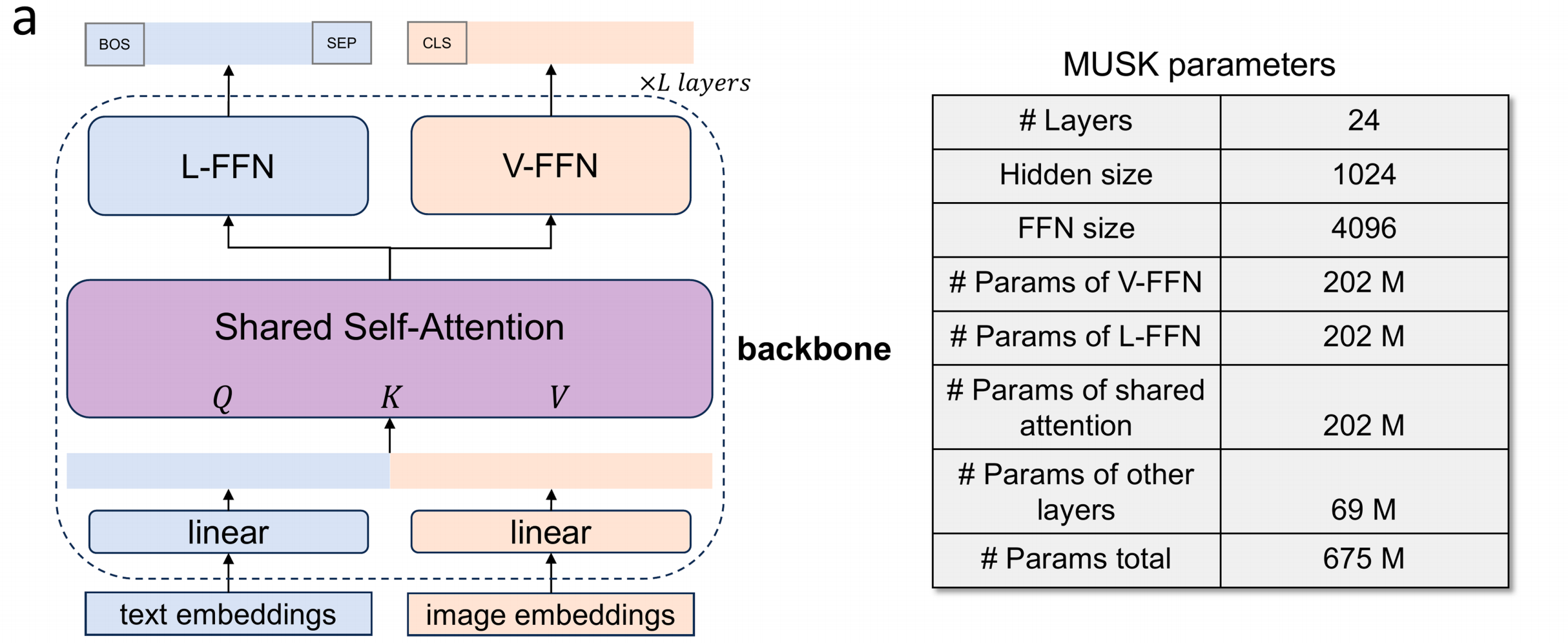
左侧部分:模型结构
输入层:
- 文本嵌入(text embeddings)通过一个线性层(linear)处理,图像嵌入(image embeddings)也通过一个线性层处理。
- 文本嵌入部分有起始标记(BOS)和分隔标记(SEP),图像嵌入部分有分类标记(CLS)。
共享自注意力层(Shared Self-Attention):
处理来自文本和图像嵌入的信息,通过查询(Q)、键(K)、值(V)的机制进行自注意力计算,这是模型的核心部分,用于捕捉文本和图像之间的交互关系和特征。
前馈网络层(Feed-Forward Networks):
- 包括文本前馈网络(L-FFN)和图像前馈网络(V-FFN),分别对经过共享自注意力层处理后的文本和图像信息进行进一步的特征提取和变换。
- 整个结构重复L层(×L layers),以逐步深化模型对输入信息的理解和处理。
右侧部分:MUSK参数
- 层数(# Layers):24层,表示整个模型结构重复的层数。
- 隐藏层大小(Hidden size):1024,指模型中隐藏层的维度大小。
- 前馈网络大小(FFN size):4096,前馈网络的维度大小。
- V-FFN的参数数量(# Params of V-FFN):202 M(2.02亿),图像前馈网络的参数数量。
- L-FFN的参数数量(# Params of L-FFN):202 M(2.02亿),文本前馈网络的参数数量。
- 共享自注意力层的参数数量(# Params of shared attention):202 M(2.02亿),共享自注意力层的参数数量。
- 其他层的参数数量(# Params of other layers):69 M(0.69亿),除上述主要层之外的其他层的参数数量。
- 总参数数量(# Params total):675 M(6.75亿),整个模型的总参数数量。
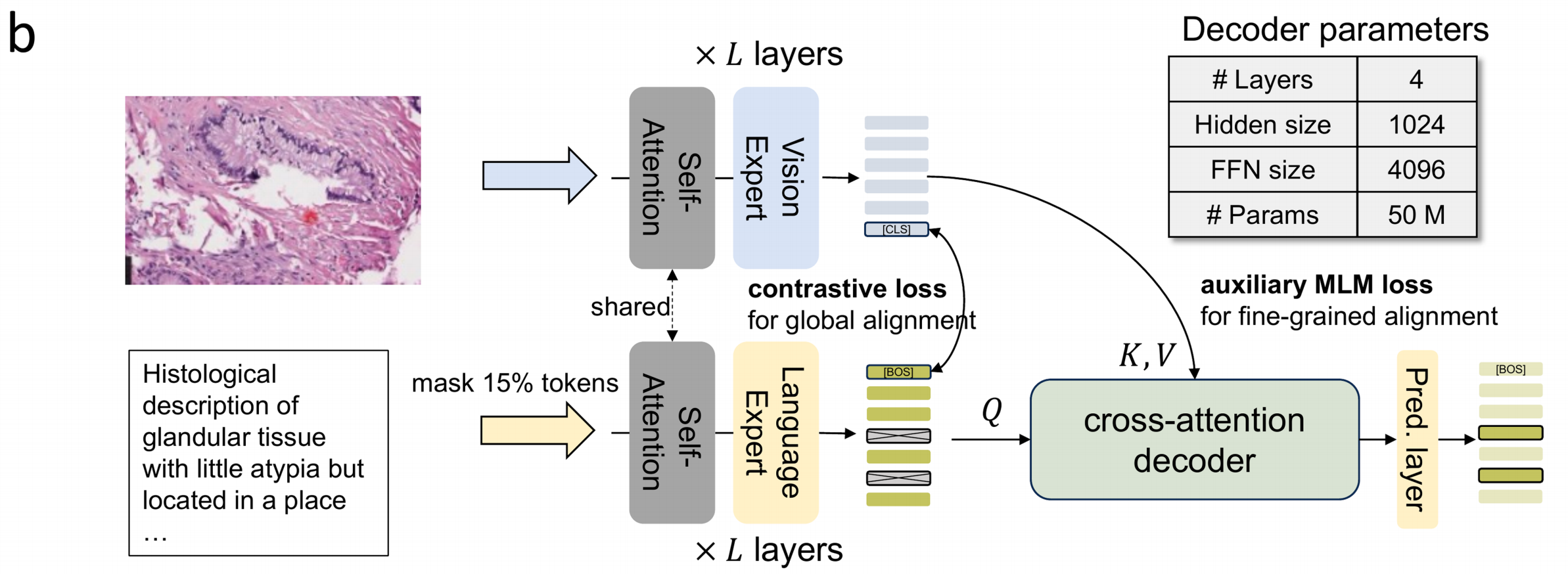
整体流程
在预训练的第二阶段,MUSK模型需要进行模态对齐(modality alignment),这里使用对比损失(contrastive loss)作为训练目标,同时还增加了一个辅助的掩码语言模型(MLM)损失。
各部分具体解释
图像输入:从左侧可以看到一张病理组织图像(Histological image),例如这里展示的是腺体组织(glandular tissue)的病理图像,伴有少量非典型性(little atypia)且位于某个位置等描述。这张图像会经过一系列处理。
视觉部分(Vision):
-
图像首先经过自注意力(Self-Attention)机制,然后进入视觉专家(Vision Expert)模块。经过这一系列处理后,会得到与图像相关的特征表示,图中用浅蓝色的方块表示。
-
这里的视觉部分重复L层(×L layers),以逐步深化对图像信息的提取和处理。
-
文本输入:下方是对病理组织的文字描述(Histological description of glandular tissue with little atypia but located in a place…),在处理过程中会掩码(mask)其中15%的标记(tokens)。
- 文本同样先经过自注意力机制,然后进入语言专家(Language Expert)模块,得到与文本相关的特征表示,用浅黄色的方块表示。这里的文本部分也重复L层。
-
模态对齐与损失函数:
- 对比损失(contrastive loss for global alignment):用于实现视觉和语言模态的全局对齐,即让模型学习到图像和文本在整体层面上的关联和一致性。
- 辅助MLM损失(auxiliary MLM loss for fine-grained alignment):这个MLM组件利用了一个简化的交叉注意力解码器(cross-attention decoder),它将文本嵌入作为查询(queries),与图像嵌入进行动态交互,从而注入精细的跨模态信息,实现更细粒度的对齐,帮助模型更好地理解图像和文本之间的细节关联。
-
解码器参数(Decoder parameters):
- 右侧的表格展示了解码器的参数信息,包括层数(# Layers)为4层,隐藏层大小(Hidden size)为1024,前馈网络大小(FFN size)为4096,参数数量(# Params)为50M(5000万)。
总体而言,这张图展示了MUSK模型在预训练第二阶段中,如何通过特定的结构和损失函数来实现图像和文本模态的对齐,以增强模型对多模态信息的处理和理解能力,尤其是在病理图像和相关文字描述的场景下,这种模态对齐对于准确的信息提取和分析具有重要意义。


















 5341
5341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









