







前言:这节课内容,介绍的是无人驾驶里面感知部分,静态环境感知基本知识,主要介绍一些图片处理算法。算法介绍,是结合一些GitHub开源项目以及论文来展开的,其中包括了车道线检测算法传统方式和深度学习方式。传统方式的在个人电脑实现了,其他涉及tensorflow,也就是深度学习方面的,都没有成功,比较遗憾。由于本人之前没有搞过深度学习,图像处理相关的,所以,只能说,这里面的内容,仅供大家参考。有不恰当地方,欢迎批评指出。
后面学校这边时间宽松些,一定会尽快解决环境配置问题(如果有大佬愿意指点一下,非常感谢),跑一下那些项目,然后也更新到这blog这里面的。–20201211
下面开启激动人心的时刻:
1、感知
20201213
1.1、广义感知
1)感知外界外界:
A、目的:感知外界环境
静态环境:车道线/路面/交通标识(识别作用:辅助规划决策;帮助更好感知运动物体状态)
动态物体:运动物体(车、人)的运动状态(位置/朝向/速度/…)
B、传感器:单目(图片)/双目(深度图/稠密点云)/激光雷达(稀疏点云)/毫米波雷达/超声波雷达
2)感知自身(定位):
A、目的:感知自身的运动状态(位置/朝向/速度/…)
B、传感器:GPS 、IMU 、HDmap、SLAM(单目、双目、RGBD、激光雷达、超声波雷达 包含VIO)
1.2图像
1)四大任务:
–分类(图片类型分类)
–分割(像素分类,如一张图片中的人、狗、路面区分出来)
–检测(框分类,如对图片中框出来的人、狗等,再进行分类)
–跟踪(使用物体的一切信息进行时序关联,如对于图片中同一物体,动态图片中,可以持续识别出来)
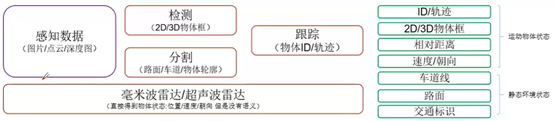
注意:
a、图片/点云数据:原始数据需要外部算法处理才能得到环境信息;
b 、毫米波/超声波雷达:传感器内置处理算法(根据多普勒效应计算的);
c、实际上,雷达信号类型,跟点云类型有区别的;
d、路面分割,相对于图片,雷达更好做;车道线分割,使用图片分割比较容易做;
e、图片、点云可以提供语义信息(如物体轮廓等),但是雷达提供不了语义信息,所以,希望可以通过两者的融合来获取更好的信息;
f、雷达,内部集成了检测和跟踪的算法;其感知数据不属于图片、点云、深度图。
2、segmentation(分割)
2.1 实战基于传统方法的车道线检测(非深度学习cnn算法)
【这个案例已复现】
code:https://github.com/andylei77
ref:https://towardsdatascience.com/tutorial-build-a-lane-detector-679fd8953132
import cv2 as cv #图像处理的库
import numpy as np #矩阵运算的库
cap = cv.VideoCapture("input.mp4") #利用opencv打开视频
while (cap.isOpened()): #只要视频还是打开的,都运行下面循环体
# ret = a boolean return value from getting the frame, frame = the current frame being projected in the video
#检测每一帧图像,检测到该帧则返回true,否则返回false
ret, frame = cap.read()
canny = do_canny(frame) #canny是边沿检测,检测所有的线
cv.imshow("canny", canny)
# plt.imshow(frame)
# plt.show()
segment = do_segment(canny) #手动分割,自定义图线有效区域
hough = cv.HoughLinesP(segment, 2, np.pi / 180, 100, np.array([]), minLineLength = 100, maxLineGap = 50) #剖复变换来从上面筛选出的图线集里面确定车道线
# Averages multiple detected lines from hough into one line for left border of lane and one line for right border of lane
lines = calculate_lines(frame, hough) #后处理
# Visualizes the lines
lines_visualize = visualize_lines(frame, lines)
cv.imshow("hough", lines_visualize) #这行和上面的那一行作用是显示车道线
# Overlays lines on frame by taking their weighted sums and adding an arbitrary scalar value of 1 as the gamma argument
output = cv.addWeighted(frame, 0.9, lines_visualize, 1, 1)#将上面显示的图线和原始的图片叠加在一起
# Opens a new window and displays the output frame
cv.imshow("output", output)
# Frames are read by intervals of 10 milliseconds. The programs breaks out of the while loop when the user presses the 'q' key
if cv.waitKey(10) & 0xFF == ord('q'):
break
# The following frees up resources and closes all windows
cap.release() #释放资源
cv.destroyAllWindows()#关掉窗口
2.1.1 canny边沿检测
1)基本原理:检测亮度的急剧变化(大梯度,比如从白色到黑色)在给定阈值下定义为边
2)预处理:转换灰度图
3)Canny:
–降噪:噪声容易导致误检,用5*5的高斯滤波器(正太分布核)对图像做卷积(平滑图像)[Canny]
–求亮度梯度:在平滑的图像上用Sobel/Roberts/Prewitt核沿x轴和y轴检测边沿是水平/垂直/对角线
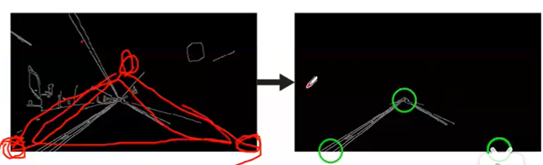
–非极大值抑制:细化边缘。检查每个像素值在先前计算的梯度方向上是否为局部最大值(相对B、C,如果A是局部最大,则在下一个点上检查非极大值抑制,否则将A的像素设置为0,并抑制A)。(看右侧轴线图)
–hysteresis thresholding:非极大值抑制后可以确认强像素在最终边缘映射中,但还要对弱像素进一步进行分析确认它是边缘还是噪声。
1)梯度>maxVal的是边缘
2)梯度小于minVal的不是边缘并将其删除
3)梯度在[minVal,maxVal]的像素,只有在和梯度高于maxVal的像素相连时才是边缘

个人理解:非极大值抑制,就是不是极大值就去掉意思。上图意思就是,如果点过于集中,就应该去掉一部分。
def do_canny(frame):
# Converts frame to grayscale because we only need the luminance channel for detecting edges - less computationally expensive
gray = cv.cvtColor(frame, cv.COLOR_RGB2GRAY)#预处理,将彩色图变为灰度图
# Applies a 5x5 gaussian blur with deviation of 0 to frame - not mandatory since Canny will do this for us
blur = cv.GaussianBlur(gray, (5, 5), 0)#预处理,通过高斯滤波器降噪
# Applies Canny edge detector with minVal of 50 and maxVal of 150
canny = cv.Canny(blur, 50, 150)#边缘检测.50就是minVal,150就是maxVal
return canny
2.1.2手动分割路面区域
1)通俗理解:手动指定一个三角形来分割路面区域,去除其他干扰边缘
2)简单效果展示: segment = do_segment(canny) #手动分割,自定义图线有效区域
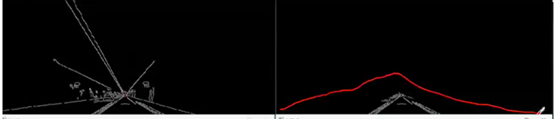
一开始是左侧图像的,经过这个函数处理,去除了三角形(如红色手画框)外的白线,效果如右侧图。
3)函数具体解析
def do_segment(frame):
# Since an image is a multi-directional array containing the relative intensities of each pixel in the image, we can use frame.shape to return a tuple: [number of rows, number of columns, number of channels] of the dimensions of the frame
# frame.shape[0] give us the number of rows of pixels the frame has. Since height begins from 0 at the top, the y-coordinate of the bottom of the frame is its height
height = frame.shape[0]
# Creates a triangular polygon for the mask defined by three (x, y) coordinates
polygons = np.array([
[(0, height), (800, height), (380, 290)]#三角形三点坐标(左上角为原点,向右为x正,向下为y正)
])
# Creates an image filled with zero intensities with the same dimensions as the frame
mask = np.zeros_like(frame)#生成一张图片,填充都是0
# Allows the mask to be filled with values of 1 and the other areas to be filled with values of 0
cv.fillPoly(mask, polygons, 255)#图片的三角形区域填充255
# A bitwise and operation between the mask and frame keeps only the triangular area of the frame
segment = cv.bitwise_and(frame, mask)#这里做掩码操作,frame是原图,mash与其做按位与的操作,抽出255区域部分,其他部分保留0,从而实现抽取图像目标区域目的
return segment
理解关键点在于,掩码处理抽取图像目标区域
2.1.3霍夫变换得到车道线(车道线是一线束)
1)性质:

简单理解,笛卡尔坐标系里面是线的话,霍夫变换后,在霍夫空间中,表现为一个点。
2)霍夫变换如何帮助我们找到线?
–将笛卡尔坐标系中一系列可能被连成线的点->该点在霍夫空间对应的线
–找到霍夫空间中的线交点(m,b),就是对应(车道)线的方程(笛卡尔坐标系)
3)霍夫空间中相交的线越多,交点表示的线在笛卡尔坐标系中对应的点越多。我们在霍夫空间中定义交点的最小阈值来检测线。霍夫变换跟踪帧中的每个点的霍夫空间交点。如果交点数量超过了阈值就确定了一条对应参数的 0(角度,中间还有一横)和d的线。
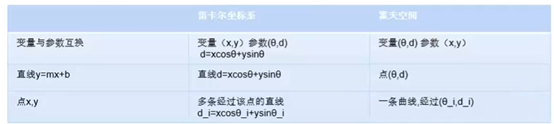
4)霍夫变换找线通俗理解,就是将笛卡尔坐标系上的可疑的点(梯度较大,有可能是车道线上的点)变换到霍夫空间的线,这些线的交点(其对应笛卡尔坐标系中的车道线),这个交点对应的(m,b)就是我们有可能想要找的车道线的方程。
5)笛卡尔上可以点转换霍夫空间线,霍夫线交点就是要找的笛卡尔坐标系中车道线

6)霍夫变换,可能得到的直线很多,如图中右上角的一段一段的,并不是连起来的直线(又或者像左下角的两个红色包围的直线蔟区间),通过后处理,求他们的斜率和截距平均值,最后输出两个绿色车道线。

2.1.4获取车道线并叠加到原始图像中
1)综合所有线,求得两条车道线的平均斜率和截距

2)代码解析
def calculate_lines(frame, lines):#lines是霍夫变换得到的线集,左右各4条
#该函数,就是计算两边线束各自的斜率以及截距平均值
# Empty arrays to store the coordinates of the left and right lines
left = []
right = []
# Loops through every detected line
for line in lines:#遍历每一根检测到的线
# Reshapes line from 2D array to 1D array#将线的2d数组表示转为1d数组表示
x1, y1, x2, y2 = line.reshape(4)
# Fits a linear polynomial to the x and y coordinates and returns a vector of coefficients which describe the slope and y-intercept
#计算线的直坐标系表达式,返回系数斜率和截距
parameters = np.polyfit((x1, x2), (y1, y2), 1)#计算表达式,并获取系数
slope = parameters[0]#斜率
y_intercept = parameters[1]#截距
# If slope is negative, the line is to the left of the lane, and otherwise, the line is to the right of the lane
#斜率是负数,那么就是左车道线;否则,为右车道线
if slope < 0:
left.append((slope, y_intercept))
else:
right.append((slope, y_intercept))
# Averages out all the values for left and right into a single slope and y-intercept value for each line
#求车道线的平均斜率和平均截距
left_avg = np.average(left, axis = 0)
right_avg = np.average(right, axis = 0)
# Calculates the x1, y1, x2, y2 coordinates for the left and right lines
#计算左右车道线在原图中的位置
left_line = calculate_coordinates(frame, left_avg)
right_line = calculate_coordinates(frame, right_avg)
return np.array([left_line, right_line])#返回左右车道线的数据数组
注意,下面深度学习感知的案例都是没有复现的,初步原因是个人环境配置还是有问题导致的。因此,仅供参考。
2.2 图片分割算法综述(基于深度学习cnn分割算法)
ref:
https://blog.csdn.net/Julialove102123/article/details/80493066
a survey on dnn based semantic segmentation
2.2.1 图片分割的类型
1)普通分割:
–将属于不同物体的像素区域分开即可
–如前景与背景分割,狗的区域与背景分割开
如下左图
2)语义分割:
–在普通分割的基础上,还要分类出每一块区域的语义(类别)
如下中图
3)实例分割
–在语义分割的基础上,还要进一步区分同种物体的不同个体
如下右

4)检测的话,需要有框,才能分类

2.2.2深度学习图片语义分割算法思路
深度学习自从被引入图像处理这个任务到现在,一个通用的框架已经大致确定。(如果对卷积神经这些基本概念都不清楚的话,可以参考这篇博客,个人感觉说得挺通俗易懂的,https://blog.csdn.net/m0_37490039/article/details/79378143)
1)前端:使用全卷积网络进行特征提取
–下采样+上采样:convlution+Deconvlution/Resize (下采样,图片尺寸越来越小;上采样,图片尺寸越来越大)
–多尺度特征融合:逐点特征相加/特征拼接
–获得像素级别的segement map:对每一个像素点进行判断类别

2)后端:后端使用CRF(条件随机场)/MRF(马尔科夫随机场)优化前端的输出得到优化后的分割图
如,图中人和羊连接处,利用这些场做好了优化
3)全卷积网络,全部都是卷积层
4)上采样可以理解为对图像进行编码,提取比较高层的特征信息;下采样可以理解为对信息进行解码,解码信息的类别
2.2.3典型算法结构

像素分类最好不用fc层
2.2.4 FCN
原论文:Fully Convolutional Networks for Semantic Segmentation
1)意义:首次将深度学习引入图片语义分割
2)主要贡献:
2-1)提出全卷积网络:将全连接层替换成了全卷积层(全链接等效为卷积核是输入特征大小的卷积),使得网络可以接受任意大小的图片,并输出和原图一样大小的特征图。只有这样,才能为每个像素做分类。
2-2)使用反卷积层(deconvolution)做上采样:特征图一般只有原图的几分之一大小。想要映射回原图大小必须对特征图进行采样。作者使用反卷积来做上采样。虽然名字叫反卷积层,但其实它并不是卷积的逆操作,更合适的名字叫做转置卷积(Transposed Convolution),作用是从小的特征图卷出大的特征图。反卷积和卷积类似,都是相乘类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。
2-3)Skip Layer:Skip的目的就是特征融合。如果将全卷积之后的结果直接上采样,得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后融合再做图像分类。不同上采样结构得到的结果对比如下图。当然,也可以将pool1,pool2的输出再上采样输出。不过,作者说这样的到的结果提升并不大

2.2.5 U-Net
1)U-Net是原作者参加ISBI Challenge提出的一种分割网络,能够适应很小的训练集(大概30张图)。U-Net与FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构简单。
2)整个U-Net网络结构如图,类似一个U字母:首先进行Conv+Pooling下采样,然后Deconv反卷积进行上采样,crop之前的低层feature map进行融合,然后再次上采样。重复这个过程,直到输出388x388x2的feature map,最后经过softmax 获得output segment map。总体来说与FCN思路非常类似。
3)与FCN逐点相加不同,U-Net采用将特征再channel维度拼接在一起,形成更“厚”的特征。

2.2.6 SegNet/DeconvNet
1)更好的上采样模式:采用类似编码器的对称结构,先编码再解码
2)反卷积和上池化
–反卷积同上(反卷积做上采样?这里忘了怎么说的了。。。)
–上池化的实现主要在于池化时,记住输出值的位置,再上池化时再将这个值填回原来的位置,其他位置填0


2.2.7 PSPNet
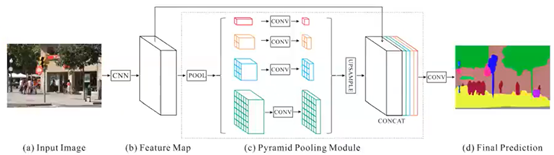
1)Pyramid Scene Parsing Network核心贡献是Global Pyramid Pooling(全局金字塔池化)
–将特征图缩放到几个不同尺寸,上采样后与之前特征融合,使得特征具有更好地全局和多尺度信息,对区分不同类别有帮助(不仅是语义分割,金字塔多尺度特征对于各类视觉问题都挺有用的)
–1x1 conv in Pyramid Pooling Module to reduce the dimension of context representation
–Use dilated conv ResNet
2.2.8 DeepLab
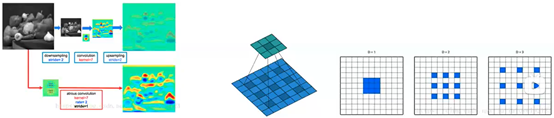
DeepLab有v1 v2 v3,其中v1是《DeepLab:Semantic Image Segmentation with Deep Convolutianal Nets,Atrous Convolution,and Fully Connected CRFs》一系列论文引入了以下几点比较重要的方法:
Dilated/Atrous Convolution:空洞卷积
–引用原因分析:为了保证之后输出的尺寸不至于太小,FCN的作者在第一层直接对原图加了100的padding,可想而知这回引入噪声。还有没有其他思路来保证输出尺寸不会太小?可能有人会想减少池化层,理论上可行,但是这样做会改变原来的网络结构,不能用就模型的参数来fine-tune了。Deeplab使用了一个非常优雅的做法:将pooling的stride改为1再加上1 padding。这样池化后的图片尺寸并没有减少,并且依然保留了池化整合特征的特性。但是,池化层变了,后面的卷积的感受野也对应改变了,这样也不能进行fine-tune。所以Deeplab提出了一种新的带孔的卷积(Dilated/Atrous Convolution)能够保证这样的池化后的感受野不变,从而可以fine-tune,同时也能保证输出的结果更加精准。
–原理:实际上就是普通的卷积核中间插入了几个洞,运算跟普通卷积保持一样,好处是感受野更大(比如3x3卷积的视野是3x3,插入一个洞后的视野是5x5)。视野变大的作用是特征图缩小到同样数倍的情况下可以掌握更多图像的全局信息,这在语义分割中很重要。
参考:各种卷积演示:
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
2.2.9 Mash R-CNN
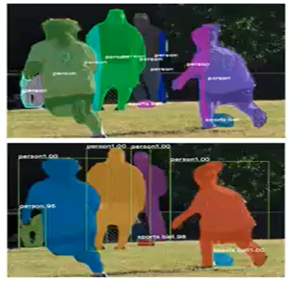

1)检测与分割:
–新增一个分支输出mash.
语义分割(单相素多分类)=框检测(box,多分类)+框内的普通分割(二分类mash)
符合人眼直觉,先整块粗分再细化形状。
2)ROIAlign解决Misalignment(不重合)的问题:
2-1)Faster R-CNN中的RoiPooling是将输入图像中任意一块区域对应到神经网络特征图中的对应区域。它使用了化整的近似来寻找对应区域,导致对应关系与实际情况有偏移。这个偏移再分类任务中可以容忍的,但对于精细度更高的分割则影响较大。(ROIPooling展示https://github.com/deepsense-ai/roi-pooling)
2-2)为了解决这个问题,ROiAlign不再使用化整操作,而是使用线性插值来寻找更精准的对应区域。效果就是可以得到更好地对应,实验也证明了效果的不错。
3)Loss Function
3-1)分类+回归+mash损失
3-2)mash分支和其他的分类分支一样,使用全卷积网络,输出了k类的mash(注意这里mash的输出使用了sigmoid函数,通过与阈值0.5作比较,输出二值mash),这样避免了类间的竞争每个类别都专门生成了本类的mash。
小结:图片处理方面的常用的深度学习算法都大概介绍一下(但是,内在含义还没有理解)。
2.3 实战基于图片分割的车道线检测(深度学习方式)
LaneNet
1)主要特点:
1-1)实例分割来检测车道线
1-2)更灵活的透视变换:
–一般将图像透视变换到鸟瞰图,可以进一步优化车道线,固定的透视变换矩阵遇到上下坡就不行了,因此作者提出用CNN学习透视变换
–输入RGB图像+分割结果->H-Network->输出透视变换参数
2)材料准备:
论文:Towords End-to-End Lane Detection:an Instance Segmentation Approach
参考:https://maybeshewill-cv.github.io/lanenet-lane-detection/
代码:https://github.com/andylei77/lanenet-lane-detection
3)实战折腾大致内容:
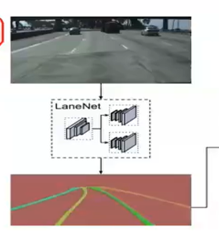
4)实战中一些关键点分析:

4-1)实例分割检测车道线:
a、语义分割:分割出所有车道线。二分类问题
b、生成像素embeding:生成每个像素的n维嵌入,使得同一车道线的嵌入距离近,不同车道的嵌入距离远
c、聚类出具体是哪条车道线:利用分割分支的二值分割图做掩码在Pixel embedding图像上得到所有车道像素的n维度嵌入,将车道像素的嵌入(蓝点)聚类得到所属类别。
d、先粗分再细分。回顾之前,语义分割=检测+普通分割
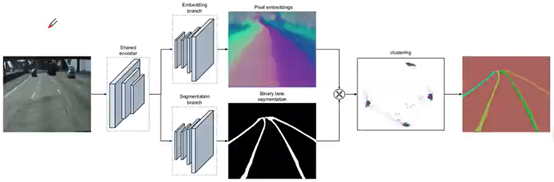
这里的 实例分割=语义分割+聚类
4-2)如何区分车道1,2,3,4?通过聚类思想,同一车道线的点很近,不同车道线的点很远,从而区别出不同车道。
3 课后答疑环节
1)案例里面使用的数据集是图森的;然后,模型也是已经训练好的
2)数据集制作:采集+人工标注
一般情况拿公开数据来跑训练足够了
3)车道线识别,传统的方法相对深度学习方法快一些;因为深度学习需要硬件加速,而且也更模型有关系。(小模型较快,但是精度较低)
4)工业界检测车道一般使用lanenet吗?不一定,这里举例子是因为,其对初学者比较友好
5)车道线标注工具,有很多开源的,可以在GitHub找到
6)车道线检测方式文档汇总:https://github.com/amusi/awesome-lane-detection
7)本节课,内容很大。有基础的,把里面涉及的论文里面的概念细节补一补;没基础的,把实战的代码看懂,基本就能干活
8)算法工程师的核心竞争力,就是将学术界的成果转为工业应用的能力大小
9)针对岗位来训练自己的能力,才能更好进入对应的岗位
10)算法工程师不一定要求编程能力很秀,但是,算法结构需要理解
个人总结:本节课,就感知基础-图像处理展开,以车道线识别为例,介绍了传统的方法,重点介绍了深度学习的方法,主要介绍相关算法的基本思路(论文体现),然后给出一个实战模型。这节课,涉及很多论文,如果有哪个小伙伴有需要,没法下载到的,可以私聊我哈。
#####################
不积硅步,无以至千里
好记性不如烂笔头
图片版权归原作者所有
感恩授课老师的付出















 5533
5533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









