







1、环境设置:
此环节将加载实现笔记本无缝功能的基本模块,包括NumPy、Pandas和TensorFlow等库。此外,它还建立了关键的环境常数,如图像尺寸和学习率,这对后续分析和模型训练至关重要。
# General
import os
import keras
import numpy as np
import pandas as pd
import tensorflow as tf
# Data
import plotly.express as px
import matplotlib.pyplot as plt
# Data Preprocessing
import tensorflow.data as tfds
from sklearn.model_selection import train_test_split
# Model
from keras.applications import VGG16
from keras.applications import Xception, InceptionV3
from keras.applications import ResNet50V2, ResNet152V2
from keras.applications import MobileNetV3Small, MobileNetV3Large
# Model training
from keras import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten, GlobalAveragePooling2D
from keras.layers import InputLayer
# Model Callbacks
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint# Setting constants for reproducibility
np.random.seed(42)
tf.random.set_seed(42)
# Constants
BATCH_SIZE = 32
IMAGE_SIZE = 2242、加载和处理UTKFace数据集
在Kaggle上发现的UTKFace数据集是一个全面的面部图像集合,专门用于年龄和性别识别任务。它包括2万多张人脸图像,并附有年龄、性别和种族的注释。这些图像是多样化的,代表了不同的种族、年龄和性别,使其成为机器学习和计算机视觉研究的广泛而有价值的资源。
UTKFace数据集中的每张图像都标有人的年龄,范围从0到116岁,以及他们的性别,分类为男性或女性。
此外,数据集还包括有关个人种族的信息,允许进行更细致的分析和应用。
研究人员和开发人员经常利用该数据集来训练和测试面部识别技术中年龄估计、性别分类和其他相关任务的算法。它的大尺寸和多样化的面部特征表示使其成为探索和开发计算机视觉领域模型的热门选择。
# Initialize the directory path
dir_path = "/kaggle/input/utkface-new/UTKFace/"
image_paths = os.listdir(dir_path)
# Initialize a Gender Mapping
gender_mapping = ["Male", "Female"]
# Choose and load an image randomly
rand_image_path = np.random.choice(image_paths)
rand_image = plt.imread(dir_path + rand_image_path)/255.
sample_age, sample_gender, *_ = rand_image_path.split("_")
print(f"Total number of images : {len(image_paths)}")
print(f"Sample Image path : {rand_image_path}")
print(f"Sample Age : {sample_age}")
print(f"Sample Gender : {gender_mapping[int(sample_gender)]}\n")
# Show the image
plt.figure(figsize = (5,5))
plt.title("Sample Image")
plt.imshow(rand_image)
plt.axis("off")
plt.show()结果: Total number of images : 23708 Sample Image path : 1_0_3_20161220222642427.jpg.chip.jpg Sample Age : 1 Sample Gender : Male
处理23,708张图像需要使用诸如批处理或使用图像生成器之类的内存高效策略来避免压倒性的内存限制。此外,描绘年龄和性别的图像路径结构(第一部分表示年龄,第二部分表示性别(0表示男性,1表示女性))为后续分析和分类提供了重要信息。
仔细管理这些路径将有助于根据年龄和性别属性进行有针对性的数据处理。
# Initialize a male counter variable
male_count = 0
# Initialize variable to store all the ages.
ages = []
# Loop over the paths and check for male images.
for path in image_paths:
path_split = path.split("_")
if "0" == path_split[1]:
male_count += 1
ages.append(int(path_split[0]))
# Computee total female counts
female_count = len(image_paths) - male_count
# Visualizing The Class Imbalance
pie_chart = px.pie(
names = gender_mapping,
values = [male_count, female_count],
hole = 0.4,
title = "Gender Distribution (Donut Chart)",
height = 500
)
pie_chart.show()
bar_graph = px.bar(
y = gender_mapping,
x = [male_count, female_count],
title = "Gender Distribution (Bar Graph)",
color = gender_mapping,
height = 500
)
bar_graph.update_layout(
yaxis_title = "Gender",
xaxis_title = "Frequency Count"
)
bar_graph.show()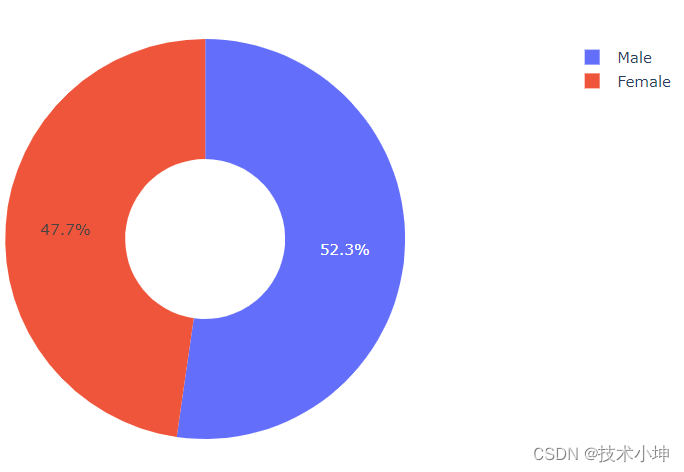
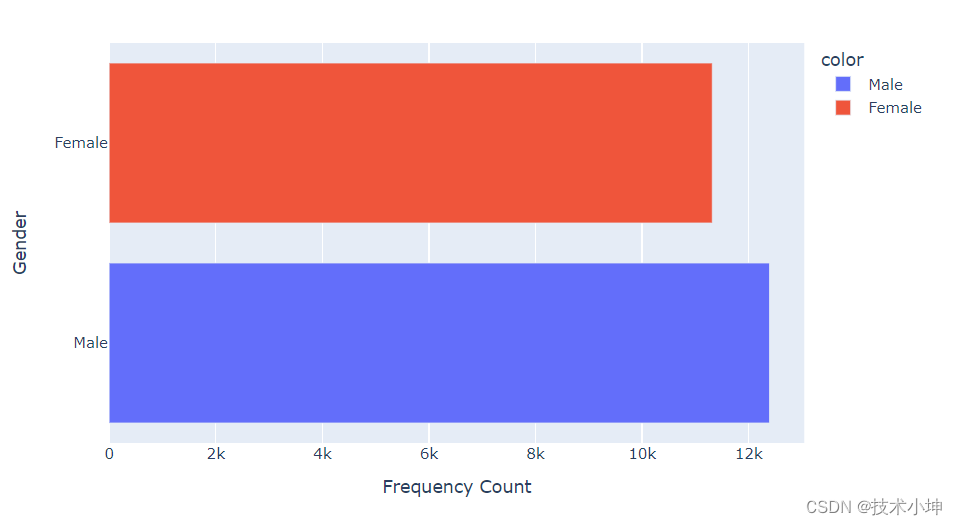
我们的数据集似乎显示出轻微的类别不平衡,男性图像的数量高于女性图像——大约52%的男性和48%的女性代表。虽然这种不平衡不足以显著影响模型的准确性,但值得注意的是,要全面了解数据集对男性图像的偏见。管理这种轻微的偏差可以提高模型的稳健性和预测的公平性,尽管它目前对准确性的影响可能有限。
# Histogram
fig = px.histogram(sorted(ages), title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
yaxis_title = "Value Counts"
)
fig.show()
# Violin Plot
fig = px.violin(x = sorted(ages), title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
yaxis_title = "Distribution"
)
fig.show()
# Box Plot
fig = px.box(x = sorted(ages), notched=True, title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
)
fig.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









