







【深蓝C++】【第3章】【知识点汇总】
0 前言
- 环境是ubuntu18.06
- IDE是clion
1 从初始化和赋值语句谈起
- 初始化/赋值语句是程序中最基本的操作,其功能是将某个值与一个对象关联起来
- 值:字面值、对象(变量或常量)所表示的值…
- 标识符:变量、常量、引用…
- 初始化基本操作
在内存中开辟空间(在栈上或在堆上),保存相应的数值
在编译器种构造符号表,将标识符与相关内存空间关联起来 - 值与对象都有类型
- 初始化/赋值可能涉及到类型转换
2 类型详述
2.1 类型详述1
- 类型是一个编译器的概念,可执行文件中不存在类型的概念
- C++是强类型语言
- 引入类型是为了更好地描述程序,防止误用
- 类型描述了:
- 存储所需要的尺寸(sizeof,标准并没有严格限制)
如下:
#include <iostream>
int main()
{
int x = 10;
char y = 'a';
std::cout << sizeof(x) << '\n';
std::cout << sizeof(int) << '\n';
std::cout << sizeof(y) << '\n';
std::cout << sizeof(char) << '\n';
}
输出:
4
4
1
1
4或者1在不同的编译环境中可能有不同的结果
1 byte -> 8 bit 256
- 取值空间(std::numeric_limits,超过范围可能产生溢出)
如下:
#include <iostream>
#include <limits>
int main()
{
std::cout << std::numeric_limits<unsigned int>::min() << std::endl;
std::cout << std::numeric_limits<unsigned int>::max() << std::endl;
unsigned int x = std::numeric_limits<unsigned int>::max();
x = x + 1;
std::cout << x << std::endl;
}
输出:
0
4294967295
0
- 对齐信息(alignof)
- CPU从内存中读取数据时,要经过一个coherency,内存中首先读取到coherency中,再到CPU中,CPU写数据也是先写道coherency中,再到内存中
- coherency在读写的时候,coherency_line为单位,coherency_line是有大小的,其可以在系统中查,在linux终端中使用
cat coherency_line_size查询;如果查询的结果是64,就是说以64个字节来读写coherency,不会分开来读,如果数据被分割,就要多读一次,分开来读- C/C++是一个性能方面的语言,从各个方面提升数据的性能,怎么样放置这样的数据,这也是一个值得考量的地方,放置不好,数据传输过程中比较慢,定义一个类型,基本就是定义一个类型的对齐信息
- int占4个字节,那么它的对齐信息就是4
- 查询相应数据的对其信息如下,且因为有对齐信息,系统有时候和想的会不一样
#include <iostream>
#include <limits>
//8000-8007 所以8个字节
struct str
{
//8000-8000 1个字节
char b;
//8004-8007 4个字节
int x;
};
int main()
{
//8000-8003
//8000-8064
//假设数据存储在7999-8002
int x = 10;
//首先读取8000-8064
//发现数据补全,读取8000-64 - 7999
//查询int类型的对齐信息
std::cout << alignof(int) << std::endl;
//查询结构体的大小
std::cout << sizeof(str) << std::endl;
}
输出:
4
8
- 可以执行的操作
基本可以进行±*/
2.2 类型详述2
- 类型可以划分为基本类型与复杂类型
- 基本(内建)类型:C++语言中所支持的类型
- 数值类型
1.1 字符类型(char、wchar_t、char16_t、char32_t)
1.2 整数类型
1.2.1 带符号整数类型:short,int,long,long long;其不同的环境下大小不同
1.2.2 无符号整数类型:unsigned+带符号整数类型(后面可以省略,默认为int)
1.3 浮点类型
float、double、long double
2. void
-
复杂类型:由基本类型组合、变种所产生的类型,可能是标准库引入(如vector),或自定义类型
-
与类型相关的标准未定义部分
- char是否有符号
在不同的系统中有不同的结果
可以使用unsigned char和signed char指定 - 整数中内存中的保存方式:大端(big Endian) 小端(Little Endian)
- 每种类型的大小(间接影响取值范围)
灵活变动:好处是提高了硬件的处理能力;坏处是影响程序的可移植性
C++11中引入了固定尺寸的整数模型,如int32_t
2.3 类型详述-字面值及其类型
- 字面值:在程序中直接表示为一个具体数值或字符串数值
- 每个字面值都有其类型
- 整数字面值:20(十进制);024(八进制);0x14/0X14(十六进制)–int型
- 浮点数:1.3;1e8 --double型
- 字符字面值:‘c’;‘\n’;‘\x4d’ --char型
- 字符串字面值:”Hello“ --char[6]型
这里之所以是6个字符,是因为C语言隐式的规定,如果写一个字符串的话,会在后面隐式的加一个‘\0’,用来表示字符串的结束
- 布尔字面值:true,false --bool型
true、false一定是小写的
- 指针字面值:nullptr --nullptr_t型
- 可以为字面值引入前缀或后缀以改变其类型
- 1.3(double) – 1.3f(float)
- 2(int) --2ULL(unsigned long long)
- 可以引入自定义后缀来修改字面值类型
通常不会这样用,但要知道
如下:
#include <iostream>
int operator "" _ddd(long double x)
{
return (int)x * 2;
}
int main()
{
int x = 3.14_ddd;
std::cout << x << '\n';
}
输出为:
6
2.4 类型详述——变量及其类型
- 变量:对应了一段存储空间,可以改变其中内容
- 变量的类型在其首次声明(定义)时指定:
- int x :定义了一个变量x,其类型为int
- 变量声明与定义的区别:extern前缀
如下:
main.cpp下:
#include <iostream>
//引入外部的定义
extern int g_x;//如果在这里赋值操作,那么就会从引用变成定义,从而报错重复定义
int main()
{
std::cout << g_x << std::endl;
}
source.cpp下:
int g_x;
输出为:
0
- 变量的初始化与赋值
- 初始化:在构造变量之处为其赋予的初始值
1.1 缺省初始化
局部变量初始值为任意值
全局变量或线程相关的变量初始值为0
对于指针也是一样
1.2 直接/拷贝初始化
拷贝初始化
int x=10;
直接初始化int x(10);和int x{10};
两者有区别,但在这里没有过多的说
1.3 其他初始化
- 赋值:修改变量所保存的数值
2.5 类型详述——(隐式)类型转换
- 为变量赋值时可能涉及到类型转换
- bool与整数之间的转换
- 浮点数与整数之间的类型转换
- 隐式类型转换不只发生在赋值时
-
if判断
-
数值比较
2.1 无符号数据与带符号数据之间的比较
C++在有符号数和无符号数之间进行默认类型转换的时候,一定是有符号数转换为无符号数
如下:
#include <iostream>
int main()
{
int x = -1;
unsigned int y = 3;
std::cout << (x < y) << std::endl;
}
输出为哦;
0
2.2 std::cmp_XXX (C++20)
- 可以避免2.1中的问题
- 使用该函数可以进行不同数据类型的数据之间的比较,其结果是符号数学上的定义的
3 复合类型:从指针到引用
3.1 复合类型:从指针到引用
- 指针:一种间接类型
- 特点
- 可以“指向”不同的对象
- 具有相同的尺寸
大部分都是8,变量的地址是一个数值,最大有多少,现在的机器都是64位机,也就是CPU总线长度是64个字节,一次性可以处理64个字节,内存最大就是2的64次方;那么保存地址的信息,在64位机就需要64个bit来保存地址信息;无论地址是指向int还是char,内部保存的都是地址信息,都需要64个bit,一个字节8个bit,所以为8个字节;若32位机,那么就是4
- 相关操作
- & - 取地址操作符
通常会把取地址操作赋予一个指针,指针可以保留相应的地址
取地址操作的对象必须是有地址的,不可&42
- * - 解引用操作符
如果是缺省初始化,对于局部指针解引用,会是随机的,对全局指针解引用,是一个0地址,0地址非常特殊,不能对其进行解引用
声明指针的时候往往要赋予一个初始值
可以直接int *p = 0;或者int *p = NULL;或者int *p = nullptr
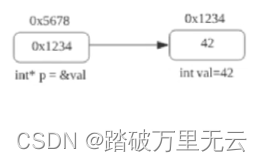
- 指针的定义
int *p = &val;int *p = nullptr;
- 关于nullptr
- 一个特殊的对象(类型为nullptr_t),表示空指针
nullptr是一个指针,其可以隐式的转换为任何一个指针
- 类似于C中的NULL,但更加安全
- 指针与bool的隐式转换:非空指针可以转换为true;空指针可以转换为false
- 指针的只要操作:解引用;增加、减少;判段是否相等 等
如下:
#include <iostream>
int main()
{
int x = 42;
int * p = &x;
std::cout << p << std::endl;
p = p + 1;
std::cout << p << std::endl;
p = p - 2;
std::cout << p << std::endl;
}
输出为:
00BEFB54
00BEFB58
00BEFB50
如果两个指针指向的不是数组的东西,那么不能对两个指针做><的判断,这种是非常危险的,虽然虽然运行,因为每次运行分配的地址都是不确定的,对于大小判断是没有道理的,这是指在堆里声明的指针
但是如果按照下面的程序书写,那么指针的大小就是稳定的,因为是在栈里分配的,有一个先后顺序的过程,后声明的地址大小永远小于先声明的地址大小:
#include <iostream>
int main()
{
int x = 42;
int * q = &x;
int y;
int* r = &y;
std::cout << (r > q) << '\n';
}
输出为:
0
- void* 指针
- 没有记录对象的尺寸信息,可以保存任意地址
在极特殊情况下,我们可能会定义一个接口,这些接口不需要关注指针的具体类型,只需要知道它是一个指针就可以了
void* 是一种特殊的指针,其可以转换为任意类型的指针,也可以由任意类型的指针转换为void*
其中内部就已经丧失了很多的信息,可能会作为一个占位符,保存指针的信息
指针一定要进行初始化
如下:
#include <iostream>
void fun(void * param)
{}
int main()
{
int* r = nullptr;
char* k = nullptr;
fun(r);
fun(k);
}
- 支持判等操作,不可以对其进行加减
#include <iostream>
void fun(void * param)
{
//下述语句会报错
//std::cout << (param + 1) << std::endl;
}
int main()
{
int* r = nullptr;
char* k = nullptr;
fun(r);
fun(k);
std::cout << r << std::endl;
std::cout << r + 1 << std::endl;
fun(r);
}
-
指针的指针

-
指针 VS 对象
- 指针复制成本低,读写成本高
指针是对对象的间接引用,间接引用可以减少程序的传输所付出的成本,特别自定义的对象大小是非常打的,基本上复制的话成本非常高
引用的复制成本低,但是读写成本高
- 指针的问题
- 可以为空
- 地址信息可能非法
- 解决方案:引用
- 引用
int &ref = val;
#include <iostream>
int main()
{
int x = 3;
int& ref = x;
std::cout << "x = " << x << "; ref = " << ref << std::endl;
int* ptr = &x;
std::cout << "*ptr = "<<*ptr << std::endl;
}
输出为:
x = 3; ref = 3
*ptr = 3
- 引用是对象的别名,不能绑定字面值
可以交叉使用对象和其引用,对引用修改等价于对本体修改
并且其不可以绑定到数字这种字面值
如下:
#include <iostream>
int main()
{
int x = 3;
int& ref = x;
std::cout << ref << std::endl;
ref = ref + 1;
std::cout << x << '\n';
}
输出为:
3
4
- 构造时绑定对象,在其生命周期内不能绑定其他对象(赋值操作会改变对象内容)
如下:
#include <iostream>
int main()
{
int x = 3;
int& ref = x;
int* ptr = &x;
int y = 0;
*ptr = y;//改变了ptr所指向对象的内容值
ptr = &y;//改变了ptr本身的内容
int z = 1;
ref = z;//相当于把z的值赋予了x
//不可以做到再把ref绑定到非x
//引用只有在初始化/构造的时候绑定到一个初始对象
//如果初始化引用的时候就没有把其绑定,那么之后也不能对其进行绑定,所以定义引用未初始化赋值会报错
}
- 不存在空引用,但可能存在非法引用——总的来说比指针安全
下面这个例程是非法引用的例程:
#include <iostream>
int& fun()
{
int x;
return x;
//相当于
/*
int x;
int& ref = x;
return ref;
*/
}
int main()
{
int& ref = fun();//由于变量生命周期的存在,
//所以这个引用相当于指向了一个已经销毁的对象
//所以说这是一个非法引用,虽然不会报错
}
- 属于编译器概念,在底层还是通过指针实现
- 指针的引用
- 指针是对象,因此可以定义引用,引用的引用是不存在的
对指针定义引用如下:
#include <iostream>
int main()
{
int x = 3;
int* ptr = &x;
int*& ref = ptr;//定义了一个指针的引用
std::cout << *ref << std::endl;//为3
}
- int *p = &val; int * ref = p;
- 类型信息从左向右解析
4 常量与常量表达式类型
4.1 常量与变量相对,表示不可修改的对象
- 使用const声明常量对象,const放在int前后都可以
- 是编译器概念,编译器利用其
- 防止非法操作
- 优化程序逻辑
4.2 常量指针与顶层常量(top-level const)
const int* p;和int const * p;//顶层常量/指针常量,指针指向的是常量,不能改变其值int* const p;//底层指针/常量指针,指向的地址不能修改const int* const p;- 常量指针可指向变量
#include <iostream>
int main()
{
int x = 4;
&x; //int* --> const int*
const int* ptr = &x;
//const int* -不能->const int*
/*
const int y = 3;
int* ptr = &x;
*/
//const int* --> const int*
const int z = 3;
const int* ptr_z = &z;
}
4.3 常量引用(也可绑定常量)
const int&
//常量引用的基本用法如下:
#include <iostream>
int main()
{
//相当于增加了限制
int x = 3;
const int& ref = x;
//下面相当于放松了限制,会报错
/*
const int y = 4;
int& ref = y;
*/
}
- 可读不可写
- 主要用于函数形参
- 可以绑定字面值
#include <iostream>
void fun(const int& param)
{
}
int main()
{
//引用绑定到3的值
int x = 3;
int& refx = x;
//引用不可以直接绑定到字面值,下面这个是报错的
/*
int y = 3;
int& refy = 3;
*/
//但是常量引用可以直接绑定到字面值,下面这个是合法的
int z = 3;
const int& refz = 3;
//之所以要这样,因为常量引用常作为函数形参,要保证下面的可以
fun(x);
fun(refx);
fun(3);//相当于把fun中的形参param与3绑定起来
}
4.4 常量表达式(从C++11开始)
- 常量可以作为接受输入
#include <iostream>
int main()
{
int x;
std::cin >> x;
//可以运行
const int y1 = x;
const int y2 = 3;
//但y1和y2有本质的区别
//y1的值在运行期确定
//y2的值编译器确定
if (y1 == 3)
{
//在编译的时候编译器会将其编译为汇编语言,等待输入然后判断是否执行
}
if (y2 == 3)
{
//在编译期就决定了是否要执行,然后编译器就可以判断是否引入优化,提高性能
}
}
- 使用constexpr声明
- 声明的是编译器常量
#include <iostream>
int main()
{
int x;
std::cin >> x;
//constexpr int y1 = x;//此式报错,因为这个值只可以在运行期确定
const int y1 = x;
//const int y2 = 3;//这个还有有一些办法可以修改其值的
constexpr int y2 = 3;//区别在于此式更明确的向编译器表示这就是一个编译器常量为3
//编译器可以踏踏实实的用来进行后续的优化
//使用constexpr修饰后,就完完全全的不能修改了
if (y1 == 3)
{
//在编译的时候编译器会将其编译为汇编语言,等待输入然后判断是否执行
}
if (y2 == 3)
{
}
}
- 编译器可以利用其进行优化
#include <iostream>
int main()
{
constexpr int y2 = 3;
//y2的类型不是constexpr int
// constexpr更像是一个限定符,不是类型符
// y2 的类型还是 const int,但不仅仅是这个类型,还在编译器就确定了
}
- 常量表达式指针:constexpr位于* 左侧,但表示指针是常量表达式
注意constexpr不是一个类型符,其更像是一个限定符
#include <iostream>
#include <type_traits>
int main()
{
constexpr int y2 = 3;
//表示ptr是一个常量
//ptr的类型是 const int* const
constexpr const int* ptr = nullptr;
//判断两个类型是否相同,此处相同返回1
std::cout << std::is_same_v<decltype(ptr), const int* const> << std::endl;
constexpr const char* ptr2 = "123";
}
5 类型别名与类型的自动推导
5.1 可以为类型引用别名,从而引用特殊的含义或便于使用(如:size_t)
size_t 是一个无符号整型,可以表示任意尺寸的对象
要根据具体的硬件环境确定 size_t 如何实现
硬件环境32位机,数据最大尺寸就是2的32次方,超过2的32次方没法表示,32位机上一个int是4个字节,可以用unsigned int表示任意长度的对象;这个时候就会尝试把size_t定义为unsigned int
如果是64位机,表示任意长度的对象,假设在该系统中int还是4位的,long是8位的,则可以把unsigned long定义为size_t
针对不同的系统,size_t是不同系统的别名
使用size_t代码是可以在不同系统里移植的
5.2 两种引入类型别名的方式
typedef int MyInt;
#include <iostream>
typedef int MyInt;
int main()
{
MyInt x = 3;
}
using MyInt = int;(从C++11开始)
5.3 使用using引入类型别名更好
typedef char MyCharArr[4];using MyCharArr = char[4];
5.4 类型别名与指针、引用的关系
- 应将指针类型别名视为一个整体,在此基础上引入常量表示指针为常量的类型
#include <iostream>
using IntPtr = int*;
int main()
{
int x = 3;
//int* const ptr = &x;
const IntPtr ptr = &x;
*ptr = 4;
}
- 不能通过类型别名构造引用的引用
C++不允许通过类型别名构造引用的引用
#include <iostream>
#include <type_traits>
using RefInt = int&;
using RefRefInt = RefInt&;
int main()
{
std::cout << std::is_same_v<RefInt, RefRefInt> << std::endl;
}
输出位:
1
5.5 类型的自动推导
- 从C++11开始,可以通过初始化表达式自动推导对象类型
使用auto,必须是变量表达式
也就是auto x;
- 自动推导类型并不意味着弱化类型,对象还是强类型
python就是弱类型,变量不需要指定类型
- 自动推导的 几种常见形式
- auto:最常用的形式,但会产生类型退化
演示如下:
#include <iostream>
#include <type_traits>
int main()
{
int x1 = 3;
int& ref = x1;
//int& -> int
int y = ref;//ref作为右值,就会从int&类型退化为int类型
//auto会产生类型退化
//int& -> int
auto ref2 = ref;//此时ref2的类型是int
std::cout << std::is_same_v<decltype(ref2), int&> << std::endl;
}
输出位:
0
- const auto/constexpr auto:推导出的是常量/常量表达式类型
#include <iostream>
#include <type_traits>
int main()
{
const auto x = 3;
std::cout << std::is_same_v<decltype(x), const int> << std::endl;
constexpr auto y = 3;
std::cout << std::is_same_v<decltype(y), const int> << std::endl;
}
输出:
1
1
- auto&:推导出引用类型,避免类型退化
#include <iostream>
#include <type_traits>
int main()
{
// int -> const int&
const auto& z = 3;
std::cout << std::is_same_v<decltype(z), const int&> << std::endl;
// const int -> int
const int x1 = 3;
auto y1 = x1;
std::cout << std::is_same_v<decltype(y1), int> << std::endl;
//const int -> const int&
const int x2 = 3;
auto& y2 = x2;
std::cout << std::is_same_v<decltype(y2), const int&> << std::endl;
// const int& -> const int&
const int& x3 = 3;
auto& y3 = x3;
std::cout << std::is_same_v<decltype(y3), const int&> << std::endl;
}
输出:
1
1
1
1
自动推导数组如下:
#include <iostream>
#include <type_traits>
int main()
{
//数组的类型自动推导
int x4[3] = { 1,2,3 };
auto x5 = x4;
std::cout << std::is_same_v<decltype(x5), int*> << std::endl;
//数组的类型自动推导
int x6[3] = { 1,2,3 };
auto& x7 = x6;
std::cout << std::is_same_v<decltype(x7), int(&)[3]> << std::endl;
}
输出:
1
1
使用auto&的缺点,为什么使用decltype
#include <iostream>
#include <type_traits>
int main()
{
int x = 3;
const int y1 = x;
//为了使用aoto避免类型退化使用&,不是百分百可靠
auto& y2 = y1;
decltype(y1) y3 = y1;
//这里auto使用auto&,反而将其多赋予了引用的类型
std::cout << std::is_same_v<decltype(y2), const int> << std::endl;
std::cout << std::is_same_v<decltype(y3), const int> << std::endl;
}
输出
0
1
- decltype(exp):返回exp表达式的类型(左值加引用)
#include <iostream>
#include <type_traits>
int main()
{
int x = 3;
int* ptr = &x;
/*
*ptr是一个左值表达式
ptr -> int*
*ptr -> int
decltype(*ptr) -> int&
//x是一个变量名称,不会加&
decltype(x)
*/
std::cout << std::is_same_v<decltype(*ptr), int&> << std::endl;
}
输出为:
1
- decltype(val):返回val的类型
当然,如果左值是一个变量名称,不用加&
#include <iostream>
#include <type_traits>
int main()
{
int x = 3;
int* ptr = &x;
(x) = 5;
const int y1 = 3;
const int& y2 = y1;
std::cout << std::is_same_v<decltype(3.5 + 15l), double> << std::endl;
std::cout << std::is_same_v<decltype(*ptr), int&> << std::endl;
std::cout << std::is_same_v<decltype(ptr), int*> << std::endl;
std::cout << std::is_same_v<decltype(x), int> << std::endl;
//x是一个变量名称;(x)是一个表达式
std::cout << std::is_same_v<decltype((x)), int&> << std::endl;
std::cout << std::is_same_v<decltype(y1), const int> << std::endl;
std::cout << std::is_same_v<decltype(y2), const int&> << std::endl;
std::cout << std::is_same_v<decltype((y1)), const int&> << std::endl;
//不存在引用的引用,所以还是引用
std::cout << std::is_same_v<decltype((y2)), const int&> << std::endl;
}
输出:
1
1
1
1
1
1
1
1
1
- decltype(auto):从C++14开始支持,简化decltype使用
#include <iostream>
#include <type_traits>
int main()
{
//这种写法特别啰嗦
decltype(3.5 + 15l) x = 3.5 + 15l;
//简便写法,等价于上面
decltype(auto) x = 3.5 + 15l;
}
- concept auto:从C++20开始支持,表示一系列类型(std:integral auto x =3;)
6 域与对象的生命周期
- 域(scope)表示了程序中的一部分,其中的名称有唯一的含义
- 全局域(global scope):程序最外围的域,其中定义的是全局对象
- 块域(block scope),使用大括号所限定的域,其中定义的是局部变量
- 还存在其他的域:类域,名字空间域…
- 域可以嵌套,嵌套域中定义的名称可以隐藏外部域中定义的名称
- 对象的生命周期起始于被初始化的时刻,终止于被销毁的时刻
- 通常来说
- 全局对象的生命周期是整个程序的运行期间
- 局部对象的生命周期起源于对象的初始化位置,终止于所在域被执行完成
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









