







- 问题引入
- 现在的生成模型由于显存的限制,无法生成大于1024分辨率的图像,问题根结于当前推理的时候需要将整张图片都加载;
- 为什么每次都需要加载整张图片,以Unet架构为例,两个相邻的block在计算的时候都相互依赖,是双向的attention;
- 方法
- Unidirectional Block Attention (UniBA) algorithm:
– 将图片划分为 B × B B\times B B×B个block,例如输入图片是 x ∈ R H × W × C x\in\mathbb{R}^{H\times W\times C} x∈RH×W×C,那么划分之后变为 x b ∈ R h × w × B 2 × C x_b\in\mathbb{R}^{h\times w\times B^2\times C} xb∈Rh×w×B2×C,之前的方法进行卷积或者attention操作的之后都是不同的block之间相互依赖,本文提出的方法就是使attention变成单向依赖的;
– 每一个block的计算只依赖于自己本身,左边,上边和左上四个block的值,attention的计算变为:其中 z ( i , j ) n z^n_{(i,j)} z(i,j)n是指 i i i行 j j j列的hidden states, P i P_i Pi是block-level的相对位置编码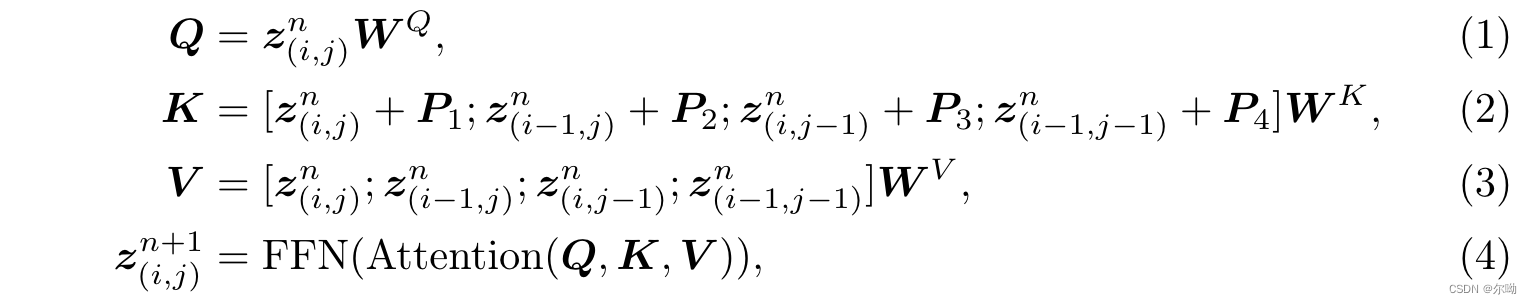
– 虽然本文的方法每一个block的计算依赖的范围变小了,但是由于特征逐层传递,还是可以捕捉到长距离的信息;
– 空间复杂度由原来的 O ( N 2 ) O(N^2) O(N2)变为 O ( N ) O(N) O(N):随着block计算的向前推进,不断有block的hidden states的值被丢弃,注意和自回归式模型的区别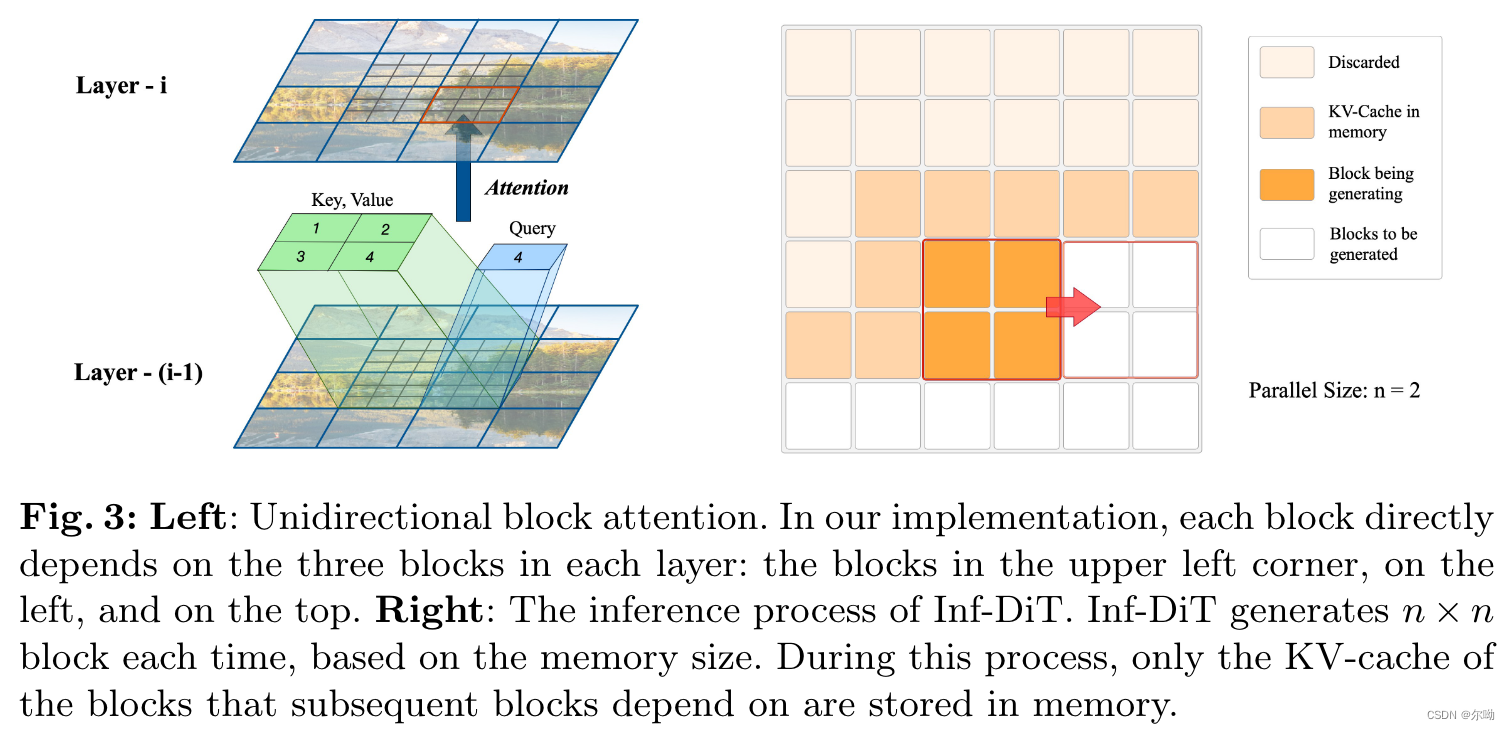
- image upsampling diffusion model
– 模型结构如下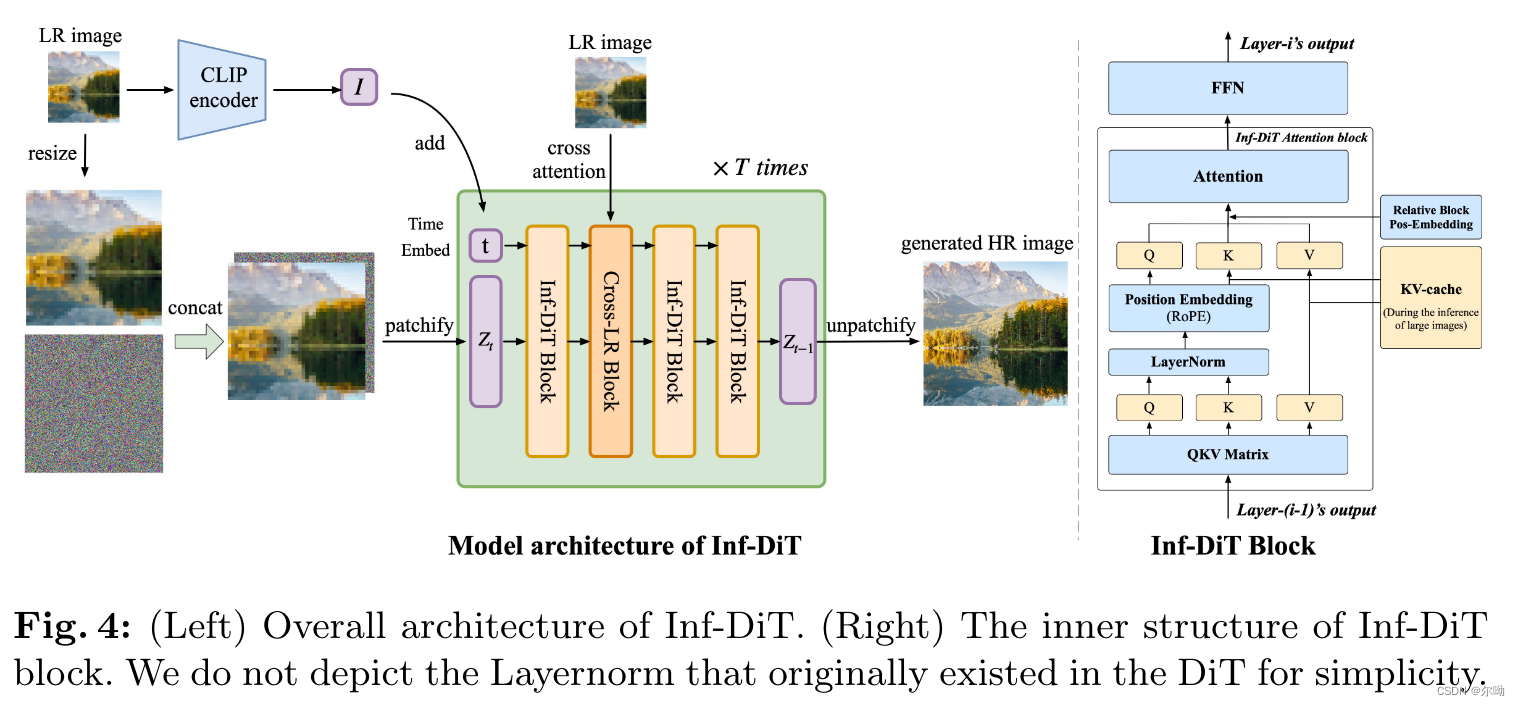
– 考虑到color shift和detail loss模型在RGB像素空间进行操作,而不是latent space;此外假设超分scale为f,你们首先将输入上采样f倍和噪声concat到一起作为模型的输入;
– 使用相对位置编码RoPE; - 全局和局部的一致性:
– 全局一致性:使用CLIP来提取LR的语义信息,和time embedding相加,这样训练还使得模型可以使用文本来进行生成的控制;
– 局部的一致性:当前块之和相邻的三个块进行交互,所以会导致不同的block之间生成存在差异,不连续,所以本文还加入了Nearby LR Cross Attention;
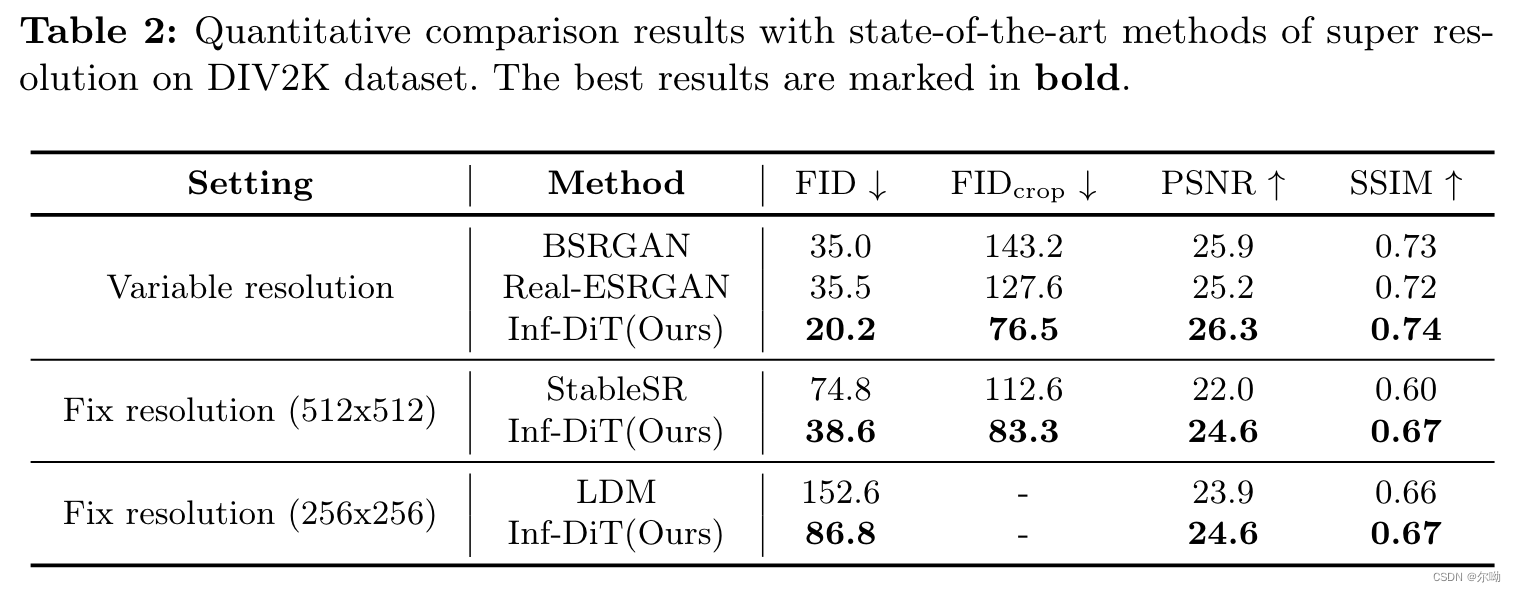
- 实验














 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









