









R笔记:全子集回归 | 最优子集筛选 AIC 最优子集筛选(Best Subset Selection)
一统浆糊 2021-05-05 18:58
变量筛选中常用方法解释
R语言| 16. 预测模型变量筛选: 代码篇 (qq.com)
在进行多因素回归(多重线性回归、logistic回归、Cox回归等)时,为了得到简洁有效的模型,我们会做变量筛选(模型选择)。根据专业进行变量的筛选才是王道,统计学检验只是辅助验证你的专业结论。我们不提倡把一堆变量放进软件由软件来筛选预测变量,但也不能因此否定统计筛选的作用。常用的统计学方法筛选方法有逐步回归(向前法、后退法、向前后退混合法)以及全子集回归(All-Subsets Regression,All Possible Regression)。全子集回归可以对所有预测变量的可能组合模型都拟合一下,然后根据某标准(如R2、校正的R2、MSE、Cp、AIC、SBIC等)筛选出现有变量条件下的最佳模型,又叫最优子集筛选(Best Subset Selection)。有些教程把最优子集定义为从含相同自变量的个数的所有模型中挑选出最佳的模型组合,比如ABCD四个自变量,可以有2^4=16个模型,其中常数项模型1个,含1个自变量的模型4个(A、B、C、D),含2个自变量的模型6个(AB、AC、AD、BC、BD、CD),含3个自变量的模型4个(ABC、ABD、ACD、BCD),含4个自变量的模型1个(ABCD),分别从含有1、2、3、4个自变量的模型中挑选出最佳的一个模型就可以组成最优子集。
R中能实现最优子集回归的函数有很多,R Site Search[http://finzi.psych.upenn.edu/search.html]可以直接搜索相关函数,你会搜到很多,比如bestglm {bestglm}、lmSubsets {lmSubsets}、leaps {leaps}/regsubsets {leaps}、bess {BeSS}、bestsubset {StepReg}、ols_step_all_possible{olsrr}、ols_step_best_subset{olsrr}。
回归与判定标准
逐步回归,模型判定:AIC,值越小模型越优;
全子集回归,模型判定,调整R²,值越大模型越优,BIC和CP值越小越好;
Lasso回归+交叉验证:模型判定,MSE,具体见下文。
示例:<<因变量二分类资料的Probit回归>>中的数据。
【1-3】数据导入>>数据初步考察与处理>>拟合多重线性回归模型
library(haven)
lmdata<-read_sav("D:/Temp/logistic_step.sav")
lmdata$race<-factor(lmdata$race)
lmdata$smoke<-factor(lmdata$smoke)
lmdata$ptl <-ifelse(lmdata$ptl>0,1, 0)
lmdata$ptl<-factor(lmdata$ptl)
lmdata$ht<-factor(lmdata$ht)
lmdata$ui<-factor(lmdata$ui)
lmfit<- lm(bwt~age+lwt+race+smoke+ptl+ht+ui+ftv,data=lmdata)
【6】变量筛选
全子集回归
本例有8个自变量,全子集回归将会包含255个模型(不含常数项模型,2^8-1=255)及其R2、校正的R2、Cp。
library(olsrr)
ols_step_all_possible(lmfit)
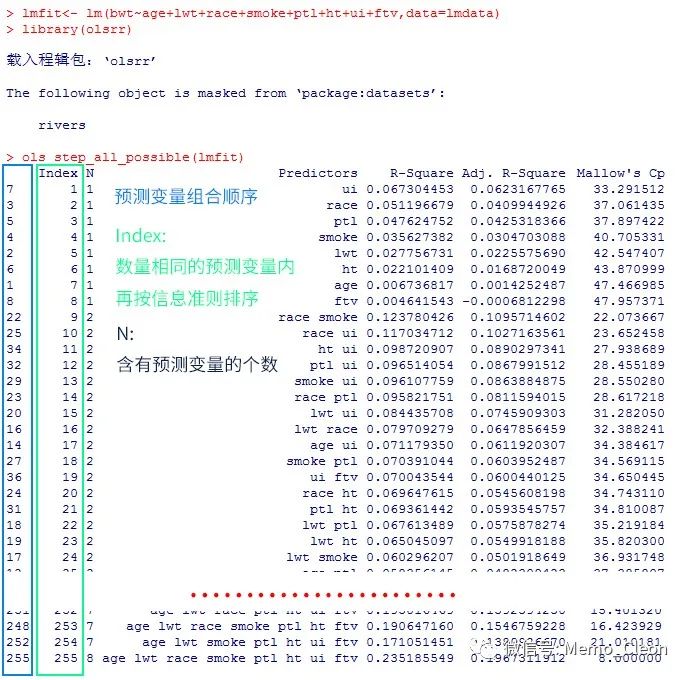
第一列是预测因子的组合顺序,我们建立了模型lmfit<- lm(bwt~age+lwt+race+smoke+ptl+ht+ui+ftv,data=lmdata),age是第1个因子(组合),ftv是第8个因子(组合),age+lwt是第9个组合。
第3列(N)是模型含有预测变量的个数,第2列(Index)是先按第3列升序排列后,自变量相同个数的模型中在按照信息准则的大小进行排列,在plot作图中用于标识模型。在进行模型比较时,R^2、校正的R^2越大,Cp值越小模型越佳。
本例涉及模型较多,为更直观的显示结果,我们可以使用图示进行结果显示。
plot(ols_step_all_possible(lmfit))
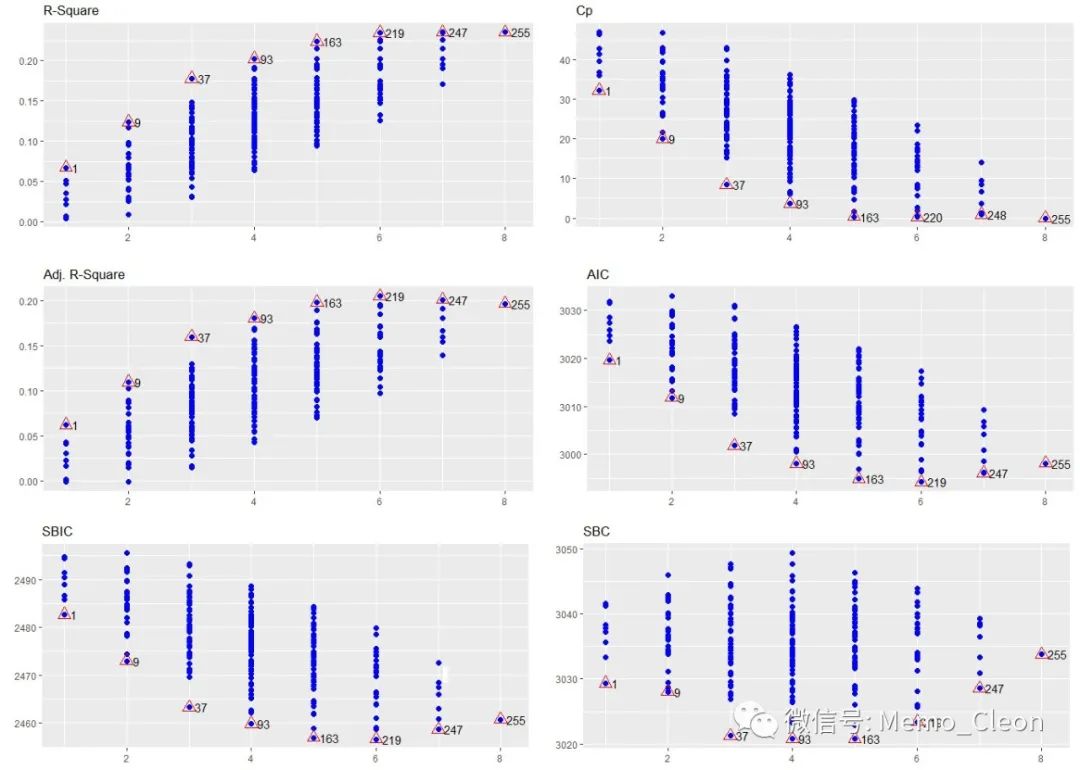
图示法采用4个指标(R2、校正R2、Cp、AIC、SBIC及SBC)。不同的评估指标筛选的最优模型会存在差异。结果显示,根据不同的评估指标,最优模型可能存在差异,基本上集中在纳入4-6个变量时,图示中评估指标值相近的的模型可以结合标识在ols_step_all_possible的结果中确定。
当然我们也可以直接使用最优子集回归。
最优子集回归
ols_step_best_subset(lmfit)

结果显示在预测变量个数一定时的最优模型,同时各种信息准则也表明在自变量6个时模型最佳。
plot(ols_step_best_subset(lmfit))
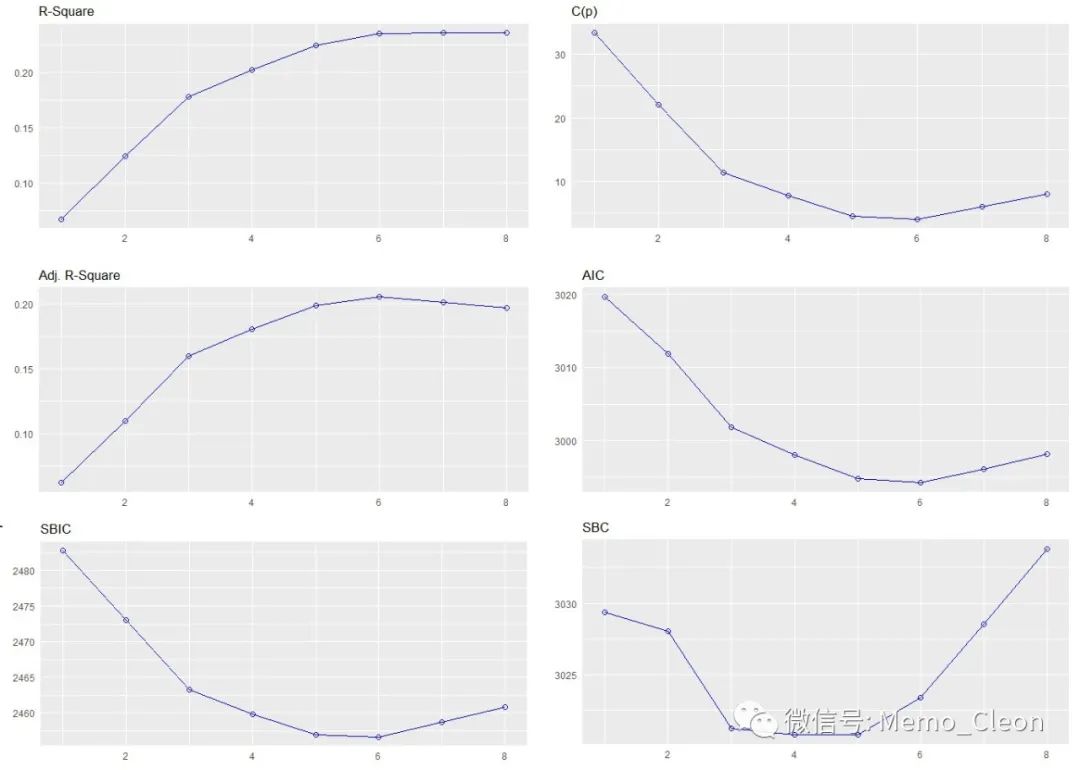
函数并没有直接给出模型的参数估计值,可以借助回归模型求得。
lmfitbm<- lm(bwt~lwt+race+smoke+ptl+ht+ui,data=lmdata)
summary(lmfitbm)

ols_step_all_possible{olsrr}、ols_step_best_subset{olsrr}可以寻找多重线性回归的最优子集。函数bestglm {bestglm}适用面更广,不仅多重线性回归,logistic回归、Poisson回归等都可以实现。以确定logistic回归的最优子集为例演示如下,示例仍以<<因变量二分类资料的Probit回归>>中的数据,结局指标为是否为低体重新生儿(low)
bestglm(Xy, family = gaussian, IC = "BIC", t = "default", CVArgs = "default", qLevel = 0.99, TopModels = 5, method = "exhaustive", intercept = TRUE, weights = NULL, nvmax = "default", RequireFullEnumerationQ = FALSE, ...)
library(haven)
lmdata<-read_sav("D:/Temp/logistic_step.sav") ##导入spss数据
lgtdata<-lmdata[c("age","lwt","race","smoke","ptl","ht","ui","ftv","low")] ##结局变量需要在最后一列
lgtdata<-as.data.frame(as.matrix(lgtdata)) ##将数据指定为矩阵后在转换为数据框
lgtdata$race<-factor(lgtdata$race)
lgtdata$smoke<-factor(lgtdata$smoke)
lgtdata$ptl <-ifelse(lgtdata$ptl>0,1, 0)
lgtdata$ptl<-factor(lgtdata$ptl)
lgtdata$ht<-factor(lgtdata$ht)
lgtdata$ui<-factor(lgtdata$ui)
library(bestglm)
library(leaps)
bestglm(lgtdata, IC="AIC", family=binomial) ##Information criteria to use: "AIC", "BIC", "BICg", "BICq", "LOOCV", "CV". Family to use: binomial(link = "logit"),gaussian(link = "identity"),Gamma(link = "inverse"),inverse.gaussian(link = "1/mu^2"),poisson(link = "log"),quasi(link = "identity", variance = "constant"),quasibinomial(link = "logit"),quasipoisson(link = "log")
lgtdata2<-lmdata[c("age","lwt","race","smoke","ptl","ht","ui","ftv","low")]
lgtdata2<-as.data.frame(as.matrix(lgtdata2))
bestglm(lgtdata2, IC="AIC", family=binomial)

结果有几点需要说明:
(1)预测变量存在因子变量时结果将以方差分析表的形式输出,预测变量全部为连续变量结果以参数估计表的形式输出,OR=exp(β)。本例只是为了演示输出格式,最后直接将race作为连续变量纳入模型实际操作是不合适的。二分类变量赋值0和1时,不论以因子变量纳入还是直接以连续变量纳入结果是一致的,因此如果想获得含有因子变量的参数估计值,除了直接使用筛选到的预测变量进行logistic回归外,还可以考虑将多分类变量设为哑变量,然后全部以连续变量纳入分析。
library(haven)
lmdata<-read_sav("D:/Temp/logistic_step.sav")
lmdata$race<-factor(lmdata$race)
library(misty)
raced<-dummy.c(lmdata$race, ref= 1, names = "race_d") ##将race设置为哑变量,哑变量名称为race_d+数字
m<-cbind(lmdata,raced) ##新生成的数据框m,包含了lmdata和raced的数据
lgtdata<-m[c("age","lwt","race_d2","race_d3","smoke","ptl","ht","ui","ftv","low")]
lgtdata<-as.data.frame(as.matrix(lgtdata))
library(bestglm)
library(leaps)
bestglm(lgtdata, IC="AIC", family=binomial)
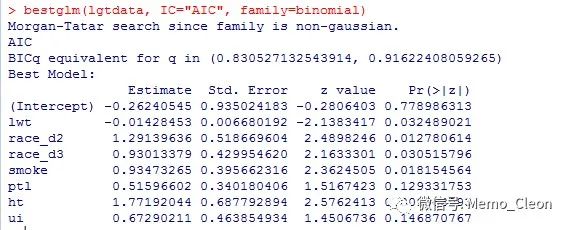
(2)不同信息准则获得的最终模型可能不同。AIC和BIC的比较可参见
https://www.jianshu.com/p/4c8cf5df2092。【AIC=2k-2ln(L),要求模型的误差服从独立正态分布。其中k是所拟合模型中参数的数量,L是对数似然值,n是观测值数目。k小意味着模型简洁,L大意味着模型精确,AIC评价模型兼顾了简洁性和精确性。BIC=-2 ln(L) + ln(n)*k,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。AIC和BIC的原理不同,AIC是从预测角度,选择一个好的模型用来预测,BIC是从拟合角度,选择一个对现有数据拟合最好的模型,从贝叶斯因子的解释来讲就是边际似然最大的那个模型。】
bestglm{bestglm}使用参考文件:bestglm:Best Subset GLM。
http://www.doc88.com/p-3347597662869.html



















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











