







C/C++常见面试题
- c++
- 变量的声明和定义有什么区别
- 前置声明
- 简述#ifdef、#else、#endif和#ifndef的作用
- 写出int 、bool、 float 、指针变量与 “零值”比较的if 语句
- 结构体可以直接赋值吗
- sizeof 和strlen 的区别
- C语言的关键字 static 和 C++的关键字 static 有什么区别
- C语言的 malloc 和 C++中的 new 有什么区别
- 为什么Free不需要指定大小?
- delete[]不需要指定大小?
- 写一个 “标准”宏MIN
- ++i和i++的区别
- volatile有什么作用
- 一个参数可以既是const又是volatile吗
- *a和&a有什么区别
- 指针与引用的区别
- 函数传指针还是传引用?
- 用C 编写一个死循环程序
- 结构体内存对齐问题
- 全局变量和局部变量有什么区别?实怎么实现的?操作系统和编译器是怎么知道的?
- 简述C、C++程序编译的内存分配情况
- 什么const在常量区(符号表优化),什么const在栈区
- 简述strcpy、sprintf 与memcpy 的区别
- typedef 和define 有什么区别
- 指针常量与常量指针区别
- 简述队列和栈的异同
- 设置地址为0x67a9 的整型变量的值为0xaa66
- 编码实现字符串转化为整数
- C语言的结构体和C++的类有什么区别
- C++中struct和class的区别
- 如何避免“野指针”
- 内存泄露
- 句柄和指针的区别和联系是什么?
- 说一说extern“C”
- C++中类成员的访问权限
- 什么是右值,什么是左值?
- 什么是左值引用,什么是右值引用?
- 为什么要有移动构造函数和移动赋值构造函数?
- std::move()
- forward函数
- 通用引用
- 完美转发
- 面向对象的三大特征
- 说一说c++中四种cast转换
- C++的空类有哪些成员函数
- 对c++中的smart pointer四个智能指针:shared_ptr,unique_ptr,weak_ptr,auto_ptr的理解
- shared_ptr线程安全吗?
- unique_ptr有没有赋值和拷贝构造函数?
- 谈谈你对拷贝构造函数和赋值运算符的认识
- 在C++中,使用new申请的内存能否用free?使用malloc申请的内存能否通过delete释放?
- 用C++设计一个不能被继承的类
- 虚继承
- C++自己实现一个String类
- 访问基类的私有虚函数
- 对虚函数和多态的理解
- 多重继承,多个父类都存在虚函数,有几个虚指针?
- 多重继承+菱形继承虚表存放?
- C++类的虚函数表和虚函数在内存中的位置
- 为什么析构函数要声明为虚函数
- 为什么构造函数不能声明为虚函数
- 为什么构造函数和析构函数中不要调用虚函数
- 简述类成员函数的重写、重载和隐藏的区别
- const成员函数可以重载吗?
- 链表和数组有什么区别
- vector的底层原理
- vector扩容为什么是1.5倍或2倍?
- vector中的reserve和resize的区别
- vector中的size和capacity的区别
- vector中erase方法与algorithn中的remove方法区别
- vector迭代器失效的情况
- 下列代码的运行结果
- 正确释放vector的内存(clear(), swap(), shrink_to_fit())
- list的底层原理
- 什么情况下用vector,什么情况下用list,什么情况下用deque
- priority_queue的底层原理
- map 、set、multiset、multimap的底层原理
- 为何map和set的插入删除效率比其他序列容器高
- 为何map和set每次Insert之后,以前保存的iterator不会失效?
- 当数据元素增多时(从10000到20000),map的set的查找速度会怎样变化?
- map 、set、multiset、multimap的特点
- 为何map和set的插入删除效率比其他序列容器高,而且每次insert之后,以前保存的iterator不会失效?
- 为何map和set不能像vector一样有个reserve函数来预分配数据?
- set的底层实现实现为什么不用哈希表而使用红黑树?
- hash_map与map的区别?什么时候用hash_map,什么时候用map?
- 迭代器失效的问题
- STL线程不安全的情况
- lambda表达式
- lambda表达式如何实现
- 什么样的函数可以抛出异常?构造函数可不可以抛出异常?
- 如何限制对象只能在栈上?如何限制对象只能在堆上?
- C++中#的用法,##的用法
- C++中调用虚函数和普通函数的开销一样吗?
- 程序的编译和运行过程中编译器做了什么?
- 运行PE文件后发生了什么?
- C++模板的优点和缺点
- 静态库(.a或.lib)和动态库(.so或.dll)的区别?
- C++实现单例的方法?哪个是线程安全的?
- 内联函数?
- 编译型语言和解释型语言的区别?
- 为什么不要以多态的方式处理数组?
- 缺乏默认构造函数的限制?
- 非必要不提供默认构造函数
- 图形学
- 渲染管线
- 几何着色器作用
- 设置渲染状态是什么意思?
- 调用Draw Call
- 顶点着色器主要的作用
- 双缓冲作用
- CPU、图形API、显卡驱动和GPU之间的关系
- CPU和GPU如何并行工作?
- 为什么Draw Call多了会影响帧率?
- 如何减少Draw Call?
- MRT,多渲染目标
- 阴影实现(shadow map)
- 阴影映射纹理的获取
- 屏幕空间的阴影映射技术
- 软阴影与硬阴影的区别
- 知道屏幕上的ui的2d坐标知道深度的情况下推算世界坐标
- 非线性深度与线性深度
- 通过非线性深度反算线性深度
- z-fighting
- 绕世界坐标系中某一物体自身的y轴旋转一定角度,旋转矩阵如何推导
- NDC(归一化的设备坐标)
- PBR
- 离线渲染和实时渲染的区别
- 纹理太小(多个像素映射到同一个纹素)
- mipmap(纹理太大的问题)
- LOD
- 微表面模型
- 为什么使用齐次坐标?
- 如何在Shader中采样,如何获取二维纹理中的具体像素值?
- mipmap的实现,如何确定使用哪一层?
- 如何渲染光照
- 透明效果的实现
- 渲染顺序
- 抗锯齿算法
- sinx实现(泰勒展开)
- 如何均匀采样一个圆?
- 如何均匀采样一个球?
- 如何均匀采样一个球面?
- 向量叉乘的几何意义?
- 矩阵旋转
- 欧拉角
- 四元数
- 万向锁问题
- UE4
- UE4AsyncLoading异步加载实现方式
- 垃圾回收GC
- 被纳入自动GC管理的条件
- 一个UObject不会被GC的条件
- 手动清理一个UObject
- 垃圾回收GC发生的时机
- 垃圾回收GC过程
- 簇和增量清除
- UE4反射的实现方式
- UHT,UBT
- UObject
- Actor
- UActorComponent
- APawn
- Controller
- 哪些数据应该放在PlayerState中?
- Player,PlayerController,PlayerState
- Actor,Pawn,Controller,Ainfo继承关系
- UE4中tick函数中DeltaTime是什么?
- USceneComponent
- 为何ActorComponent不能互相嵌套?而在SceneComponent一级才提供嵌套?
- ULevel架构图
- UWorld
- 为什么要有PersistentLevel?
- WorldContext
- 为什么要在Level里保存Actors,而不是把所有Map的Actors配置都生成在World一个总Actors里?
- GameInstance
- UEngine
- GameMode与PlayerController和GameInstance比较
- GameState
- UE4网络同步
- 中介转发
- 帧同步与状态同步
- RPC
- UE4中的服务器与客户端
- UE4中的服务器与客户端连接过程
- 骨骼动画
- 骨骼动画制作
- 插值方法
- 线性混合蒙皮
- 正向动力学
- 姿态调整
- CCD(循环坐标下降算法)
- CAA(圆形对齐算法)
- 一个服务器中有个tick函数,每次固定加1/30秒,不考虑帧率波动会出现问题吗?
- 顶点动画的缺陷
- 操作系统
- 用户态和内核态
- 用户态线程
- 内核态线程
- 用户态线程与内核态线程间的映射关系
- 用户态切换到内核态(系统调用)
- 进程和线程基本概念
- 进程状态与切换
- 线程从运行态到阻塞态,操作系统做了什么?
- 进程与线程的区别?
- 同一个进程下的不同线程,栈和堆是公有还是私有?
- 并发和并行的区别
- 死锁是什么?
- 产生死锁的四个必要条件?
- 死锁预防
- 死锁避免
- 死锁检测
- 死锁解除
- 同步与互斥
- 临界区、信号量、互斥量
- 互斥量(锁)的种类
- lock_guard
- unique_lock
- 条件变量
- 为防止两个进程同时进入临界区,同步机制应当遵循的准则
- 实现临界区互斥访问的方法
- 原子操作
- 线程池
- 生产者消费者问题
- 为什么使用虚拟内存?
- 地址变换逻辑
- 页面置换算法
- 改进型CLOCK算法优于简单CLOCK算法的地方
- 虚拟地址翻译为物理地址过程
- 内存分配管理方式
- 数据结构
- 计算机网络
- 设计模式
- 数据库
c++
变量的声明和定义有什么区别
变量的定义为变量分配地址和存储空间,变量的声明不分配地址。一个变量可以在多个地方声明,但是只在一个地方定义。加入extern修饰的是变量的声明,说明此变量将在文件以外或在文件后面部分定义。说明:很多时候一个变量,只是声明不分配内存空间,直到具体使用时才初始化,分配内存空间,如外部变量。
- 注意:声明的最终目的是为了提前使用,即在定义之前使用,如果不需要提前使用就没有单独声明的必要,变量是如此,函数也是如此,所以声明不会分配存储空间,只有定义时才会分配存储空间。
- 用static来声明一个变量的作用:
1)对于局部变量用static声明,则是为该变量分配的空间在整个程序的执行期内都始终存在。
2)外部变量用static来声明,则该变量的作用只限于本文件模块。
- 示例:
int main()
{
extern int A;
//这是个声明而不是定义,声明A是一个已经定义了的外部变量
//注意:声明外部变量时可以把变量类型去掉如:extern A;
dosth(); //执行函数
}
int A; //是定义,定义了A为整型的外部变量
前置声明
在.h文件中用class 声明代替include头文件
前置声明要求:
1.其声明的类是文件所声明的类的数据成员时,是指针成员或引用成员(而不是对象成员);
2.其声明的类是文件所声明的类的成员函数的参数或返回值时,该函数在文件中不存在定义。
为什么使用前置声明?
- 当两个类相互包含头文件时无法通过编译。(必须使用)
- 有助于分离类的声明和定义文件。(只在.cpp文件中include.h文件)(按照个人风格)
- 节省编译时间。(修改某个头文件后需要编译多个无关的依赖文件)(按照需求)前置声明隐藏了依赖关系,头文件改动时,用户的代码会跳过必要的重新编译过程。
- 对于C++类而言,如果它的头文件变了,那么所有这个类的对象所在的文件都要重编,但如果它的实现文件(cpp文件)变了,而头文件没有变(对外的接口不变),那么所有这个类的对象所在的文件都不会因之而重编。
大神链接
简述#ifdef、#else、#endif和#ifndef的作用
利用#ifdef、#endif将某程序功能模块包括进去,以向特定用户提供该功能。在不需要时用户可轻易将其屏蔽。
#ifdef MATH
#include "math.c"
#endif
在子程序前加上标记,以便于追踪和调试。
#include <stdio.h>
#define CONFIG_DEBUG
int main(){
FILE *fp;
fp=fopen("D:\\DEV\\test.txt","r");
if(NULL==fp){
printf("error!");
}
#ifdef CONFIG_DEBUG
printf("open test.txt ok");
#endif
return 0;
}
应对硬件的限制。由于一些具体应用环境的硬件不一样,限于条件,本地缺乏这种设备,只能绕过硬件,直接写出预期结果。
注意:虽然不用条件编译命令而直接用if语句也能达到要求,但那样做目标程序长((因为所有语句都编译),运行时间长(因为在程序运行时间对if语句进行测试)。而采用条件编译,可以减少被编译的语句,从而减少目标程序的长度,减少运行时间。
写出int 、bool、 float 、指针变量与 “零值”比较的if 语句
//int与零值比较
if ( n == 0 )
if ( n != 0 )
//bool与零值比较
if (flag) // 表示flag为真
if (!flag) // 表示flag为假
//float与零值比较
const float EPSINON = 0.00001;
if ((x >= - EPSINON) && (x <= EPSINON) //EPSINON是允许的误差(即精度)
//指针变量与零值比较
if (p == NULL)
if (p != NULL)
结构体可以直接赋值吗
声明时可以直接初始化,同一结构体的不同对象之间也可以直接赋值,但是当结构体中含有指针“成员”时一定要小心。注意:当有多个指针指向同一段内存时,某个指针释放这段内存可能会导致其他指针的非法操作。因此在释放前―定要确保其他指针不再使用这段内存空间。
sizeof 和strlen 的区别
1、sizeof是一个操作符,strlen是库函数。
2、sizeof的参数可以是数据的类型,也可以是变量,而strlen只能以结尾为‘\0’的字符串作参数。
3、编译器在编译时就计算出了sizeof的结果,而strlen函数必须在运行时才能计算出来。并且sizeof计算的是数据类型占内存的大小,而strlen计算的是字符串实际的长度。
4、数组做sizeof的参数不退化,传递给strlen就退化为指针了
C语言的关键字 static 和 C++的关键字 static 有什么区别
C语言中static关键字的作用:
1.修饰变量:变量又分为全局变量和局部变量。
(1).修饰全局变量
作用域仅限于变量被定义的文件中,其他文件即使用extern 声明也没法使用此变量。
(2).修饰局部变量
在函数内定义的局部变量被修饰,可以延长变量的生命周期,但是作用域不变。
2.修饰函数
和修饰全局变量的效果类似,表明函数的作用域仅限于被定义的文件中,不必担心与其它文件中的函数同名。
C++兼容C语言,所以static在C语言中的用法,在C++中同样适用。除此之外,C++中的static关键字还有以下作用:
1.修饰类的数据成员
经过static关键字修饰的数据成员就成为了静态数据成员,不属于任何一个对象,而是经过此类定义的所有对象共有此静态数据成员。但是静态数据成员必须得在类外进行初始化。优点是可以实现信息隐藏,访问权限设为private,全局变量做不到这一点。
2.修饰类的成员函数
经过static关键字修饰的成员函数就成了静态成员函数,不属于任何一个对象,而是属于类的方法,所以静态成员函数没有隐含的this指针,不能被const所修饰,在调用时可以通过类名和作用域限定符的方式调用,也可以通过对象进行调用。
注意:
1、static成员函数可以调用static数据成员。
2、static成员函数不可以调用非static数据成员。
3、static成员函数可以调用static成员函数。
4、static成员函数不可以调用非static成员函数。
5、非static成员函数可以调用static成员函数。
C语言的 malloc 和 C++中的 new 有什么区别
- new 、delete是操作符,可以重载,只能在C++中使用。malloc、free是函数,可以覆盖,C、C++中都可以使用。
- new可以调用对象的构造函数,对应的delete调用相应的析构函数。malloc仅仅分配内存,free 仅仅回收内存,并不执行构造和析构函数。
- new 、delete返回的是某种数据类型指针,malloc、free返回的是void 指针。
- new能自动计算需要分配的内存空间,而malloc需要手工计算字节数。
- 注意:
malloc申请的内存空间要用free释放,而new申请的内存空间要用delete释放,不要混用。
delete和free被调用后,内存不会立即回收,指针也不会指向空,delete或free仅仅是告诉操作系统,这一块内存被释放了,可以用作其他用途。但是由于没有重新对这块内存进行写操作,所以内存中的变量数值并没有发生变化,出现野指针的情况。因此,释放完内存后,应该先该指针指向NULL。
为什么Free不需要指定大小?
大神链接
当调用malloc(size)时,实际分配的内存大小大于size字节,这是因为在分配的内存区域头部有类似于
struct control_block {
unsigned size;
int used;
};
这样的一个结构,如果malloc函数内部得到的内存区域的首地址为void p,那么它返回给你的就是p + sizeof(control_block),而调用free§的时候,该函数把p减去sizeof(control_block)即向前偏移一段,然后就可以根据((control_blcok)p)->size得到要释放的内存区域的大小。这也就是为什么free只能用来释放malloc分配的内存,如果用于释放其他的内存,会发生未知的错误。
delete[]不需要指定大小?
struct array {
size_t count_of_test;
Test t[10];
};
在调用new[]时先通过malloc申请内存多申请一点空间保存count_of_test,然后是返回给用户t空间的例子。这个地址要在malloc获得的array地址上加一个偏移量。最后对这个t空间调用每个元素的构造函数。
调用delete[]的参数实际上是t空间的地址。先对这个地址参数进行减偏移量运算得到array地址并取得count_of_test,然后对t空间调用析构函数count_of_test次。最后以array地址作为参数调用free()函数。
写一个 “标准”宏MIN
# define min(a , b) ((a) < = (b) ? (a) : (b))
++i和i++的区别
++ i 先自增1,再返回,i++先返回i , 再自增1。如果i是基本类型,两个效率基本一致。如果是自定义类型,++i效率,因为++i只需要修改并且返回,i++需要保留原值,再修改,然后再返回原值。
volatile有什么作用
volatile在C++中的作用
1、状态寄存器一类的并行设备硬件寄存器。
2、一个中断服务子程序会访问到的非自动变量。
3、多线程间被几个任务共享的变量。当多个线程共享某一个变量时,该变量的值会被某一个线程更改,应该用 volatile 声明。作用是防止编译器优化把变量从内存装入CPU寄存器中,当一个线程更改变量后,未及时同步到其它线程中导致程序出错。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
注意:虽然volatile在嵌入式方面应用比较多,但是在PC软件的多线程中,volatile修饰的临界变量也是非常实用的。如果一个基本变量被volatile修饰,编译器将不会把它保存到寄存器中,而是每一次都去访问内存中实际保存该变量的位置上。这一点就避免了没有volatile修饰的变量在多线程的读写中所产生的由于编译器优化所导致的灾难性问题。所以多线程中必须要共享的基本变量一定要加上volatile修饰符。
一个参数可以既是const又是volatile吗
可以,用const和volatile同时修饰变量,表示这个变量在程序内部是只读的,不能改变的,只在程序外部条件变化下改变,并且编译器不会优化这个变量。每次使用这个变量时,都要小心地去内存读取这个变量的值,而不是去寄存器读取它的备份。
注意:在此一定要注意const的意思,const只是不允许程序中的代码改变某一变量,其在编译期发挥作用,它并没有实际地禁止某段内存的读写特性。
*a和&a有什么区别
&a :其含义就是“变量a的地址”。
∗
*
∗a : 用在不同的地方,含义不一样 。
在声明语句中,
∗
*
∗a只说明a是一个指针变量,如int
∗
*
∗a;
在其他语句中,
∗
*
∗a前面没有操作数且a是一个指针时,
∗
*
∗a代表指针a指向的地址内存放的数据,如b=
∗
*
∗a;
∗
*
∗a前面有操作数且a是一个普通变量时,a代表乘以a,如c=
b
∗
a
b*a
b∗a。
指针与引用的区别
(1)指针是实体,引用是别名,没有空间。
(2)引用定义时必须初始化,指针不用。
(3)指针可以改,引用不可以。(因此没有int & const a,因为const本来就不可以修改;但是有int const &a,表明不能通过a修改某变量)
(4)引用不能为空,指针可以。
(5)sizeof(引用)计算的是它引用的对象的大小,而sizeof(指针)计算的是指针本身的大小。
(6)不能有NULL引用,引用必须与一块合法的存储单元关联。
(7)给引用赋值修改的是该引用与对象所关联的值,而不是与引用关联的对象。
(8)如果返回的是动态分配的内存或对象,必须使用指针,使用引用会产生内存泄漏。
(9)对引用的操作即是对变量本身的操作。
函数传指针还是传引用?
- 引用只能传实例化后的对象,而指针可以是空指针。
- 传指针操作更自由,传引用更安全。
- 如果在函数中会重新赋值,那么需要穿指针
- 如果需要返回某种能够被当成赋值对象的东西,那么传引用(v[5] = 10;重载[]函数需要返回引用)。
用C 编写一个死循环程序
while(1)
{ }
注意:很多种途径都可实现同一种功能,但是不同的方法时间和空间占用度不同,特别是对于嵌入式软件,处理器速度比较慢,存储空间较小,所以时间和空间优势是选择各种方法的首要考虑条件。
结构体内存对齐问题
原因:
- 效率。内存对齐可以提高存取效率(例如,有些平台每次读都是从偶地址开始,如果一个int型存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并且要对两次读出的结果的高低字节进行拼凑才能得到这32bi的数据)。
- 兼容不同的硬件平台。各个硬件平台对存储空间的处理有很大的不同,一些平台对某些特定类型的数据只能从某些特定地址开始存取,例如,有些架构的CPU在访问一个没有对齐的变量时会发生错误,那么这时候编程必须保证字节对齐
请写出以下代码的输出结果:
#include<stdio.h>
struct S1
{
int i:8;
char j:4;
int a:4;
double b;
};
struct S2
{
int i:8;
char j:4;
double b;
int a:4;
};
struct S3
{
int i;
char j;
double b;
int a;
};
int main()
{
printf("%d\n",sizeof(S1));
printf("%d\n",sizeof(S2);
printf("%d\n",sizeof(S3));
return 0;
}

说明:结构体作为―种复合数据类型,其构成元素既可以是基本数据类型的变量,也可以是一些复合型类型数据。对此,编译器会自动进行成员变量的对齐以提高运算效率。默认情况下,按自然对齐条件分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同,向结构体成员中size最大的成员对齐。许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,而这个k则被称为该数据类型的对齐模数。
对于常见类型大小的说明
//c语言中没有string类型,c++中有,其实具体大小取决于编译器
x86
sizeof(char) 1
sizeof(int) 4
sizeof(unsigned int) 4
sizeof(long) 4
sizeof(unsigned long) 4
sizeof(long long) 8
sizeof(unsigned long long) 8
sizeof(double) 8
sizeof(float) 4
sizeof(string) 28
指针都为4字节
x64
sizeof(char) 1
sizeof(int) 4
sizeof(double) 8
sizeof(float) 4
sizeof(string) 40
指针都为8字节
指针的大小只与操作系统有关
#pragma pack (2) // 强制以 2 的倍数进行对齐,如果long是4字节答案是12,如果是8字节答案是16
struct stu1 {
short a;
int b;
long c;
char d;
};
#pragma pack () // 取消强制对齐,恢复系统默认对齐
全局变量和局部变量有什么区别?实怎么实现的?操作系统和编译器是怎么知道的?
全局变量是整个程序都可访问的变量,谁都可以访问,生存期在整个程序从运行到结束(在程序结束时所占内存释放);
局部变量存在于模块(子程序,函数)中,只有所在模块可以访问,其他模块不可直接访问,模块结束(函数调用完毕),局部变量消失,所占据的内存释放。
操作系统和编译器,可能是通过内存分配的位置来知道的,全局变量分配在全局数据段并且在程序开始运行的时候被加载.局部变量则分配在堆栈里面。
简述C、C++程序编译的内存分配情况
从静态存储区域分配:
内存在程序编译时就已经分配好,这块内存在程序的整个运行期间都存在。速度快、不容易出错,因为有系统会善后。例如全局变量,static变量,常量字符串等。
在栈上分配:
在执行函数时,函数内局部变量的存储单元都在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。大小为2M。
从堆上分配:
即动态内存分配。程序在运行的时候用malloc或new申请任意大小的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活。如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,另外频繁地分配和释放不同大小的堆空间将会产生堆内碎块。
一个C、C++程序编译时内存分为5大存储区:栈区、堆区、全局区、文字常量区、程序代码区


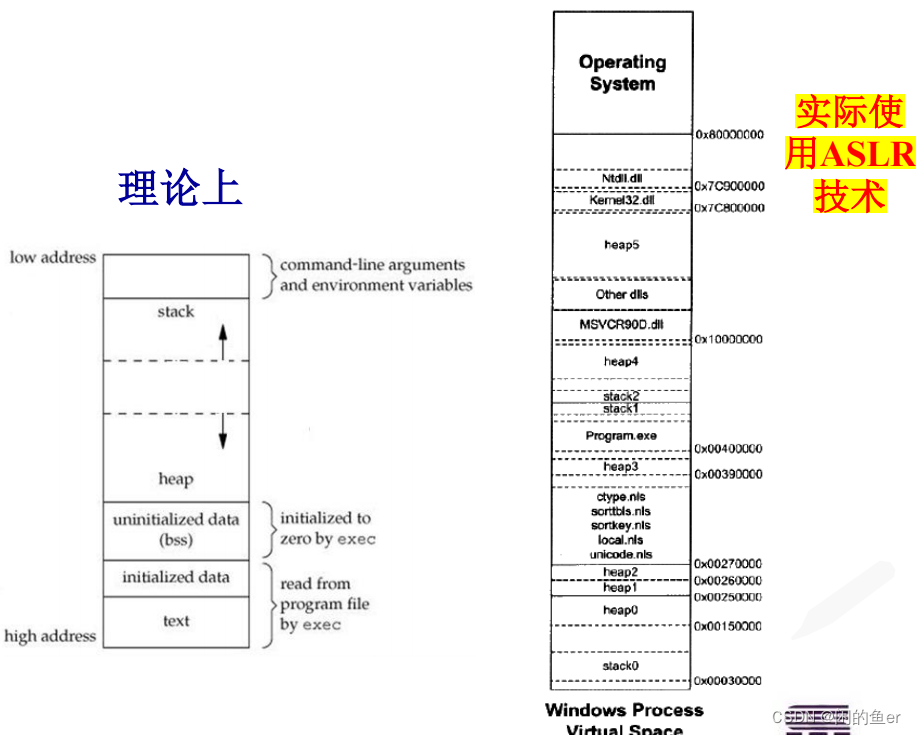
ASLR是一种针对缓冲区溢出的安全保护技术,通过对堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的。
什么const在常量区(符号表优化),什么const在栈区
如果我们可以在编译期确定该常量的值,那么在常量区。constexpr一定在常量区。
如果不能在编译期确认该常量的值,那么在栈区。(例如const int a = b;
)或自定义对象。(或者被取地址、extern)
简述strcpy、sprintf 与memcpy 的区别
操作对象不同,strcpy 的两个操作对象均为字符串,sprintf 的操作源对象可以是多种数据类型, 目的操作对象是字符串,memcpy 的两个对象就是两个任意可操作的内存地址,并不限于何种数据类型。
执行效率不同,memcpy 最高,strcpy 次之,sprintf 的效率最低。
实现功能不同,strcpy 主要实现字符串变量间的拷贝,sprintf 主要实现其他数据类型格式到字符串的转化,memcpy 主要是内存块间的拷贝。
注意 :strcpy、sprintf与memcpy都可以实现拷贝的功能,但是针对的对象不同,根据实际需求,来选择合适的函数实现拷贝功能 。
memmove解决memcpy拷贝出错的问题
/*sprintf用法示例*/
#include <stdio.h>
#include <math.h>
int main()
{
char str[80];
sprintf(str, "Pi 的值 = %f", M_PI);
puts(str);
return(0);
}
/*输出:Pi 的值 = 3.141593*/
typedef 和define 有什么区别
- 用法不同:typedef 用来定义一种数据类型的别名,增强程序的可读性。define 主要用来定义 常量,以及书写复杂使用频繁的宏。
- 执行时间不同:typedef 是编译过程的一部分,有类型检查的功能。define 是宏定义,是预编译的部分,其发生在编译之前,只是简单的进行字符串的替换,不进行类型的检查。
- 作用域不同:typedef 有作用域限定。define 不受作用域约束,只要是在define 声明后的引用 都是正确的。
- 对指针的操作不同:typedef 和define 定义的指针时有很大的区别。
#include <stdio.h>
#define INT_D int*
typedef int* int_p;
int main()
{
printf("hello world\n");
INT_D a,b;//b不是指针,编译报错
int_p c,d;
int num=8;
a=#
b=#
c=#
d=#
return 0;
}
- 注意 :typedef定义是语句,因为句尾要加上分号。而define不是语句,千万不能在句尾加分号。
指针常量与常量指针区别
1.指针常量与常量指针的概念
指针常量=指针本身是常量,换句话说,就是指针里面所存储的内容(内存地址)是常量,不能改变。但是,内存地址所对应的内容是可以通过指针改变的。
常量指针=指向常量的指针,换句话说,就是指针指向的是常量,它指向的内容不能发生改变,不能通过指针来修改它指向的内容。但是,指针自身不是常量,它自身的值可以改变,从而指向另一个常量。
2.指针常量与常量指针的声明
指针常量:数据类型
∗
*
∗ const 指针变量。
常量指针:数据类型 const
∗
*
∗指针变量 或者 const 数据类型
∗
*
∗指针变量。
常量指针常量:数据类型 const
∗
*
∗const 指针变量 或者 const 数据类型
∗
*
∗const 指针变量。
3.例子:
/*指针常量的例子*/
int a,b;
int * const p;
p = &a;//正确
p = &b;//错误
*p = 20;//正确
/*常量指针的例子*/
int a,b;
int const *p;
p = &a;//正确
p = &b;//正确
*p = 20;//错误
简述队列和栈的异同
队列和栈都是线性存储结构,但是两者的插入和删除数据的操作不同,队列是“先进先出”,栈是“后进先出”。
注意:区别栈区和堆区。堆区的存取是“顺序随意”,而栈区是“后进先出”。栈由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。堆一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。分配方式类似于链表。堆区和栈区是程序的不同内存存储区域。
设置地址为0x67a9 的整型变量的值为0xaa66
int *ptr;
ptr = (int *)0x67a9;
*ptr = 0xaa66;
注意:这道题就是强制类型转换的典型例子,无论在什么平台地址长度和整型数据的长度是一样的,即一个整型数据可以强制转换成地址指针类型,只要有意义即可。
编码实现字符串转化为整数
//剑指offer代码
#include<iostream>
using namespace std;
enum Status {KValid=0,KInvalid};
int g_nStatus = KValid;
int StrToIntCore(const char* digit, bool minus)
{
long long num=0;
while (*digit!='\0')
{
if (*digit >= '0'&&*digit <= '9')
{
int flag = minus ? -1 : 1;
num = num * 10 + flag*(*digit - '0');
if ((!minus&&num > 0x7FFFFFFF) || (minus&&num < (signed int)0x80000000))//越界
{
num = 0;
break;
}
*digit++;
}
else//非数字字符
{
num = 0;
break;
}
}
if (*digit == '\0')//转换合法
{
g_nStatus = KValid;
}
return num;
}
int StrToInt(const char* str)
{
g_nStatus = KInvalid;
long long number = 0;
if (str != NULL&&*str!='\0')
{
bool minus = false;//是否为负数
if (*str == '+') str++;
else if (*str == '-')
{
minus = true;
str++;
}
if (*str != '\0')
{
number = StrToIntCore(str, minus);
}
}
return (int)number;
}
int main()
{
const char *str = "-12345";
if (g_nStatus == KValid)
cout << StrToInt(str) << endl;
else
cout << "Invalid" << endl;
return 0;
}
C语言的结构体和C++的类有什么区别
C语言的结构体是不能有函数成员的,而C++的类可以有。
C语言的结构体中数据成员是没有private、public和protected访问限定的。而C++的类的成员有这些访问限定。
C语言的结构体是没有继承关系的,而C++的类却有丰富的继承关系。
注意:虽然C的结构体和C++的类有很大的相似度,但是类是实现面向对象的基础。而结构体只可以简单地理解为类的前身。
C++中struct和class的区别
在C++中, class和struct做类型定义是只有两点区别:
1.默认继承权限不同,class继承默认是private继承,而struct默认是public继承
2.class还可用于定义模板参数,像typename,但是关键字struct不能同于定义模板参数
C++保留struct关键字,原因:
保证与C语言的向下兼容性,C++必须提供―个struct
C++中的struct定义必须百分百地保证与C语言中的struct的向下兼容性,把C++中的最基本的对象单元规定为class而不是struct,就是为了避免各种兼容性要求的限制
对struct定义的扩展使C语言的代码能够更容易的被移植到C++中
如何避免“野指针”
野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)。
指针变量声明时没有被初始化。解决办法:指针声明时初始化,可以是具体的地址值,也可让它指向NULL。
指针p被free或者delete之后,没有置为NULL。解决办法:指针指向的内存空间被释放后指针应该指向NULL
指针操作超越了变量的作用范围。解决办法:在变量的作用域结束前释放掉变量的地址空间并且让指针指向NULL。
函数返回指向局部变量的指针。
内存泄露
内存泄漏 (memory leak) 是指由于疏忽或错误造成了程序未能释放掉不再使用的内存的情况。
- 堆内存指的是程序运行中根据需要分配通过 malloc , new 等从堆上分配的一块内存,再然后必须通过调用 free 和 delete 删掉。如果程序设计错误导致这块内存没有被释放,那么此后这一块内存将不会被使用。
- 系统资源泄露主要指程序使用系统分配的资源比如 Bitmap , handle , socket(使用close()函数释放) 等没有使用相应的函数释放掉,导致系统资源的浪费。
- 没有将析构函数写成虚函数。
句柄和指针的区别和联系是什么?
句柄和指针其实是两个截然不同的概念。Windows系统用句柄标记系统资源,隐藏系统的信息。句柄是个32bit的uint。指针则标记某个物理内存地址,两者是不同的概念 。指针可以直接对内存数据进行操作,而句柄需要通过操作系统来对某些特定的,操作系统允许的数据进行操作。

说一说extern“C”
extern"C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern" C"后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。这个功能十分有用处,因为在C++出现以前,很多代码都是C语言写的,而且很底层的库也是C语言写的,为了更好的支持原来的C代码和已经写好的C语言库,需要在C++中尽可能的支持C,而extern" C"就是其中的一个策略。
使用:
C++代码调用C语言代码
在C++的头文件中使用
在多个人协同开发时,可能有的人比较擅长C语言,而有的人擅长C++,这样的情况下也会有用到
在C++环境下使用C函数的时候,常常会出现编译器无法找到obj模块中的C函数定义,从而导致链接失败的情况,应该如何解决这种情况呢?
答案与分析:
C++语言在编译的时候为了解决函数的多态问题,会将函数名和参数联合起来生成一个中间的函数名称,而C语言则不会,因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,这告诉编译器,请保持我的名称,不要给我生成用于链接的中间函数名。
#ifdef __cplusplus /* 如果采用了C++,如下代码使用C编译器 */
extern "C" { /* 如果没有采用C++,顺序预编译 */
#endif
/* 采用C编译器编译的C语言代码段 */
#ifdef __cplusplus /* 结束使用C编译器 */
}
#endif
C++中类成员的访问权限
C++通过public、 protected、 private三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符。在类的内部(定义类的代码内部),无论成员被声明为public、protected还是private,都是可以互相访问的,没有访问权限的限制。在类的外部(定义类的代码之外),只能通过对象访问成员,并且通过对象只能访问public属性的成员,不能访问private、protected属性的成员
什么是右值,什么是左值?
左值和右值的概念:
左值:能取地址,或者具名对象,表达式结束后依然存在的持久对象;
右值:不能取地址,匿名对象,表达式结束后就不再存在的临时对象;
区别:
左值能寻址,右值不能;左值能赋值,右值不能;
左值可变,右值不能(仅对基础类型适用,用户自定义类型右值引用可以通过成员函数改变);
转载大佬的左右值讲解:非常详细易懂
什么是左值引用,什么是右值引用?
左值引用和右值引用的概念:
左值引用:C++11之前的引用,就是我们常见的变量别名。
右值引用:就是给右值(匿名变量)其了个别名。
左值引用只能绑定左值,右值引用只能绑定右值,如果绑定的不对,编译就会失败。
//转载自上面讲左右值的链接,下面也是。
int&& a = 1; //实质上就是将不具名(匿名)变量取了个别名
int b = 1;
int && c = b; //编译错误! 不能将一个左值复制给一个右值引用
class A {
public:
int a;
};
A getTemp()
{
return A();
}
A && a = getTemp(); //getTemp()的返回值是右值(临时变量),生命周期与a一致
为什么要有移动构造函数和移动赋值构造函数?
在代码中常有调用拷贝构造函数,拷贝的是临时对象,拷贝完就没什么用了,这就造成了没有意义的资源申请和释放操作,如果能够直接使用临时对象已经申请的资源,既能节省资源,又能节省资源申请和释放的时间。而C++11新增加的移动语义就能够做到这一点。
移动构造函数与拷贝构造函数的区别是,拷贝构造的参数是const MyString& str,是常量左值引用,而移动构造的参数是MyString&& str,是右值引用,而MyString(“hello”)是个临时对象,是个右值,优先进入移动构造函数而不是拷贝构造函数。而移动构造函数与拷贝构造不同,它并不是重新分配一块新的空间,将要拷贝的对象复制过来,而是变更了所有权,将自己的指针指向别人的资源,然后将别人的指针修改为nullptr(需要注意的是并不是只有指针需要修改,假设是int&&a,也需要最后把a = 0)。
std::move()
左值,本应当调用拷贝构造函数了,但是有些左值是局部变量,生命周期也很短,能不能也移动而不是拷贝呢?C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语义。
- str6 =std::move(str2),虽然将str2的资源给了str6,但是str2并没有立刻析构,只有在str2离开了自己的作用域的时候才会析构,所以,如果继续使用str2已经转移了所有权的变量,可能会发生意想不到的错误。
- 如果我们没有提供移动构造函数,只提供了拷贝构造函数,std::move()会失效但是不会发生错误,因为编译器找不到移动构造函数就去寻找拷贝构造函数,也这是拷贝构造函数的参数是constT&常量左值引用的原因!
- c++11中的所有容器都实现了move语义,move只是转移了资源的控制权,本质上是将左值强制转化为右值使用,以用于移动拷贝或赋值,避免对含有资源的对象发生无谓的拷贝。move对于拥有如内存、文件句柄等资源的成员的对象有效,如果是一些基本类型,如int和char[10]数组等,如果使用move,仍会发生拷贝(因为没有对应的移动构造函数),所以说move对含有资源的对象说更有意义。
forward函数
不管是T&&、左值引用、右值引用,std::forward都会按照原来的类型完美转发。forward主要解决引用函数参数为右值时,传进来之后有了变量名就变成了左值。
通用引用
当右值引用和模板结合的时候,T&&并不一定表示右值引用,它可能是个左值引用又可能是个右值引用。 传递左值进去,就是左值引用,传递右值进去,就是右值引用。
完美转发
所谓转发,就是通过一个函数将参数继续转交给另一个函数进行处理,原参数可能是右值,可能是左值,如果还能继续保持参数的原有特征,那么它就是完美的。
void process(int& i){
cout << "process(int&):" << i << endl;
}
void process(int&& i){
cout << "process(int&&):" << i << endl;
}
void myforward(int&& i){
cout << "myforward(int&&):" << i << endl;
process(i);
}
int main()
{
int a = 0;
process(a); //a被视为左值 process(int&):0
process(1); //1被视为右值 process(int&&):1
process(move(a)); //强制将a由左值改为右值 process(int&&):0
myforward(2); //右值经过forward函数转交给process函数,却称为了一个左值,
//原因是该右值有了名字 所以是 process(int&):2
myforward(move(a)); // 同上,在转发的时候右值变成了左值 process(int&):0
// forward(a) // 错误用法,右值引用不接受左值
}
上述例子不是完美转发,需要使用forward()函数去保证传入的是右值,那么我调用函数的时候依然是右值,使用这个函数之后,需要使用通用引用,采用T&&的模板,完成最终的完美转发。
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
void RunCode(int &&m) {
cout << "rvalue ref" << endl;
}
void RunCode(int &m) {
cout << "lvalue ref" << endl;
}
void RunCode(const int &&m) {
cout << "const rvalue ref" << endl;
}
void RunCode(const int &m) {
cout << "const lvalue ref" << endl;
}
// 这里利用了universal references,如果写T&,就不支持传入右值,而写T&&,既能支持左值,又能支持右值
template<typename T>
void perfectForward(T && t) {
RunCode(forward<T> (t));
}
template<typename T>
void notPerfectForward(T && t) {
RunCode(t);
}
int main()
{
int a = 0;
int b = 0;
const int c = 0;
const int d = 0;
notPerfectForward(a); // lvalue ref
notPerfectForward(move(b)); // lvalue ref
notPerfectForward(c); // const lvalue ref
notPerfectForward(move(d)); // const lvalue ref
cout << endl;
perfectForward(a); // lvalue ref
perfectForward(move(b)); // rvalue ref
perfectForward(c); // const lvalue ref
perfectForward(move(d)); // const rvalue ref
}
面向对象的三大特征
- 封装性:将客观事物抽象成类,每个类对自身的数据和方法实行protection (private , protected ,public )。
- 继承性:广义的继承有三种实现形式:实现继承(使用基类的属性和方法而无需额外编码的能力)、可视继承(子窗体使用父窗体的外观和实现代码)、接口继承(仅使用属性和方法,实现滞后到子类实现)。继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有的特性基础上进行扩展,增加功能,这样产生新的类,称作是派生类。继承呈现了面向对象程序设计的层析结构,体现了由简单到复杂的认知过程。继承是类设计层次的复用。
- 多态性:是将父类对象设置成为和一个或更多它的子对象相等的技术。用子类对象给父类对象赋值 之后,父类对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。

说一说c++中四种cast转换
大神链接
C++中四种类型转换是:static_cast , dynamic_cast ,const_cast ,reinterpret_cast
1.const_cast < type-id > ( expression ):
主要是用来去掉const属性,也可以加上const属性。
去掉const属性:const_case<int*> (&num),因为不能把一个const变量直接赋给一个非const变量,必须要转换。
加上const属性:const int* k = const_case<const int*>(j),少用,可以把一个非const变量直接赋给一个const变量,比如:const int* k = j;
使用范围:1、常量指针被转化成非常量指针,转换后指针指向原来的变量(即转换后的指针地址不变)。2、常量引用转为非常量引用。3、常量对象(或基本类型)不可以被转换成非常量对象(或基本类型)。
 对上述运行结果的解释:如果将常量指针转换为非常量指针,编译是可以通过的。但是,如果想通过这个非常量指针去改变常量指针所指内容,是无效的
对上述运行结果的解释:如果将常量指针转换为非常量指针,编译是可以通过的。但是,如果想通过这个非常量指针去改变常量指针所指内容,是无效的
2. static_cast
用于各种隐式转换,比如非const转const,void
∗
*
∗转指针等, static_cast能用于多态向上转化,如果向下转能成功但是不安全,结果未知;
3、dynamic_cast用于动态类型转换。只能用于含有虚函数的类,用于类层次间的向上和向下转化。只能转指针或引用。向下转化时,如果是非法的对于指针返回NULL,对于引用抛异常。要深入了解内部转换的原理。
向上转换:指的是子类向基类的转换
向下转换:指的是基类向子类的转换
它通过判断在执行到该语句的时候变量的运行时类型和要转换的类型是否相同来判断是否能够进行向下转换。
4、reinterpret_cast 几乎什么都可以转,比如将int转指针,可能会出问题,尽量少用;可以用在转换函数指针中,但是不安全。
5、为什么不使用C的强制转换((类型说明符)(表达式))
C的强制转换表面上看起来功能强大什么都能转,但是转化不够明确,不能进行错误检查,编译器不容判断其正确性,且在代码中无法快速定位使用强制转换的位置,容易出错。
C++的空类有哪些成员函数
缺省构造函数、缺省拷贝构造函数、缺省析构函数、缺省赋值运算符、缺省取址运算符、缺省取址运算符const。
注意:有些书上只是简单的介绍了前四个函数。没有提及后面这两个函数。但后面这两个函数也是空类的默认函数。另外需要注意的是,只有当实际使用这些函数的时候,编译器才会去定义它们。
对c++中的smart pointer四个智能指针:shared_ptr,unique_ptr,weak_ptr,auto_ptr的理解
为什么要使用智能指针:解决内存泄漏
智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。(RAII直译过来是“资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源)
使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。
智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
这个大佬写的非常好
shared_ptr的实现
shared_ptr线程安全吗?
引用计数是原子的。大神链接
1)同一个shared_ptr被多个线程“读”是安全的;
2)同一个shared_ptr被多个线程“写”是不安全的;
3)共享引用计数的不同的shared_ptr被多个线程”读写“ 是安全的;
unique_ptr有没有赋值和拷贝构造函数?
大神链接
没有,但是有移动构造和移动赋值函数。原因:转让所有权原指针就无了。
谈谈你对拷贝构造函数和赋值运算符的认识
大神链接
拷贝构造函数和赋值运算符重载有以下两个不同之处:
1.拷贝构造函数生成新的类对象,而赋值运算符不能。
2.由于拷贝构造函数是直接构造一个新的类对象,所以在初始化这个对象之前不用检验源对象是否和新建对象相同。而赋值运算符则需要这个操作,另外赋值运算中如果原来的对象中有内存分配要先把内存释放掉。
注意:当有类中有指针类型的成员变量时,一定要重写拷贝构造函数和赋值运算符,不要使用默认的。
在C++中,使用new申请的内存能否用free?使用malloc申请的内存能否通过delete释放?
不能,malloc/free主要为了兼容C, new和delete完全可以取代malloc/free的。malloc/free的操作对象都是必须明确大小的。而且不能用在动态类上。new和delete会自动进行类型检查和大小, malloc/free不能执行构造函数与析构函数,所以不能用在动态类上。
从理论上说使用malloc申请的内存是可以通过delete释放的。不过一般不这样写的。而且也不能保证每个C++的运行时都能正常。
用C++设计一个不能被继承的类
请移步
c11之前:
///
// Define a class which can't be derived from
///
template <typename T>
class MakeFinal
{
friend T;
private :
MakeFinal() {}
~MakeFinal() {}
};
class FinalClass2 : virtual public MakeFinal<FinalClass2>
{
public :
FinalClass2() {}
~FinalClass2() {}
};
FinalClass2不能被继承,因为其子类不是MakeFinal类的友元函数,无法调用其构造函数及析构函数。
c11之后,使用final:
struct A
{
virtual void foo() final;
};
struct B final : A
{
void foo(); // Error: foo cannot be overridden as it's final in A
};
struct C : B // Error: B is final
{
};
虚继承
为了解决菱形继承,虚继承体系中,虚基类会被优先构造。虚继承使用一个虚基表指针,指向虚基表,虚基表中存放了虚基表指针距离虚基类的偏移量,通过虚基类指针加上偏移量访问虚基类中的成员。由于虚继承多用于菱形继承,即有多继承的情况,因此最终多继承的子类有多个虚基表指针。(常见的是2两个)
虚基类使用
虚基类原理
C++自己实现一个String类
#include<iostream>
#include <cstring>
using namespace std;
class String
{
public:
// 默认构造函数
String(const char *str = nullptr);
// 拷贝构造函数
String(const String &str);
// 析构函数
~String();
// 字符串赋值函数
String& operator=(const String &str);
void Prints()
{
for (int i = 0; i < msize; i++)
{
cout << mystr[i];
}
cout << endl;
}
private:
char *mystr;
int msize;
};
String::String(const char *str)//得分点:输入参数为const型
{
if (str == nullptr)
{
msize = 0;
mystr = new char[1];
mystr[0] = '\0';// 得分点:对空字符串自动申请存放结束标志'\0'的
}
else
{
msize = strlen(str);
mystr = new char[msize + 1];
strcpy(mystr, str);
}
}
String::String(const String& str)
{
msize = str.msize;
mystr = new char[msize + 1];//加分点:对mystr加NULL 判断
strcpy(mystr, str.mystr);
}
String::~String()
{
delete[] mystr;
}
String& String::operator=(const String &str)
{
if (this == &str) return *this;//得分点:检查自赋值
delete[] mystr;//得分点:释放原有的内存资源
msize = strlen(str.mystr);
mystr = new char[msize + 1];
strcpy(mystr, str.mystr);
return *this;//得分点:返回本对象的引用
}
访问基类的私有虚函数
写出以程序的输出结果:
#include <iostream>
using namespace std;
class A
{
virtual void g()
{
cout << "A::g" << endl;
}
private:
virtual void f()
{
cout << "A::f" << endl;
}
};
class B : public A
{
void g()
{
cout << "B::g" << endl;
}
virtual void h()
{
cout << "B::h" << endl;
}
};
typedef void(*Fun)(void);//定义一个函数指针
void main()
{
B b;
Fun pFun;
for (int i = 0; i < 3; i++)
{
pFun = (Fun)*((int*) * (int*)(&b) + i);
pFun();
}
}
结果:

分析:
A的虚函数表:
| A::g |
|---|
| A::f |
| B的虚函数表: |
| B::g |
| – |
| B::h |
| 首先在for循环内,使用函数指针获得B类对象b的首地址,因为b的首地址保存了一个指针,这个指针指向了这个类的虚函数表,而这个虚函数表包含了父类A的虚函数表,当子类覆盖了父类中的虚函数时(此例子中的virtual void g()),那么b的虚函数表中原本指向父类的虚函数g()就改指向子类b的g()了。 |
| 其中要注意的是,父类的虚函数表的函数顺序是按照声明的顺序,并且父类的虚函数在子类的虚函数前面。因此对象stu的首地址指向的就是被自己覆盖的name()函数了。 |
| 虚函数表解析 |
对虚函数和多态的理解
多态的实现主要分为静态多态和动态多态,静态多态主要是重载,在编译的时候就已经确定;动态多态是用虚函数机制实现的,在运行期间动态绑定。举个例子:一个父类类型的指针指向一个子类对象时候,使用父类的指针去调用子类中重写了的父类中的虚函数的时候,会调用子类重写过后的函数,在父类中声明为加了virtual关键字的函数,在子类中重写时候不需要加virtual也是虚函数。
虚函数的实现:在有虚函数的类中,类的最开始部分是一个虚函数表的指针,这个指针指向一个虚函数表,表中放了虚函数的地址,实际的虚函数在代码段(.text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率。
多重继承,多个父类都存在虚函数,有几个虚指针?
会有多个虚指针,对应多个虚表,虚表尾部以*号结尾而不是0结尾则表示还有更多虚表。
1.子类虚函数会覆盖每一个父类的每一个同名虚函数。
2.父类中没有的虚函数而子类有,填入第一个虚函数表中,且用父类指针是不能调用。
3.父类中有的虚函数而子类没有,则不覆盖。仅子类和该父类指针能调用
大神链接
多重继承+菱形继承虚表存放?
大神链接
A是基类,B,C虚继承A,D继承B,D。A,B,C,D都有虚函数。
- 继承自B的虚表:先存放B自身没有被覆盖的虚函数(B::funcB),和D中没有覆盖别的类的虚函数(D::funcD),(我们之前说过,多继承以后子类中没有覆盖其他函数的虚函数放在所继承的第一个虚表中)
- 继承自C的虚表:虚表中只有自身没有被覆盖的虚函数(C::funcC)
- 继承自A的虚表:指向的虚表中有被D类覆盖的虚函数(D::func1)和祖先类(A)中的虚函数(A::funcA)
- 还会存放两个虚基表指针,指向虚基表,虚基表中存放偏移量,通过偏移量可以访问虚基类中的内容。
C++类的虚函数表和虚函数在内存中的位置
`A* a = new A();
a位于栈区,虚指针位于堆区,虚函数表位于只读数据段(.rodata),即:C++内存模型中的常量区;虚函数代码则位于代码段(.text),也就是C++内存模型中的代码区。
大神链接
为什么析构函数要声明为虚函数
如果一个父类指针指向一个子类对象,而析构函数没有声明为虚函数,那么在指针超出作用域的时候,会调用父类的析构函数,无法释放掉子类的资源。
为什么构造函数不能声明为虚函数
虚函数表指针在构造函数中初始化,因此如果构造函数为虚函数,无法初始化虚函数指针
为什么构造函数和析构函数中不要调用虚函数
不要在构造函数中调用虚函数的原因:因为父类对象会在子类之前进行构造,此时子类部分的数据成员还未初始化, 因此调用子类的虚函数是不安全的,故而C++不会进行动态联编。
不要在析构函数中调用虚函数的原因:析构函数是用来销毁一个对象的,在销毁一个对象时,先调用子类的析构函数,然后再调用基类的析构函数。所以在调用基类的析构函数时,派生类对象的数据成员已经“销毁”,这个时再调用子类的虚函数已经没有意义了。
简述类成员函数的重写、重载和隐藏的区别
(1)重写和重载主要有以下几点不同。
范围的区别:被重写的和重写的函数在两个类中,而重载和被重载的函数在同一个类中。
参数的区别:被重写函数和重写函数的参数列表一定相同,而被重载函数和重载函数的参数列表一定不同。
virtual的区别:重写的基类中被重写的函数必须要有virtual修饰,而重载函数和被重载函数可以被virtual修饰,也可以没有。
(2)隐藏和重写、重载有以下几点不同。
与重载的范围不同:和重写一样,隐藏函数和被隐藏函数不在同一个类中。
参数的区别:隐藏函数和被隐藏的函数的参数列表可以相同,也可不同,但是函数名肯定要相同。当参数不相同时,无论基类中的参数是否被virtual修饰,基类的函数都是被隐藏,而不是被重写。
注意:虽然重载和覆盖都是实现多态的基础,但是两者实现的技术完全不相同,达到的目的也是完全不同的,覆盖是动态态绑定的多态,而重载是静态绑定的多态。
派生类与基类数据成员及函数成员同名,则隐藏基类同名成员函数和数据成员

const成员函数可以重载吗?
可以,类普通成员函数与普通函数的区别在于隐含了this指针,而const成员函数相当于this指针类型:const Date* const。而普通的成员函数:可以修改成员变量 ,其this指针类型:Date* const,因此可以重载。
- 非const对象既可以调用const型成员函数,也可以调用非const型成员函数。
- const对象不可以调用非const成员函数。
- const成员函数不可以调用非const成员函数。
- 非const成员函数可以调用const成员函数。
链表和数组有什么区别
存储形式:数组是一块连续的空间,声明时就要确定长度。链表是一块可不连续的动态空间,长度可变,每个结点要保存相邻结点指针。
数据查找:数组的线性查找速度快,查找操作直接使用偏移地址。链表需要按顺序检索结点,效率低。
数据插入或删除:链表可以快速插入和删除结点,而数组则可能需要大量数据移动。
越界问题:链表不存在越界问题,数组有越界问题。
注意:在选择数组或链表数据结构时,一定要根据实际需要进行选择。数组便于查询,链表便于插入删除。数组节省空间但是长度固定,链表虽然变长但是占了更多的存储空间
vector的底层原理
vector底层是一个动态数组,包含三个迭代器,start和finish之间是已经被使用的空间范围, end_of_storage是整块连续空间包括备用空间的尾部。当空间不够装下数据(vec.push_ back(val))时,会自动申请另一片更大的空间( 1.5倍或者2倍),然后把原来的数据拷贝到新的内存空间,接着释放原来的那片空间[vector内存增长机制]。当释放或者删除(vec.clear())里面的数据时,其存储空间不释放,仅仅是清空了里面的数据。因此,对vector的任何操作一旦引起了空间的重新配置,指向原vector的所有迭代器会都失效了。
vector扩容为什么是1.5倍或2倍?
采用倍数扩容的原因是倍数扩容O(1)比线性扩容O(n)均摊效率更高(推导)使用2倍(k=2)扩容机制扩容时,每次扩容后的新内存大小必定大于前面的总和。而使用1.5倍(k=1.5)扩容时,在几次扩展以后,可以重用之前的内存空间了。为了防止申请内存的浪费,现在使用较多的有2倍与1.5倍的增长方式,而1.5倍的增长方式可以更好的实现对内存的重复利用。

vector中的reserve和resize的区别
- resize()函数的作用是改变vector元素个数
resize(n,m)第二个参数可以省略
n代表改变元素个数为n,m代表初始化为m .
主要有三层含义:
1.如果n比vector容器的size小,结果是size减小到n,然后删除n之后的数据。
2.如果n比vector容器的size大比容器的capacity小,结果是增加size,并初始化----如果指定了,初始化为指定值,没指定初始化为缺省值,capacity不变。
3.如果n比vector容器中的capacity大,结果是先增加容量,然后增加size,并初始化。capacity和size均改变。 - reverse()函数的作用是改变容量
reverse(n)
1.如果n的大小比vector的容量大,增容到n。size不变。
2.如果n的大小比vector的容量小。容量没有变化。size也没有变。 - 总结:
resize()函数是改变容器中元素个数,并初始化。------配合v1[i]来使用。因为这些位置已经初始化了,因此要用赋值。
reserve() 函数只是改变容量。----------配合push_back使用。
vector中的size和capacity的区别
size表示当前vector中有多少个元素(finish - start);capacity函数则表示它已经分配的内存中可以容纳多少元素(end_of_storage - start);
vector中erase方法与algorithn中的remove方法区别
vector中erase方法真正删除了元素,迭代器不能访问了。remove只是简单地将元素移到了容器的最后面,迭代器还是可以访问到。因为algorithm通过迭代器进行操作,不知道容器的内部结构,所以无法进行真正的删除
vector迭代器失效的情况
当插入一个元素到vector中,由于引起了内存重新分配,所以指向原内存的迭代器全部失效。
当删除容器中一个元素后,该迭代器所指向的元素已经被删除,那么也造成迭代器失效。erase方法会返回下一个有效的迭代器,所以当我们要删除某个元素时,需要it=vec.erase(it)或者vec.erase(it++)。
下列代码的运行结果
int main()
{
map<int, int> Map;
for (int i = 1; i < 10; i++)
{
Map[i] = i;
}
for (auto it = Map.begin(); it != Map.end();it++)
{
if (it->second % 3 == 0)
{
Map.erase(it);
}
}
cout << endl;
return 0;
}
上述代码无法运行成功,原因是在it->second为3的整数倍时,通过erase删除了该迭代器,迭代器失效,无法完成it++操作。可以使用以下方法达到想要的情况:
int main()
{
map<int, int> Map;
for (int i = 1; i < 10; i++)
{
Map[i] = i;
}
for (auto it = Map.begin(); it != Map.end();it++)
{
if (it->second % 3 == 0)
{
it = Map.erase(it);
//C11以后才可以使用,原因是C11之前map没有erase函数返回下一个迭代器
//C98使用Map.erase(it++);原因查看下面的链接
}
else
{
it++;
}
}
cout << endl;
return 0;
}
正确释放vector的内存(clear(), swap(), shrink_to_fit())
vec.clear():清空内容,但是不释放内存。
vector().swap(vec):清空内容,且释放内存,想得到一个全新的vector。
vec.shrink_to_fit():请求容器降低其capacity和size匹配。
vec.clear();vec.shrink_to_fit();:清空内容,且释放内存。
list的底层原理
list的底层是一个双向链表,使用链表存储数据,并不会将它们存储到一整块连续的内存空间中。恰恰相反,各元素占用的存储空间(又称为节点)是独立的、分散的,它们之间的线性关系通过指针来维持,每次插入或删除一个元素,就配置或释放一个元素空间。
list不支持随机存取,如果需要大量的插入和删除,而不关心随即存取
什么情况下用vector,什么情况下用list,什么情况下用deque
vector可以随机存储元素(即可以通过公式直接计算出元素地址,而不需要挨个查找),但在非尾部插入删除数据时,效率很低,适合对象简单,对象数量变化不大,随机访问频繁。除非必要,我们尽可能选择使用vector而非deque,因为deque的迭代器比vector迭代器复杂很多。
list不支持随机存储,适用于对象大,对象数量变化频繁,插入和删除频繁,比如写多读少的场景。
需要从首尾两端进行插入或删除操作的时候需要选择deque。
priority_queue的底层原理
priority_queue:优先队列,其底层是用堆来实现的。在优先队列中,队首元素一定是当前队列中优先级最
高的那一个。
map 、set、multiset、multimap的底层原理
map、set、multiset、multimap的底层实现都是红黑树,epoll模型的底层数据结构也是红黑树, linux系统中CFS进程调度算法,也用到红黑树。红黑树的特性︰
每个结点或是红色或是黑色;
根结点是黑色;
每个叶结点是黑的;
如果一个结点是红的,则它的两个儿子均是黑色;
每个结点到其子孙结点的所有路径上包含相同数目的黑色结点
为何map和set的插入删除效率比其他序列容器高
因为不需要内存拷贝和内存移动
为何map和set每次Insert之后,以前保存的iterator不会失效?
因为插入操作只是结点指针换来换去,结点内存没有改变。而iterator就像指向结点的指针,内存没变,指向内存的指针也不会变。
当数据元素增多时(从10000到20000),map的set的查找速度会怎样变化?
RB-TREE用二分查找法,时间复杂度为logn,所以从10000增到20000时,查找次数从log10000=14次到log20000=15次,多了1次而已。
map 、set、multiset、multimap的特点
set和multiset会根据特定的排序准则自动将元素排序,set中元素不允许重复,multiset可以重复。
map和multimap将key和value组成的pair作为元素,根据key的排序准则自动将元素排序(因为红黑树也是二叉搜索树,所以map默认是按key排序的),map中元素的key不允许重复,multimap可以重复。
map和set的增删改查速度为都是logn,是比较高效的。
为何map和set的插入删除效率比其他序列容器高,而且每次insert之后,以前保存的iterator不会失效?
存储的是结点,不需要内存拷贝和内存移动。
插入操作只是结点指针换来换去,结点内存没有改变。而iterator就像指向结点的指针,内存没变,指向内存的指针也不会变。
为何map和set不能像vector一样有个reserve函数来预分配数据?
在map和set内部存储的已经不是元素本身了,而是包含元素的结点。也就是说map内部使用的Alloc并不是map<Key, Data, Compare, Alloc>声明的时候从参数中传入的Alloc。
set的底层实现实现为什么不用哈希表而使用红黑树?
set中元素是经过排序的,红黑树也是有序的,哈希是无序的
如果只是单纯的查找元素的话,那么肯定要选哈希表了,因为哈希表在的最好查找时间复杂度为O(1),并且如果用到set中那么查找时间复杂度的一直是O(1),因为set中是不允许有元素重复的。而红黑树的查找时间复杂度为O(lgn)
hash_map与map的区别?什么时候用hash_map,什么时候用map?
构造函数:hash_map需要hash function和等于函数,而map需要比较函数(大于或小于)。
存储结构:hash_map以hashtable为底层,而map以RB-TREE为底层
总的说来,hash_map查找速度比map快,而且查找速度基本和数据量大小无关,属于常数级别。而map的查找速度是logn级别。但不一定常数就比log小,而且hash_map还有hash function耗时。
如果考虑效率,特别当元素达到一定数量级时,用hash_map。
考虑内存,或者元素数量较少时,用map。
迭代器失效的问题
插入操作:
对于vector和string,如果容器内存被重新分配,iterators、pointers、references失效;如果没有重新分配,那么插入点之前的iterator有效,插入点之后的iterator失效;
对于deque,如果插入点位于除front和back的其它位置,iterators、pointers、references失效;当我们插入元素到front和back时,deque的迭代器失效,但reference和pointers有效;
对于list和forward_list,所有的iterator,pointer和refercnce有效。
删除操作:
对于vector和string,删除点之前的iterators、pointers、references有效;off-the-end迭代器总是失效的;
对于deque,如果删除点位于除front和back的其它位置,iterators、pointers、references失效;当我们插入元素到front和back时,off-the-end失效,其他的iterators、pointers、references有效;
对于list和forward_list,所有的iterator、pointer和refercnce有效。
对于关联容器map来说,如果某一个元素已经被删除,那么其对应的迭代器就失效了,不应该再被使用,否则会导致程序无定义的行为。
STL线程不安全的情况
在对同一个容器进行多线程的读写、写操作时;
在每次调用容器的成员函数期间都要锁定该容器;
在每个容器返回的迭代器(例如通过调用begin或end)的生存期之内都要锁定该容器;
在每个在容器上调用的算法执行期间锁定该容器
lambda表达式
[capture] (params)opt->ret{body;};
[函数对象参数] (操作符重载函数参数)mutable或exception声明->返回值{函数体};
1.函数对象参数
| 操作符 | 意义 |
|---|---|
| [] | 不截取任何变量 |
| [&] | 截取外部作用域的所有变量,并且按引用传递 |
| [=] | 截取外部作用域的所有变量,并且按值传递 |
| [=,&foo] | 截取外部作用域的所有变量,并且按值传递,但是对foo变量使用引用 |
| [bar] | 截取bar变量,并且按值传递,同时不截取其他变量 |
| [this] | 截取当前类中的this指针,如果使用&或者=就默认添加此选项 |
| 2.重载参数列表 | |
| 调用的时候需要传递的参数(参数可以缺省) | |
| 3.返回类型(可以自动推导,可以省略) | |
| 4.函数体 | |
| 5.函数选项opt | |
| 选项 | 意义 |
| – | – |
| mutable | 表示函数体可以修改捕获的变量,同时可以访问捕获对象的非常属性的成员函数 |
| exception | 是否抛出异常以及抛出何种异常 |
| attribute | 用来声明属性 |
lambda表达式如何实现
大神链接
编译器为我们创建了一个匿名类,重载了() (仿函数机制),捕获的变量相当于将该变量定义在该类中的成员变量中。
什么样的函数可以抛出异常?构造函数可不可以抛出异常?
析构函数:
除析构函数,别的都可以抛出异常。
1.不要在析构函数中抛出异常!虽然C++并不禁止析构函数抛出异常,但这样会导致程序过早结束或出现不明确的行为。
2.如果某个操作可能会抛出异常,class应提供一个普通函数(而非析构函数),来执行该操作。目的是给客户一个处理错误的机会。
3.如果析构函数中异常非抛不可,那就用try catch来将异常吞下,但这样方法并不好,我们提倡有错早些报出来。
构造函数:
1. 构造函数中抛出异常,会导致析构函数不能被调用,但对象本身已申请到的内存资源会被系统释放(已申请到资源的内部成员变量会被系统依次逆序调用其析构函数)。
2. 因为析构函数不能被调用,所以可能会造成内存泄露或系统资源未被释放。
3. 构造函数中可以抛出异常,但必须保证在构造函数抛出异常之前,把系统资源释放掉,防止内存泄露。
最后总结如下:
- 构造函数中尽量不要抛出异常,能避免的就避免,如果必须,要考虑不要内存泄露!
- 不要在析构函数中抛出异常!
如何限制对象只能在栈上?如何限制对象只能在堆上?
大神链接
只在堆上:将析构函数私有化
只占栈上:将new和delete重载并私有化
C++中#的用法,##的用法
大神链接
#的功能是将其后面的宏参数进行字符串化操作
##被称为连接符(concatenator),用来将两个Token连接为一个Token。所谓的子串(token)就是指编译器能够识别的最小语法单元。
#define f(a,b) a##b
#define g(a) #a
#define h(a) g(a)
int main()
{
printf("%s\n", h(f(1, 2)));
printf("%s\n", g(f(1, 2)));
return 0;
}
运行结果:
12 //h(f(1, 2)) -> h(12) -> g(12) -> "12"
f(1,2) //g(f(1, 2)) -> "f(1, 2)"
C++中调用虚函数和普通函数的开销一样吗?
大神链接
不一样,虚函数开销大,除了虚指针和虚表的内存开销,查虚表的时间开销,还有流水线和分支预测,由于虚函数调用需要间接跳转,所以会导致虚函数调用比普通函数调用多了分支预测的过程,产生性能差距的原因主要是分支预测失败导致的流水线冲刷性能开销。
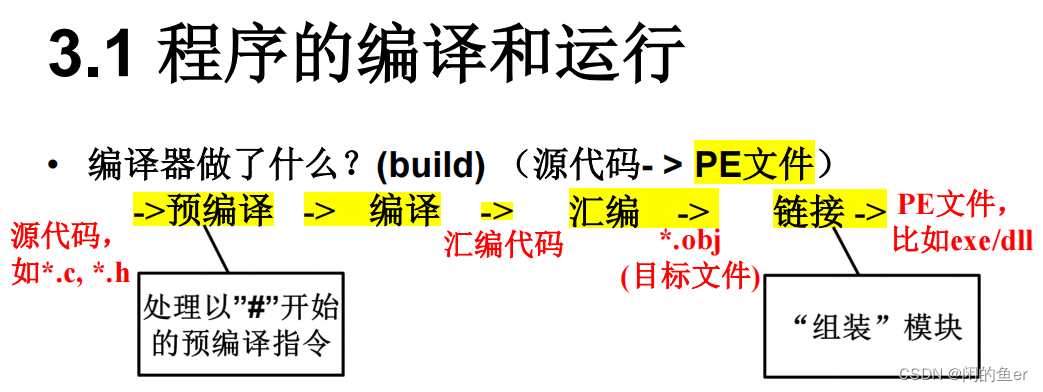
程序的编译和运行过程中编译器做了什么?
运行PE文件后发生了什么?

C++模板的优点和缺点
C++ 模板的优点有:
- 可以用来创建泛型算法,可以被应用到各种数据类型上,提高了代码的可重用性。
C++ 模板的缺点有:
- 编译时间可能会增加,因为编译器需要生成代码的实例。
- 可能会导致代码膨胀,因为编译器会为每个使用模板的类型生成一份代码的实例。
- 可能会增加代码的阅读难度,因为模板代码看起来可能会很复杂。
- 兼容性问题,老版本C++不兼容模板
静态库(.a或.lib)和动态库(.so或.dll)的区别?
静态库在程序编译时会被连接到目标代码中,程序运行时将不再需要该静态库。
- 优点:移植方便,运行速度快。
- 缺点:体积更大,消耗内存,升级麻烦,如果静态库更新,那么所有使用该静态库的代码都要重新编译。
动态库在程序编译时并不会被连接到目标代码中,而是在程序运行时才被载入,因此在程序运行时还需要动态库存在,因此代码体积较小。 - 优点:不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,节省内存。方便升级,只要替换对应动态库即可,不必重新编译整个可执行文件
- 缺点: 当可执行文件需要使用到函数库的机制时,程序才会去读取函数库来使用,也就是说可执行文件无法单独运行。
C++实现单例的方法?哪个是线程安全的?
懒汉式(需要的时候去构造),饿汉式(程序开始即初始化的时候就构造)。安全的是饿汉式和加锁的懒汉式。
大神链接
内联函数?
为了解决频繁的栈调用消耗掉大量内存,而使用内联函数。从源码看有函数的结构,但是在编译后不具备函数的性质,采用类似宏定义的方式在编译后内联展开。

编译型语言和解释型语言的区别?
来源
对于计算机硬件而言,它们只能识别某些特定的二进制指令(机器码),而无法解读和直接执行我们编写的源代码。因此,在程序真正运行之前必须将源代码转换成二进制指令。而因为不同语言转换的时机不同,但总体上可分为两类,因而将高级编程语言分为了编译型语言和解释型语言。
- 编译型语言在程序在执行之前需要一个专门的编译过程,通过编译器把程序编译成为可执行文件,再由机器运行这个文件,运行时不需要重新翻译,直接使用编译的结果就行了。而解释型语言是一边执行一边转换的,其不会由源代码生成可执行文件,而是先翻译成中间代码,再由解释器对中间代码进行解释运行,每执行一次都要翻译一次。
- 编译型语言可以实现一次编译,无限次运行,只要在首次执行时编译生成相应的可执行文件,在以后的每次运行就只需要直接运行这个可执行文件,因此其运行效率高于解释型语言,但因为不同平台的可执行文件不同(同时不同平台支持的函数、类型、变量等都可能不同),因此编译型语言难以实现在不同操作系统间随意切换,可移植性较差。对于解释型语言,其实现的是一次编写,到处运行,每次执行都得重新转换源代码,因此其在效率上天生就低于编译型语言,但也因为其每次运行都会重新转换源代码,因此只需要解释器根据操作系统的不同将源代码转换成不同的机器码,相同的源代码,就可以实现在不同的平台上运行,因此其更灵活。
为什么不要以多态的方式处理数组?
因为在数组访问过程中,编译器需要知道每个数组元素的大小,如果以多态的方式处理,那么数组中的元素可能并不是它声明的大小,就会带来不可预期的问题。c++规范中说,通过一个基类指针删除一个由派生类构成的数组,那么结果未定义。
缺乏默认构造函数的限制?
- 使用该类会出现限制,例如难以使用对象数组。
- 不适用于很多模版容器类,可能该模板实现中需要默认构造函数。
非必要不提供默认构造函数
添加无意义的默认构造函数会影响程序效率,且有些类的默认构造函数没有意义。(More Effective C++ P19)
在没有默认构造函数的类使用对象数组可以采用以下方法:
- 使用在栈上的数组,数组在声明时直接初始化
- 使用指针数组而非对象数组。
图形学
渲染管线
- RTR4中将渲染分为应用阶段,几何阶段,光栅化阶段,像素处理。
- 应用阶段:可以执行一些任务,例如碰撞检测,全局加速算法,动画,物理模拟等,应用阶段一般由运行在CPU上的软件实现,所以开发者完全可以决定如何实现以及优化该阶段达到提升性能的目的。为了提升性能采用了一种 “超标量结构”的CPU设计,可以同时执行几个进程,应用阶段最主要的任务是输入后面阶段需要的数据(输出需要渲染的图元),如:模型,贴图,光照,相机位置等。
- 几何阶段:主要分为四个阶段,顶点着色器,投影,裁剪,屏幕映射。除了上述操作,还可以进行曲面细分,几何着色器,流输出等,曲面细分是让模型更加平滑精细,几何着色器可以将输入图元转换为另一种图元,流输出就是将顶点存储在一个数组中,可以对该数组进行进一步的处理。这一阶段将会输出屏幕空间的二维顶点坐标、每个顶点对应的深度值、颜色值等信息。
- 光栅化阶段:主要包括三角形设置和三角形遍历两个阶段,三角形设置主要计算三角形的一些数据,在三角形遍历的过程中,每一个像素的中心点都会被检查是否被三角形覆盖。
- 像素处理:主要分为两个阶段:像素着色与融合,像素着色就是逐像素的对该像素的信息进行调整。融合是将像素着色阶段产生的片段颜色与存储在颜色缓存中的颜色进行混合(半透明物体)。模板测试通常用于限制渲染的区域,还可以用于渲染阴影、轮廓渲染。

几何着色器作用
在顶点着色器以及曲面细分着色器之后,专门处理场景中的几何图形,可以将创建和销毁几何图元,可以根据顶点信息批处理几何图形。可以做出爆炸效果,法线可视化(先正常绘制,然后再次绘制该场景,利用几何着色器沿着法向量生成三条线),线框球等效果。
大神链接
大神链接
设置渲染状态是什么意思?
渲染状态定义了场景中的网格怎样被绘制。使用什么顶点、片元着色器,光源属性,材质。
调用Draw Call
Draw Call是一个命令,发起方是CPU,接收方式GPU。
顶点着色器主要的作用
顶点着色器不会创建或销毁任何顶点,而且无法得到顶点和顶点之间的关系。顶点着色器需要完成的工作主要有:坐标变换和逐顶点光照。顶点着色器还可以输出后续需要的数据。
双缓冲作用
避免我们看到正在光栅化的图元。避免读取到下一帧的颜色缓冲。
CPU、图形API、显卡驱动和GPU之间的关系
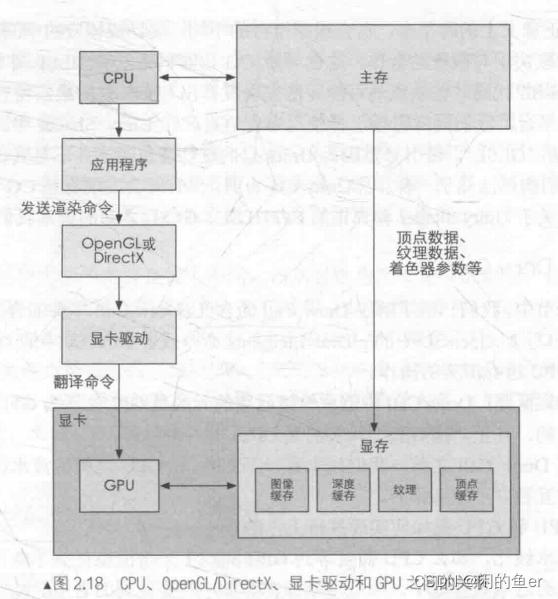
CPU和GPU如何并行工作?
使用命令缓冲区。CPU添加命令,GPU读取命令(可以改变渲染模型、改变渲染状态)。改变渲染状态比较耗时。
为什么Draw Call多了会影响帧率?
每次调用Draw Call,CPU都需要向GPU发送很多内容,包括数据、状态和命令,耗时长。GPU的渲染速度往往高于CPU提交命令的速度。
如何减少Draw Call?
批渲染(Batch)
Batch render 是大部分引擎提高渲染效率的方法,基本原理就是通过将一些渲染状态一致的物体合成一个大物体,一次提交给gpu进行绘制,如果不batch的话,就要提交给很多次,这可以显著的节省drawcall,实际上这主要节省了cpu的时间,cpu从提交多次到提交一次,对gpu来说也不用多次切换渲染状态。当然能batch的前提一定是渲染状态一致的一组物体。(比较适合静态物体)
在模型方面,避免使用大量很小的网格,当不可避免的需要使用很小的网格结构的时候,考虑是否可以合并他们。
避免使用过多的材质。尽量在不同的网格之间公用一个材质。
大神链接
MRT,多渲染目标
将每个像素的数据保存到不同的缓冲区中,这样的好处是这些缓冲区的数据可以成为照片级光照效果着色器的参数。采样这种技术,光照可以在所有几何图形被渲染以后进行应用,不需要进行多步的渲染,因此称为延期着色。存储在表面的信息可以包括位置、法线、颜色以及材质的信息。
阴影实现(shadow map)
首先将摄像机放在与光源重合的位置上,那么阴影区域就是当前摄像机看不到的地方,shadow map本质上也是一个深度图,记录了从光源位置出发能看到的场景中距离它最近的表面信息。
在传统的阴影映射中,我们要将坐标系变换为光源坐标,然后进行深度采样,在最终渲染的时候,计算每个点到光源的距离,然后与深度采样结果进行比较,如果大于深度采样,则处于阴影中。我们使用xy分量对阴影映射纹理进行采样,得到阴影映射纹理中该位置的深度信息。如果该深度值小于该顶点的深度值(通常由z分量得到),那么说明该点位于阴影中。
阴影映射纹理的获取
在LightMode为ShadowCaster的Pass专门更新光源的阴影映射纹理,这个Pass的渲染目标不是帧缓存,而是阴影映射纹理
屏幕空间的阴影映射技术
屏幕空间的阴影映射技术(需要支持MRT,多渲染目标)先获取光源的阴影映射纹理和摄像机的深度纹理,根据这两个纹理获得屏幕空间的阴影图,如果摄像机中记录的表面深度大于转换到阴影映射纹理中的深度值,就说明该表面虽然是可见的,但是却在阴影中。如果我们想要一个物体接收来自其他物体的阴影,只需要在Shader中对阴影图进行采样,由于阴影图在屏幕空间下,因此要将表面坐标从模型空间变换到屏幕空间,然后对阴影图进行采样。
- 如果我们想要一个物体接收其他物体的阴影:在Shader中对阴影映射纹理进行采样,把采样结果和最后的光照效果相乘来产生阴影效果。
- 如果我们想要一个物体向其他物体投射阴影,就必须把该物体放入光源的阴影映射纹理的计算当中。
软阴影与硬阴影的区别
软阴影是指从区域光源获得的阴影,而不是从点光源或定向光获得的硬阴影。软阴影具有半影 penumbra – 柔和的边缘从全阴影过渡到全光照。
软阴影介绍
知道屏幕上的ui的2d坐标知道深度的情况下推算世界坐标
讲解视频
首先利用屏幕上的坐标求出裁剪空间中的x’‘,y’‘,z’‘关于w的公式,此时是在NDC之前的坐标,然后利用投影矩阵正向计算可以得出一个z关于w的公式,再将z=z’‘*w带入,解方程求出w,乘w求出在裁剪空间下的x’‘,y’‘,z’'坐标,然后利用如下公式,算出在View空间下的坐标,利用view的逆矩阵算出在世界空间下的坐标。

非线性深度与线性深度
视频讲解
视图空间中的深度是线性深度,由于视图空间转换为投影空间需要乘投影矩阵,然后同时除w值,即透视除法,得到NDC坐标下的z值[-1,1],由于屏幕空间下深度[0,1],因此depth = (z + 1)/2。

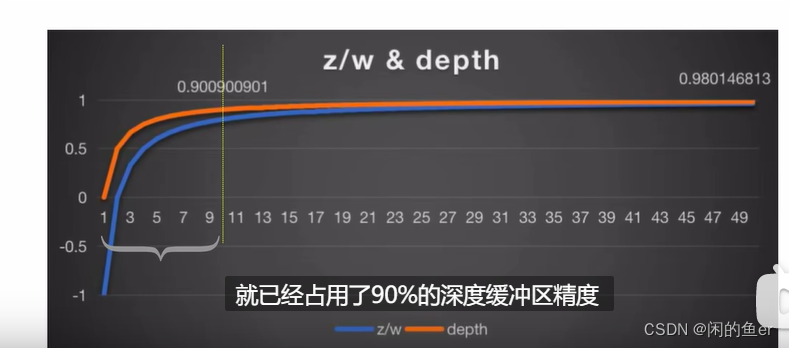
由上述图像可知,离摄像机越远的像素精度越低。其底层原因是因为经过透视除法,深度是一个关于1/z的函数,而1/z是一个非线性函数。
通过非线性深度反算线性深度

z-fighting
由于摄像机远的地方,深度精度越低,因此当摄像机距离物体较远的时候,该像素在深度测试时有时是A通过测试,有时是B通过测试,因此出现闪烁现象。

绕世界坐标系中某一物体自身的y轴旋转一定角度,旋转矩阵如何推导
先进行平移和旋转变换,换为该物体的模型空间,然后绕y轴旋转,最后把三个矩阵相乘即可。
NDC(归一化的设备坐标)
标准齐次除法处理后的坐标,即将x,y,z除以z之后的坐标,经过这一步之后,裁剪空间中的物体全部放置在一个立方体中,等待进行屏幕映射。
PBR
PBR就是基于物理的渲染,不是基于经验模型的。
PRB介绍
离线渲染和实时渲染的区别
离线渲染也称为预计算,不考虑时间对渲染的影响,渲染一副图像(1帧)需要花上许多时间,离线渲染的渲染质量更高,多用于影视电影中。缺点是渲染画面无法与用户交互。
实时渲染绘制一幅图像(1帧)只需要1/30秒,速度非常快,多用于游戏、仿真、模拟中。优点是可以进行实时操纵,缺点是受系统负载能力的限制,牺牲了一定的画面效果。
纹理太小(多个像素映射到同一个纹素)
- Unity中的point模式,使用最近邻作为该像素的采样点,因此效果会出现像素风格。
- Bilinear双线性插值,寻找四个最近邻进行插值
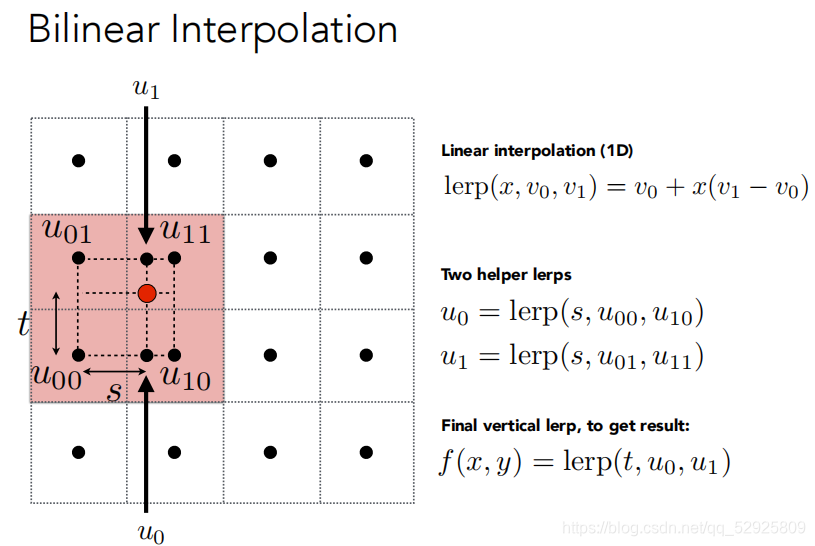
- bicubic 取临近的16个进行插值
- Unity中Trilinear还会进行多层渐远之间的混合
mipmap(纹理太大的问题)
- 原理,将贴图按照2的倍数进行缩小,直到1X1,在渲染时,根据一个像素离眼睛的距离,选择合适的图层赋值给像素,大小介于两个纹理图像之间时,对两个纹理图像进行线性插值。
- 优点:优化渲染,提高游戏的流畅度,根据摄像机距离模型的远近而调整不同质量的贴图显示,减少渲染消耗,提升帧数。
- 缺点:占用内存增大(33%)
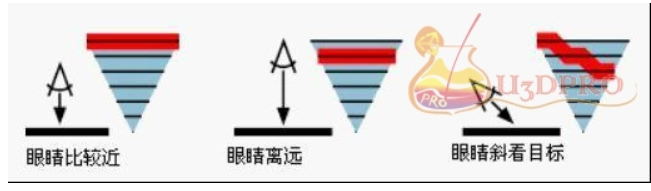
LOD
- 模型金字塔,不同级别展示不同的细节,当摄像机距离远时,使用低级别的模型,距离近时使用高细节模型。
微表面模型
- 微表面模型假定物体表面是由一系列朝向各异的微小镜面组成的,各个微小镜面的朝向分布越分散,则宏观的物体表面就会越粗糙;若越集中,则物体表面就会越光滑。
为什么使用齐次坐标?
齐次坐标可以表示所有的仿射变换,包括平移变换和线性变换。可以方便的区分点和向量,点的w值为1,向量的w值为0。支持投影矩阵。
如何在Shader中采样,如何获取二维纹理中的具体像素值?
glGenTextures()、glBindTexture(),在shader中texture()与texelFetch()。
mipmap的实现,如何确定使用哪一层?
如果纹理开启了mipmap,离相机越远的表面,在进行纹理采样的时候,会使用更低的mipmap等级,来提升游戏的性能。
px=纹素x大小ddx
py=纹素y大小ddy
float lod=0.5*log2(max(dot(px,px),dot(py,py)));
在光栅化的时刻,GPU会并行运行很多Fragment Shader,并不是一个像素一个像素去执行的,而是组织在一个2X2的一组像素中,并行执行。ddx(屏幕空间中x轴向的偏导数)=p(x+1,y)-p(x,y),ddy(y轴的偏导数)=p(x,y+1)-p(x,y)。
层与层直接插值处理。
如何渲染光照
经验模型(如phong模型),pbr光照模型,光线追踪。
透明效果的实现
alpha,当透明度为1时,完全不透明,为0时,完全不会显示。
- 透明度测试(无法得到真正的半透明效果,不需要关闭深度写入):只有某个片元的透明度不满足条件(通常是小于某个阈值)那么该片元就会被舍弃,被舍弃的片元不会进行任何处理,也不会对颜色缓冲产生任何影响。否则,就会按照普通的不透明物体处理他。也就是说,透明度测试处理的物体要么完全透明,要么完全不透明。
- 透明度混合:使用当前片元的透明度作为混合因子,与已经存储在颜色缓冲中的颜色值进行混合,得到新的颜色。透明度混合关闭了深度写入(不透明物体依然可以进行深度写入),但是没有关闭深度测试,这保证了不透明物体可以正常遮挡透明物体。
渲染顺序
-
常用方法:
-
先渲染所有的不透明物体,开启深度测试和深度写入。
-
把半透明物体按距离摄像机的距离从远到近进行排序,从后往前进行渲染,并开启深度测试,但是关闭深度写入。
-
出现问题:半透明物体之间的错误遮挡。
-
解决方案:
1.把大模型拆成小模型,即使出现问题但因为模型小,不会那么明显。
2.也可以将透明通道变得柔和一点,让模型的穿插不那么明显。
3.使用渲染队列,使用一系列整数索引来表示每个渲染队列,索引号越小表示越早被渲染。 -
开启深度写入的半透明效果:写两个pass,一个进行深度写入,但是不填充颜色,另一个按照像素级别的深度写入结果进行填充。
-
绘制物体时,一般会开启背面剔除,这一物体内部,背对摄像机的面是不会被绘制的。但是当绘制半透明物体时,有时我们可能希望要绘制内部的背对摄像机的面,因为物体是半透明的,这些面是可以被看到的。对于这种需求,我们采用双面渲染的方法,使用两个pass渲染。
Pass 1 开启剔除,剔除正面。渲染该半透明物体。
Pass 2 开启剔除,剔除背面。再次渲染该物体。
抗锯齿算法
- SSAA :光栅化时,采样多个子像素,进行加权平均,作为最终像素的颜色
- MSAA(多重采样抗锯齿):将一个像素分为多个子采样点,计算每个子采样点的颜色,是否被某个三角形覆盖,最后像素颜色为四个采样点的插值。只对多边形边缘采样,只支持前向渲染,不支持延迟渲染;更适合静态画面;只能消除几何走样,对于高光区域走样没有用,对边缘不明确和半透明物体效果不好。
- TAA:对每一帧画面,加上微小的抖动偏移(0~1像素),在时域上得到当前像素的子像素信息,在时域上加权融合,得到当前像素的最终颜色.将子像素采样分摊到多个历史帧上,减少每帧的开销。支持延迟渲染,需要额外内存开销(速度缓冲)
- MLAA:通过亮度、颜色、深度、法线等检测每帧图像的边缘,对边缘进行模式识别,分为Z、U、L三类。根据边缘的形状,判断原始边缘的形状,对边缘进行重新矢量化,计算权重,与周围颜色进行混合。
sinx实现(泰勒展开)
double tsin(double x)
{
double sum = 0;
double t = x;
int n = 1;
do
{
sum= sum + t;//结果累加
n++;//迭代变量
//每一项的表达式,后一项比前一项的区别在于:
//1、分子每次多乘2次x。2、分母每次阶乘都比前面多二个,多的就是比前面大1和大2的那二个数
t = -t * x * x / (2 * n - 1) / (2 * n - 2);
} while (fabs(t)>=value);
return sum;
}
如何均匀采样一个圆?
- 拒绝采样:随机[-1,1]的坐标,然后判断是否在圆内,不在圆内就舍弃。
- 对角度用[0,2pi]随机,半径用[0,1]的平方,(只用r不对)
如何均匀采样一个球?
- 随机取三个点x,y,z,它们的取值范围[-1,1]。若点落在球外就舍弃重新选择三个数。若在圆内,该点(x,y,z)就是本次被采样到的点。
如何均匀采样一个球面?
- 随机取三个点x,y,z,它们的取值范围[-1,1]。若点落在球外就舍弃重新取三个数。若在球内,从原点(0,0,0)到(x,y,z)做一条直线,一直延伸到球面上,落在球面上的位置为(x’,y’,z’)。(x’,y’,z’)就是本次被采样到的点。
向量叉乘的几何意义?
区分左右
矩阵旋转
优点:
- 与四元数一样,不存在万向节锁问题
- 可以表示围绕任意轴的旋转
缺点:
- 矩阵旋转使用4x4矩阵,记录16个数值,而四元数只需要4个数值。计算复杂,效率低。
欧拉角
优点:
- 三个角度组成,直观,容易理解。
- 旋转角度不受限,可以进行从一个方向到另一个方向旋转大于180度的角度。
弱点:
- 万向锁问题。
- 只能以三个坐标轴为方向旋转
- 旋转的顺序影响结果。
四元数
对于一个物体的旋转,我们只需要知道四个值:一个旋转的向量 + 一个旋转的角度。而四元数也正是这样的设计:q = (x,y,z,w)。
其中x,y,z 代表的是向量的三维坐标,w代表的是角度,四元数提供的是球面的线性插值。


优点:
- 四元旋转不存在万向节锁问题。
- 存储空间小,计算效率高。
弱点:
- 单个四元数不能表示在任何方向上超过180度的旋转。
- 四元数的数字表示不直观。只能绕过原点的轴旋转。
万向锁问题
对于动态欧拉角(绕物体坐标系旋转),无论绕第一,三个轴转动的旋转角为多少度,只要绕第二个轴的旋转角为±90°,就会出现万向锁现象。
万向锁现象:一旦选择±90°作为pitch角,就会导致第一次旋转和第三次旋转等价,整个旋转表示系统被限制在只能绕竖直轴旋转,丢失了一个表示维度。
UE4
UE4AsyncLoading异步加载实现方式
对于资源加载,UE4有同步加载和异步加载两种方式。同步加载是阻塞操作,比如LoadObject函数,会阻塞主线程,如果加载一个较大资源,或者对外部依赖较多的资源,会造成游戏明显卡顿。异步加载为使用另一个专用的异步加载线程来加载资源,或者依然在主线程做加载,只是使用异步编程模式,在tick中分散加载一些资源。异步加载不会阻塞主线程。
FAsyncLoadingThread类是实现异步加载功能的主体,它的一大特点为既可以启动一个单独的线程做异步加载,也可以由主线程tick调用,分散做数据异步加载。默认配置不启用专门异步加载线程。异步加载线程的工作模式为我们熟知的“生产者-消费者”模式,GameThread生产加载请求,异步加载线程消费请求,QueuedPackages为工作队列。
大神链接
垃圾回收GC
垃圾回收1
垃圾回收2
垃圾回收3
UE4对所有的UObject对象提供了自动垃圾回收机制,当达到GC条件时(内存不足,到达GC时间间隔,切换场景强制GC),会通过扫描系统中所有的UObject是否存活,来清理那些不需要UObject对象,释放其内存空间。
UE4垃圾回收的核心是使用了标记-清理算法,标记指的是它以所有在ROOT上的UObject列表为根,去递归遍历所有这些根Uobject的引用链,所有能访问到的UObject就标记为可达的。清理阶段会在标记完后,收集所有这些UnReachable Uobjects,对其进行清理回收。标记流程在一帧内完成,而清理阶段可以分为多个帧,时间切片方式完成,所以GC机制的性能点在于标记阶段,如果有太多的UObject对象,那么游戏GC时会有明显的卡顿,所以需要控制内存中UObject数量。
被纳入自动GC管理的条件
- UObject对象中的UObject*成员变量必须被UPROPERTY宏定义修饰,自动被加入到引用。
- UObject对象实现了派生的AddReferencedObjects接口,手动将UObject*变量添加到引用。
- 对于Struct结构体中引用的UObject,必须继承FGCObject对象,并实现派生的AddReferencedObjects接口,手动将UObject*变量加入引用。
一个UObject不会被GC的条件
- UObject对象被加入到Root根上(调用AddRoot函数)。
- 直接或者间接被根节点Root对象引用(UPROPERTY宏修饰的UObject成员变量 注:UObject放在UPROPERTY宏修饰的TArray、TMap中也可以)
- 直接或间接被存活的FGCObject对象引用
手动清理一个UObject
手动对UObject对象调用MarkPendingKill(),该函数会 将UObject对象对应GUObjectArray中的FUObjectItem的Flags加上EInternalObjectFlags::PendingKill标记,在下一次GC时,会被GC机制在标记阶段,标记为UnReachable对象,进而被回收,同时会自动更新所有引用该对象的UObject*变量为nullptr。
垃圾回收GC发生的时机
- 切换场景强制GC:在加载场景LoadMap时,UE会进行一次完整的GC,清理上个场景无用的对象,释放内存,切场景时进行的是强制GC,强制GC时清理阶段不会分帧进行(全量清理,阻塞主线程),同步一次性完成清理。
- 定时GC:定时清理无用的Object,定时GC的清理阶段会分帧进行(增量清理),尽量降低对游戏性能的损耗,标记阶段依旧会在同一帧进行,清理会分帧进行。
- 手动进行GC:在我们想要UE立刻进行垃圾回收时,我们可以通过调用GEngine->ForceGarbageCollection(bool bForcePurge)接口,来让UE进行一次完整的垃圾回收,当bForcePurge为true时,会更改强制GC标识,进行的是强制GC,为false时会更新时间戳,触发定时GC。它们的区别在于强制GC进行全量清理,而定时GC进行增量清理。
垃圾回收GC过程
GC主要包括两个阶段:标记阶段和清理阶段。
标记阶段:从一个根集合出发,遍历所有可达对象,遍历完成后就能标记出可达对象和不可达对象了,这个阶段会在一帧内完成。
清理阶段:会渐进式的清理这些不可达对象,因为不可达的对象将永远不能被访问到,所以可以分帧清理它们,避免一下子清理很多UObject,比如map卸载时,发生明显的卡顿。
簇和增量清除
- 簇是为了提高回收效率:集群(簇),Cluster,可以把它当作一个有着共同生命周期的UObjects集合,把它当作一个整体,该整体的可达性由这个集群的Cluster Root是否可达来决定,如果Cluster Root不可达,那么表示该Cluster中所有的UObject都是不可达的,将会被垃圾回收机制全部回收(也有例外,如果被标记了ReachableInCluster会被略过)。该特性可以加快垃圾回收标记流程,在集群中的UObject不会递归遍历引用链,只有Cluster Root是关键。
- 增量清除是为了避免垃圾回收时导致的卡顿。
UE4反射的实现方式
反射是指在程序运行时得到类型信息,通过类型信息创建对象、读取修改属性、调用对象方法的功能。反射机制支撑了虚幻编辑器编辑器中的细节面板、序列化、垃圾回收、网络复制、以及蓝图与C++交互等功能。UE中当前实现反射的方案就是,先在C++源程序文件中做出宏标记(UCLASS,UFUNCTION),然后再用UHT工具分析生成generated.h/.cpp文件,在generate.h和cpp里注册相关信息,之后再一起编译。
UHT,UBT
- UnrealBuildTool:UE4的自定义工具,来编译UE4的逐个模块并处理依赖等。Target.cs,Build.cs都是为这个工具服务的。
- UnrealHeaderTool:UE4的C++代码解析生成工具,我们在代码里写的那些宏UCLASS等和#include "*.generated.h"都为UHT提供了信息来生成相应的C++反射代码。
UObject
UObject是UE4的基础,提供了元数据,反射,GC,编辑器可见,序列化等一系列功能。从UObject派生的每个类都会创建一个UClass,UClass包含该类实例的所有元数据。
Actor
UE4中所有可以放入关卡中的对象均派生自AActor。Actor的概念在UE里其实不是某种具象化的3D世界里的对象,而是世界里的种种元素,用更泛化抽象的概念来看,小到一个个地上的石头,大到整个世界的运行规则,都是Actor。
因此虽然transform是大多数Actor需要的功能,但是并不是所有的Actor都需要,UE4的设计理念是“不为你不需要的东西付代价”,因此UE把Transform封装进了SceneComponent,当作RootComponent,Actor想要平移、旋转、缩放都是内部转发到了RootComponent然后执行。
UActorComponent
可为不同类型的Actor提供相同的功能。Component与游戏逻辑无关,理想情况下,组件可以迁移到另一个游戏中不受影响。
TSet<UActorComponent*> OwnedComponents 保存着这个Actor所拥有的所有Component,一般其中会有一个SceneComponent作为RootComponent。
TArray<UActorComponent*> InstanceComponents 保存着实例化的Components。
APawn
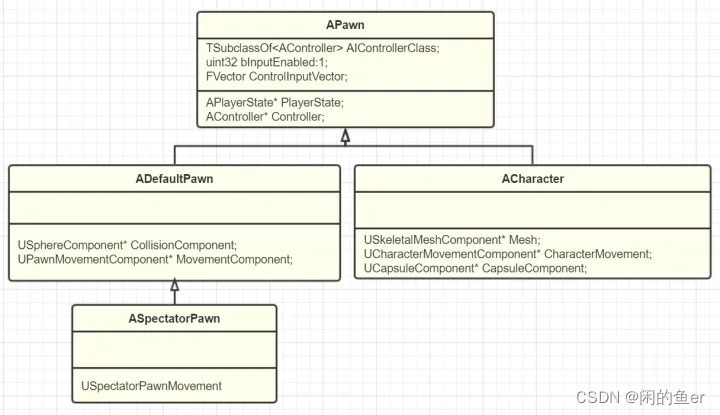
Pawn可移动,可被操纵,带物理碰撞
Character是个人形,带骨骼
Controller
Controller默认情况下1:1控制Pawn,但是想要多对多需要自己实现。
哪些数据应该放在PlayerState中?
从应用范围上来说,PlayerState表示的是玩家的游玩数据,所以那些关卡内的其他游戏数据就不应该放进来(GameState是个好选择),另外Controller本身运行需要的临时数据也不应该归PlayerState管理。而玩家在切换关卡的时候,APlayerState也会被释放掉,所有PlayerState实际上表达的是当前关卡的玩家得分等数据。这样,那些跨关卡的统计数据等就也不应该放进PlayerState里了,应该放在外面的GameInstance,然后用SaveGame保存起来。
Player,PlayerController,PlayerState
在任一刻,Player:PlayerController:PlayerState是1:1:1的关系。但是PlayerController可以有多个备选用来切换,PlayerState也可以相应多个切换。UPlayer可以简单理解为游戏里一个全局的玩家逻辑实体,而PlayerController代表的就是玩家的意志,PlayerState代表的是玩家的状态。
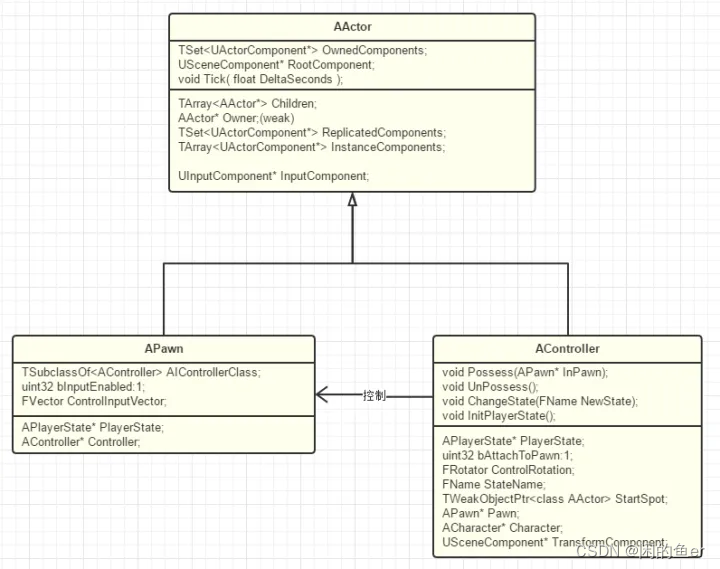
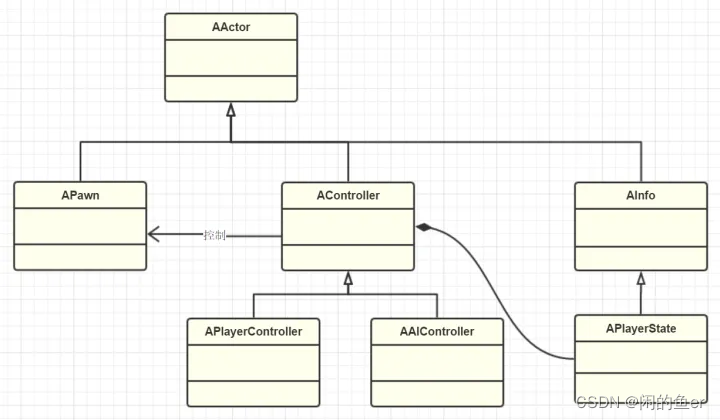
Actor,Pawn,Controller,Ainfo继承关系
UE4中tick函数中DeltaTime是什么?
距离上一帧调用过去了多久。
USceneComponent
USceneComponent提供了两大功能,一是Transform,二是SceneComponent的互相嵌套。
为何ActorComponent不能互相嵌套?而在SceneComponent一级才提供嵌套?
- 减少了被误用的机会,让你随便嵌套的组件模式可能会在使用上更容易出问题。
- 从功能上来说,UE更倾向于编写功能单一的Component(如UMovementComponent),而不是一个整合了其他Component的大管家Component
- 从游戏逻辑的实现来说,UE也是不推荐把游戏逻辑写在Component里面,所以你其实也没什么机会去写一个很复杂的Component。
ULevel架构图
来源
Level作为Actor的容器,同时也划分了World,一方面支持了Level的动态加载,另一方面也允许了团队的实时协作,大家可以同时并行编辑不同的Level。
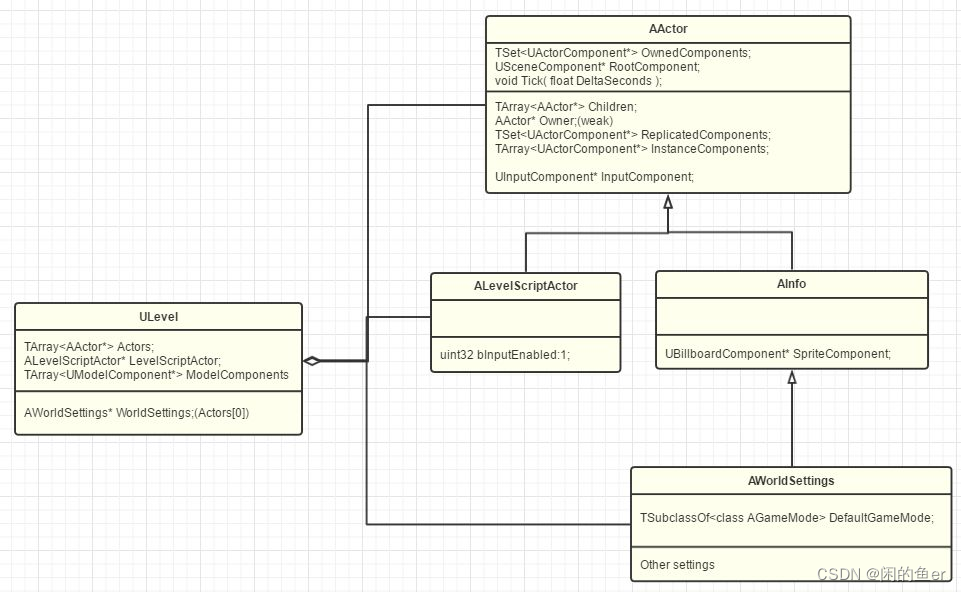
Actors们的排序依据是把那些“非网络”的Actor放在前面,而把“网络可复制”的Actor们放在后面,然后加一个起始索引标记iFirstNetRelevantActor,相当于为网络Actor划分了一个缓存,从而加速了网络复制时的检测速度。
UWorld
Persistent的意思是一开始就加载进World,Streaming是后续动态加载的意思。Levels里保存有所有的当前已经加载的Level,StreamingLevels保存整个World的Levels配置列表。PersistentLevel和CurrentLevel只是个快速引用。在编辑器里编辑的时候,CurrentLevel可以指向其他Level,但运行时CurrentLevel只能是指向PersistentLevel。
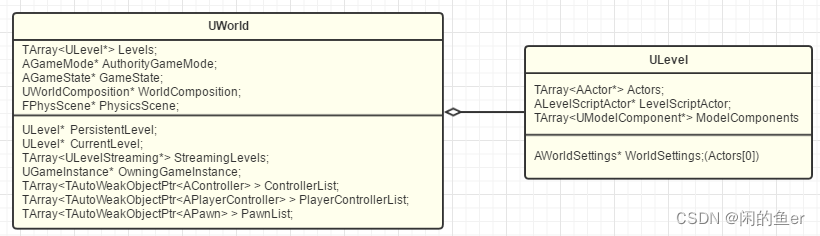
为什么要有PersistentLevel?
首先,World至少有一个Level,而且在多个level拼接进world中后,需要以Persistentlevel为主。
WorldContext
一个游戏中不只是有一个World,FWorldContext保存着ThisCurrentWorld来指向当前的World。而当需要从一个World切换到另一个World的时候(比如说当点击播放时,就是从Preview切换到PIE),FWorldContext就用来保存切换过程信息和目标World上下文信息,也负责Level之间切换的操作信息。
为什么要在Level里保存Actors,而不是把所有Map的Actors配置都生成在World一个总Actors里?
这肯定也是一种实现方式,好处是把整个World看成一个整体,所有的actors都从属于world,这样就不存在Level边界,可以更整体的处理Actors的作用范围和判定问题,实现上也少了拼接导航等步骤。当然坏处也是模糊了Level边界,这样在加载进一个Level之后,之后再动态释放,就需要再重新再从整体中抽离出部分来释放,这个筛选过程也会产生比较大的损耗。试着去理解UE的权衡,应该是尽量的把损耗平摊(这里是把Level加载释放的损耗尽量减小),才不会产生比较大的帧率波动,让玩家感觉到卡帧。
GameInstance
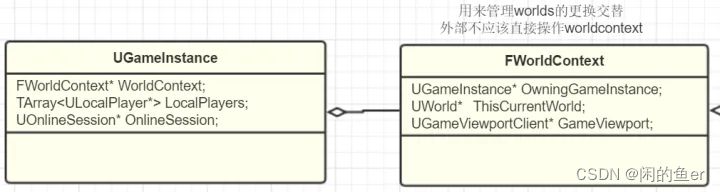
GameInstance里会保存着当前的WorldContext和其他整个游戏的信息。明白了GameInstance是比World更高的层次之后,独立于Level的逻辑或数据要在GameInstance中存储了。
UEngine
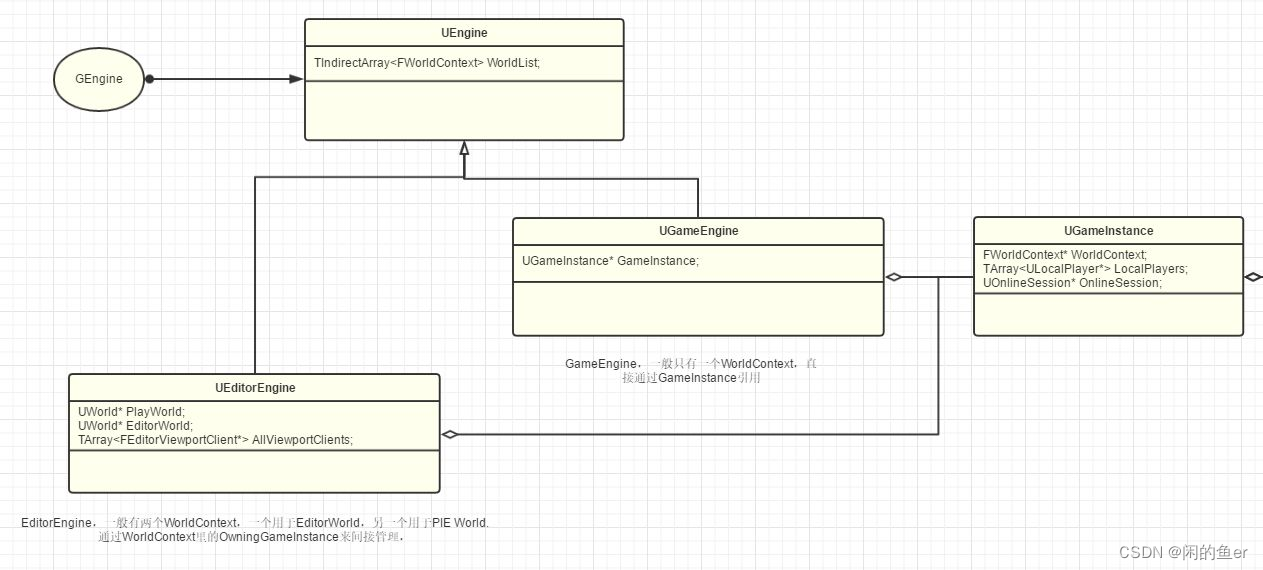
Object->Actor+Component->Level->World->WorldContext->GameInstance->Engine
GameMode与PlayerController和GameInstance比较
专注于游戏世界玩法。与LevelScript不同,LevelScript专注于本关卡内某些逻辑规则,比如改变Level内某些Actor的运动轨迹,或者某一个区域的重力,或者触发一段特效或动画。而GameMode应该专注于玩法,比如胜利条件,怪物刷新等。GameMode可以跨level,因此通用的玩法应该放在GameMode上面。
GameMode只在Server存在(单机游戏也是Server),对于已经连接上Server的Client来说,因为游戏的状态都是由Sever决定的,Client只是负责展示,所以Client上是没有GameMode的,但是有LevelScriptActor,所以GameMode里不要写Client特定相关的逻辑。
跟下层的PlayerController比较,GameMode关心的是构建一个游戏本身的玩法,PlayerController关心的玩家的行为。
跟上层的GameInstance比较,GameInstance关注的是更高层的不同World之间的逻辑,因此可以把不同GameMode之间协调的工作交给GameInstance,而GameMode只专注自己的玩法世界。
GameState
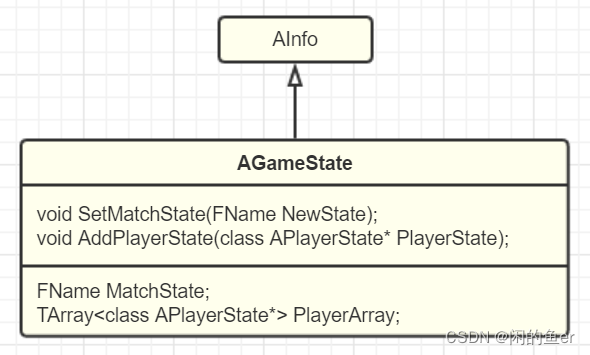
保存当前游戏的状态数据
UE4网络同步
大神链接
多人游戏里面需要把某个玩家操作的结果通知给其他玩家,这个通知的过程就是同步,再放到局域网或者广域网中进行,就是网络同步了。
中介转发
中介转发就是客户端/服务器模式(C/S),添加一个服务器作为中介节点,每台客户端只与服务器建立连接,客户端与客户端彼此独立,服务器负责转发消息。这种架构的复杂度仅为O(N),维护起来也方便。
帧同步与状态同步
帧同步是服务器将某个玩家的输入直接转发给其他玩家,自己不做处理。理论上所有客户端都以相同的初始状态开始,只要收到的输入相同,那么每时每刻的状态都会是相同的。
状态同步是服务器只同步影响游戏功能的某些重要状态变量,并且这些重要变量是在服务器运算出来的或者至少校验过的,客户端拿到这些状态变量后自行做本地的表现。
一般来说帧同步在实时性、节省流量方面比较好,状态同步则在安全性角度来说更胜一筹。具体选用哪种方案由具体游戏类型来决定,UE是在射击游戏基础上发展而来的,它默认的网络同步方案是状态同步,把决策权放在服务器上做,可以有效减少外挂,对于中途加入/断线重连也能天然支持。
采用帧同步的例子:RTS游戏,例如帝国时代、星际争霸、魔兽争霸。MOBA手游王者荣耀(手机网络没有PC稳定),动作游戏
采用状态同步的例子:各类FPS游戏,DOTA和LOL,大型MMORPG(帧同步需要追帧,而MMORPG可能都运行一个月了)。
状态同步的优势:
- 预表现容易,对弱网络的适应能力更强,因为客户端可以直接通过调解(Reconciliation)本地和服务端状态进行平滑和Roll-Forth;而帧同步需要做序列化和反序列化;
- 重连容易,因为直接下发实时状态即可;而帧同步需要追帧;
- 重播容易,因为下发历史状态即可;而帧同步需要追帧;
- 外挂影响小,一般最多是透视挂和开图挂,但服务端可以进行一定的视野剔除;而帧同步客户端拥有所有信息,外挂影响会比较严重;
- 第三方库支持更好,因为对于帧同步第三方库也要确保确定性。
状态同步的缺点:
- 流量较高,取决于客户端可观察到的网络实体数目;而帧同步取决于玩家数目。所以录像也相应更大。
- 开发效率不及帧同步;
- 打击感不及帧同步,因为帧同步在本地运算的确定性,确保各种反馈,包括结算、特效、音效等能在准确的时刻产生。
RPC
RPC (远程过程调用)是在本地调用但在其他机器(不同于执行调用的机器)上远程执行的函数。RPC 函数非常有用,可允许客户端或服务器通过网络连接相互发送消息。
这些功能的主要作用是执行那些不可靠的暂时性/修饰性游戏事件。这其中包括播放声音、生成粒子或产生其他临时效果之类的事件,它们对于 Actor 的正常运作并不重要。在此之前,这些类型的事件往往要通过 Actor 属性进行复制。
UE4中的服务器与客户端
Listen Server:方便进行局域网本地游戏,在本地机器上搭建服务器,此时本地机器既是服务器又是客户端。其接受远程客户端中的连接,且直接在服务器上拥有本地玩家。此模式通常用于临时合作和竞技多人游戏。
Dedicated Server:独立服务器,在独立服务器上则不执行渲染任务,只承担服务器的相关职责。其接受远程客户端中的连接,但无本地玩家,因此为了高效运行,其将废弃图形、音效、输入和其他面向玩家的功能。此模式常用于需要更固定、安全和大型多人功能的游戏。此类游戏包括MMO、竞技MOBA,或快节奏网络射击游戏。
服务器是多人游戏实际发生的地方。客户端会远程控制其在服务器上各自拥有的 Pawn,发送过程调用以使其执行游戏操作。但服务器不会将视觉效果直接流送至客户端显示器。服务器会将游戏状态信息复制到各客户端,告知应存在的Actor、此类Actor的行为,以及不同变量应拥有的值。然后各客户端使用此信息,对服务器上正在发生的情况进行高度模拟。
服务器是多人游戏实际发生的地方。客户端会远程控制其在服务器上各自拥有的 Pawn,发送过程调用以使其执行游戏操作。但服务器不会将视觉效果直接流送至客户端显示器。服务器会将游戏状态信息复制到各客户端,告知应存在的Actor、此类Actor的行为,以及不同变量应拥有的值。然后各客户端使用此信息,对服务器上正在发生的情况进行高度模拟。
服务器需要选择性地向各客户端发送信息,游戏编程时须指定要复制的信息和接收副本的机器。主要的难点在于选择应复制的信息及方式,以向所有玩家提供一致的游戏体验,同时需最小化信息复制量,尽可能减少网络带宽占用率。
游戏状态和流程一般是通过 GameMode 这一 actor 来驱动。只有服务器才包含此 actor 的有效复本(客户端不包含复本)。要向客户端传达该状态,可以使用 GameState actor 显示 GameMode actor 的重要状态。这个 GameState actor 被标记为复制到每个客户端。客户端将包含此 GameState actor 的一个近似复本,而且能使用这个 actor 作为引用,用于了解游戏的一般状态。
UE4中的服务器与客户端连接过程
1.客户端发送连接请求。
2.如果服务器接受连接,则发送当前地图。
3.服务器等待客户端加载此地图。
4.加载之后,服务器将在本地调用AGameModeBase::PreLogin。这样可以使 GameMode 有机会拒绝连接
5.如果接受连接,服务器将调用AGameModeBase::Login。该函数的作用是创建一个 PlayerController,可用于在今后复制到新连接的客户端。成功接收后,这个 PlayerController 将替代客户端的临时PlayerController (之前被用作连接过程中的占位符)。此时将调用APlayerController::BeginPlay。应当注意的是,在此 actor 上调用 RPC 函数尚存在安全风险。您应当等待AGameModeBase::PostLogin 被调用完成 。
6.如果一切顺利,AGameModeBase::PostLogin将被调用。这时,可以放心的让服务器在此 PlayerController 上开始调用 RPC 函数。
越好的网络环境和网络模型,客户端的游戏状态会越接近服务器。
客户端之间是没有直接连接的,必须通过服务器来进行客户端之间的交互,即:如果没有服务器告知,客户端之间是不知道互相之间的存在的。
游戏信息只准从服务器向客户端同步,客户端不能向服务器同步,就算客户端发信息给服务器,服务器也当成垃圾丢掉。
客户端向服务器发信息的方式只有调用RPC中的Server函数一种形式。
骨骼动画
以下骨骼动画内容来源
骨骼动画(Skeletal Animation) 是模型动画中的一种,通过改变骨骼的朝向和位置来为模型生成动画。模型(Model)由一个个三角面组成,这种三角面也被称为网格(Mesh),网格上有一个个顶点(Vertex) 。网格(Mesh)也被称作皮肤(Skin);骨骼之间的连接处称作关节(Joints),骨骼可以绕着关节旋转。
骨骼动画制作
在关键帧编辑骨骼姿态,在非关键帧插值骨骼姿态,在所有帧上进行蒙皮。
- 骨骼与标准姿势(T-pose)的绑定与蒙皮(binding, skinning)
- 动画师操作骨骼,制作关键帧(keyframe)
- 关键帧之间的插值形成整个动画
插值方法
直接插值关节坐标。这在动作幅度小的时候问题不大,但是如果动作幅度大,不同的关节的运动速度是不同的,很容易插值出不自然的结果。
- 正向运动学:插值变换矩阵。
- 插值部分关节坐标,其余的对逐帧进行逆向运动学的解算。
线性混合蒙皮
每个骨骼上会储存一个变换矩阵(变换矩阵就是从 关节坐标系 到 世界坐标系 的 平移、旋转、缩放矩阵的乘积,关节坐标系是以某个关节为原点的坐标系)
我们假设对这个顶点有影响的 骨骼 i 的 权重 为 w[i] 、变换矩阵为 M[i]、在 T-Pose 下的坐标为 V,那最后混合后的世界坐标 就为 sum(V * w[i] * M[i]),其中所有对其有影响的骨骼的权重之和为 1 。(其实这个公式就是按各个骨骼的权重比例转换,实际上是对每个骨骼的变换矩阵进行插值)。计算关节坐标系需要利用正向运动学计算变换矩阵。
正向动力学
我们有了每个节点 相对父节点 的 小变换矩阵,从 关节坐标系 到 世界坐标系 的最终 变换矩阵 就由这一个个小变换矩阵累积获得,这个求解最终 变换矩阵 过程也就是 正向动力学 的本质。实际上,每个节点的这个最终 变换矩阵 也就是从 根节点 到 该节点 路径上,每个 小变换矩阵 的乘积。
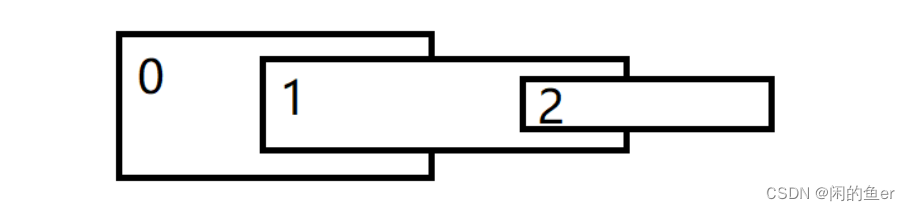
设骨骼 i 的 小变换矩阵 为 m[i],特别的,根节点的变换矩阵设为 O,那显然对上图:M[0] = O、M[1] = m[1]* O、M[2] = m[2] * m[1] * O = M[1] * O,显然可以通过在树上进行一次遍历求得。
现在我们要插值非关键帧,除了插值关节的坐标,我们还可以插值每个骨骼的变换矩阵,从而得到平滑的结果。
平移矩阵和缩放矩阵可以简单的通过线性插值得到,但是旋转矩阵不可以。
姿态调整

对于关节树,给定末端的 关节坐标 ,怎么获得每个关节的坐标,从下往上 逆向 求解,就是 逆向动力学 的本质。
逆向动力学的解决方案一般是 CCD(Cyclic Coordinate Descent) 或 CAA(Circular Alignment Algorithm) 等。
CCD(循环坐标下降算法)
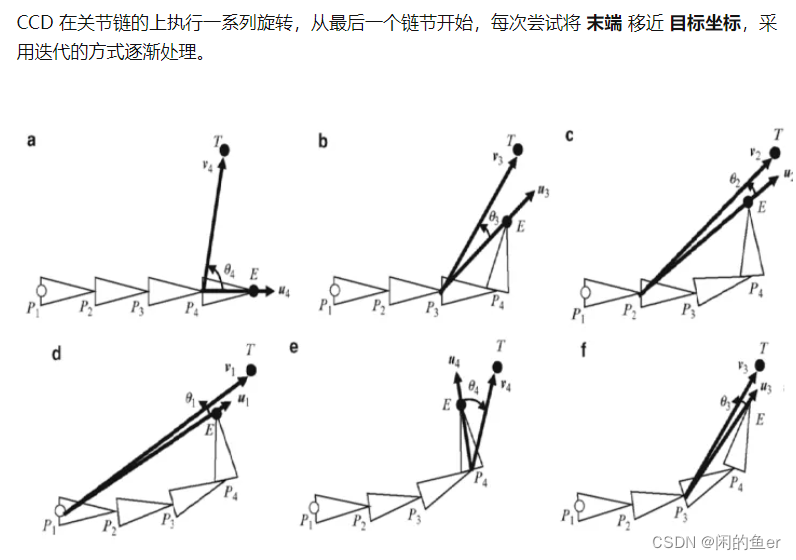
CCD的缺点:
- 一组关节的物理系统一般有 关节角度约束 等物理限制,在解决 逆向动力学 的时候需要考虑到这些限制。CCD 算法可以生成可能违反关节角度约束 的大角度旋转。
- 在某些情况下,特别是当靠近目标坐标时,CCD 算法会导致一条链形成循环 与自身相交。
- 在某些情况下,CCD 可能会进行大量迭代,导致末端缓慢的 锯齿形运动。
CAA(圆形对齐算法)
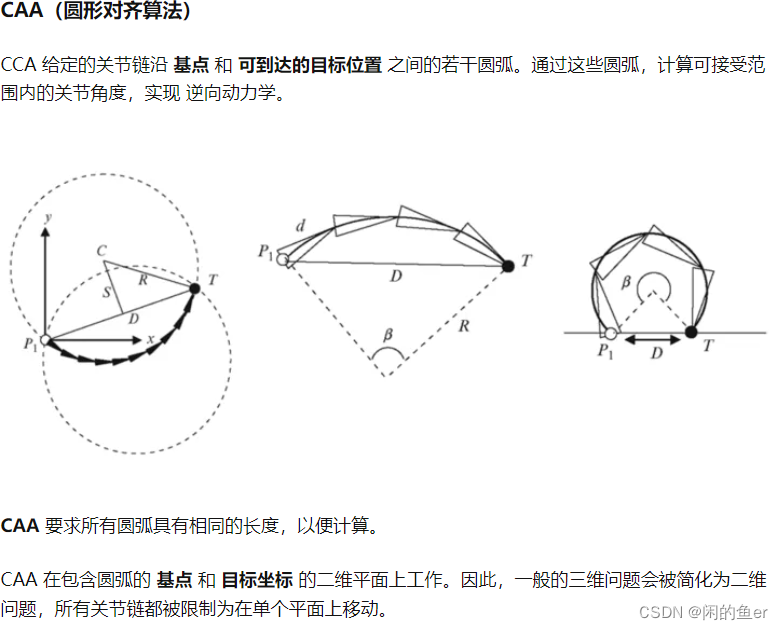
一个服务器中有个tick函数,每次固定加1/30秒,不考虑帧率波动会出现问题吗?
会,这种情况一个大的float加一个很小的正float,首先进行阶码对齐,然后正常增加,可能出现结果比两个数还小的情况。
顶点动画的缺陷
- 随着顶点的增加,计算量会增加很多。
- 可能得到不符合物理模型的结果。
操作系统
用户态和内核态
- 内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
- 用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
- 内核在创建线程的时候,会为线程创建相应的堆栈。每个线程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当线程在用户空间运行时,CPU堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当线程在内核空间时,CPU堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
用户态线程
来源
另一个来源
用户态线程也称作用户级线程(User LevelThread)。操作系统内核并不知道它的存在,它完全是在用户空间中创建。用户级线程有很多优势,比如:
- 管理开销小:创建、销毁不需要系统调用
- 切换成本低:用户空间程序可以自己维护,不需要走操作系统调度。
但是这种线程也有很多的缺点: - 与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行I/O的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
- 线程间协作成本高:设想两个线程需要通信,通信需要I/O,I/O需要系统调用,因此用户态线程需要支付额外的系统调用成本。
- 无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
- 操作系统无法针对线程调度进行优化:当一个进程的一个用户态线程阻塞(Block)了,操作系统无法及时发现和处理阻塞问题,它不会更换执行其他线程,从而造成资源浪费。
内核态线程
内核态线程也称作内核级线程(Kernel LevelThread)。这种线程执行在内核态,可以通过系统调用创造一个内核级线程。内核级线程有很多优势:
可以利用多核CPU优势:
- 内核拥有较高权限,因此可以在多个CPU核心上执行内核线程。
- 操作系统级优化:内核中的线程操作I/O不需要进行系统调用;一个内核线程阻塞了,可以立即让另一个执行。
内核线程也有一些缺点:
- 创建成本高:创建的时候需要系统调用,也就是切换到内核态。
- 扩展性差:由一个内核程序管理,不可能数量太多。
- 切换成本较高:切换的时候,也同样存在需要内核操作,需要切换内核态。
用户态线程与内核态线程间的映射关系
用户态线程创建成本低,问题明显,不可以利用多核。内核态线程,创建成本高,可以利用多核,切换速度慢。因此通常我们会在内核中预先创建一些线程,并反复利用这些线程。
- 多对一:用户态进程中的多线程复用一个内核态线程。这样,极大地减少了创建内核态线程的成本,但是线程不可以并发。
- 一对一:这种模型允许所有线程并发执行,能够充分利用多核优势,Windows NT内核采取的就是这种模型。但是因为线程较多,对内核调度的压力会明显增加。
- 多对多:减少了内核线程,同时也保证了多核心并发。Linux目前采用的就是该模型。
- 上述几种的混合:这种模型混合了多对多和一对一的特点。多数用户态线程和内核线程是n对m的关系,少量用户线程可以指定成1对1的关系。
用户态切换到内核态(系统调用)
他们的工作流程如下:
- 用户态程序将一些数据值放在寄存器中, 或者使用参数创建一个堆栈(stack frame), 以此表明需要操作系统提供的服务.
- 用户态程序执行陷阱指令
- CPU切换到内核态, 并跳到位于内存指定位置的指令, 这些指令是操作系统的一部分, 他们具有内存保护, 不可被用户态程序访问
- 这些指令称之为陷阱(trap)或者系统调用处理器(system call handler). 他们会读取程序放入内存的数据参数, 并执行程序请求的服务
- 系统调用完成后, 操作系统会重置CPU为用户态并返回系统调用的结果
进程和线程基本概念
- 进程是具有独立功能的程序在某个数据集合上的一次执行过程。进程是系统进行资源分配和调度的一个独立单位。
- 线程,又称为轻量级的进程,是CPU使用的基本单元,是进程内的一个执行实体或执行单元,是被系统独立调度和分配的基本单元。由线程ID、程序计数器、寄存器集合和堆栈组成。它与属于同一进程的其他线程共享其代码段、数据段和其他操作系统资源(如打开文件和信号)。线程有,新建,就绪,运行,阻塞状态。
- 在现代操作系统中,资源申请的基本单位是进程,进程由程序段、数据段和PCB(进程控制块)组成。
进程状态与切换



线程从运行态到阻塞态,操作系统做了什么?
当发生系统调用时,用户态的程序发起系统调用。因为系统调用中牵扯特权指令,用户态程序权限不足,因此会中断执行,也就是Trap(Trap是一种中断)。发生中断后,当前CPU执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。内核处理完成后,主动触发Trap,这样会再次发生中断,切换回用户态工作。
进程与线程的区别?

同一个进程下的不同线程,栈和堆是公有还是私有?
栈私有,堆公有。
并发和并行的区别
- 并发(concurrency):把任务在不同的时间点交给处理器进行处理。在同一时间点,任务并不会同时运行。
- 并行(parallelism):把每一个任务分配给每一个处理器独立完成。在同一时间点,任务一定是同时运行。
并发不是并行。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
死锁是什么?
以下多线程问题出自于
多个进程或线程为了抢夺共享资源,导致每个线程或进程都不能获得需要的全部资源,从而程序无法向下执行下去的现象。

产生死锁的四个必要条件?
互斥(同一个资源在同一时间只能被一个进程或线程使用)
不剥夺(进程或线程已经获得的资源,不会被剥夺)
请求与保持(已经申请到的资源不会释放)
循环等待(形成环状的资源等待状态)

死锁预防
破坏产生死锁的四个必要条件(完全不会出现死锁 )。死锁预防的条件更严格,实现简单,但是会导致资源利用率低,效率低。
死锁避免
对分配资源做安全性检查,确保不会产生循环等待。
- 系统安全状态
- 银行家算法(Max[i][j]进程i对j类资源的最大需求书,Allocation[i][j]已经分配给进程i的j类资源数,Need[i][j]进程i还需要的j类资源数,Need = Max - Allocation。)
//Request是进程的请求向量
if (Request[j] <= Need[i][j])
{
if (Request[j] <= Available[j])
{
Available = Available - Request;
Allocation[i][j] = Allocation[i][j] + Request[j];
Need[i][j] = Need[i][j] - Request[j];
if (!isSafe())//系统处于不安全状态
{//放弃本次分配,恢复原来的资源状态,让进程i等待
}
}
}
死锁检测
允许死锁的发生,但提供检测方法。当前的资源分配图如果是不可简化的那么就处于死锁状态(死锁定理)。

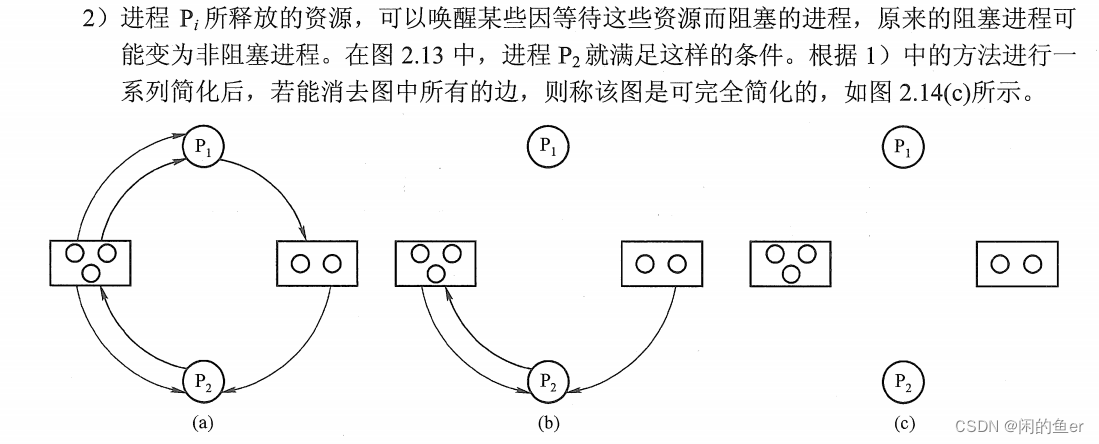
死锁解除
已经产生了死锁,强制剥夺资源或者撤销进程。

同步与互斥
同步就是只有任务A执行完才能执行任务B。
互斥就是资源在同一时刻只能被一个进程/线程使用。
临界区、信号量、互斥量
三者都可用来进行进程的同步与互斥;
- 临界区:用于同一进程下的不同线程,但是不能用于不同进程中的不同线程,临界区保证同一段代码只被一个线程执行。
- 信号量:可以让多个线程同一时刻访问共享资源,进行线程的计数,确保同时访问资源的线程数目不超过上限,当访问数超过上限后,不发出信号量。(PV操作)
- 互斥量(锁)
互斥量(锁)的种类
- 互斥锁(加锁资源支持互斥访问),互斥锁是一种sleeping waiting类型,如果锁被其他线程持有,那么就释放CPU资源,加入阻塞队列。需要进行上下文的切换、CPU抢占等。
- 读写锁(对共享资源的访问者划分为读者和写者,多个读者可以同时读,但只有一个写者可以改)。shared_mutex通过lock_shared,unlock_shared进行读者的锁定与解锁;通过lock,unlock进行写者的锁定与解锁。
shared_mutex s_m;
std::string book;
void read()
{
s_m.lock_shared();
cout << book;
s_m.unlock_shared();
}
void write()
{
s_m.lock();
book = "new context";
s_m.unlock();
}
- 自旋锁属于busy waiting类型,会一直占用CPU,但是效率高于互斥锁(如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁;自旋锁比较适用于锁使用者保持锁时间比较短的情况。)
lock_guard
由于程序员可能忘记unlock,通过与智能指针一致的思路,将互斥量用对象包裹,在构造函数中lock,在析构函数中unlock。因此可以通过{}调整作用域来调整临界区代码。使用lock_guard不能手动lock, unlock。
mutex Mutex;
lock_guard<mutex> a(Mutex);
unique_lock
类似于lock_guard,但是可以手动lock,unlock。与unique_ptr一致,unique_lock是所有权类型。
unique_lock<mutex> g2(m,defer_lock);
unique_lock<mutex> g3(move(g2));//所有权转移,此时由g3来管理互斥量m
条件变量
需要#include<condition_variable>std::condition_variable类搭配std::mutex类来使用,std::condition_variable对象(std::condition_variable cond;)的作用不是用来管理互斥量的,它的作用是用来同步线程,它的用法相当于编程中常见的flag标志(A、B两个人约定flag=true为行动号角,默认flag为false,A不断的检查flag的值,只要B将flag修改为true,A就开始行动)。类比到std::condition_variable,A、B两个人约定notify_one为行动号角,A就等着(调用wait(),阻塞),只要B一调用notify_one,A就开始行动(不再阻塞)。
为防止两个进程同时进入临界区,同步机制应当遵循的准则

实现临界区互斥访问的方法
1.软件方法:
- 单标志法(必须交替进入,否则就无法进入临界区,假设p0进入后p1没有进入临界区,那p0也无法再进入临界区)
- 双标志位先检查

- 双标志位后检查

- 皮特森算法

2.硬件方法: - 中断屏蔽方法(切换进程时需要发生中断,把中断屏蔽了就不能切换了)
- 硬件指令方法(硬件原子指令)
原子操作
原子操作指“不可分割的操作”,也就是说这种操作状态要么是完成的,要么是没完成的,不存在“操作完成了一半”这种状况。automic<>模板使用该模板类实例化的对象,提供了一些保证原子性的成员函数来实现共享数据的常用操作。
std::atomic<>对象提供了常见的原子操作(通过调用成员函数实现对数据的原子操作): store是原子写操作,load是原子读操作。exchange是于两个数值进行交换的原子操作。 即使使用了std::atomic<>,也要注意执行的操作是否支持原子性,也就是说,你不要觉得用的是具有原子性的变量(准确说是对象)就可以为所欲为了,你对它进行的运算不支持原子性的话,也不能实现其原子效果。
线程池
为了减少创建与销毁线程所带来的时间消耗与资源消耗,因此采用线程池的策略:
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。接收到任务后,任务被挂在任务队列,线程池选择一个空闲线程来执行此任务。任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。
生产者消费者问题
#include<iostream>
#include<thread>
#include<mutex>
#include<queue>
#include<condition_variable>
using namespace std;
//缓冲区存储的数据类型
struct CacheData
{
//商品id
int id;
//商品属性
string data;
};
queue<CacheData> Q;
//缓冲区最大空间
const int MAX_CACHEDATA_LENGTH = 10;
//互斥量,生产者之间,消费者之间,生产者和消费者之间,同时都只能一个线程访问缓冲区
mutex m;
condition_variable condConsumer;
condition_variable condProducer;
//全局商品id
int ID = 1;
//消费者动作
void ConsumerActor()
{
unique_lock<mutex> lockerConsumer(m);
cout << "[" << this_thread::get_id() << "] 获取了锁" << endl;
while (Q.empty())
{
cout << "因为队列为空,所以消费者Sleep" << endl;
cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl;
//队列空, 消费者停止,等待生产者唤醒
condConsumer.wait(lockerConsumer);
cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl;
}
cout << "[" << this_thread::get_id() << "] ";
CacheData temp = Q.front();
cout << "- ID:" << temp.id << " Data:" << temp.data << endl;
Q.pop();
condProducer.notify_one();
cout << "[" << this_thread::get_id() << "] 释放了锁" << endl;
}
//生产者动作
void ProducerActor()
{
unique_lock<mutex> lockerProducer(m);
cout << "[" << this_thread::get_id() << "] 获取了锁" << endl;
while (Q.size() > MAX_CACHEDATA_LENGTH)
{
cout << "因为队列为满,所以生产者Sleep" << endl;
cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl;
//对列慢,生产者停止,等待消费者唤醒
condProducer.wait(lockerProducer);
cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl;
}
cout << "[" << this_thread::get_id() << "] ";
CacheData temp;
temp.id = ID++;
temp.data = "*****";
cout << "+ ID:" << temp.id << " Data:" << temp.data << endl;
Q.push(temp);
condConsumer.notify_one();
cout << "[" << this_thread::get_id() << "] 释放了锁" << endl;
}
//消费者
void ConsumerTask()
{
while(1)
{
ConsumerActor();
}
}
//生产者
void ProducerTask()
{
while(1)
{
ProducerActor();
}
}
//管理线程的函数
void Dispatch(int ConsumerNum, int ProducerNum)
{
vector<thread> thsC;
for (int i = 0; i < ConsumerNum; ++i)
{
thsC.push_back(thread(ConsumerTask));
}
vector<thread> thsP;
for (int j = 0; j < ProducerNum; ++j)
{
thsP.push_back(thread(ProducerTask));
}
for (int i = 0; i < ConsumerNum; ++i)
{
if (thsC[i].joinable())
{
thsC[i].join();
}
}
for (int j = 0; j < ProducerNum; ++j)
{
if (thsP[j].joinable())
{
thsP[j].join();
}
}
}
int main()
{
//一个消费者线程,5个生产者线程,则生产者经常要等待消费者
Dispatch(1,5);
return 0;
}
为什么使用虚拟内存?
- 物理内存不限制读写特性,使用虚拟内存可以限制读写特性,保证读写安全。
- 保证各进程之间有独立的地址空间,一个进程无法修改其他进程的内容。
- 利用局部性原理,从逻辑上扩大了内存,提高了内存的利用率。
地址变换逻辑
先查快表,若找到要访问的页,则修改页表项中的访问位(写指令还需要重置修改位),然后利用页表项中给出的物理块号和页内地址形成物理地址。
若未找到该页的页表项,则应到内存中去查找页表,再对比页表项中的状态位P,看该页是否已调入内存,未调入则产生缺页中断,请求从外存把该页调入内存。
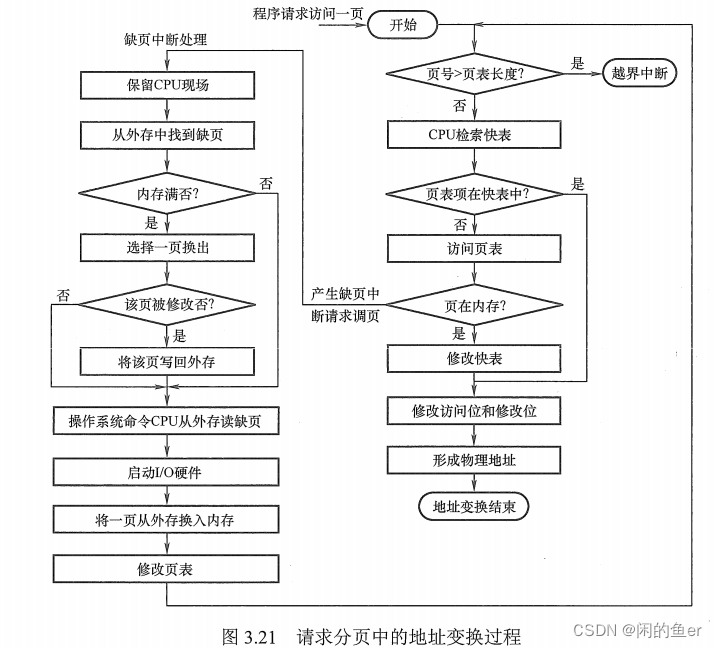
页面置换算法
- OPT(最佳置换算法):理论算法,被淘汰页面以后永远不再使用。
- 先进先出:还会产生所分配的物理块数增大而页故障数不减反增的异常现象,称为Belady异常。
- LRU:性能接近OPT,但是实现困难,开销大。
- CLOCK算法:当需要替换一页时,操作系统扫描缓冲区,以查找使用位被置为0的一帧。每当遇到一个使用位为1的帧时,操作系统就将该位重新置为0;若在这个过程开始时,缓冲区中所有帧的使用位均为0,则选择遇到的第一个帧替换;若所有帧的使用位均为1,则指针在缓冲区中完整地循环一周,把所有使用位都置为0,并停留在最初的位置上,替换该帧中的页。
- 改进版CLOCK算法

改进型CLOCK算法优于简单CLOCK算法的地方
改进型CLOCK算法优于简单CLOCK算法的地方在于替换时首选没有变化的页。由于修改过的页在被替换之前必须写回,因而这样做会节省时间。
Clock算法和Clock改进型都是为了以更小的开销接近LRU的性能。
虚拟地址翻译为物理地址过程
查找顺序是从TLB到页表(TLB不命中),查页表之后如果页面不再主存中则产生缺页中断,查到物理地址以后先去Cache,不在Cache中去查主存,最后到外存。

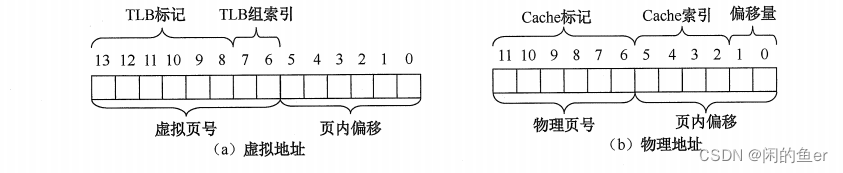

内存分配管理方式
- 页式:逻辑地址由页号和页内偏移组成。页表中存储了页号对应的物理块号,物理地址块和页内偏移结合起来组成物理地址。为了加快查询页表的速度,在地址变换机构中增设一个具有并行查找能力的高速缓冲存储器——快表,又称相联存储器(TLB),用来存放当前访问的若干页表项,以加速地址变换的过程。
- 段式:逻辑地址有段号和段内偏移组成。

- 段页式:

数据结构
十大排序的复杂度
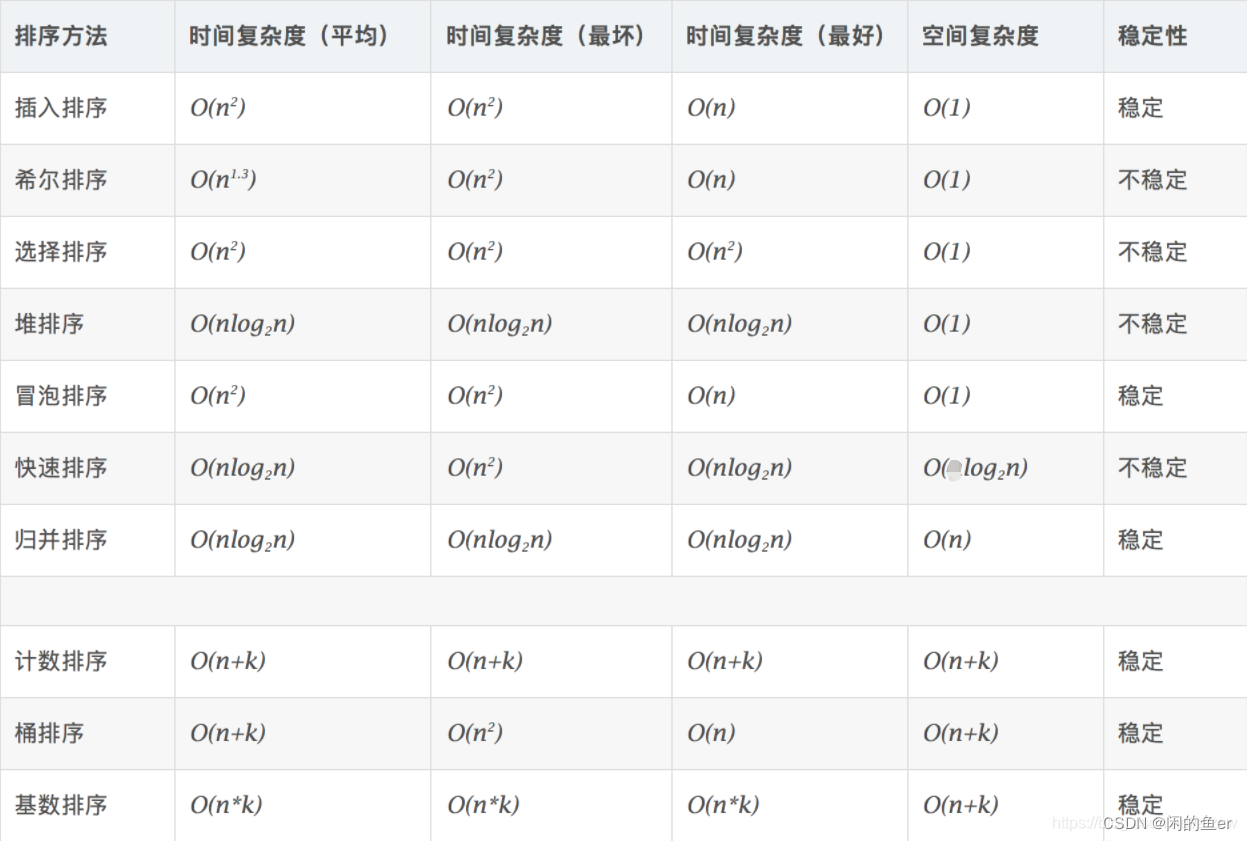
为什么快速排序在实际应用中比堆排序快?
堆排序访问数据的方式没有快速排序友好,快速排序Cache命中率更高。对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。
对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。建堆可能会把原来有序的数据变得更加无序了。
归并排序应用场景

快速排序应用场景
数据大且初始状态杂乱的场景。
KMP算法
模式匹配算法,在主串s中寻找t的过程,在KMP算法中主串中的字符只匹配一次,需要维护next数组,next数组中的值只与子串有关。next数组的含义就是每个子串的最长前缀与最长后缀的相同长度。假设我们的子串为ababaca,那么我们对其进行分析。
ababaca,长度是7,所以next[0],next[1],next[2],next[3],next[4],next[5],next[6]分别计算的是a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀的长度。它们的相同的最长前缀和最长后缀分别是0,0,a,ab,aba,0,a。(注意,最长前缀不包括最后一个字符) 所以next数组的值是[0,0,1,2,3,0,1]。
常见的垃圾回收算法
- 引用计数法:基于引用计数器的垃圾收集器运行较快,不会长时间中断程序执行,适宜必须实时运行的程序。但引用计数器增加了程序执行的开销,因为每次对象赋给新的变量,计数器加1,而每次现有对象超出了作用域,计数器减1。
- 标记-清除算法:标记-清除算法分为“标记”和“清除”两个阶段,首先通过可达性分析,标记出所有需要回收的对象,然后统一回收所有被标记的对象。
标记-清除算法有两个缺陷,一个是效率问题,标记和清除的过程效率都不高,另外一个就是,清除结束后会造成大量的碎片空间。有可能会造成在申请大块内存的时候因为没有足够的连续空间导致再次GC。 - 复制算法 :为了解决碎片空间的问题,出现了“复制算法”。复制算法的原理是,将内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上。然后将然后再把已使用的内存整个清理掉。
缺点:因为每次在申请内存时,都只能使用一半的内存空间。内存利用率严重不足。 - 标记-整理算法:复制算法在 GC 之后存活对象较少的情况下效率比较高,但如果存活对象比较多时,会执行较多的复制操作,效率就会下降。而老年代的对象在 GC 之后的存活率就比较高,所以就有人提出了“标记-整理算法”。
标记-整理算法的“标记”过程与“标记-清除算法”的标记过程一致,但标记之后不会直接清理。而是将所有存活对象都移动到内存的一端。移动结束后直接清理掉剩余部分。 - 分代收集算法:在程序设计中有这样的规律:多数对象存在的时间比较短,少数的存在时间比较长。因此, generation算法将堆分成两个或多个,每个子堆作为对象的一代 (generation) 。由于多数对象存在的时间比较短,随着程序丢弃不使用的对象,垃圾收集器将从最年轻的子堆中收集这些对象。在分代式的垃圾收集器运行后,上次运行存活下来的对象移到下一最高代的子堆中,由于老一代的子堆不会经常被回收,因而节省了时间。
计算机网络
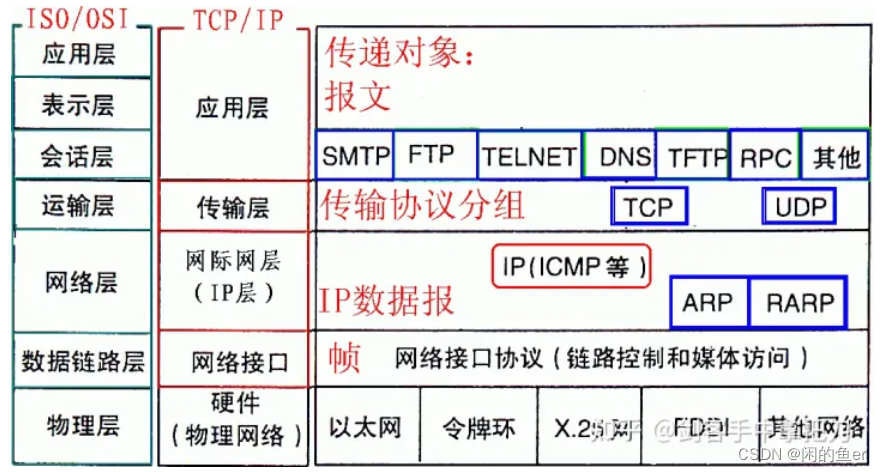
计算机网络体系结构
TCP会对报文段进行重传的事件
- 超时:TCP每发送一个报文段,就对这个报文段设置一次计时器。计时器设置的重传时间到期但还未收到确认时,就要重传这一报文段。
- 冗余ACK:超时触发重传存在的一个问题是超时周期往往太长。冗余ACK就是如果对一个数据包的ACK超过了3次,那么就认为该报文段已丢失,重传该报文段。
TCP流量控制
TCP提供流量控制服务来消除发送方使接收方缓存区溢出的可能性,因此可以说流量控制是一个速度匹配服务(匹配发送方的发送速率与接收方的读取速率)。
在通信过程中,接收方根据自己接收缓存的大小,动态地调整发送方的发送窗口大小,这称为接收窗口rwnd,即调整TCP报文段首部中的“窗口”字段值,来限制发送方向网络注入报文的速率。同时,发送方根据其对当前网络拥塞程序的估计而确定的窗口值,这称为拥塞窗口cwnd(后面会讲到),其大小与网络的带宽和时延密切相关。
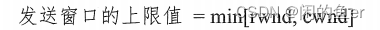
TCP拥塞控制
所谓拥塞控制,是指防止过多的数据注入网络,保证网络中的路由器或链路不致过载。出现拥塞时,端点并不了解到拥塞发生的细节,对通信连接的端点来说,拥塞往往表现为通信时延的增加。当然,拥塞控制和流量控制也有相似的地方,即它们都通过控制发送方发送数据的速率来达到控制效果。

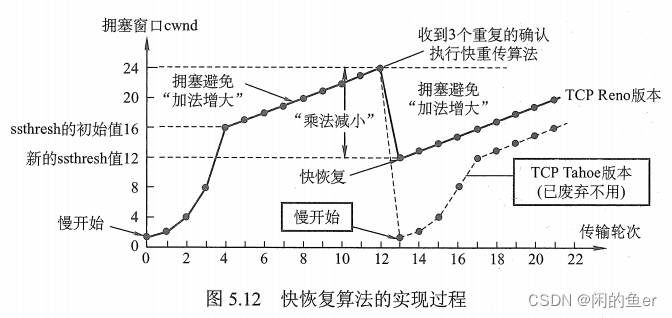
控制拥塞窗口的算法
超时时使用慢开始和拥塞避免。
- 慢开始:初始cwnd大小为1(MSS,最大报文段长度),每经历一个往返时延RTT,就翻倍cwnd,直到达到门限值,然后改用拥塞避免算法。
- 拥塞避免:每经过一个RTT就增加一个MSS大小,当出现一次超时,令门限值为当前cwnd的一半。
网络出现拥塞时,无论是在慢开始阶段还是在拥塞避免阶段,只要发送方检测到超时事件的发生(未按时收到确认,重传计时器超时),就要把慢开始门限ssthresh 设置为出现拥塞时的发送方的cwnd值的一半(但不能小于2)。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。这样做的目的是迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完。
收到冗余ACK时使用快重传和快回复。 - 快重传:当发送方连续收到三个重复的ACK报文时,直接重传对方尚未收到的报文段,而不必等待那个报文段设置的重传计时器超时。
- 快回复:发送端收到连续三个冗余ACK(即重复确认)时,执行“乘法减小”算法,把慢开始门限 ssthresh 设置为出现拥塞时发送方cwnd 的一半。与慢开始(慢开始算法将拥塞窗口cwnd设置为1)的不同之处是,它把 cwnd 的值设置为慢开始门限ssthresh 改变后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
TCP粘包问题
以下粘包问题出自
客户端发送的多个数据包被当做一个数据包接收。也称数据的无边界性,read()/recv() 函数不知道数据包的开始或结束标志(实际上也没有任何开始或结束标志),只把它们当做连续的数据流来处理。
TCP是一个面向字节流的传输层协议。“流” 意味着 TCP 所传输的数据是没有边界的。
TCP粘包、拆包问题发生原因
- 应用进程写入的数据量大于TCP发送缓冲区的大小,这将会发生拆包。
- 应用进程写入的数据量小于TCP发送缓冲区的大小,这将会发生粘包。
- 当应用进程发送的数据包大于 MSS(最大报文段长度)时,将会发生拆包。
- 接收方不及时读取接收缓冲区中的数据,将会发生粘包。
什么时候不需要考虑粘包、拆包问题?
- 如果 TCP 是短连接,即只进行一次数据通信过程,通信完成就关闭连接,这样就不会出现粘包问题。
- 如果传输的是字符串、文件等无结构化数据时,也不会出现粘包问题。因为发送方只管发送,接收方只管接收存储就行了。
粘包、拆包问题解决方案?
- 发送定长包。即发送端将每个数据包封装为固定长度(长度不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。(适合定长结构的数据)
- 包头加上包体长度。发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便可以知道每一个数据包的实际长度了。(适合不定长结构的数据)
- 在包尾部设置边界标记。发送端在每个数据包尾部添加边界标记,可以使用特殊符号作为边界标记。如此,接收端通过这个边界标记就可以将不同的数据包拆分开来。但这可能会存在一个问题:如果数据包内容中也包含有边界标记,则会被误判为消息的边界,导致出错。这样方法要视具体情况而定。例如,FTP协议就是采用 “\r\n” 来识别一个消息的边界的。
设计模式
ECS架构
来源
ECS全称Entity-Component-System,即实体-组件-系统。是一种软件架构模式,主要用于游戏开发。ECS认为组合优于继承。其核心思想就是对数据与运算的分离,系统只有方法,组件只有成员变量。
- Entity 实体,本质上是存放组件的容器。
- Component 组件,游戏所需的所有数据结构。
- System 系统,根据组件数据处理逻辑状态的管理器。
ECS 将认为游戏世界仅仅是系统和组件的集合体。而一个实体也只是组件的集合所对应的ID。
组件仅仅用于存储游戏状态(即数据),而不具备行为。系统具有行为却不保存游戏状态。或者这样说,组件是没有函数(行为)的,系统是没有成员变量的(数据/状态)。数据和行为分离,每个子类组件都有自己的成员变量,系统利用这些变量来表现行为。“组件没有函数,系统没有状态”。
- 游戏世界,称为EntityAdmin,它保存了一组系统,以及一个以实体ID作为键值的实体哈希表。
- Entity(实体) 保存了实体的ID,一个组件列表,以及可选择的对游戏资源的引用(称之为实体的定义)。
- Component(组件)是一个有着上百个子类的简单的基类,每个子类组件都有自己的成员变量,系统利用这些变量来表现行为。Component中的多态函数仅用于实体的生命周期管理,我们会重写它的创建函数和析构函数。其它添加到组件实例(Component的子类)中的函数就只有一些辅助函数,用于更方便的访问其内部状态,但它们没有真正的行为,只是简单的访问函数(因为行为由系统控制)。
传统面向对象设计模式的问题
通过继承联系起来的对象,一旦某个共同功能需要改动,或增加功能,就要调整类的结构。不处于同一条继承线中的对象如果有相同的功能,也无法通过继承的方式复用代码,造成了代码重复。
数据库
事务的概念和特性?
事务(Transaction)是⼀个操作序列,不可分割的⼯作单位,以BEGIN TRANSACTION开始,以ROLLBACK/COMMIT结束。
特性(ACID):
- 原⼦性(Atomicity):逻辑上是不可分割的操作单元,事务的所有操作要么全部提交成功,要么全部失败回滚(⽤回滚⽇志实现,反向执⾏⽇志中的操作);
- ⼀致性(Consistency):事务的执⾏必须使数据库保持⼀致性状态。在⼀致性状态下,所有事务对⼀个数据的读取结果都是相同的;
- 隔离性(Isolation):⼀个事务所做的修改在最终提交以前,对其它事务是不可⻅的(并发执⾏的事务之间不能相互影响);
- 持久性(Durability):⼀旦事务提交成功,对数据的修改是永久性的.
并发一致性问题?
- 丢失修改:⼀个事务对数据进⾏了修改,在事务提交之前,另⼀个事务对同⼀个数据进⾏了修改,覆盖了之前的修改;
- 脏读(Dirty Read):⼀个事务读取了被另⼀个事务修改、但未提交(进⾏了回滚)的数据,造成两个事务得到的数据不⼀致;
- 不可重复读(Nonrepeatable Read):在同⼀个事务中,某查询操作在⼀个时间读取某⼀⾏数据和之后⼀个时间读取该⾏数据,发现数据已经发⽣修改(针对update操作);
- 幻读(Phantom Read):当同⼀查询多次执⾏时,由于其它事务在这个数据范围内执⾏了插⼊操作,会导致每次返回不同的结果集(和不可重复读的区别:针对的是⼀个数据整体/范围;并且针对insert/delete操作)。
数据库四种隔离级别
- 未提交读(Read Uncommited):在⼀个事务提交之前,它的执⾏结果对其它事务也是可⻅的。会导致脏读、不可重复读、幻读;
- 提交读(Read Commited):⼀个事务只能看⻅已经提交的事务所作的改变。可避免脏读问题;
- 可重复读(Repeatable Read):可以确保同⼀个事务在多次读取同样的数据时得到相同的结果。
(MySQL的默认隔离级别)。可避免不可重复读; - 可串⾏化(Serializable):强制事务串⾏执⾏,使之不可能相互冲突,从⽽解决幻读问题。可能导致⼤量的超时现象和锁竞争,实际很少使⽤。
什么是乐观锁和悲观锁
- 悲观锁:认为数据随时会被修改,因此每次读取数据之前都会上锁,防⽌其它事务读取或修改数据;应⽤于数据更新⽐较频繁的场景;
- 乐观锁:操作数据时不会上锁,但是更新时会判断在此期间有没有别的事务更新这个数据,若被更新过,则失败重试;适⽤于读多写少的场景。乐观锁的实现⽅式有:
- 加⼀个版本号或者时间戳字段,每次数据更新时同时更新这个字段;
- 先读取想要更新的字段或者所有字段,更新的时候⽐较⼀下,只有字段没有变化才进⾏更新

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









