







 文章探讨了双目相机模型中的针孔相机原理,强调了相机坐标系、归一化坐标系和图像坐标系的区别。作者指出了在双目相机中右像素坐标的理解,以及求解深度Z时单位的一致性问题。提到了SGBM算法在求视差中的应用,以及极线约束在加速匹配过程中的作用。此外,还讨论了双目校正的重要性,确保对极线行对齐以简化匹配过程。
文章探讨了双目相机模型中的针孔相机原理,强调了相机坐标系、归一化坐标系和图像坐标系的区别。作者指出了在双目相机中右像素坐标的理解,以及求解深度Z时单位的一致性问题。提到了SGBM算法在求视差中的应用,以及极线约束在加速匹配过程中的作用。此外,还讨论了双目校正的重要性,确保对极线行对齐以简化匹配过程。
这章的内容我感觉是相对比较简单的,主要想分享一下自己的一些疑惑和后面的解答,可能有点水
针孔相机模型
在相机中 K(相机内参) * 相机下归一化坐标点 = 像素点。
首先大家要搞清楚相机坐标系下 世界坐标系下 归一化坐标系 还有图像坐标系。其实分清楚以后就相对很明确。
首先讲的是双目相机模型,当时自己在纠结为什么 右像素坐标为什么是负的,是因为UR在的坐标系是右坐标系下 根据 u v的坐标方向,可能就认为ur是负坐标。?
但是一般坐标系u v坐标系不是左上角为原点嘛? 以圆心为目标的不是xy坐标系嘛。后面会有解决的
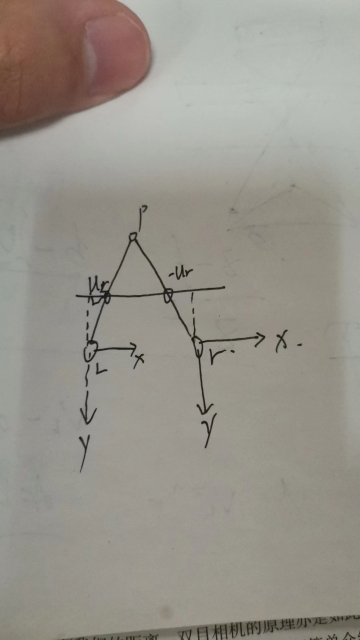
其实对于双目相机来说,成像平面肯定是要展平的想,两个平面,而成像点肯定是在相同的行上,不同的是横坐标。
而后面的求z的公式 我想一般想过的人都会觉得z的单位不对的把 安装公式z = fb/d f单位是m是焦距 不是fx 内参 fx = αf 。 b是双目相机的基线 也是测量的单位,也是m把 d = ul- ur 的话 单位肯定不能像素把,不然单位不统一啊,所以 我感觉肯定哪里出错了。
然后一般大家用这个公式的时候用的都是fx 而不是f 这样不就错了嘛 于是我相到 x 和u也是相差一个倍数α把,然后有平移 ,平移的话再d = ul- ur 再b中平移的量已经被减为0了。 所以我们一般用的是fx的话那我求的视差d的单位就应该是像素。 所以 我觉得再书中,用f 对应的话应该用xl xr来表示可能比较好理解。而求视差的算法求出的一般都是像素单位,所以再使用的过程中会用fx 而不是f。
这是我的理解。
https://www.likecs.com/show-204777434.html这是别人的
再双目中,求视差的算法一般是写好的把? 是需要自己求的 不然不能直接得到z
而再双目求视差中为了求得视差那么一定要有匹配点把
而对于双目相机来说,如何求的视差也是一个难题,一般是用sgbm算法来求视差的,求视差首先要求出匹配信息把,而对双目相机来说,他的匹配信息肯定不能像orb中这样繁琐把、,需要变快。
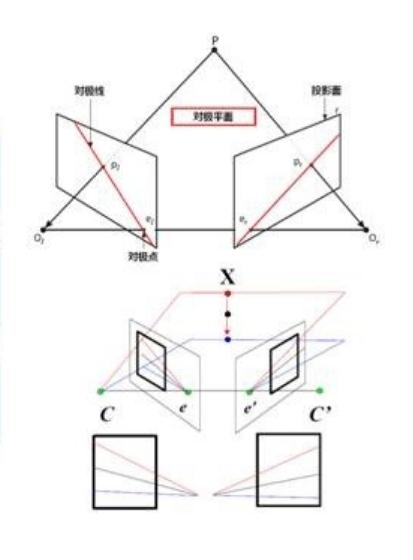
双目校正:(极线约束:空间中任意一点在图像平面上的投影点,必然处于由该点和两个摄像头中心组成的对极平面上。对于图像上的某一个特征点,其在另一个视图上的匹配点必处于对应的对极线上,这称为极线约束。极线约束使得特征匹配由二维搜索降低到一维搜索,从而大大加快计算速度,并且减少误匹配。)双目校正是根据摄像头标定后获得单目内参数据(焦距,成像原点,畸变参数)和双目相对位置关系(旋转矩阵和平移向量),分别对左右视图进行消除畸变和行对准,使得左右试图的成像原点坐标一致、两摄像头光轴平行、左右成像平面共面、对极线行对齐(使得两幅图像的对极线恰好在同一水平线上),这样一幅图像上任意一点与其在另一幅图像上的对应点就必然具有相同的行号,只需要对该行进行一维搜索即可匹配到对应点。
图像在计算机c++中存着的是一个矩阵形式。行是y 列是x
根据深度还原















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









