








本论文选自 ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) |顶会的一篇文章
关键词:Time series forecasting; temporal modeling; Transformer
这是一个用于时间序列预测(Time Series Forecasting)的模型,整个模型就是用的Autoformer的架构,不同之处在于,把Self-Attention换为了MSSC(Multi-Scale Segment-Correlation,多尺度段相关),把解码器中的Cross-Attention换为了PreMSSC(带预测范式的多尺度段相关)。所以,文章的主要创新点不是模型框架,而是如何算Attention。
ABSTRACT
在长期时间序列预测中,大多数基于 Transformer 的方法采用标准的逐点注意力机制,该机制不仅复杂度高,而且无法明确捕获上下文中的预测依赖关系,因为相应的键和值是从同一点转换的。本文提出了一种基于 Transformer 的预测模型,称为 Preformer。 Preformer 引入了一种新颖高效的多尺度分段相关机制,将时间序列划分为分段,并利用基于分段相关的注意力来取代逐点注意力。开发了多尺度结构来聚合不同时间尺度的依赖关系并促进片段长度的选择。 Preformer 进一步设计了解码的预测范式,其中键和值来自两个连续的段而不是同一段。实验表明 Preformer 优于其他基于 Transformer 的模型。
The codes are available at https://github.com/ddz16/Preformer.
1. INTRODUCTION
长期时间序列预测在现实世界中具有广泛的应用。现有的基于深度学习的方法可以分为四类,即RNN[1,2,3,4,5],TCN[6,7,8,9],MLP[10,11]和基于Transformer的模型[12, 13]。其中,基于 Transformer 的方法最近受到了时间序列预测社区的关注,尤其是长期预测[14,15,16],因为 Transformer 中的自注意力可以直接对任何元素对之间的关系进行建模。然而,Transformer 中的标准自注意力计算所有时间点对之间的相似度,其中时间和空间复杂度随着时间序列的长度呈二次方增加。最近的工作[17,18,14,16]探索了不同的稀疏注意力机制来抑制不相关时间步的贡献并减轻计算压力。这些模型仍然单独对时间步骤执行点积关注,并利用逐点连接来捕获时间依赖性。然而,单个点对预测未来的影响可能有限。 Autoformer [15] 通过执行以下操作来进行系列依赖关系发现自相关,聚合运算作用于整个延迟序列,并且需要复杂的傅里叶变换。
这些方法要么在点级别要么在整体序列级别执行相关性,这不仅需要高计算冗余来集中处理点对或执行时频域变换,而且不能直接反映时间序列内的真实依赖关系。时间序列往往在局部(一个片段内)具有很强的连续性和内部动态。因此,在细分层面存在更强的相关性。为此,我们提出了一种称为多尺度分段相关(MSSC)的新颖注意机制,它计算两个分段之间的互相关性[19]作为相似性度量。 Segment-Correlation的输出是通过对所有segment的聚合进行加权得到的,其中segment是最小的注意力单元,这实际上保留了每个segment内的连续性。由于分段比点少,因此在执行分段注意力时需要较少的计算。段长度是一个关键的超参数。长段会忽略细粒度信息,而短段则具有较高的计算冗余。为了解决这个问题,MSSC对多个片段长度(即多尺度分辨率)进行相关计算和融合,同时保持低复杂度。
此外,标准注意力范式[12]可以应用于MSSC进行时间序列编码,但它不太适合预测,因为未知预测段自己生成查询来预测自己。对于预测任务,利用前一段的查询来生成未知段的预测是更合理的。在这种情况下,如果给定的预测查询与某些段的键相似,则它们的下一个段而不是这些段本身应该对预测做出更多贡献。受此启发,我们进一步提出了预测多尺度分段相关性(PreMSSC),其中当前分段输出 Yi 可以通过使用前一个分段 Qi−1 查询所有分段 {K1, K2, … 来获得。 。 .}并对下一段的值进行加权{V2, V3, . 。 .} 通过计算出的相关性。我们通过分别用 MSSC 和 PreMSSC 替换原始 Transformer 模型中的标准自注意力和交叉注意力,得到了我们的预测模型,即 Predictive Transformer (Preformer)。
2. METHOD
2.1. Problem Definition
多水平时间序列预测旨在预测多个未来时间步长的值[20]。通常,给定先前的时间序列 X1:t0 = {x1, x2, . 。 。 , xt0 },其中 xt ∈ Rdx 并且 dx 是变量的维度,我们的目标是预测未来值 Yt0+1:t0+τ = {yt0+1, yt0+2, 。 。 。 , yt0+τ },其中 yt ∈ Rdy 是每个时间步 t 的预测,dy 是输出变量的维度。我们期望模型的预测 ^ Yt0+1:t0+τ 接近真实值 Yt0+1:t0+τ 。对于长期预测,要预测的未来持续时间 τ 较长。
2.2. The Preformer Model

如图1所示,Preformer的整体架构与Autoformer[15]类似。虽然模型架构相似,但核心模块的思路却完全不同。考虑到时间序列的强局部性(相邻点之间的连续性),我们将分段视为注意力计算的最小单位,并在聚合时保持每个分段内部的连续性。
Model inputs.
原始时间序列输入Preformer的方式与AutoFormer一致[15]。我们利用称为协变量的附加时间相关特征(例如,一天中的小时、一周中的某一天)作为输入的一部分。在输入 MSSC 模块之前,编码器和解码器的输入通过嵌入层转换为特征维度。
Encoder and decoder
编码器由 N 个相同的层组成,其中每层由 MSSC 模块和前馈网络组成,每个模块后面跟着一个具有残差连接的串联分解模块。编码器的输入包括过去的时间序列值和协变量。系列分解模块通过平均池层将输入分解为季节和趋势分量[15]。编码器中的所有分解模块都消除了趋势分量,这使得编码器专注于季节性模式建模。解码器由 M 个相同的层组成。与编码器不同的是,还有一个额外的 PreMSSC 模块,其中键和值矩阵是根据每个解码器层中的编码器输出进行转换的。解码器的输入包括两个分量:季节分量和趋势分量。解码器中的分解模块逐步从隐变量中提取趋势部分,最后与季节部分相加,得到导出输出。全连接层将解码器的输出作为输入,并生成最终预测 ˆ Yt0+1:t0+τ ∈ Rτ ×dy 。
2.3. Segment-Correlation
Segment-Correlation是Preformer中的关键模块,它执行分段注意力而不是点注意力。我们将每个分段相关模块的输入表示为 H ∈ RL×d,其中 L 和 d 分别是输入的长度和维度。形式上,对于单头情况,输入序列 H 将通过三个投影矩阵进行投影以获得查询、键和值,即 Q = HWq、K = HWk、V = HWv。然后将所有的Q、K和V分割成具有相同长度Lseg的若干段:{Q1,Q2,……。 。 。 ,Qm},{K1,K2,. 。 。 ,Kn},{V1,V2,. 。 。 , Vn},其中 Qi ∈ RLseg×d,Ki ∈ RLseg×d,Vi ∈ RLseg×d,m,n 表示分段数量,Lseg 是一个超参数,通过控制分段长度来确定计算复杂度。任意一对查询段 Qi 和关键段 Kj 之间的相关性测量 cij 由以下函数计算:
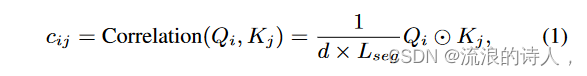
其中 ⊙ 是两个相同大小的矩阵之间的点积运算符。对于每个查询段Qi,其与所有关键段的相关性测量将通过Softmax函数进行归一化以获得聚合权重:

第i段Yi位置的输出是所有值段{Vj|的加权和。 j = 1,. 。 。 , n}:

最后,Segment-Correlation 模块的输出是通过连接所有 Yi 沿长度维度获得的:

其中 SC 是段相关性的缩写。
Multi-Scale Segment-Correlation.
由于 Lseg 决定了段相关性中涉及的最小单元的分辨率计算中,较大的 Lseg 意味着可以捕获时间序列中粗粒度的时间依赖关系,而较小的 Lseg 的 SegmentCorrelation 可以捕获细粒度的依赖关系。为了减弱超参数 Lseg 选择对性能的影响,我们通过将多个分段相关的输出与不同的 Lseg 融合来提出多尺度分段相关(MSSC)。考虑到迭代所有选择以找到最佳组合的效率低下,我们使用指数增长的段长度来覆盖尽可能多的尺度级别。具体来说,随着规模水平的增加,我们从一个小的初始段长度 L0 开始,并以指数方式增加段长度,即 Ll = 2lL0,其中 l ∈ {0, 1, . 。 。 , lmax} 表示尺度级别,lmax = ⌊log2( L L0 )⌋。输入H经过这些不同尺度级别的Segment-Correlation层,以获得相应尺度级别的输出。考虑到细粒度的输入包含更多的信息,我们将所有尺度级别的输出进行聚合,得到整个MSSC模块的输出,其中第l个级别的权重设置为随着尺度级别的增加呈指数下降。因此,MSSC 的公式为:

Predictive paradigm.
在解码阶段,对要预测的周期的查询是其前一段而不是其本身。因此,如果某些关于键的片段与查询高度相关,那么它们的未来片段而不是它们本身应该对查询的预测做出更多贡献。受这种直觉的启发,我们通过在键及其相应值之间引入段延迟来提出预测范例。对于没有预测范式的分段相关,根据式(1)获得第i分段Yi位置处的输出: (3)。如果我们将 ˆ cij 重新表示为 ˆ c(Qi,Kj ),则我们有:
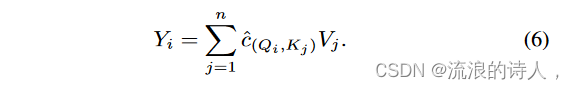
这是预测范式和非预测范式之间的两个区别。首先,为了得到当前段Yi的输出,使用前一段Qi−1的查询来计算与所有段{K1,...的键的相关性。 。 。 ,Kn−1}。其次,将某个段Kj的关键字对应的相关性^c(Qi−1,Kj)作为下一个段Vj+1聚合值的权重。也就是说,value的段相对于对应的key的段向前偏移了一段。因此,我们可以通过以下等式得到Yi:

2.4. Complexity Analysis
对于单尺度分段相关,如果分段长度 Lseg = L0,则计算复杂度为 O(L2/L0)。对于多尺度分段相关,计算复杂度是所有尺度的总和,受益于分段长度的指数增长,计算复杂度仍然与 O(L2/L0) 相同。大多数其他稀疏机制都会引入一些额外的操作,例如 Informer 中的主导查询选择和 Autoformer 中的快速傅立叶变换。虽然它们的理论复杂度是 O(L log L),但实际运行效率甚至不如我们的 Multi-Scale Segment-Correlation。请参阅第 3.4 节了解更多详细信息。
表 1. 在五个数据集上与之前最先进的基于 Transformer 的模型进行比较。粗体和下划线分别表示每行中的最佳结果和第二好结果。

3. EXPERIMENTS
3.1. Experimental Setup
我们对五个数据集进行实验。 (1) ETT [14]包含两个站点在 2 年内收集的与电力相关的数据。 (2)电力[14]包含321个客户2年内每小时的用电量。 (3) Exchange [3] 收集 1990 年至 2016 年 8 个国家的每日汇率。 (4) Traffic [14] 收集加州交通部 2 年内每小时的道路占用率。 (5)天气[15]记录马克斯普朗克研究所2020年每10分钟的气候数据。我们按照 Autoformer [15] 分割数据集。我们在训练集上训练模型,在验证集上调整超参数,并评估测试集上的性能。我们使用初始学习率为 1e-4 的 ADAM [21] 优化器和学习率衰减来训练我们的模型。我们利用提前停止训练策略来避免过度拟合。训练周期数设置为 10,批量大小设置为 32。对于所有实验设置,Preformer 包含两个编码器层和一个解码器层。之前的工作已经证明 Transformer 在长期预测方面优于 RNN 和 TCN [14],因此我们只与四种基于 Transformer 的模型进行比较,即 Autoformer [15]、Informer [14]、LogTrans [17]、Pyraformer [16] ]。
3.2. Main Results
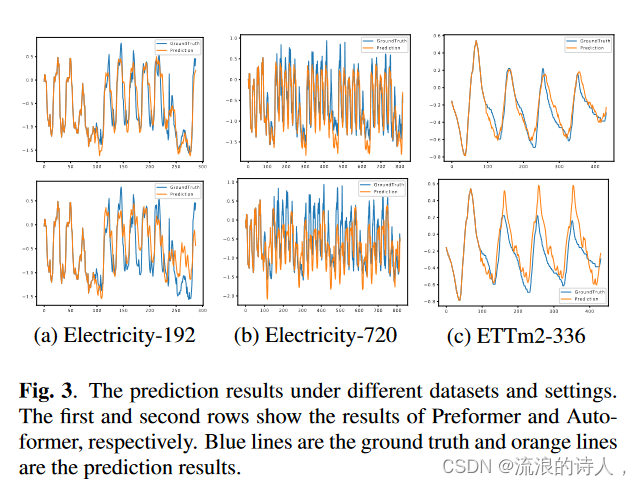
为了全面比较 Preformer 和基线,我们主要在多种设置(即 dy > 1)下对各种数据集进行多变量预测实验。Preformer 也适用于单变量预测。对于所有数据集,输入长度固定为 96,预测长度从 {96, 192, 336, 720} 中选择。从表1中,我们发现Preformer在所有情况下都优于除Autoformer之外的其他模型,并且仅在少数设置下比Autoformer表现稍差。例如,在 input96-predict-192 设置下,与之前的最先进结果相比,Preformer 在 ETTm2 方面实现了 4.3% (0.281 → 0.269) 的相对 MSE 改进,在电力方面实现了 14.9% (0.222 → 0.189) 的相对 MSE 改进, 10.7%交易中为 (0.300 → 0.268),流量中为 8.3% (0.616 → 0.565),天气中为 10.4% (0.307 → 0.275)。此外,Preformer 在长预测范围的情况下表现出稳定的性能,这表明它适合长期预测。 Autoformer 是除了我们的 Preformer 之外最好的预测模型。因此,我们将 Preformer 和 Autoformer 的预测结果绘制在图 2 中。 3 进一步比较。我们的Preformer可以准确预测周期性、趋势甚至一些小的波动。尽管在很长的预测范围内,Preformer 也能表现良好。
3.3. Ablation Study
impact of the multi-scale structure.
多尺度结构可以有效地提取不同时间分辨率下的依赖关系,这对于时间序列预测非常重要。为了说明这一点,我们从 Preformer 中的所有 PreMSSC 和 MSSC 模块中删除多尺度结构,以获得没有多尺度结构的模型。如表2所示,在所有情况下,具有多尺度结构(MS+Pre)的Preformer的预测性能都优于没有多尺度结构(Only Pre)的预测性能。特别是在 ETTh1 和 Exchange 数据集上,多尺度结构可以带来可观的性能提升。
Impact of the predictive paradigm.
为了探索预测范式对于预测任务是否真的有效,我们在具有不同设置的三个数据集上对其进行了消融。表2中,MS+Pre表示标准的Preformer模型,Only MS表示将Preformer解码器中的PreMSSC模块替换为MSSC模块。实验结果表明,具有预测范式的Preformer在几乎所有情况下都取得了更好的性能,这证明所提出的预测范式对于预测任务是有帮助的
The sensitivity analysis of the segment length.
段长度 Lseg 是段相关中的一个关键超参数。多尺度结构可以方便片段长度的选择。我们在四个数据集上从 {2, 4, 8, 12, 24, 48} 中选择不同的初始片段长度 L0 进行实验。如图所示。 4、多尺度结构的Preformer在所有数据集上表现更稳定、更好,即MSE分数的均值和方差更小。
3.4. Efficiency analysis
我们在图 2 的训练阶段比较了具有不同稀疏注意力机制的模型的运行内存和时间。 5. 值得注意的是,由于 Autoformer 中的快速傅里叶变换和告密者都需要额外的时空复杂性。
4. CONCLUSION
在本文中,我们提出了一种基于 Transformer 的模型,称为 Preformer,用于长期时间序列预测。在Preformer中,我们引入了一种称为多尺度分段相关性(MSSC)的有效注意机制,它利用分段对之间的相关性来发现依赖性并聚合时间序列中的信息。此外,我们设计了一种新颖的预测范式,并将其与 MSSC 相结合以获得预测多尺度分段相关性(PreMSSC),它可以从上下文中发现预测依赖性。大量的实验证明了 Preformer 的优越性。















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









