






今早的奥斯卡闹了个大乌龙,颁奖最佳影片时,颁奖人错拿了最佳女主的信封,将奖项错颁给《爱乐之城》,让真正得主《月光男孩》黯然神伤。有趣的是,著名群体智能预测网站Swarm AI阴差阳错,“连这次乌龙都预测到了”。到底所因为何?请看今日播报。
点击题目蓝色字体即可阅读原文。
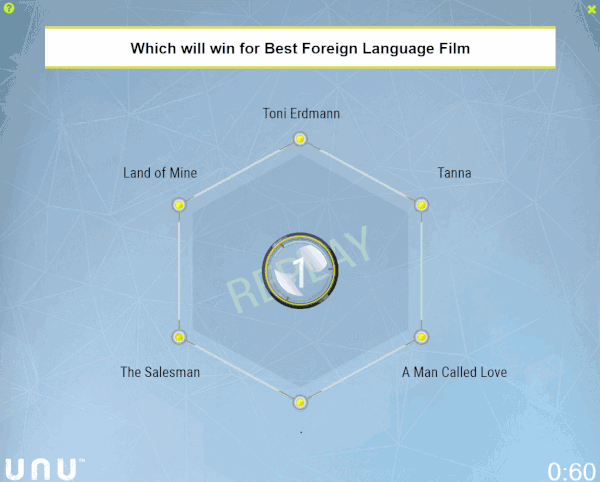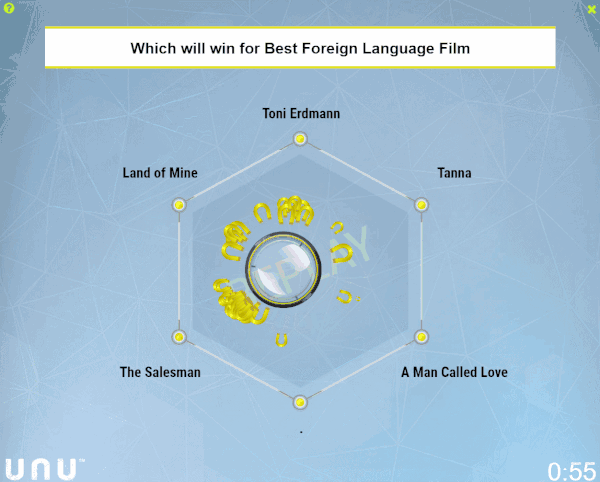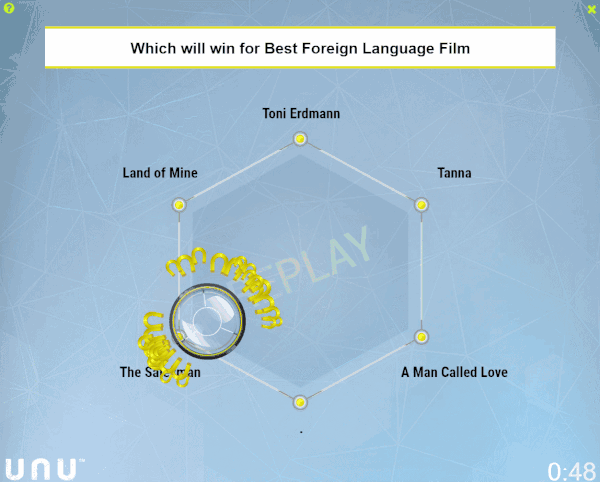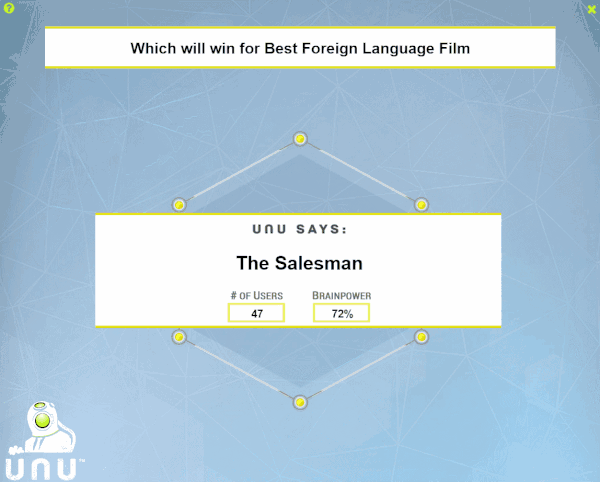
2017奥斯卡大奖揭晓,群集智能AI成功预测12项
2017年2月27日,第89界奥斯卡诸项大奖名单新鲜出炉,《月光男孩》战胜呼声甚高的《爱乐之城》拿下最佳影片。大奖公布之前,著名的群体智能预测网站的Swarm AI再出手预测,今年它虽然保持着75%的胜率,但是却预测错了两项大奖。
Swarm AI 的平台由 Unanimous 公司开发。Unanimous A.I 的研究员集合了近50名电影爱好者群集,来预测2月27日奥斯卡大奖的归属。
用户注册后可在Unanimous A.I 参与预测,在做出决定时,每位用户都有一个可以拖向他们的选择的虚拟圆盘。每个人都可以看见其他人的决定,也可以随时改变自己决定。这个集群中的每个个体都可以互相影响。
AI“荡涤”华尔街,股票交易员或比卡车司机更早失业
去年一整年,我们一直担心AI技术的发展是否会让300万卡车司机丢了工作。不过让人大跌眼镜的是,眼下要丢了工作的不是卡车司机而是华尔街交易商和对冲基金经理,虽然他们有能力购买最贵的跑车,也有能力雇佣 Elton John 参加他们的汉普顿之家聚会。
像高盛一样的金融巨头和许多顶级的对冲基金都在开发人工智能驱动系统。这或许表示AI在市场趋势预测方面的确比人做得更好。美国AI的投资人和美国竞争力委员会的高级顾问 Mark Minevich 表示,高收入的交易员会被毫不留情地抛弃,就像一群被关闭了工厂赶走的工人一样。“它(AI)真的会打击到华尔街的灵魂,它会改变纽约。”
Eurekahedhge(尤里卡对冲基金)监测了23个应用人工智能软件的对冲基金,发现它们的表现超过了主要依赖人的资金。
ICLR 17最具争议的最佳论文,实至名归还是盛名过誉?
2月25日,ICLR 2017的论文评选结果出炉。经过近三个月的评选,本次 ICLR 的 507 篇论文中共诞生 15 篇口头展示论文,181 篇海报展示论文,而三篇最佳论文也已正式公布。
在三篇最佳论文中,争议最大的莫过于这篇名为《Understanding Deep Learning Requires Rethinking Generalization》(《理解深度学习,需要重新思考泛化问题》)的论文。
论文要点:
成功的神经网络在训练与测试性能之间存在非常小的差异,但传统观点认为这是泛化误差的结果。这篇论文就以「重新思考泛化问题」为主题,通过系统试验,展示传统方法无法解释大规模神经网络在实践中的泛化表现好的原因。而在实验中,研究者证明了用随机梯度训练、用于图像分类的 CNN 很容易拟合随机标签数据,而且本质上并不受显式正则化的影响。
该论文作者阵容豪华,但 OpenReview 上的评论却一度呈现两极分化态势:
- 以纽约大学博士生张翔为代表的研究者认为此文被高估,他认为这篇论文归根结底可以总结为:在跟输入无关的随机标签下,模型的泛化能力很差。
「我的反对意见是,论文实验中采用的与输入无关的随机标签训练神经网络模型,是极端显而易见且没有意义的,这个结果并没有教给研究人员任何新的知识。」
- 而评审的最终结果却认为它具有重要的学术意义。
作者在论文中阐述了深度神经网络拟合随机标签数据的能力,并给出了非常不错的实验结果。这个调查不仅全面,也具有启发意义。作者提出了 a) 一个理论实例,说明一个具有足够规模参数的简单浅层网络能够产生完美的有限样本表达性;b) 系统广泛的实验评估得以支持研究结果。这个实验评价是一个具有彻底性的模型。
毋庸置疑,这是一项具有颠覆性的工作,将会启发未来数年的许多研究。
最终,该论文被评为三篇最佳论文之一,获得演讲展示资格。
解析 2017 最火结构 Wasserstein GAN
本文为国外研究者撰写的《Wasserstein GAN》导读,作者尝试着把Wassertein GAN (Martin Arjovsky et al., 2017)论文中艰涩难懂的理论简单化。
你为什么要读这篇论文:
- 论文提出了一种新的GAN的训练算法,能够在一般的GAN数据集上运行得很好;
- 这种训练算法有理论支撑。在深度学习领域,不是所有理论上可行的论文都能有良好的操作结果,但有良好操作结果的理论上可行的文章,都会有真正良好的操作结果。对这些论文来说,理解它们的理论非常重要,因为它们的理论能够解释为什么它们表现得如此出色;
- 我听说在Wasserstein GAN中,你可以(也应该)训练鉴别器收敛。如果真是这样,就不需要用鉴别器更新来平衡发生器更新了,这就像是训练GAN的最大黑魔法之一;
- 论文显示了鉴别器损失和理解质量的相关性。如果真是这样,那可不得了。在我有限的GAN的经验里,一个很大的问题就是损失并不意味着什么——这要感谢对抗性训练,它让判别模型是否在训练都变得很难。强化学习和损失函数有着相似的问题,但我们至少获取了某些意义上的回报。即使是一个粗略定量测量的训练过程,对于自动超参数优化(比如贝叶斯优化)来说也够宝贵了。
阿里开源Gym StarCraft 能帮助开发者体验强化学习
在星际争霸的AI研究中,一直以来缺乏完善的工具链和开发环境。
今年年初Facebook公司发布的TorchCraft打通了星际和Torch之间的桥梁,但却不支持主流的Python开发语言和TensorFlow深度学习框架;早前OpenAI公司发布的Gym算法平台虽然支持众多游戏环境下的算法验证和对比测试,但却缺少对星际的支持。
针对星际AI的这一现状,阿里巴巴开发了一套专业易用的研究平台Gym StarCraft,并且已经开源:https://github.com/deepcraft/gym-starcraft。
在Gym StarCraft中,AI和强化学习研究者可以非常方便地使用Python语言来进行深度强化学习智能Agent的开发,它底层完成了对TorchCraft和OpenAI Gym的封装,支持基于TensorFlow和Keras等主流算法框架进行开发,仅需几十行代码即可完成一个基本的智能Agent的开发。
同时,便于评测智能Agent的有效性,Gym StarCraft被集成在了OpenAI Gym这一主流的强化学习AI评测平台中,支持世界各地的星际AI研究者基于它去进行公平、快捷的效果评估,为广大开发者提供了一个人工智能的开放协作研究平台。对于强化学习的普及和推广起着关键性作用。
MIT团队训练AI玩任天堂游戏 已跻身顶级玩家之列
近日,麻省理工大学的研究生团队研发了一款名为Philip的游戏AI,已能胜任多种“任天堂明星大乱斗”游戏人物。并跻身世界顶级玩家之列。
Philip是麻省理工大学研究生 Vlad Firoiu带队研发的深度学习系统。2月21日,该团队在Arxiv上发布了一篇名为Beating the World’s Best at Super Smash Bros. with Deep Reinforcement Learning(《用深度增强学习打败世界最强任斗选手》)的论文。(论文地址)
Philp采用 Q Learning及Actor-Critic算法,尽管这两种算法并非为视频类游戏量身定做,但只要训练数据足够,效果还是很喜人的。和AlphaGo一样,Philip也是在一局一局的对抗中逐渐获得数据。
但团队为Philip设置了人类7倍的反应速度,且使Philip能够从后台读取对手的速度及位置。与用人眼看屏幕来做出反应的人类玩家相比,Philip占太多优势。
虽然研究尚在初级阶段,该团队论文已初显其意义。论文表示,事实证明,通过迁移学习可以使Philip在不同角色中切换;且训练Philip玩某一特定角色的难度,和人类对该角色难度的认知是相符的。
对抗生成网络(GAN)为什么会火
自2014年Ian Goodfellow提出生成对抗网络(GAN)的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,Yann LeCun更是称之为”过去十年间机器学习领域最让人激动的点子”。
生成对抗网络训练一个生成器(Generator,简称G),从随机噪声或者潜在变量(Latent Variable)中生成逼真的的样本,同时训练一个鉴别器(Discriminator,简称D)来鉴别真实数据和生成数据,两者同时训练,直到达到一个纳什均衡,生成器生成的数据与真实样本无差别,鉴别器也无法正确的区分生成数据和真实数据。
近两年来学术界相继提出了条件生成对抗网络(CGAN),信息生成对抗网络(InfoGAN)以及深度卷积生成对抗网络(DCGAN)等众多GAN的变种。那么GAN相比传统的深度神经网络,它的优势在哪里?
对此,GAN的发明人Ian Goodfellow解答到:
优势
- GANs是一种以半监督方式训练分类器的方法,可以参考我们的NIPS paper和相应代码。在你没有很多带标签的训练集的时候,你可以不做任何修改的直接使用我们的代码,通常这是因为你没有太多标记样本。我最近也成功地使用这份代码与谷歌大脑部门在深度学习的隐私方面合写了一篇论文。
- GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据。
- GANs不需要蒙特卡洛估计来训练网络,人们经常抱怨GANs训练不稳定,很难训练,但是他们比训练依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼机简单多了。因为蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中。GANs起码在ImageNet上训练后可以学习去画一些以假乱真的狗。
- 相比于变分自编码器,GANs没有引入任何决定性偏置(deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊。
- 相比非线性ICA(NICE, Real NVE等),GANs不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的。
- 相比玻尔兹曼机和GSNs,GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次。
劣势
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多。
- 它很难去学习生成离散的数据,就像文本。
- 相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素,你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值。
我在伯克利大学的课堂上前二十分钟讲到了这个问题。课程链接,请自带梯子。
今天的播报就到这里,若您想要与我交流,请邮件wangyi@csdn.net或扫描下方二维码加我微信。

















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









