









《无需思考的推理模型依然有效》
近年来,大型语言模型(LLM)在推理任务上的表现显著提升,尤其是在数学问题求解、代码生成和形式定理证明等领域。这种进步很大程度上得益于推理模型在生成过程中引入了显式的、冗长的“思考”过程(Chain-of-Thought, CoT),通过逐步推理、反思和验证来逼近正确答案。然而,一篇由加州大学伯克利分校和艾伦人工智能研究所的研究者于2025年发表的预印本论文《Reasoning Models Can Be Effective Without Thinking》(arXiv: 2504.09858v1)提出了一个令人惊讶的观点:显式的思考过程可能并非推理模型高性能的必要条件。本文将面向对LLM推理感兴趣的深度学习研究者,介绍这篇论文的核心贡献及其对未来研究的启发。
论文背景
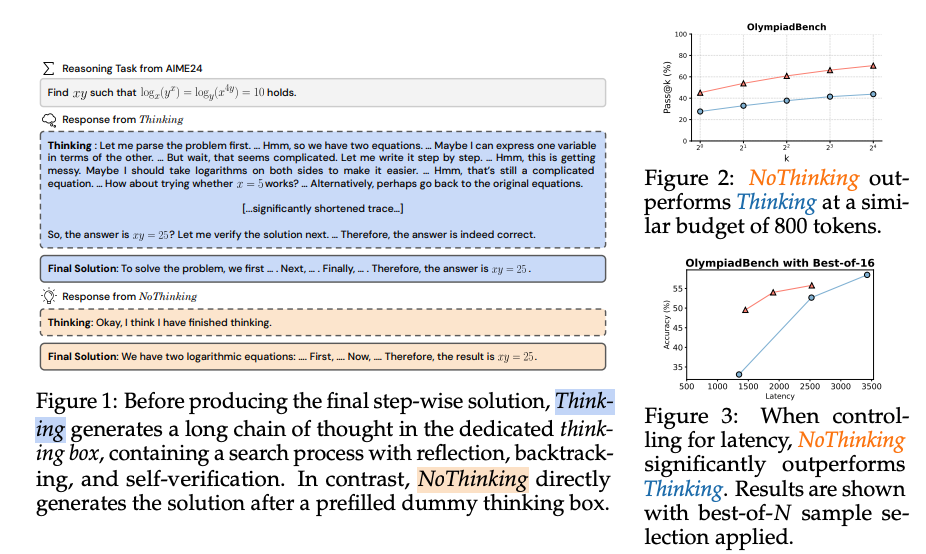
当前的主流推理模型,如DeepSeek-R1、OpenAI o1和Qwen等,通常在生成答案前会输出一个包含搜索、反思、回溯和自我验证的“思考”过程。这种方法通过推理时间计算扩展(inference-time compute scaling)显著提升了模型在复杂任务上的表现。然而,显式思考过程带来了高昂的计算成本,包括更高的token使用量和推理延迟。已有研究尝试通过强化学习或精简CoT轨迹来优化推理效率,但这些方法仍依赖于显式思考。
这篇论文挑战了这一范式,提出了一种名为“NoThinking”的简单提示方法,试图绕过显式思考过程,直接生成最终解决方案和答案。研究者基于先进的推理模型DeepSeek-R1-Distill-Qwen进行了广泛实验,验证了NoThinking在多种推理任务上的有效性。
核心贡献
论文的主要贡献可以总结为以下几点:
1. NoThinking方法:绕过显式思考过程
NoThinking通过在提示中插入一个伪造的、空洞的思考块(例如,<|beginning_of_thinking|> Okay, I have finished thinking. <|end_of_thinking|>),强制模型直接生成解决方案,而非传统的CoT过程。这种方法极大地减少了token使用量(相比传统Thinking方法减少2.0-5.1倍),同时显著降低了推理延迟。
2. 在多种推理任务上的出色表现
研究者在七个具有挑战性的推理数据集上评估了NoThinking,包括:
- 数学问题求解:AIME 2024、AIME 2025、AMC 2023、OlympiadBench(数学子集)
- 代码生成:LiveCodeBench
- 形式定理证明:MiniF2F、ProofNet
实验结果表明:
- 低预算场景:在控制token使用量的情况下,NoThinking在低预算设置(例如700 token)下显著优于Thinking。例如,在AMC 2023数据集上,NoThinking的pass@1准确率为51.3%,而Thinking仅为28.9%。
- 高k值场景:随着pass@k中k的增加(k从1到64),NoThinking的性能逐渐追平甚至超越Thinking,尤其是在定理证明任务(MiniF2F和ProofNet)上,NoThinking在所有k值下与Thinking表现相当,同时使用3.3-3.7倍更少的token。
- 任务特异性差异:NoThinking在不同任务上的表现存在细微差异。例如,在MiniF2F和ProofNet上,NoThinking在pass@1时即可匹敌Thinking,而在AIME和LiveCodeBench上,NoThinking在k=1时略逊,但在k较大时表现更优。
3. 并行推理策略的优越性
基于NoThinking在高k值下的优异表现,论文提出了一种并行推理策略:通过并行生成N个独立输出,并使用任务特定验证器或简单的最优N选择策略(例如基于置信度的选择)进行聚合。这种策略在以下方面展现了优势:
- 低延迟:相比传统的顺序推理(Thinking),NoThinking结合并行推理可将延迟降低高达7-9倍。
- 高准确性:在有验证器的任务(如形式定理证明)中,NoThinking并行推理的准确性超越Thinking,甚至在总token使用量减少4倍的情况下仍保持竞争力。在无验证器的任务(如OlympiadBench)中,NoThinking也能以9倍更低的延迟实现更高的准确性。
4. 重新审视显式思考的必要性
论文最重要的理论贡献是挑战了显式思考过程的必要性。实验表明,即使在经过强化学习或CoT微调的推理模型中,显式思考可能并非性能提升的唯一途径。NoThinking的成功表明,模型可能通过训练过程中内化的推理能力直接生成高质量答案。这一发现为高效推理提供了新的视角。
5. 提供低预算推理的强基准
NoThinking方法无需额外的训练或奖励信号,仅通过简单的提示调整即可实现高效推理。这为资源受限的场景(如边缘设备或低成本推理)提供了一个强有力的基准。研究者还通过引入AIME 2025等新数据集验证了方法的泛化能力,排除了数据污染的可能性。
对深度学习研究者的启发
对于关注LLM推理的深度学习研究者,这篇论文提供了以下启发:
-
推理效率优化:NoThinking表明,推理效率的提升可能不需要复杂的训练流程或模型结构调整。简单的提示工程可能足以挖掘模型的潜在能力。研究者可以进一步探索其他提示策略,以在不牺牲性能的前提下降低计算成本。
-
并行推理的应用:论文的并行推理策略展示了在高k值场景下利用pass@k指标的潜力。研究者可以考虑将并行推理与先进的聚合方法(如强化学习优化的选择器)结合,进一步提升性能。
-
任务特异性分析:NoThinking在不同任务上的表现差异提示我们,推理策略的有效性可能与任务特性密切相关。未来的研究可以深入分析哪些任务更适合NoThinking,以及模型为何在某些任务上无需显式思考即可表现优异。
-
模型内部推理机制:NoThinking的成功可能暗示模型在训练过程中已将推理能力内化。研究者可以通过可视化或解释性分析,探究模型在NoThinking模式下的决策过程,揭示其高效推理的机理。
-
开源与可复现性:论文使用了DeepSeek-R1-Distill-Qwen等开源模型,并提供了详细的实验设置和提示示例(附录C)。这为研究者复现实验或基于NoThinking进行扩展研究提供了便利。
总结
《Reasoning Models Can Be Effective Without Thinking》通过提出NoThinking方法,挑战了显式思考过程在推理模型中的必要性。实验结果表明,NoThinking在低预算和低延迟场景下能够匹敌甚至超越传统Thinking方法,尤其是在并行推理策略的加持下。这项工作不仅为高效推理提供了新的基准,也为研究者重新思考LLM推理机制开辟了道路。对于深度学习领域的从业者而言,这篇论文是一个值得深入探讨的起点,激励我们在推理效率、提示工程和模型内部机制方面进行更多创新。
后记
2025年4月18日于上海,在grok 3大模型辅助下完成。

















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









