







解读《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》的贡献与洞见
《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》是一篇由Lianmin Zheng等人于2023年发表在NeurIPS Datasets and Benchmarks轨道的重要论文,聚焦于大型语言模型(LLM)作为评估工具(即“LLM-as-a-Judge”)的可行性及其在评估聊天机器人性能方面的应用。本文通过系统性研究和两个创新基准(MT-Bench和Chatbot Arena),为LLM研究者提供了宝贵的洞见。以下从研究背景、主要贡献以及对LLM研究的影响三个方面进行介绍,旨在帮助研究者深入理解该论文的价值。
Paper:https://arxiv.org/pdf/2306.05685
研究背景
随着LLM在指令跟随和多轮对话能力上的显著进步,传统的评估基准(如MMLU、HELM)逐渐显露出局限性。这些基准主要关注模型在封闭式任务上的核心能力(如多项选择题或检索任务),难以有效评估LLM在开放式任务中的表现,尤其是与人类偏好的一致性。例如,经过指令微调和人类反馈强化学习(RLHF)对齐的模型在用户偏好上表现优异,但传统基准评分未必能反映这种优势。这种评估与用户感知之间的“错位”促使研究者探索更贴近人类偏好的评估方法。
本文提出利用强大的LLM(如GPT-4)作为“裁判”来评估聊天机器人,试图通过自动化、可扩展的方式近似人类偏好。同时,作者设计了两个新的基准——MT-Bench和Chatbot Arena,以更好地捕捉LLM在多轮对话和开放式任务中的能力。
主要贡献
论文的贡献可以总结为以下两点,每一点都为LLM研究提供了重要的方法论和数据资源:
1. 系统性研究LLM-as-a-Judge的潜力与局限性
论文深入探讨了LLM作为裁判的可行性,提出了三种评估模式:成对比较(Pairwise Comparison)、单答案评分(Single Answer Grading)和参考引导评分(Reference-guided Grading),并分析了它们的优缺点。例如,成对比较在模型数量增加时计算复杂度较高,而单答案评分可能对细微差异不够敏感。
此外,作者识别并量化了LLM-as-a-Judge的几种偏差和局限性,包括:
- 位置偏差(Position Bias):LLM倾向于偏向答案的呈现顺序(如更倾向于第一个答案)。实验表明,GPT-4在65%的案例中保持一致性,而Claude-v1和GPT-3.5的表现较差(表2)。作者提出通过交换答案顺序或随机分配位置来缓解此问题。
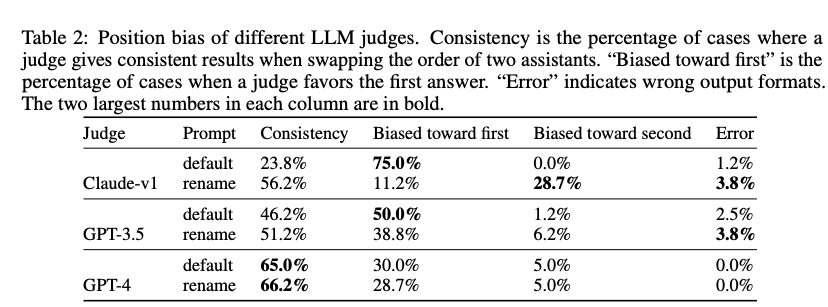
- 冗长偏差(Verbosity Bias):LLM可能偏好更冗长的回答,即使其质量并不更高。通过“重复列表攻击”实验,作者发现Claude-v1和GPT-3.5的失败率高达91.3%,而GPT-4仅为8.7%(表3)。

- 自我增强偏差(Self-enhancement Bias):LLM可能倾向于偏好自身生成的答案,但实验数据不足以明确证实此偏差。
- 数学与推理能力的局限性:LLM在评估数学和推理问题时可能出错,即使它们能够独立解决这些问题。作者提出链式思考(Chain-of-Thought, CoT)和参考引导方法显著降低失败率(表4)。

通过这些分析,论文不仅揭示了LLM-as-a-Judge的潜力(例如,GPT-4与人类偏好的同意率超过80%,与人类-人类同意率相当),还提供了具体的改进策略,如位置交换、少样本提示(Few-shot Prompting)和CoT提示,为研究者优化自动化评估提供了实用指导。
2. 引入MT-Bench和Chatbot Arena两个创新基准
论文设计了两个专门针对人类偏好和多轮对话能力的基准,填补了现有评估框架的空白:
- MT-Bench:包含80个高质量多轮问题,覆盖写作、数学、知识等8个类别(表1)。这些问题旨在测试模型的指令跟随能力和多轮对话的连贯性。例如,写作任务要求模型生成旅行博客并按特定格式重写,数学任务涉及函数求值和求解。MT-Bench通过专家投票(3K票)和公开数据集为研究者提供了高质量的评估资源。
- Chatbot Arena:一个众包平台,用户可与两个匿名模型同时交互并投票选出更优回答。平台收集了约30K次投票,涵盖多样化的用户兴趣和用例。Chatbot Arena的开放性使其能够捕捉真实场景中的用户偏好,补充了MT-Bench的结构化评估。
这两个基准的结合为评估LLM提供了一个混合框架:MT-Bench关注结构化、挑战性的问题,Chatbot Arena则捕捉广泛的现实用例。作者还公开了相关数据集(https://github.com/lm-sys/FastChat),为后续研究提供了宝贵资源。
对LLM研究的洞见与启发
本文的贡献为LLM研究者提供了以下几点启发:
-
重新定义评估范式:传统基准(如MMLU)无法充分反映LLM在开放式任务中的表现,而人类偏好是评估聊天机器人实用性的直接指标。LLM-as-a-Judge结合MT-Bench和Chatbot Arena的混合评估框架,为研究者提供了一种可扩展、自动化且贴近人类偏好的评估方法。研究者可参考这一框架设计更全面的基准,平衡核心能力和用户对齐。
-
优化LLM裁判的实用性:论文揭示的偏差(如位置偏差、冗长偏差)提示研究者在部署LLM-as-a-Judge时需谨慎设计提示和评估流程。例如,交换答案顺序或引入参考答案可显著提高评估的可靠性。此外,少样本提示和CoT技术在提升一致性和推理能力方面的潜力值得进一步探索。
-
开源模型的潜力:论文在附录F中探讨了Vicuna-13B作为低成本裁判的可能性。未经微调的Vicuna表现不佳(一致性仅11.2%-16.2%),但通过Chatbot Arena的22K人类投票微调后,其一致性提升至65%,与GPT-4的66%接近(表15)。这表明,通过适当微调,开源模型有望成为闭源模型的经济替代品,降低评估成本。
-
数据驱动的模型改进:MT-Bench和Chatbot Arena提供的高质量数据集为研究者提供了训练和验证LLM的机会。例如,Chatbot Arena的30K投票可用于微调模型以更好地对齐人类偏好,而MT-Bench的结构化问题可用于测试模型在特定任务上的鲁棒性。
总结
《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》通过系统性研究LLM-as-a-Judge的潜力和局限性,以及引入MT-Bench和Chatbot Arena两个创新基准,为LLM评估领域带来了重要突破。其核心洞见在于:强大的LLM(如GPT-4)可以作为人类偏好的可扩展代理,而新设计的基准能够更好捕捉模型在开放式任务中的表现。研究者可以利用公开的数据集和提出的优化策略(如位置交换、CoT提示)进一步完善自动化评估流程,同时探索开源模型在降低成本方面的潜力。这篇论文不仅为LLM评估提供了新的方法论,也为构建更贴近用户需求的智能系统铺平了道路。
后记
2025年4月30日于上海,在grok 3大模型辅助下完成。

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









