







1. CenterNet
CenterFusion基于CenterNet构建,因此我们先来了解一下CenterNet。
与基于Anchor的检测方式不同,其预测中心点位置和BBox尺寸来定位目标。
- Anchor方式的劣势:大量Anchor导致正负样本失衡; 要配置较多参数, 比如anchor_base_size, ratio等;
同时结果需要进行NMS处理耗时。
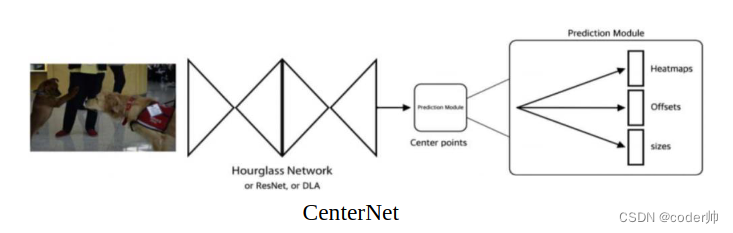
回归头:
1. HeatMap (W/4, H/4, C) C是类别数,表示每类中图像各个位置中心点的概率.
计算损失前,需要进行NMS过滤(3x3 max pooling) -> 寻找topK个最大值, 得到对应宽高和offset.
loss: BCE(二元交叉熵)
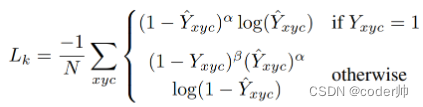
2. Offset(W/4, H/4, C) 长宽的偏移量,图像在下采样时会损失位置小数, 用Offset微调最终位置
loss: 中心点真值和偏移后的预测值的 L1损失, p是中心点坐标,R是Heatmap缩放因子,p~是offset
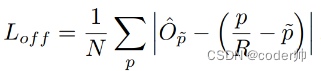
3. H, W (W/4, H/4, C) Bbox长和宽
loss: L1损失
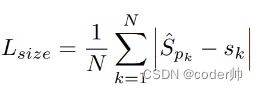
2. CenterFusion
让我们再回归到CenterFusion的网络结构上, 能看到有两个回归头。其中每个回归头都是基于CenterNet的结构。
第一个回归头是从image分支经过Backbone提取特征并回归多项:
HM(heat map), Offset(2D BBox), WH, Dimention(H, W, L: 3D BBox), Depth, Rotation.
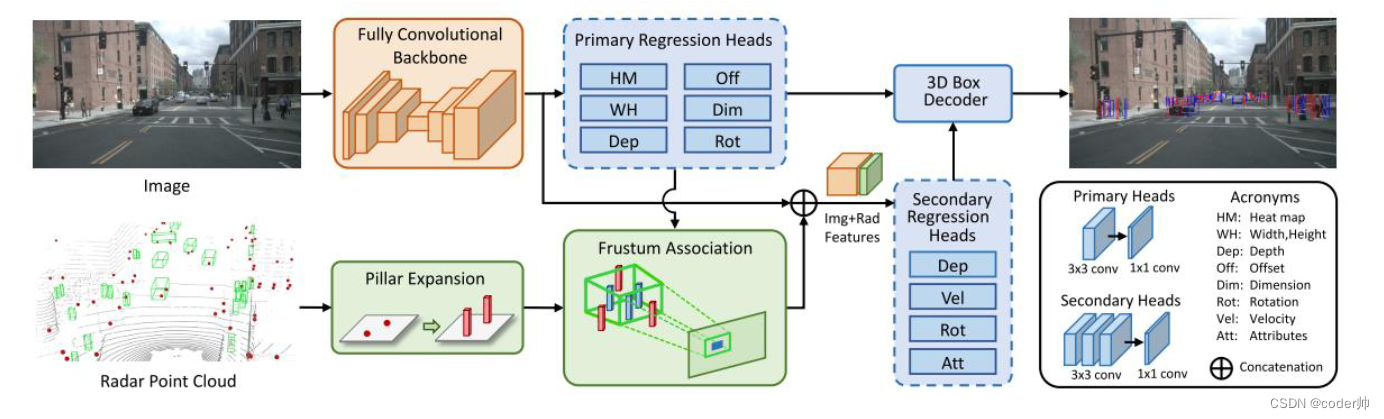 当我们获得2D BBox的位置(center point, offset, H, W)和框内像素的深度的初步估计,可以得到bbox的3D视锥大致范围,以此为依据滤除雷达背景点。
当我们获得2D BBox的位置(center point, offset, H, W)和框内像素的深度的初步估计,可以得到bbox的3D视锥大致范围,以此为依据滤除雷达背景点。
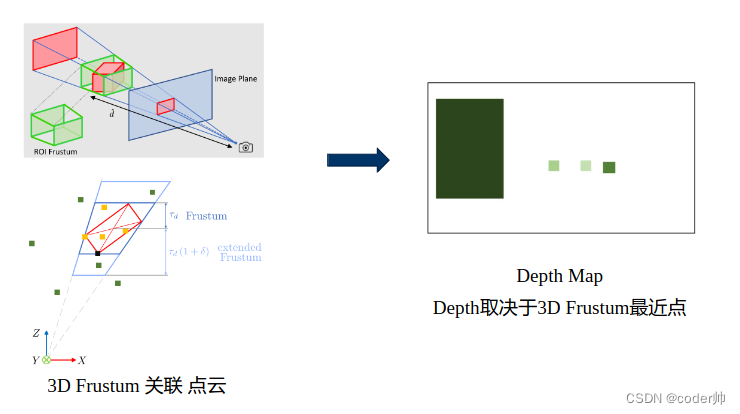
Radar点首先进行空间3D尺寸扩充(Pillar Extension), 再和图像回归出的3D Frustum关联(由于image depth估计存在误差, 对Frustum在深度上进行扩展)。把落入视锥的Radar点和对应雷达Depth Map上的2D BBox关联起来,作者以这个视锥内点的最小深度填充Depth Map.
因为 Radar 可以测速,因此还可以得到BBox内目标的速度信息。
另外,Radar点较稀疏,作者实行多帧叠加(3帧或以上)。
Feature Fusion: 在通道维度上拼接图像和雷达特征, 比图像feature多了Depth和Velocity两个通道。
将融合特征再次输入到第二个回归头,预测Depth, Velocity, Rotation, Attribute。对于重复回归项,相当于微调的作用。两次预测结果经过Decoder得到3D BBox.
3. 消融实验
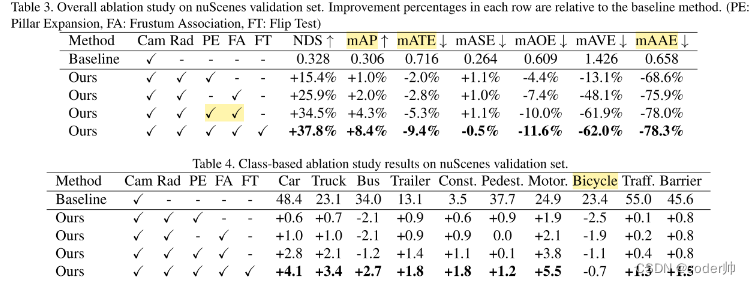
PE是Radar点扩展,FA是视锥关联,FT是增广翻转
能看到PE单独带来15.4%提升,FA单独25.9%提升,而二者结合带来34.5%的提升,说明扩展点云+视锥关联这种融合方式相辅相成对Radar点进行了前景和背景的分离,带来了更好的提升。
4. 实验思考
整个实验流程里有哪些值得借鉴?哪些还需改进的地方呢?
首先,Radar点云稀疏, 作者堆叠多帧处理,这是一个可以借鉴之处。
其次,Radar噪点是怎么进行过滤的呢?是用Image回归深度的视锥进行筛选的, 利用多模态感知的优势。
最后,图像和Radar特征表达存在差异,怎么关联二者的呢? 在BEV视角下的3D 视锥空间进行关联,这给了我们启发,很多BEV感知模型的View Transformer模块都是在3D空间下进行特征对齐。
问题: 视锥最近点深度填充Radar feature
- 最近点可能是噪点(深度无意义);
可以把视锥内点用PointNet等点云处理网络提取整体深度特征,而不是只用一点来代表整个视锥,可能提升鲁棒性。 - 重叠目标可能落入同一个视锥,小目标深度信息可能丢失。
用图像多尺度特征(FPN)分别和Radar点关联筛选,得到多个level的depth特征图,即把不同大小的目标分开回归。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









