









目录
1.4 大邻域搜索方法——邻域通过destroy和repair方法隐式定义
1.4.1 自适应大邻域搜索ALNS——为每个destroy和repair方法分配一个权重
这又是一种基于邻域的搜索算法,邻域及其邻域的相关知识可以看这篇——禁忌搜索(TS——Tabu Search)与邻域搜索基础知识。之所以单独拿出来,是因为邻域搜索Neighborhood Search(NS)(本质也是一种启发式算法)也是一个奇妙的分支。
自适应大邻域搜索算法(Adaptive Large Neighborhood Search)是由Ropke与Pisinger在2006年提出的一种启发式方法。它在邻域搜索的基础上增加了的对算子作用效果的衡量,使算法能够自适应选择好的算子对解进行破坏与修复,从而加速更好的解方案的产生。
在邻域搜索算法中,如果邻域搜索范围较小,那么即使使用额外的元启发式技术,如模拟退火或禁忌搜索,也很难摆脱陷入局部最优的情况;在大型邻域搜索技术中(如变邻域搜索算法),通过在当前解的多个邻域中寻找更满意的解,能够大大提高算法在解空间的搜索范围,但是它在使用算子时盲目地将每种算子形成的邻域结构都搜索一遍,缺少了一些启发式信息的指导且时间成本较高。
自适应大邻域搜索算法弥补了这种不足,首先ALNS算法允许在一次搜索中搜索多个邻域,它会根据算子的历史表现与使用次数选择下一次迭代使用的算子,通过算子间的相互竞争来生成当前解的邻域结构,而在这种结构中有很大概率能够找到更好的解。
1.邻域搜索及其大家族
1.1 邻域搜索涉及概念
邻域搜索算法(或称为局部搜索算法)是一类非常常见的改进算法,在每次迭代时通过搜索当前解的“邻域”找到更优的解。 邻域搜索算法设计中的关键是邻域结构的选择,即邻域定义的方式。 根据以往的经验,邻域越大,局部最优解就越好,这样获得的全局最优解就越好。 但是,与此同时,邻域越大,每次迭代搜索邻域所需的时间也越长。出于这个原因,除非能够以非常有效的方式搜索较大的邻域,否则启发式搜索也得不到很好的效果。所以仍然是时间和解的质量的平衡。
所谓邻域,简单的说即是给定点附近其它点的集合。在距离空间中,邻域一般被定义为以给定点为圆心的一个圆;而在组合优化问题中,邻域一般定义为由给定转化规则对给定的问题域上每结点进行转化所得到的问题域上结点的集合 。通俗一点:邻域就是指对当前解进行一个操作(这个操作可以称之为邻域动作,也可以称为 )可以得到的所有解的集合。那么不同邻域的本质区别就在于邻域动作的不同了。

1.2 邻域搜索的分类
邻域搜索:neighborhood serach,它有好多种衍生和变种出来的算法。比如大邻域Large Neighborhood Serach,LNS;超大规模邻域搜索算法Very Large Scale Neighborhood Search,VLSNA ;或者自适应邻域搜索Adaptive Large Neighborhood Search ,ALNS。名字很相近,实则大有不同。
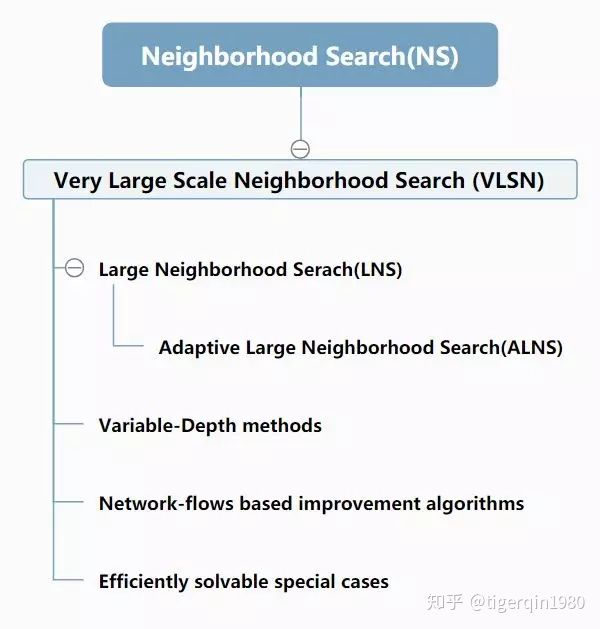
1.3 超大邻域搜索方法VLSN
当一个邻域搜索算法搜索的邻域规模随着算例规模的增大而呈指数增长,或者邻域太大而不能在实际中明确搜索时,我们把这类邻域搜索算法归类为Very Large-Scale Neighborhood Search(VLSN)。
一些超大规模的邻域搜索方法已经运用于运筹学中了,并且取得了不错的效果。 例如,如果将求解线性规划的单纯形算法看成邻域搜索算法的话,那么列生成算法就是一种超大规模的邻域搜索方法。 此外,用于解决许多网络流问题的方法也可以归类为超大规模的邻域搜索方法。 用于求解最小费用流问题的negative cost cycle canceling algorithm和用于求解分配问题的augmenting path algorithm就是两个例子。[1]
超大规模邻域搜索算法VLSN又可以分为三类:[1]
- Variable-depth methods
- Network-flows based improvement algorithms
- Efficiently solvable special cases
而Large Neighborhood Search(LNS) 则不属于以上三种类型,但它确实是属于VLSN这种类型的,因为它搜索的是一个非常大的邻域。
最后呢,是Adaptive Large Neighborhood Search(ALNS),它是根据Large Neighborhood Search(LNS) 算法扩展和延伸而来(嗯,相当于爸爸和儿子的关系……)。
1.4 大邻域搜索方法——邻域通过destroy和repair方法隐式定义
Large Neighborhood Serach,LNS,是VLSN的一个实例。大多数邻域搜索算法都明确定义它们的邻域。 在LNS中,邻域是由destroy和repair方法隐式定义的。destroy方法会破坏当前解的一部分,而后repair方法会对被破坏的解进行重建。destroy方法通常包含随机性的元素,以便在每次调用destroy方法时破坏解的不同部分。
当前解x经过destroy和repair方法以后生成的是一个邻域(邻居解的集合)。
那么,解x的邻域N(x)就可以定义为:首先通过利用destroy方法破坏解x,然后利用repair方法重建解x,从而得到的一系列解的集合(邻域)。
1.4.1 自适应大邻域搜索ALNS——为每个destroy和repair方法分配一个权重
ALNS是从LNS发展扩展而来的,在了解了LNS以后,我们现在来看看ALNS。ALNS在LSN的基础上,允许在同一个搜索中使用多个destroy和repair方法来获得当前解的邻域。
ALNS会为每个destroy和repair方法分配一个权重,通过该权重从而控制每个destroy和repair方法在搜索期间使用的频率。 在搜索的过程中,ALNS会对各个destroy和repair方法的权重进行动态调整,以便获得更好的邻域和解。
简单点解释,ALNS和LNS不同的是,ALNS通过使用多种destroy和repair方法,然后再根据这些destroy和repair方法生成的解的质量,选择那些表现好的destroy和repair方法,再次生成邻域进行搜索。
2.destroy和repair方法——邻域构建的关键
关于destroy和repair方法,在LNS和ALNS中是要组合在一起使用的。其实,一个解x经过destroy和repair方法以后,实则是相当于经过了一个邻域动作的变换。如下图所示:[1]
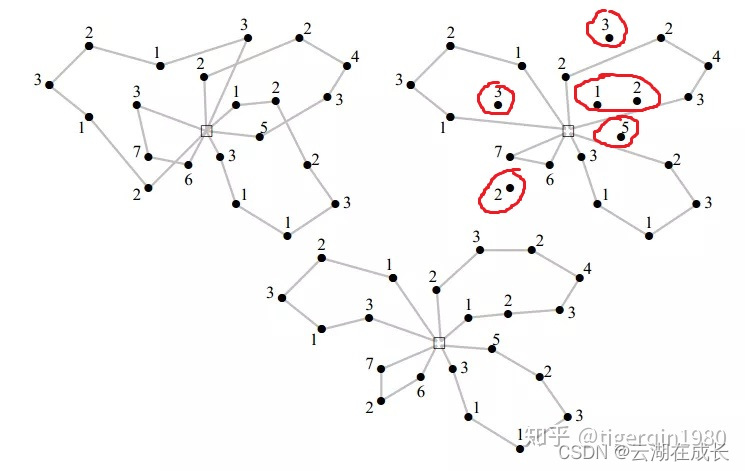
上图是三个CVRP问题的解,上左表示的是当前解,上右则是经过了destroy方法以后的解(移除了6个customers),下面表示由上右的解经过repair方法以后最终形成的解(重新插入了一些customers)。
上面展示的只是生成邻域中一个解的过程而已,实际整个邻域还有很多其他可能的解。比如在一个CVRP问题中,将destroy方法定义为:移除当前解x中15%的customers。假如当前的解x中有100名customers,那么就有C(100,15)= 100!/(15!×85!) =2.5×10的17次方 种移除的方式。并且,根据每一种移除方式,又可以有很多种修复的方法。这样下来,一对destroy和repair方法能生成非常多的邻居解,而这些邻居解的集合,就是邻域了。
3.ALNS的具体流程
3.1 LNS的伪代码
ALNS是由LNS扩展而来的,在了解ALNS之前,先来了解一下LNS的具体流程。下面是LNS的伪代码:[1]

LNS算法中包含三个变量。变量x^b记录目前为止获得的最优解,x则表示当前解,而x^t是临时解(便于回退到之前解的状态)。
函数d(.)是destroy方法,而r(.)是repair方法。详细点就是,d(x)表示破坏解x的部分,而r(x)则表示对破坏的解进行重新修复。
在第2行中,初始化了全局最优解。在第4行中,算法首先用destroy方法,然后再用repair方法来获得临时解x^t 。在第5行中,评估临时解x^t 的好坏,并以此确定该临时解x^t 是否应该成为当前新的解x(第6行)。
评估的方式因具体程序而异,可以有很多种。最简单的评估方式就只接受那些变得更优的解。注:评估准则可以参考模拟退火的算法原理,设置一个接受的可能性,效果也许会更佳。
第8行检查新解x是否优于全局最优解x^(b)。此处c(x)表示解x的目标函数值。如果新获得的解x更优,那么第9行将会更新全局最优解x^(b)。在第11行中,检查终止条件。在第12行中,返回找到的全局最优解x^(b)。
从伪代码可以注意到,LNS算法不会搜索解的整个邻域,而只是对该邻域进行采样搜索。也就是说,这么大的邻域是不可能一一遍历搜索的,只能采样,搜索其中的一些解而已。
3.2 ALNS的具体流程
在理解了LNS的基础上,理解ALNS也非常easy了。前面说过,ALNS对LNS进行了扩展,它允许在一次搜索中搜索多个邻域(使用多组不同的destroy和repair方法)。至于搜索哪个邻域呢,ALNS会根据邻域解的质量好坏,动态进行选择调整。好啦,来看伪代码:[1]

上面就是ALNS伪代码。相对于LNS来说,新增了第4行和第12行,修改了第2行。
和
分别表示destroy和repair方法的集合。第2行中的
和
分别表示各个destroy和repair方法的权重集合。一开始时,所有的方法都设置相同的权重。
第4行根据和
选择destroy和repair方法。至于选择哪个方法的可能性大小,是由下面公式算出的:[1]
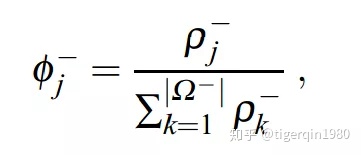
总的来说,权重越大,被选中的可能性越大。
除此之外,权重大小是根据destroy和repair方法的在搜索过程中的表现进行动态调整的(第12行)。具体是怎么调整的呢?这里也给大家说一说:
在ALNS完成一次迭代搜索以后,我们使用下面的函数为每组destroy和repair方法的好坏进行一个评估:[1]

其中, ,为自定的参数。
假如,a和b是上次迭代中使用的destroy和repair方法。那么其权重更新如下所示:
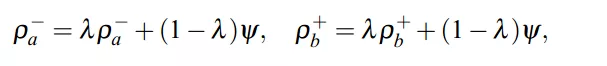
其中,λ∈[0,1],为参数。
再来给大家看个图
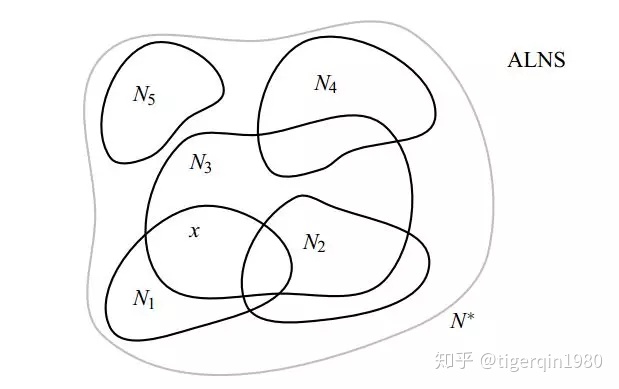
在一个ALNS算法中,有很多个邻域,每个邻域都可以看做是一组destroy和repair方法生成的。
参考链接:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









