






一、MonoScene
1.概要
a.使用单目相机,不用深度估计和点云来实现占据网络。
b.提出了一种2D-3D的一种转换方法。
c.在3D-unet底部加入3DCRP来捕获长距离的一个信息。
2.模型结构
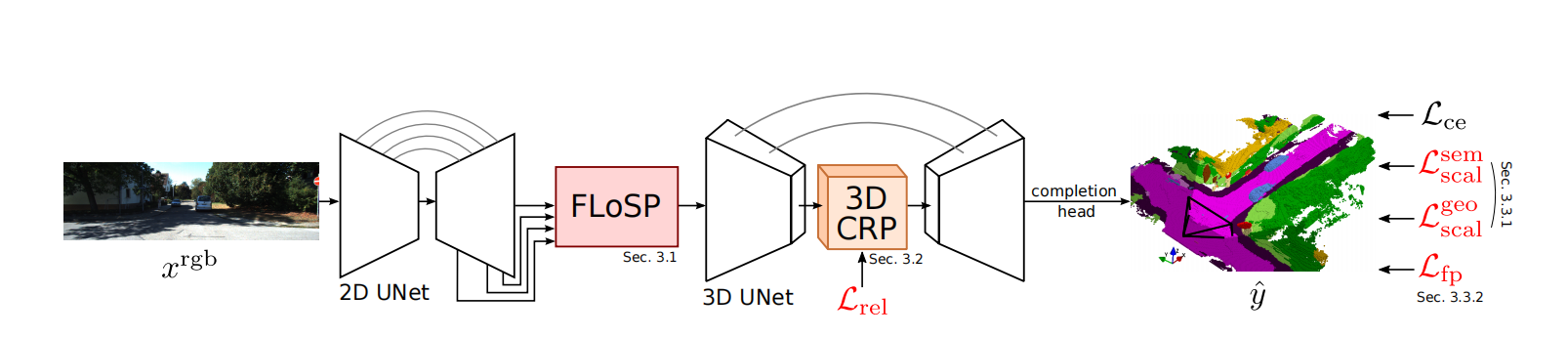
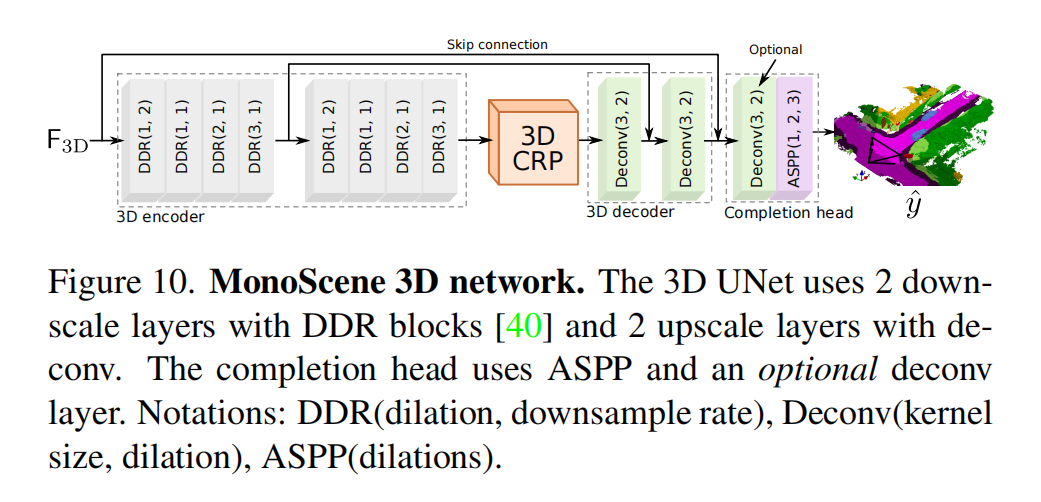
图像先经过一个2D的unet结构,这里论文里用的预训练的EfficientNet,然后经过一个论文里提出的FLOSP模块,从2D到3D,不过是一个多尺度的投影,再上采样concate。这里的转换模块个人感觉和FastBEV一样。后续3Dunet是一个简单的编解码网络,加入了空洞卷积和作者提出的一个3DCRP的结构。最后加入一个head完成多类别的一个语义分割 。
3.2D到3D转换(FLoSP)
说实话我感觉这个和FastBEV一样,这个多尺度的图片投影到不同的尺度的3D体素中,然后再聚合不同尺度的3D特征。
4.3D CRP
因为语义分割场景高度依赖于上下文的一个关系,所以论文里在3Dunet底部加入了一个CRP的结构,从而为网络提供了一个全局的感受野。这里因为全局语义分割存在极度的不均衡,所以单纯的二分类其实是次要的,论文里提出了体素与体素之间的一个关系,从而增强模型的上下文之间的关联。这里怎么划分体素之间的关系我有点看不懂原文的描述,原文这里很乱。
二、 VoxFormer
1.摘要
a.提出一种两阶段的框架,使用图像生成完整的3D体素化语义场景。
b.预测图像深度,再生成稀疏的体素,使用transformer进一步得到完整的体素语义场景 。
2.模型结构


先对图像的特征进行提取,同时对其深度也进行估计,根据相机内外参投影到体素里,得到一个稀疏的Q,这个Q与图像特征进行交叉注意力机制,加上mask token后再做一个自注意力的操作,相当于对语义场景进行补全,最后上采样做多类别语义分割。
3. 第一阶段的query
初始化定义的query是忽略类别的,h*w*z*d,这个尺度相较于最终的语义分割尺度进行了2倍降采样,主要是为了提高模型的一个鲁棒性,防止因为深度预测误差过大,像素点没有落到该有的体素内。
根据深度估计和相机内外参,我们可以得到许多3D空间的点云,但此时这个点云是非常不可靠的,特别是在远处,几个点云决定了一大片区域的深度。为了降低深度容错和提高模型的鲁棒性,使用了一个简化版的unet网络对Min(H*W*D)进行卷积占据预测,输出Mout(h*w*d)表示是否占据。
根据是否占据,我们在q里面选择占据的query出来,组成Qp。这里有个疑问Qp的个数会变化呀?不是固定数量的query也可以吗?这里的好处是跳过空白的区域,只对图像上看到的地方进行query。
4.第二阶段补全query后的语义分割
使用deformable交叉注意力机制,Qp有一个3D坐标,投到图像上有一个参考点,根据偏移和权重,在多个时序图上进行特征的提取。经过几层可变形交叉注意力之后,我们把Qp与mask token结合得到完整的体素特征。然后使用可变形自注意力机制,对完整的体素特征进行细化。然后再上采样到原始的分辨率,对其进行多类别语义分割。
这里的mask token是一个d维的可学习向量,主要用于填充第一阶段没有对应图像的一些体素,同时这些mask token也加入了位置编码,来让其对自己的位置有一定的了解。
三、TPVFormer
1.摘要
a.提出了一种新颖的三维空间表示方法,相较于体素,计算量大大下降,相较于BEV,其对空间的细粒度三维结构表示更加丰富。
b.使用可变形注意力机制生成空间三视图,可以完成任意分辨率的空间占据表示。
2.模型结构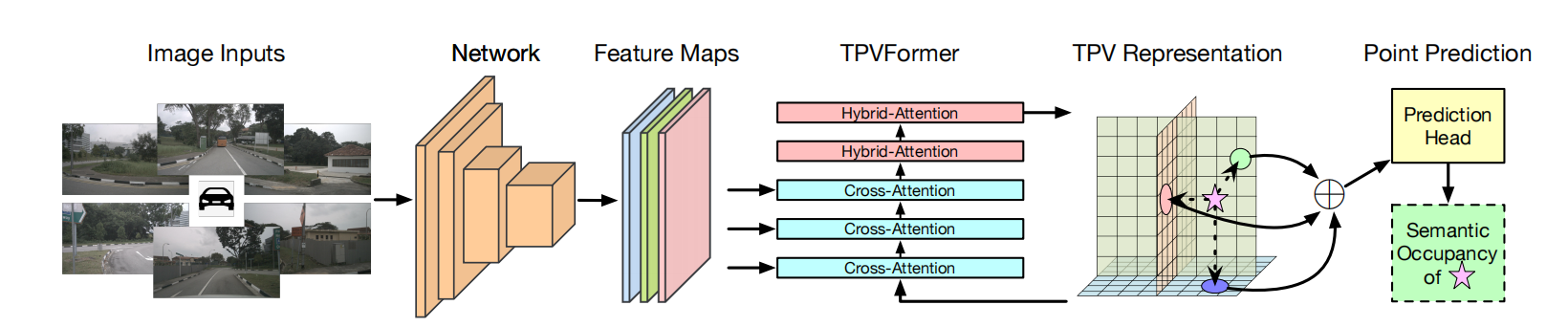
图像先通过backbone和Neck提取相应的特征,然后TPV query向图像进行可变形注意力机制查询,再加上三个平面之间的特征交互,最终生成TPV的特征,我们根据这个图,可以插值得到最终3D空间的占据预测。这里的TPV query是最终三个视图里面的每个像素点,t∈T。
3.Image cross attention
在进入这个模块时,先对TPV query添加位置编码。 考虑到TPV query的个数以及图像像素的个数,所以我们不进行全局注意力机制,而使用可变形注意力机制。比如一个俯视图的TPV query,他有一个xy,那么我们对z进行间隔采样,会得到许多3D点,然后我们对这些3D点向一张图像做投影,可以得到一些有效投影点,对这些有效投影点做可变形注意力机制,最后对六张图像的可变形注意力机制结果求平均。

4.Cross-View Hybrid-Attention
因为上面每个视图单独查询图像特征,他们之间并没有充分的交互,所以提出交叉视图混合注意力机制,有利于上下文特征的提取。比如俯视图上一个点,我们直接在其周围生成一些参考点,然后沿着z生成几个3D点,投影到前视图和左视图,又能得到几个参考点,对这些参考点做可变形注意力机制,得到最终的特征。 
四、SurroundOcc
1.摘要
a.使用由粗到细的思想策略,先生成小分辨率的体素特征,再逐步上采样,生成密集的体素特征。
b.针对占据网络稀疏的GT监督,论文提出了一种生成密集占据标签的方法。
2.模型结构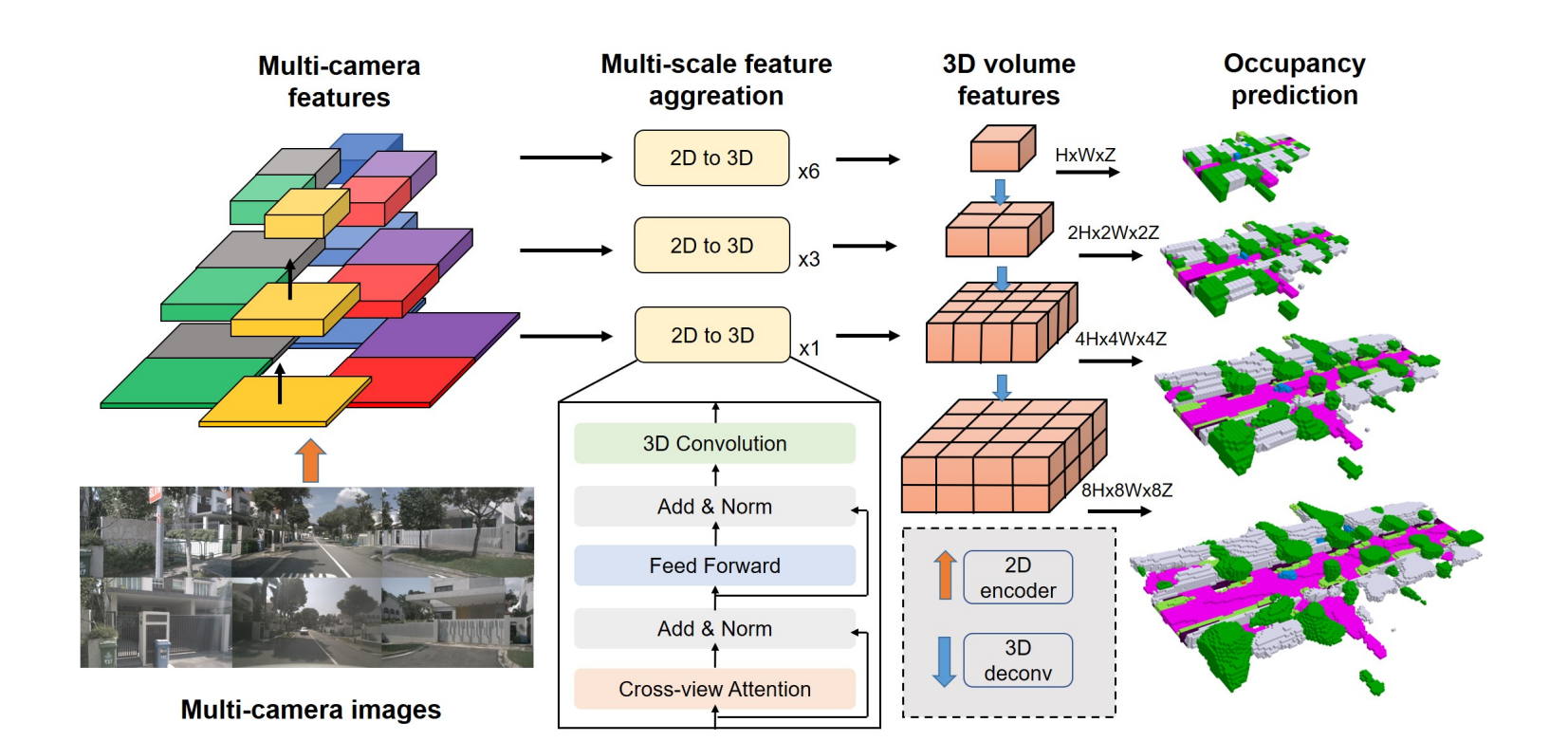
首先提取图像的多尺度特征信息,然后使用类似于bevformer的思想,使用可变形交叉注意力机制,完成2D到3D的特征转换,后续再加一些3D卷积。把低分辨率的3D体素特征逐层上采样合并,最后加head完成预测。我们对不同尺度的3D体素都施加监督,不过监督权重呈衰减形式,从上到下由大到小。
3.密集占据真值生成
多帧点云拼接,将点云分为动静态,静态根据车身位姿变化堆叠在一起,然后动态的根据track id合并填充进去。这样聚合完还是会存在一些空洞的区域,根据其邻域中的空间分布计算法向量,使用poisson曲面重建算法来进行补全。最后使用最近邻算法来对空白网格的语义进行填充。
五、OpenOcc
1.摘要
a.使用AAP(Augmenting And Purifying)方法对nuScenes数据生成密集的占用语义标签。
b.提出lidar和camera结合的占用网络,同时采用由粗到细的cascade策略提升性能。
2.模型结构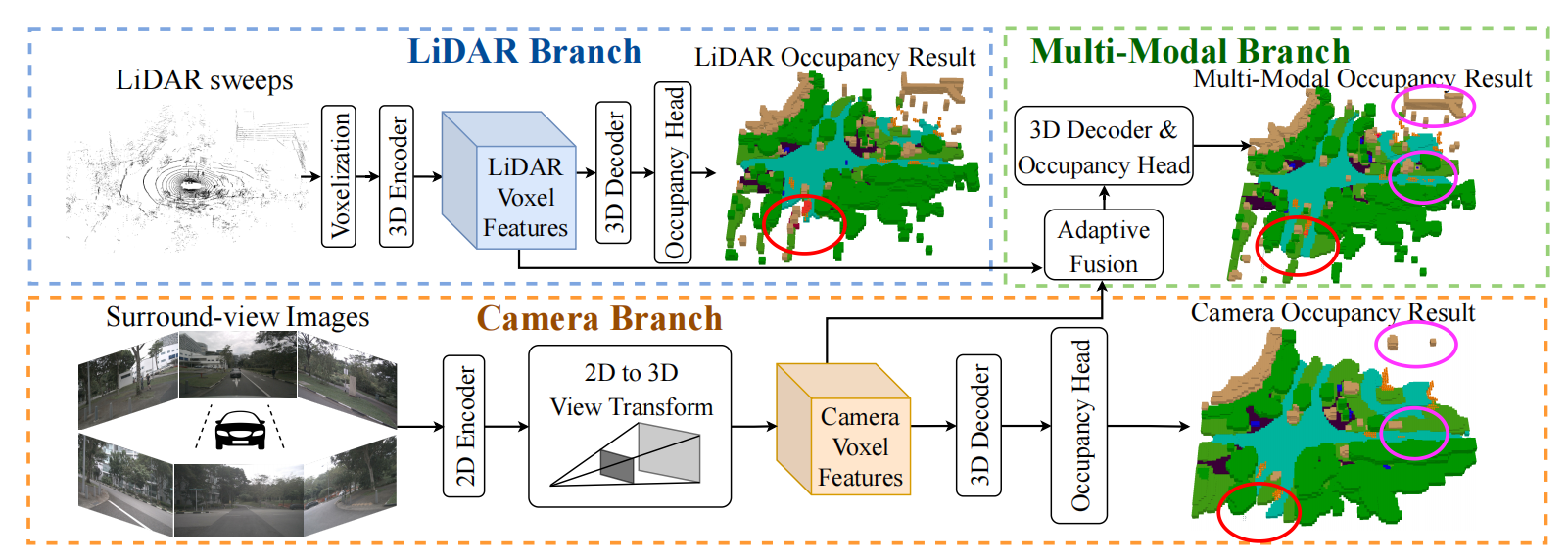
LiDAR分支先对点云进行体素化操作,然后使用3D稀疏卷积得到(D/S, H/S,W/S)特征 ,后续解码器将其降采样再上采样合并,最终softmax进行3D语义预测。
Camera分支先提取图像的特征,然后将其转换到3D下,进行和lidar一样的操作。
对于lidar和camera的融合,我们采用自适应的融合模块,动态的整合图像和lidar的特征。先把lidar和camera特征在channel维度合并,然后再卷积sigmoid生成权重。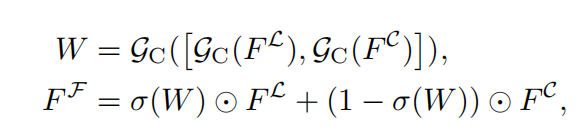
3. Cascade Occupancy Network
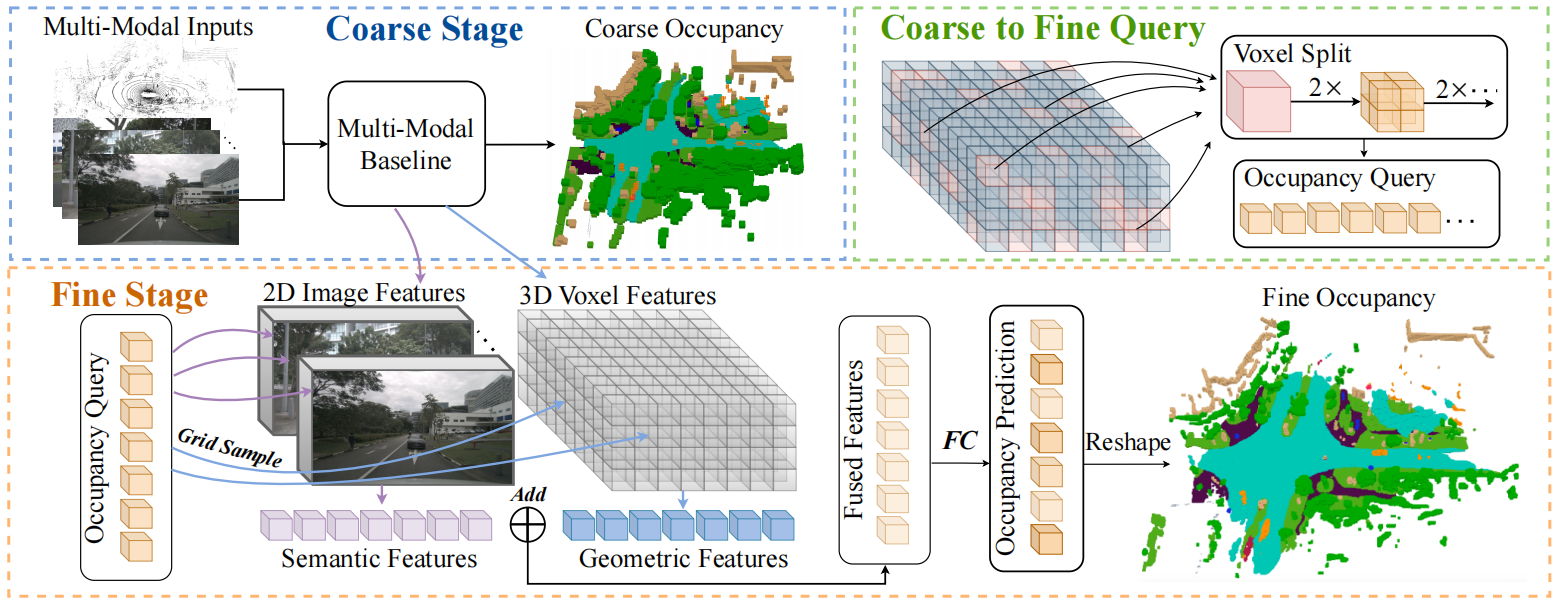
多模态模型生成的粗略体素特征大小为(D/S, H/S,W/S),这里论文里选取的S是4,然后我们对体素里面预测为占据的地方进行切割划分,比如一个大体素,切成8个小的,他们向图像投影得到语义特征,向体素特征查询得到几何特征(这里不太懂,是指大体素的18维特征直接拿来当他的8个小体素的几何特征吗?)在特征维度合并后,加上FC层进行精细化的占据预测。
4.nuScenes-Occupancy数据集生成
前面的操作和surroundocc里一样多帧对齐,然后我们用这个含有一定空白的数据训练一版模型。使用模型对本帧数据进行预测,得到一个预测的占据结果,加上原始的密集占据标签,原始里面空白的地方用预测的结果填充,得到全面的一个占据结果。但是这个GT存在一定的误标注,因为模型推理不一定正确,所以后续人工又进行了错误标注删除的操作。从而得到最终的密集标注结果。


















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











