










本文总结于王岩博士在2021年9月11日在深蓝学院的公开课。王岩博士就读于康奈尔大学,提出的基于伪点云的纯视觉3D物体检测算法广泛应用于工业界。
本次的讲座分为如下几个部分,第一个是关于用相机做深度估计和背景检测的背景和动机,第二个是单目和双目深度估计算法的基础,第三个是关于深度检测的优化和提升,第四个是关于目前存在的问题。
首先,为什么要做3d物体检测,因为在自动驾驶场景中,我们通常需要去感知场景中的每一个物体,只有在这个基础上,我们才能进一步进行物体跟踪和路径规划,也就是说,物资检测是自动驾驶感知流程的一个基石。
在自动驾驶场景中,比较常用的感知传感器是激光雷达,但是,激光雷达所对应的问题之一在于高成本,而相比之下,相机就廉价了很多,因此,我们希望用相机而不是激光雷达去满足一些感知需求。另一方面,在雨,雾,霾等天气条件下,激光雷达所获取的深度图将夹带很大的噪声,只依赖激光雷达将在很多场景造成不确定性。还有一个问题在于激光雷达点云的稀疏性,也就是近的点相对稠密,而远的点会很稀疏,这会让远距离物体的估计非常困难。面对激光雷达的这些问题,我们关注的是能否通过相机来辅助甚至去取代激光雷达的功能。
我们再来回顾一下如何用激光雷达和相机去检测3D物体。激光雷达的数据可以用点云或者栅格来直接表达物体。而针对图像,我们还需要从图像中获取深度信息才能得到对应的检测框。然后,一些实验效果证明,当被检测的物体在30米以外时,基于图像3d检测结果相对于激光雷达相差甚远。
而这背后的原因又是什么呢?我们所提出的的第一个猜想就是基于图像得到的深度信息非常不不准确,因此得到的检测框信息也很不准确。为了进行验证,我们把从图像估计出的深度图通过转换与激光雷达的点云进行对比,而观察结果是,两者非常接近,因此否定了深度图估计不准的猜想。
除此之外,我们提出的另一个猜想就是深度图的“表达方式”问题,因为在物体边界位置,相邻的像素可能⼀个在物体上,⼀个在背景,因此深度相差很⼤。在进⾏2D卷积时,卷积会对相邻的点进⾏加权平均,在物体边界处会把物体拉伸,不能反映真实世界的情况。基于这个猜想,我们提出了一种伪激光雷达的方案,当我们得到深度图后,我们将其转化为点云的表达形式,而实验结果显示,检测效果也因此得到了显著地提升。此外,我们也对比了单目和双目的识别效果,而实验结果证明,双目的效果要明显好于单目相机。
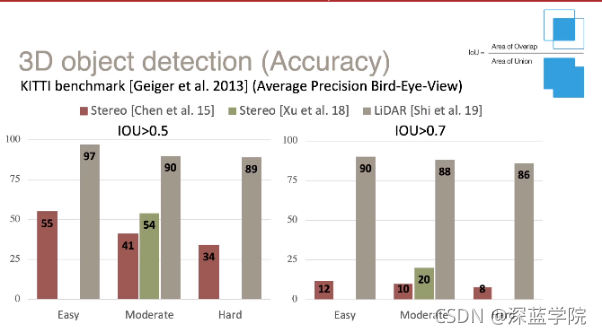
图一:相机和雷达在不同难度场景下的识别精度
然而,伪激光雷达得到的深度还是有一定误差,如何对于深度估计的效果进行提升呢?
我们先来介绍一下相机的深度估计的原理,针对双目相机和深度几何,我们都可以利用对极几何的基本原理来时实现深度估计,而对于单目相机,我们可以把视频作为输入,然后通过structure from motion的方式去实现。
而如何用深度学习的方式来实现对于深度以及不同帧的位姿的估计呢?比较有代表性的思路是使用两个卷积神经网络分别实现对于单帧图像深度的估计以及多帧图像的位姿估计,基于位姿和深度信息,我们可以预测一帧图像上一点在下一帧的位置,然后计算这两个位置像素值的差,称为photometric损失函数,来训练⽹络。最终这个网络也将同时输出深度和位姿信息。这个方案同样存在一些明显的问题,比如,它是基于场景物体都是静止的假设,而这在自动驾驶的场景是基本不成立的。目前有一些工作就在研究估计运动物体的深度信息。
回到我们的主线,图像信息的深度估计,当我们有双目相机的图片时,我们就可以通过图像特征的视差(disparity)和焦距以及基线等信息实现对于深度的恢复。而如何用深度学习去解决这个问题呢?接下来介绍一下现在的主流方法,当我们有了深度图像后,我们可以通过一个2维的卷积去得到它的深度特征,在此基础上,我们可以建立代价体(cost volumn),并用一个维度来存储视差,对于这个维度,再通过softmax的处理方式,就可以得到不同视差的概率分布,并选择最大值或者期望作为最终估计。为了训练网络,我们可以从lidar中采取真值进行训练。然而,视差和深度存在着反比的关系,这会造成对于远处的物体,微小的视差区别将造成深度估计的很大变化,因此,一种思路是直接用深度而不是视差参与网络和代价体的设计,实验证明,这样确实可以让物体检测的效果显著提升。
然而,深度图的估计因为涉及到代价体的建立,通常需要较长的时间估计。通过降低分辨率的思路设计网络虽然可以提高速度,但是也会降低精度。
对于深度图,它自身的问题在于图像近大远小的特性,使得近处的物体对应的像素点多,因此训练时的权重也就更大,另外,这也会造成代价体的信息分布不均匀。面对深度图的诸多问题,一种解决思路是,直接从图像生成伪3D点云。这样,我们直接建立基于伪激光雷达的代价体,这时得到的代价体将会有均匀分布的优点。基于这样的思路设计后,网络的处理速度得到了很大提升,除此之外,识别精度也得到了提高,并接近激光雷达的识别效果。

图二:伪点云和四线的激光雷达点云可视化
接下来介绍的工作关于多传感器融合。激光雷达的价格和线束通常成正比,因此,我们想尝试使用低线束的激光雷达点云和通过图像生成的伪点云进行融合。融合的目的是为了把错误位置的伪点云进行纠正。去实现这样的纠正,我们首先对于每个点进行K最近邻搜索,并计算邻居点的权重,权重的作用是为了通过最近邻实现对于点的重构。然后,我们将激光雷达的点加入并投影到图像上,并和伪点云的点进行匹配。接下来,我们将利用最小二乘的思想调整伪点云的点进行重构。
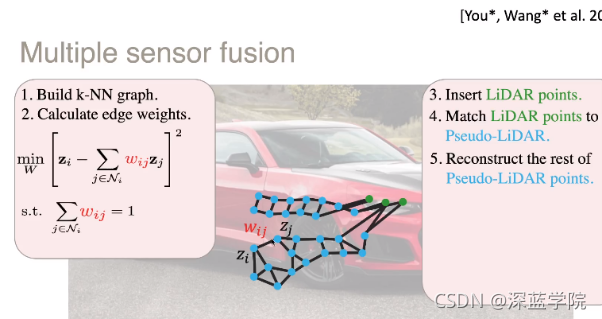
图三:利用稀疏点云信息纠正图像伪点云
关于今天的讲座,做一个简单的总结,今天我主要介绍了我自己关于用相机做三维目标跟踪的一些工作。首先是使用点云而不是深度图去代表3D点,然后是把基于视差的模型训练改为了直接用深度,以及直接预测点云而不是深度图,最后是关于我们提出的传感器融合的方法。虽然,这些方法得到的点云和目标检测的效果性能已经接近激光雷达,但是仍然有一定差距,也需要大家接下来的进一步努力。
点击下方可以观看直播公开课
自动驾驶纯视觉3D物体检测算法 - 深蓝学院 - 专注人工智能的在线教育 https://www.shenlanxueyuan.com/open/course/112
https://www.shenlanxueyuan.com/open/course/112

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









