







论文标题:
SemCity: Semantic Scene Generation with Triplane Diffusion
论文作者:
Jumin Lee1, Sebin Lee1, Changho Jo, Woobin Im, Juhyeong Seon, Sung-Eui Yoon
项目地址:https://sglab.kaist.ac.kr/SemCity/
前言:
该论文已被CVPR24接收,提出了一个可用于户外真实场景的生成的三维扩散模型。其利用Triplane
Diffusion方法,不仅出色完成户外真实场景的生成,还可以无缝的进行场景生成等的扩展任务(如:Scene Inpainting,Scence Outpainting,语义场景完成细化)。©️【深蓝AI】编译
1. 背景介绍
扩散(Diffusion)模型是当前主流的场景生成工具,尤其在图像领域取得了很好的效果。当前无论是学术界还是工业界,都在积极探索扩散模型在三维数据(3D data)生成领域的应用场景,并且有些扩散模型在生成各种三维形式(如体素、网格)方面也有不俗的表现。尽管这些三维扩散模型主要旨在制作单个物体,但生成由多个物体组成的场景仍然是三维扩散暂未探索到的领域。
场景生成扩散模型旨在制作几何和语义上协调一致的环境。与单个物体生成相比,生成包含多个物体的场景,由于其空间范围更广,需要对更复杂的几何和语义结构有更深入的理解。场景生成扩散模型主要有两个方向,分别针对室内和户外环境。特别是户外环境比室内环境具有更广阔的景观,但同时挑战更大。
在本文中,作者提出了SemCity方法,它是一种用于实际户外环境语义场景生成的三维扩散模型。具体来说,SemCity利用三平面表示(Triplane Representation)来处理更广阔的户外场景,这是一种将三维数据分解到三个正交二维平面上的方法,已经被广泛应用于三维物体重建和NeRF模型中。三平面表示方法在解决户外数据集中通常存在的数据稀疏问题(这是由于传感器限制,譬如遮挡、范围限制等在捕捉户外场景时造成的)方面有一定的优势,它可以通过将三维数据分解到二维平面来减少不必要的空白信息的包含。
这种捕捉相关空间细节的效率使其成为表示户外环境中通常存在的众多物体的有效工具。
在本文中,作者通过重建场景的语义标签,利用一个三平面自编码器学习将体素化场景压缩为三平面表示。此外,研究者还训练三平面扩散模型并用于生成新场景,如图1(a)所示, 通过基于高效表示创建新的三平面。且其能够将三平面扩散模型扩展到几个实际任务(即场景修复、场景扩展和语义场景完成细化),如图1(b-d)所示。

图1|SemCity 扩散模型户外场景生成概览©️【深蓝AI】编译
本文主要贡献:
●作者揭示了三平面表示在生成实际户外环境的语义场景中的适用性,并将其扩展到场景修复、场景扩展和语义场景完成细化等实际下游任务。
●同时提出在扩散过程中操作三平面特征,无缝地将该方法扩展到下游任务(如添加、删除或修改场景中的物体)。
●明了该方法在真实户外环境中显著提高了生成场景的质量。
2. 相关工作
2.1 扩散模型
通过基于评分函数的迭代去噪过程学习数据分布。其生成的结果在各种2D图像合成任务中展现了非常逼真的外观、高保真度和多样性,如outpainting、inpainting和文本到图像生成。在这些基础上,扩散模型也被扩展到3D领域,在各种3D形状中生成了不错的结果,包括体素网格、点云、网格和隐式函数。虽然这些模型可以制作单个3D物体,但SemCity专注于使用分类体素数据结构生成由多个物体组成的3D场景,这是3D扩散领域相对较少探索的领域。
2.2 场景生成的扩散模型
与单个物体生成相比,场景生成涉及对更大3D空间的理解,导致更多语义和几何复杂性。在室内环境中,扩散模型旨在通过表示为场景图来学习对象之间关系的分布。场景图包含对象属性(如位置、方向和大小),捕捉有限空间内复杂的对象间关系。对于户外场景,不同的是它通常包含大量空旷区域(如天空、开放区域)。传统方法依赖于体素空间上的离散扩散方法,需要对每个空气体积进行详细表示,而SemCity是通过将3D空间抽象为三个正交的2D平面,三平面表示有效地捕捉了以空气为主的户外环境的广阔性。
2.3 3D Inpainting and Outpainting
3D Inpainting的主要目标是填补缺失部分或修改现有元素,同时保持几何一致性。大多数现有工作集中在单个物体修复,例如将3D椅子的腿数从三个过渡到四个。与修复相反,3D Outpainting是在未观察到的空间外推给定的场景。现有工作专注于在有界的室内环境内进行场景外推。而在2D图像中,修复和外推并不限于单个物体。同样地,在3D空间中,本文更关注场景级修复,SemCity可以无缝地添加、删除或修改场景中的物体。此外,本文的场景级Outpainting不局限于有界的场景,可以从传感器范围(如LiDAR)扩展到城市规模的户外场景。
2.4 语义场景完成
语义场景完成(Semantic Scene Completion: SSC)对于3D场景理解至关重要,它从传感器观测(如RGB图像或点云)中共同推断3D场景的完成和语义分割。此外,SSC在支持全面自主导航系统的关键下游任务(如路径规划和地图构建)中发挥关键作用。尽管该领域取得了重大进展,但一个持续的挑战是SSC估计的场景与其真实对应物之间存在语义和几何差异,如图1©所示。这些差异可能会损害下游任务的性能。本文的三平面扩散模型可以通过利用3D场景先验来帮助弥合这一差距。这种方法提高了SSC的可靠性和有效性,预计将改善其在自主导航系统中的应用。
3. 方法精析
本节重点阐述SemCity中的三平面扩散模型及其扩展。

图2|SemCity工作原理©️【深蓝AI】编译
3.1 Representing a Semantic Scene with Triplane
为了将3D场景表示为三平面,自编码器学习将3D场景压缩为如图2(a)所示的三平面表示。自编码器由两个模块组成:
1)一个编码器 f θ f_{\theta} fθ,产生一个三平面
2)一个隐式多层感知机(MLP)解码器 g θ g_{\theta} gθ,用于从三平面重建。
编码器 f θ f_{\theta} fθ接受一个体素化的场景 x = R X × Y × Z \mathbf x = \mathbb R^{X \times Y \times Z } x=RX×Y×Z,其中包含 N N N个类别,空间网格分辨率为 X × Y × Z X \times Y \times Z X×Y×Z。它产生一个轴对齐的三平面表示 h = [ h x y , h x z , h y z ] \mathbf h = [\mathbf h^{xy}, \mathbf h^{xz}, \mathbf h^{yz}] h=[hxy,hxz,hyz]。三平面由三个平面组成,每个平面都有不同的维度特性: h x y ∈ R C h × Y h × Z h , h x z ∈ R C h × Y h × Z h \mathbf h^{xy} \in \mathbb R^{C_h \times Y_h \times Z_h},\mathbf h^{xz} \in \mathbb R^{C_h \times Y_h \times Z_h} hxy∈RCh×Yh×Zh,hxz∈RCh×Yh×Zh和 h y z ∈ R C h × Y h × Z h \mathbf h^{yz} \in \mathbb R^{C_h \times Y_h \times Z_h} hyz∈RCh×Yh×Zh,其中 C h C_h Ch表示特征维度 X h 、 Y h X_h、Y_h Xh、Yh和 Z h Z_h Zh表示三平面的空间维度。在编码阶段,通过3D卷积层从场景 x \mathbf x x中提取3D特征体积,然后通过轴向平均池化得到三平面。给定3D坐标 p = ( x , y , z ) \mathbf p = (x, y, z) p=(x,y,z),三平面被解释为从每个平面双线性插值的向量之和: h ( p ) = h x y ( x , y ) + h x z ( x , z ) + h y z ( y , z ) \mathbf{h(p)} = \mathbf h^{xy}(x, y) + \mathbf h^{xz}(x, z) + \mathbf h^{yz}(y, z) h(p)=hxy(x,y)+hxz(x,z)+hyz(y,z)。为了重建3D场景 x \mathbf x x,通过使用隐式MLP解码器 g θ g_{\theta} gθ解码编码的三平面 h \mathbf h h,该解码器预测语义类概率。解码器采用三平面向量 h ( p ) \mathbf {h(p)} h(p)及其正弦位置编码 P E ( p ) {PE}(\mathbf p) PE(p),得到类概率 c ( p ) = g θ ( h ( p ) , P E ( p ) ) ∈ [ 0 , 1 ] N \mathbf {c(p)} = g_{\theta}(\mathbf{h(p)}, {PE}(\mathbf p)) \in [0, 1]^{N} c(p)=gθ(h(p),PE(p))∈[0,1]N。位置编码根据坐标 p \mathbf p p产生高频特征,有助于隐式解码器表示高频场景内容。编码器 f θ f_{\theta} fθ和MLP解码器 g θ g_{\theta} gθ使用自编码器损失 L A E \mathcal L_{AE} LAE和场景标签 x ( p ) \mathbf {x(p)} x(p)进行训练,如公式(1)所示,其中 λ \lambda λ是损失权重, P \mathcal P P是场景网格坐标集合,并使用加权交叉熵损失 ℓ C E \ell_{CE} ℓCE和Lovász-softmax损失 ℓ L Z \ell_{LZ} ℓLZ来学习场景中不平衡的语义分布。
L A E = E p ∼ P [ ℓ C E ( c ( p ) , x ( p ) + λ ℓ L Z c ( p ) , x ( p ) ) ] ( 1 ) \mathcal L_{AE} = \mathbb E_{\mathbf p \sim \mathcal P}[\ell_{CE}(\mathbf{c(p), x(p)} + \lambda \ell_{LZ}\mathbf{c(p), x(p)}) ]\qquad(1) LAE=Ep∼P[ℓCE(c(p),x(p)+λℓLZc(p),x(p))](1)
3.2 Triplane Diffusion
基于3D语义场景的三平面表示,其中三平面扩散模型 D ϕ D_{\phi} Dϕ通过去噪扩散概率模型学习生成新的三平面,如图2(b)所示。这种三平面生成最终通过使用隐式MLP解码器 g θ g_{\theta} gθ解码生成的三平面来生成3D场景。通过参数化,扩散模型 D ϕ D_{\phi} Dϕ被训练去重建给定其从扩散过程 q ( h t ∣ h ) = N ( α ˉ h , ( 1 − α ˉ t ) I ) q(\mathbf h_{t}|\mathbf h) = \mathcal N (\sqrt{ \bar{\alpha}}\mathbf h, (1 - \bar{\alpha}_t)I) q(ht∣h)=N(αˉh,(1−αˉt)I)中采样的受损三平面 h t \mathbf h_{t} ht,其中 N \mathcal N N是高斯分布, α ˉ t = ∏ i = 1 t α i , α t = 1 − β t , β t \bar{\alpha}_t = \prod\limits_{i=1}^t \alpha_i,\alpha_t = 1 - \beta_t,\beta_t αˉt=i=1∏tαi,αt=1−βt,βt是方差时间表。扩散过程 q ( h t ∣ h ) q(\mathbf h_{t}|\mathbf h) q(ht∣h)是从单步扩散过程 q ( h t ∣ h t − 1 ) = N ( 1 − β t h t − 1 , β t I ) q(\mathbf h_{t}|\mathbf h_{t-1}) = \mathcal N (\sqrt{1-\beta_t}\mathbf h_{t-1}, \beta_tI) q(ht∣ht−1)=N(1−βtht−1,βtI)导出的马尔可夫链规则。因此,三平面扩散损失定义为:
L D = E t ∼ U ( 1 , T ) ∥ h − D ϕ ( h t , t ) ∥ p ( 2 ) \mathcal L_D = \mathbb E_{t \sim \mathcal U(1, T)} \parallel \mathbf h - D_\phi(\mathbf h_t, t)\parallel_p\qquad(2) LD=Et∼U(1,T)∥h−Dϕ(ht,t)∥p(2)
其中 T T T是去噪步数, p p p表示范数的阶。时间步长 t t t从离散均匀分布 U \mathcal U U中采样。训练后,扩散模型 D ϕ D_{\phi} Dϕ通过从 h T ∼ N ( 0 , I ) \mathbf h_T \sim \mathcal N(0, I) hT∼N(0,I)开始的迭代DDPM生成过程生成新的三平面 h 0 \mathbf h_0 h0:
h t − 1 ∼ N ( γ t h t + δ t D ϕ ( h t , t ) , β t 2 I ) ( 3 ) \mathbf h_{t-1} \sim \mathcal N(\gamma_t \mathbf h_t + \delta_tD_\phi(\mathbf h_t, t), \beta_t^2\mathbf I)\qquad(3) ht−1∼N(γtht+δtDϕ(ht,t),βt2I)(3)
其中 γ t : = α t ( 1 − α ˉ t − 1 ) / ( 1 − α ˉ t ) , δ t : = α t − 1 β ˉ t / ( 1 − α ˉ t ) \gamma_t := {\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}/{(1 - \bar{\alpha}_{t} )},\delta_t := {\sqrt{\alpha_{t-1}}\bar{\beta}_{t}}/{(1 - \bar{\alpha}_{t} )} γt:=αt(1−αˉt−1)/(1−αˉt),δt:=αt−1βˉt/(1−αˉt)。从生成的三平面 h 0 \mathbf h_0 h0,通过查询坐标 p \mathbf p p到隐式解码器 g θ ( p 0 ( p ) , P E ( p ) ) g_\theta(\mathbf p_0(\mathbf p), PE(\mathbf p)) gθ(p0(p),PE(p))来生成新的3D语义场景 x 0 x_0 x0。
3.3 Applications with Triplane Manipulation
如上所述,基于三平面扩散过程允许模型在进行少量修改的情况下促进各种实际的下游任务。
Scene Inpainting:通过随机编辑3D场景,无缝地添加、修改或删除物体,同时保持场景的一致性和真实性。例如,修复包括汽车或人行道出现然后消失,或者相反的情况,如图1(d)所示。受到RePaint采样策略的启发,本文提出了一种具有语义一致性的3D感知修复方法。不同于RePaint只专注于图像域,而没有明确考虑底层3D场景的保真度。为了实现3D感知修复,作者对三平面进行修复,作为场景的紧凑代理表示。SemCity方法定义了一个二进制空间遮罩 m = [ m x y , m x z , m y z ] \mathbf m = [\mathbf m^{xy}, \mathbf m^{xz}, \mathbf m^{yz} ] m=[mxy,mxz,myz],覆盖三平面空间上的修复区域,允许控制生成过程中的遮罩区域。遮罩 m / \mathbf m/ m/被设置为修复区域为1,其他区域为0。通过覆盖生成过程(公式3)中的第 t t t个三平面 h t = [ h t x y , h t x z , h t y z ] \mathbf h_t = [\mathbf h_t^{xy}, \mathbf h_t^{xz}, \mathbf h_t^{yz} ] ht=[htxy,htxz,htyz],如公式4所示。
h t ← m ⊗ h t + ( 1 − m ) ⊗ h t k n o w n ( 4 ) \mathbf h_t \leftarrow \mathbf m \ \otimes \ \mathbf h_t + (1 - \mathbf m) \otimes \mathbf h_t^{known}\qquad(4) ht←m ⊗ ht+(1−m)⊗htknown(4)
其中 ⊗ \otimes ⊗是元素级乘积,完整区域的已知三平面 h t k n o w n \mathbf h_t^{known} htknown是从扩散过程 q ( h t k n o w n ∣ h ) : = q ( h t ∣ h ) q(\mathbf h_t^{known} | \mathbf h) := q(\mathbf h_t | \mathbf h) q(htknown∣h):=q(ht∣h)中采样的,它遵循已知的高斯分布。
Scene Outpainting: 在不需要额外训练的情况下扩展了3D场景的边界,就像修复一样。为了无缝地外推场景,被扩展的区域应该以原始场景为条件。为了覆盖需要外推的区域,扩散模型生成了一个部分重叠于原始三平面的新三平面,通过使用遮罩 m \mathbf m m和已知三平面 h t k n o w n \mathbf h_t^{known} htknown的概念来实现这一点。遮罩 m \mathbf m m覆盖需要外推的区域,而 h t k n o w n \mathbf h_t^{known} htknown是从原始和外推区域之间三平面的交集中获得的。基于外推策略,可以沿着主要和次要方向扩展给定的场景,从而创造出无边界的场景。虽然三平面扩散模型是使用固定大小的三平面训练的,但它展示了将场景扩展到比原始场景大几倍的能力,如图1©所示。
Semantic Scene Completion Refinement: SSC模型从传感器观测(如图像或点云)中完成和分割3D场景。与数据分布相比,SSC结果存在几何和语义上的差异,如图1(b)所示。通过扩展了三平面扩散模型,以减少这种差异,对SSC模型的预测进行细化。为了有效地将三平面扩散方案与SSC模型的预测 x s c c \mathbf x^{scc} xscc相结合,可以利用由三平面编码器 f θ f_\theta fθ导出的它的三平面表示 h s c c = f θ ( x s c c ) \mathbf h^{scc} = f_\theta(\mathbf x^{scc}) hscc=fθ(xscc)。通过对扩散损失(公式2)和 生成过程(公式3)中的三平面 h t \mathbf h_{t} ht进行简单修改来扩展三平面扩散方案,如公式5所示。
h t = h t s c c ⊗ h s c c ( 5 ) \mathbf h_{t} = \mathbf h_t^{scc} \otimes \mathbf h^{scc}\qquad(5) ht=htscc⊗hscc(5)
其中 ⊗ \otimes ⊗是连接操作, h t s c c \mathbf h_t^{scc} htscc是通过DDPS扩散过程以SSC预测的三平面 h s c c \mathbf h^{scc} hscc为条件采样的第 t t t个扩散三平面。
4. 实验
4.1 实验细节
训练数据集: 实验在SemanticKITTI和CarlaSC数据集上进行验证。其中SemanticKITTI提供了20个语义类别的真实户外环境的3D语义场景标注。每个场景由256×256×32的体素网格表示,覆盖了车前51.2米、车侧各51.2米、高度6.4米的区域。该数据集保留了传感器帧集成产生的物体运动痕迹,用于建立密集的地面真值。相比之下,CarlaSC是一个合成数据集,提供了11个语义类别的3D语义户外场景,没有移动物体的痕迹。该数据集包含128×128×8的体素网格,覆盖了车前后25.6米、车侧各25.6米、高度3米的区域。
实现细节: 实验部署在单个RTX3090 GPU上,三平面自编码器的批量大小为4,三平面扩散模型的批量大小为18。对于三平面自编码器,输入场景被编码为空间分辨率 ( X h , Y h , Z h ) = ( 128 , 128 , 32 ) (X_h,Y_h, Z_h) = (128,128,32) (Xh,Yh,Zh)=(128,128,32)、特征维度 C h = 16 C_h=16 Ch=16的三平面。公式1中的损失权重 λ \lambda λ设为1.0。公式2中范数 p p p的阶数对于SSC细化设为1,其他情况设为2。在扩散过程中,使用默认设置,共100个时间步( T T T)。对于三平面inpainting和outpainting,作者采用了RePaint采样策略作为参考,进行5次重采样和20的跳跃步长。
评估指标: 通过检查渲染图像中3D语义场景的多样性和保真度来评估语义场景生成的性能。并使用召回率评估多样性,使用精确度和Inception Score(IS)评估保真度;以及使用Fr ́echet Inception Distance(FID) 和Kernel Inception Distance(KID) 指标,用来反映多样性和保真度对场景质量的综合影响。在语义场景完成(SSC)细化性能方面,使用交并比(IoU)指标量化场景完整性,使用平均IoU(mIoU)度量语义分割质量。
4.2 语义场景生成
如图3所示,SemCity展示了即使在真实数据集上也能有效合成详细场景的能力。它在准确捕捉CarlaSC数据集上复杂建筑物形状方面表现优于SSD。此外,该方法在生成SemanticKITTI数据集上道路和建筑物的整体轮廓以及细节方面也表现出卓越的能力。表1提供了使用各种指标的详细比较评估。SemCity模型在生成场景的保真度和多样性方面都显示出显著改进。此外,如图4所示,其生成的结果不受固定分辨率的限制,这得益于隐式神经表示。更多结果请参见原论文提供的补充材料。

图3|SemCity在SemanticKITTI和CarlaSC数据集上的定性比较©️【深蓝AI】编译

图4|高分辨的场景生成©️【深蓝AI】编译

表1|语义场景生成结果©️【深蓝AI】编译
4.3 Triplane Diffusion的应用
Scene Inpainting: 如图5所示,SemCity展示了在修复场景中小区域和大区域时的有效性,同时保持3D上下文的一致性。具体而言,a和b第二行说明了该模型无缝删除车辆的能力,与相邻的道路协调一致。第三行展示了插入新实体(a中的一辆车,b中的一个人)的能力,这些实体与参考场景的上下文一致。图5(a)中的第四行展示了该模型在修改和添加场景中车辆的双重功能,第五行突出了该模型修改场景的熟练程度。在这里,该模型改变了现有的场景组件,展示了它改变整个场景氛围的能力。这些结果表明,SemCity模型不仅擅长物体级别的修复,也擅长场景级别的修复。

图5|Scene Inpainting效果图©️【深蓝AI】编译
Scene Outpainting: 图6展示了生成的外推城市级场景,将256×256×32的场景扩展到大规模的1792×3328×32景观,结果显示SemCity展示了在大范围内保持一致性的能力。

图6|Scene Outpainting效果图©️【深蓝AI】编译
Semantic Scene Completion Refinement: 在图7中,现有语义场景完成(SSC)方法预测的场景与其真实场景对应物之间存在明显的语义和几何差异。SemCity模型通过利用3D场景先验来弥补这一差距,这种先验通过作者的扩散模型得到有效建模。虽然SSC模型显示出与真实世界数据分布的差异,但SemCity模型显示出将这些差异更紧密地与现实对齐的潜力。如表2所示,SemCity的SSC细化过程似乎为所有最先进的SSC模型提供了改进。这些初步结果表明,SemCity模型不仅能提供更准确的语义分割,还能提供更完整的场景。

图7|语义场景完成效果图©️【深蓝AI】编译

表2|Refining SSC的定量结果©️【深蓝AI】编译
Semantic Scene to RGB Image: 如图8所示,通过进行图像到图像的生成实验。语义地图在没有阴影的驾驶视角下呈现,用作ControlNet的输入。生成的RGB图像在几何和语义上都是合理的,但由于预训练的ControlNet未在实际自动驾驶数据集上训练,因此仅显示出一定的合成质量。

图8|语义场景到RGB图像©️【深蓝AI】编译
4.4 消融实验
如表3所示,作者也对三平面扩散模型进行了消融研究,其中重点关注两个关键设计元素:
位置嵌入 ——SemCity的变体排除了位置嵌入( P E PE PE),这会产生对于详细场景重建至关重要的高频特征。其缺失导致了所有指标的性能下降。
三平面表示 ——另外作者也评估了三平面表示在真实户外场景生成中的有效性。与3D特征相比,三平面和 x y xy xy平面可以提高生成质量,而 x y xy xy平面的性能低于三平面。可能的原因,过度的因子化限制了 x y xy xy平面相对于三平面的表示能力。
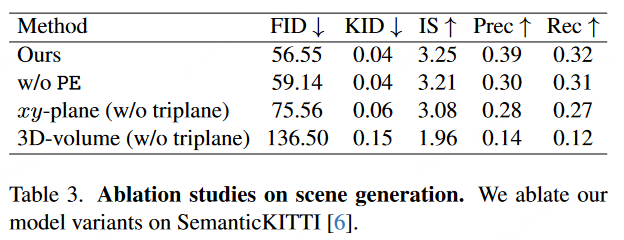
表3|场景生成的消融实验结果©️【深蓝AI】编译
4.5 局限性
尽管Semcity模型在3D真实户外场景生成方面取得了显著进展,但它本质上反映了训练数据的特点。这种依赖性带来了一些局限性。一个明显的挑战是模型难以准确描绘传感器视角下被遮挡的区域,如建筑物的后侧,这常常导致这些区域在生成的场景中表现不完整。此外,由于数据集是从驾驶视角捕获的,因此无法完全捕捉建筑物的全高。这导致场景中建筑物和其他高大元素的垂直结构只能部分表现。另一个问题是,模型倾向于产生来自数据集预处理合并连续帧的移动物体痕迹。
5. 总结
在本文中,作者提出SemCity的扩散框架,用于真实户外场景生成。其核心思想是通过将真实户外场景分解为三平面表示来生成场景。它借助三平面表示优于传统的体素方法的特点,生成的场景不仅视觉上更吸引人,在语义细节方面也更丰富,有效地捕捉了场景中各种物体的复杂性,而且由于引入隐式神经表示,该方法也不受固定分辨率的限制。另外,通过扩展三平面扩散模型的功能,SemCity模型不仅可以应用于scene inpainting、scene outpainting和语义场景完成细化等方面,还可以使用3D先验知识更好地将现有语义场景完成方法预测的场景与实际数据分布进行对齐。
编译|巴巴塔
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









