






导读: 在计算机视觉与机器人感知领域,利用单目摄像头实现高精度三维环境感知与重建一直是富有挑战性的研究课题。传统方案通常依赖对相机位姿的反复优化与繁琐的后处理,不仅耗时冗长,而且在动态或复杂场景中稳定性与精度难以兼得。随着深度学习技术的成熟,人们愈发重视如何借助前馈神经网络从纯RGB数据中直接提取精确的三维信息,从而摆脱传统SLAM算法的掣肘。
©️【深蓝AI】编译
论文题目:SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
论文作者:Yuzheng Liu, Siyan Dong, Shuzhe Wang, Yingda Yin, Yanchao Yang, Qingnan Fan, Baoquan Chen
论文地址:https://arxiv.org/abs/2412.0940
SLAM3R(作者在文中专门注明发音为slæmər~)的设计正是立足于此前沿思考。它通过端到端的结构将局部三维点云重建与全局配准无缝融合,以递进式的方式逐步构建全局一致的场景表示,彻底避免显式求解相机参数的步骤。采用滑动窗口分片策略并直接回归点云,使得系统可在实时处理下将局部模型自然衔接,从而为精度、完整性与效率建立了全新平衡点。
实验结果表明,SLAM3R在多个数据集上均展现出领先的三维重建质量和完整性,同时保持20帧/秒以上的实时性能。这一成果不仅为各类下游应用——包括移动机器人导航、增强现实环境映射及自主驾驶感知模块——提供了更高效的技术支撑,也为未来低成本、高精度、实时三维重建研究开辟了广阔道路。
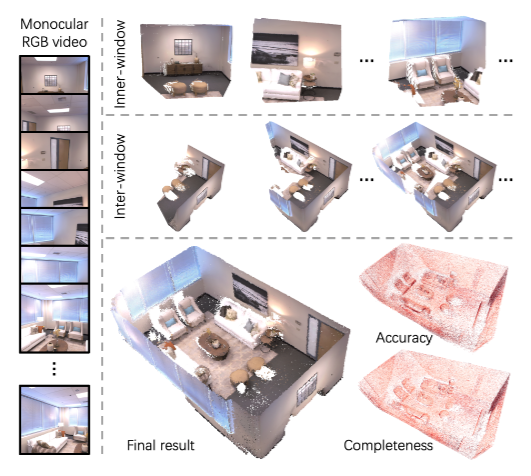
▲图1|稠密重建过程示意(从单目输入到场景稠密点云地图建立)©️【深蓝AI】编译
1.引入
密集3D重建一直是计算机视觉领域中一项由来已久的挑战,其目标在于捕获并重建真实世界场景的精细几何结构。传统方法通常依赖多阶段的处理流程:先利用稀疏的同步定位与建图(SLAM)或运动恢复结构(SfM)算法估计相机参数,再通过多视点立体(MVS)技术来完善场景细节。尽管这些方法能提供高质量的重建结果,但它们常常需要离线处理才能获得完整模型,从而在实际应用中受到限制。
已有研究提出了密集SLAM方法,将密集场景重建作为一个完整的系统加以解决。然而,这些方法常在重建精度或完整度上表现不足,或过分依赖深度传感器。近期,一些单目SLAM系统尝试从RGB视频出发实现密集场景重建。通过引入先进的场景表示形式,它们在精度和完整度上取得了出色表现,但运行效率因此大幅下降。例如,NICER-SLAM的处理速度明显低于1帧/秒。因此,现有方法在重建精度、完整度或效率这三项关键指标中,总有至少一项难以兼顾。
尽管单目密集SLAM系统存在上述局限,但近期在双视图几何方面的研究已展现出希望。DUSt3R以纯端到端方式进行密集重建学习,通过在大规模数据集上的训练,其网络可以在实时条件下从成对图像中生成高质量的密集重建结果。然而,当处理多视图数据时,仍需通过全局优化来对齐图像对,显著降低了效率。一项同期研究Spann3R则通过成对增量式重建管线将DUSt3R拓展至多视图(视频)场景,虽加快了重建,但累积漂移和重建质量下降的问题依然突出。
为应对这些挑战,引入了SLAM3R,这是一种旨在仅凭RGB视频即可实现实时密集3D重建的新型SLAM系统。SLAM3R采用两层级框架:首先在一个滑动窗口内处理输入视频的短片段,以重建局部3D几何结构;然后逐步对这些局部重建进行配准,从而构建全球一致的3D场景。两个模块均采用简洁而高效的前馈模型,实现了端到端的高效场景重建。具体而言,系统由Images-to-Points(I2P)和Local-to-World(L2W)两个模块组成。I2P模块受DUSt3R启发,在局部窗口中选定一个关键帧作为坐标基准,直接预测出剩余帧所支持的密集3D点图。L2W模块则将这些局部重建的点图增量式地融合为统一的全球坐标系统。这些过程均无需显式估计任何相机参数。
通过大量实验证明,SLAM3R能在各种基准数据集上实现高质量的场景重建并保持最低的漂移,其性能优于现有的密集SLAM方法。此外,SLAM3R在20帧/秒以上的速度下取得这一结果,从而在仅依赖RGB的密集场景重建中实现了质量与效率的平衡。
主要贡献如下:
-
提出了一种可在统一坐标系中直接预测3D点图的实时端到端密集3D重建系统。
-
精心设计的I2P模块可同时处理任意数量的图像,有效扩展了DUSt3R至多视图场景,生成更高质量的预测结果。
-
新颖的L2W模块可将局部预测的3D点图直接对齐至统一的全球坐标体系,无需显式估计相机参数和高昂的全局优化。
-
在多个公共基准数据集上的评估显示,该方法在精度和完整度方面达到先进水平,并能在实时速度下运行。
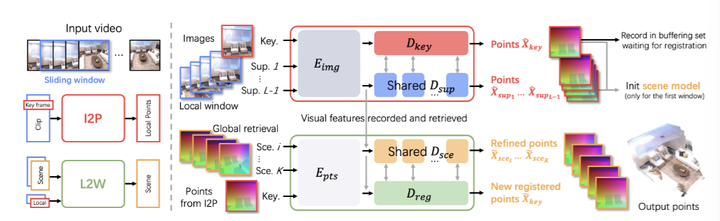
▲图2|全文方法总览©️【深蓝AI】编译
2.具体方法与实现
首先,我们一起来看一下对于该问题的陈述:对于给定的单目视频序列![]() ,其中每一帧Ii为RGB图像并拍摄自同一静态场景,目标在于重建该场景的密集3D点云
,其中每一帧Ii为RGB图像并拍摄自同一静态场景,目标在于重建该场景的密集3D点云![]() ,M为3D点数量。此领域的研究重点在于三个关键目标:在保持实时性能的前提下,尽可能完整地恢复3D点(以确保重建的完整度)、提高每个恢复点的精度,以及在两者间实现平衡。
,M为3D点数量。此领域的研究重点在于三个关键目标:在保持实时性能的前提下,尽可能完整地恢复3D点(以确保重建的完整度)、提高每个恢复点的精度,以及在两者间实现平衡。
图2则展示了全文方法的整体流程,我们先来一起理解一下图2的内容:
图2中显示,SLAM3R系统包含两个主要组件:一个“Image-to-Points”(I2P)网络,用于从视频片段中恢复局部3D点;以及一个“Local-to-World”(L2W)网络,用于将这些局部重建结果注册到全局场景坐标系中。在对密集点云进行重建的过程中,系统并不显式求解任何相机参数,而是直接在统一坐标系中预测3D点图。
从左往右看(体现数据的基本处理流程):系统首先对输入视频应用长度为L的滑动窗口机制,将其转换为短片段![]() 。I2P网络处理每个窗口
。I2P网络处理每个窗口,以恢复局部3D点图。在每个窗口中,系统选取一个关键帧作为点重建的参考坐标系(这部分笔者将在2.1进行展开介绍)。默认情况下,滑动窗口步幅为1,确保视频中的每帧至少有一次被选择为关键帧。
从上往下看(体现系统从local到global的过渡):对于全局场景重建,系统以第一个窗口初始化世界坐标系,并将I2P网络输出的重建帧(图像和局部点图)作为L2W模型的输入。L2W模型以增量方式将这些局部重建结果融合入统一的全球3D坐标系。为在此过程中同时确保精度与效率,系统维护了一组已注册的参考帧(称为“场景帧”)。当L2W模型注册一个新关键帧时,系统会从场景帧中检索与其最佳相关的参考帧用于对齐(这部分笔者将在2.2展开介绍)。
2.1 窗口内部的局部重建
I2P模型的目标是在给定视频片段中,为关键帧的每个像素推断密集3D点图。默认情况下,窗口W的中间图像作为关键帧Ikey,以定义局部坐标系,因为它与其他帧的重叠最大。其余图像![]() 为辅助帧。需要注意的是,这些辅助帧的3D点图也可通过I2P重建。I2P网络借鉴了DUSt3R的设计思路,但为多视图场景进行了简洁而有效的改进。I2P模型采用多分支的Vision Transformer(ViT)作为主干,包括一个共享的图像编码器Eimg、两个独立的解码器Dkey和Dsup,以及一个点回归头用于最终预测。
为辅助帧。需要注意的是,这些辅助帧的3D点图也可通过I2P重建。I2P网络借鉴了DUSt3R的设计思路,但为多视图场景进行了简洁而有效的改进。I2P模型采用多分支的Vision Transformer(ViT)作为主干,包括一个共享的图像编码器Eimg、两个独立的解码器Dkey和Dsup,以及一个点回归头用于最终预测。
这些组件如下所述:
图像编码器(Eimg):给定视频片段中的每帧Ii,图像编码器Eimg对其进行编码,获得令牌表示![]() ,其中T为令牌数,d为令牌维度。编码器Eimg由m个ViT编码模块组成,每个模块包含自注意力和前馈层。编码过程记为
,其中T为令牌数,d为令牌维度。编码器Eimg由m个ViT编码模块组成,每个模块包含自注意力和前馈层。编码过程记为![]() ,
,![]() 。各帧独立并行处理。输出分为两部分:Fkey用于关键帧,
。各帧独立并行处理。输出分为两部分:Fkey用于关键帧,![]() 用于辅助帧。
用于辅助帧。
关键帧解码器(Dkey):关键帧解码器Dkey由n个ViT解码模块组成,每个模块包含自注意力、交叉注意力和前馈层。有别于DUSt3R使用的标准交叉注意力,这里引入了一种新颖的多视图交叉注意力,将来自不同辅助帧的信息组合起来。Dkey以Fkey为输入,对其执行自注意力,并对Fkey与![]() 进行交叉注意力操作。每个交叉注意力层的查询来自Fkey,而键与值来自Fsupi。通过并行处理L−1个交叉注意力层,并在之后通过最大池化聚合特征,最终获得解码后的关键帧特征Gkey。
进行交叉注意力操作。每个交叉注意力层的查询来自Fkey,而键与值来自Fsupi。通过并行处理L−1个交叉注意力层,并在之后通过最大池化聚合特征,最终获得解码后的关键帧特征Gkey。
辅助帧解码器(Dsup):辅助解码器Dsup用于补充关键帧解码器。它采用与DUSt3R中相同的解码结构,由n个标准ViT解码模块组成。交叉注意力仅在辅助帧与关键帧之间进行交互。所有辅助帧共享同一个Dsup。该过程记为,![]() 。
。
点重建:与DUSt3R类似,这里使用线性预测头H根据解码后的令牌回归统一坐标系下的密集3D点图。此外,还预测每帧的置信图以评估其可靠性。最终预测为:![]() ,其中
,其中为预测的3D点图,
为对应的置信图。
训练损失:遵循DUSt3R的做法,I2P网络使用场景点的真值Xi对网络进行端到端训练。真实点图与预测点图在归一化尺度下进行比较。损失函数考虑置信度,以平衡点预测误差和置信度正则项。
2.2 窗口之间的全局配准
在获得I2P网络生成的3D点图X̂key后,使用L2W模型将新生成的点图增量式地注册到全局3D坐标系中。与I2P网络类似,L2W模型也需要一些帧作为场景参考。此外,L2W可利用多个已注册关键帧作为全局参考,这些关键帧称为场景帧,并通过抽样机制保存在缓存集中。
该缓存集用于处理长视频的可扩展性。采用蓄水池抽样策略以在有限内存中存储无偏的场景帧子集。当有新关键帧从I2P推断完毕准备融合时,系统会从缓存集中检索与其最相关的K个场景帧作为全局配准的支持。随后通过场景初始化、缓存与检索、点特征嵌入、配准解码器、场景解码器以及最终的点重建与训练损失构建优化来完成所有的配准,笔者将对这个pipeline上的每个模块进行单独的介绍:
场景初始化:第一个窗口用于初始化场景模型。为确保初始化的准确性,系统对该窗口执行L次I2P推断,尝试将窗口内的每帧都作为关键帧,并选取置信度最高的结果进行场景初始化。由此得到的场景点云及一组注册帧皆视为场景帧,用于初始化缓存集。
缓存与检索:每个场景帧都记录其潜在特征
和点图
。采用蓄水池抽样以在长期视频中保持高效且公平的场景帧选择策略。当需要注册新关键帧Ikey时,通过检索模块计算Ikey与缓存集中各场景帧的相关度分数,以选择最适合的K个场景帧作为全局参考。该检索模块使用I2P部分结构作为骨干,通过线性映射与平均池化对相似度进行评分。
点特征嵌入:由I2P模型重建的3D点图通过类似图像块嵌入的方式编码进入L2W模型。新关键帧及K个检索到的场景帧并行处理,并将编码后的几何令牌与对应的视觉令牌相加,以获得既包含图像外观信息又包含3D几何信息的特征。
配准解码器:配准解码器Dreg以![]() 为输入,将关键帧的局部重建转换至场景坐标系。其结构与关键帧解码器Dkey相同。
为输入,将关键帧的局部重建转换至场景坐标系。其结构与关键帧解码器Dkey相同。
场景解码器:场景解码器Dsce同样以![]() 为输入,用于在不改变坐标系的情况下优化场景几何。其网络结构与Dkey相同。默认情况下,每次注册一个关键帧。
为输入,用于在不改变坐标系的情况下优化场景几何。其网络结构与Dkey相同。默认情况下,每次注册一个关键帧。
点重建与训练损失:与I2P网络类似,这里通过线性预测头H在全局坐标系下预测所有点图及其置信图
。L2W网络的训练损失与I2P类似,但不对预测点图进行归一化,以确保输出尺度与输入场景帧对齐,从而使输出可直接融入已有的重建中。
3.实验
作为一个SLAM方法,本文的实验设置和大多数SLAM方法类似,主要从定位精度,建图质量两个角度出发,对方法进行评估,值得Highlight的一点是作者做了大量的可视化实验,因此我们能够很清晰明了的观测到SLAM3R对于单目输入的稠密重建效果。

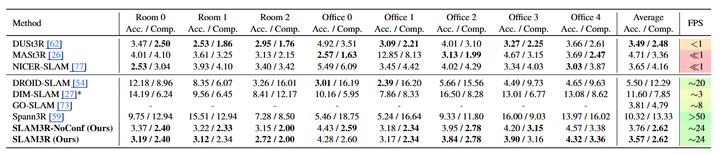
▲图3|数值对比实验©️【深蓝AI】编译
图3所示为数值对比实验,需要关注的点有两个地方,第一个是算法的Acc,这代表精度,直接决定了SLAM算法的定位效果,显然SLAM3R在多个数据集上与当前的SOTA方法相比都取得了领先,第二个值得关注的点是FPS,这是SLAM算法最重要的一个指标,实时性,这一点SLAM3R取得的成果尤为突出,基本上能够在各个数据集上领先对比的方法10倍以上。
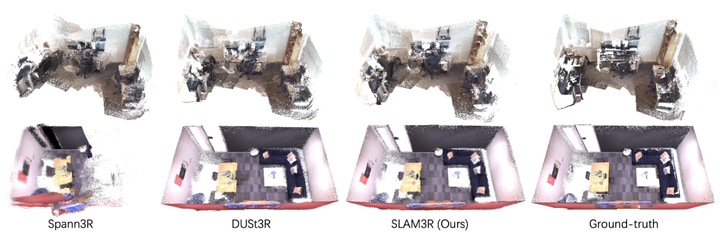
▲图4|可视化稠密重建实验(室内)©️【深蓝AI】编译

▲图5|可视化稠密重建实验(室外)©️【深蓝AI】编译
图4与图5为可视化的稠密重建实验效果,分别包含了室内场景以及室外场景,从稠密的可视化结果来看能够直观清晰的体会到SLAM3R的出色效果,对于室内的重建能够很好的保持整体场景的刚性,墙壁等边缘细节处没有出现扭曲或者弯曲的情况。室外场景的重建中,SLAM3R能够对物体的表面纹理进行非常清晰的恢复,没有出现点云重叠或者漂移造成的表明模糊和不清晰的情况。

▲图6|细节重建可视化©️【深蓝AI】编译
图6是对一些物体的细节重建可视化,这些问题大多采用表面光滑,比较少纹理的物体进行测试,比如套磁制品等等,这些物体一般会对重建带来一定的挑战,并且对于这些小物体的扫描通常需要更多的移动相机,这也对相机的位姿定位精度带来了一定程度的要求,而从图6能够看出SLAM3R取得了非常棒的重建效果,由此可见其对于自身位姿的估计以及稠密的重建效果都是非常出色的。
4.总结
在本文中,作者提出了SLAM3R,这是一种新颖且高效的单目RGB SLAM系统,可用于实时高质量的密集3D重建。该系统采用两层级神经网络框架,通过精简的前馈流程实现端到端的3D重建,无需显式求解任何相机参数。实验证明,该方法在重建质量与实时效率方面均达到了当前最先进的水平,并可实现20帧/秒以上的处理速度。

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









