



导读
何恺明(Kaiming He),麻省理工学院电气工程与计算机科学系(EECS)终身副教授,兼任 Google DeepMind 杰出科学家,是全球计算机视觉与深度学习领域最具影响力的学者之一。他以提出 ResNet(深度残差网络) 闻名,该工作彻底改变了深度神经网络的训练方式,被公认为 21 世纪引用量最高的论文之一。此后,他在 目标检测与实例分割(Mask/Faster R-CNN)、自监督学习(MoCo、MAE) 等方向持续创新,奠定了现代视觉模型与生成架构的基础。
何恺明的研究长期聚焦于深度学习的核心命题——结构设计、表示学习与通用智能架构。他主张通过对模型训练机制与归纳偏置的系统性理解,寻找神经网络在“感知—生成—推理”间的统一原则。从微软亚洲研究院(MSRA)到 Facebook AI Research(FAIR),再到麻省理工学院,何恺明推动的技术浪潮从 ImageNet 时代的视觉识别,延伸至 Transformer、Diffusion、以及大规模生成模型的时代核心。
2025 年,何恺明团队的研究延续了其在深度学习体系中的核心追求——以结构创新推动表征进化,以理论简化引领生成范式。这一年,团队围绕生成建模、自监督学习与基础架构优化等方向展开系统探索,持续拓展视觉智能的理论与工程边界。
在生成建模方面,研究团队尝试从“噪声、流动、表征”的角度重新审视现有扩散模型框架,提出更具稳定性与可解释性的生成机制,使得模型能够在保持高保真度的同时实现更高的计算效率。在视觉表征学习中,他们探索了去归一化、压缩编码、分形结构等新形式的网络设计理念,推动模型在不同模态与任务间的泛化能力。与此同时,团队还从理论层面对数据偏差、训练动态与归纳偏置进行了反思,力求建立更加稳健与统一的视觉智能理论体系。
这些工作共同呈现出一个清晰的趋势:从结构到原理,从生成到理解,何恺明团队正致力于构建一个更高效、更普适的视觉世界模型。
这一年,他们不仅在模型性能上刷新记录,更在方法论层面提出了新的可能——如何让深度学习从“经验驱动”走向“结构驱动”,让人工智能的生成与理解真正融为一体。
接下来,小编将带大家一同走进何恺明教授 2025 年的研究世界,看看这位“深度学习时代的系统设计师”如何再次定义人工智能的下一阶段
值得说明的是,何凯明教授近年来科研合作研究广泛,而本文所盘点的内容,仅聚焦于由何凯明教授本人担任大通讯作者(corresponding author)的核心论文,代表其团队在 2025 年度的主要研究脉络与前沿突破。部分工作仍处于审稿或预印本阶段,因此暂未标注最终发表会议与期刊。
参考:
https://scholar.google.com/citations?hl=zh-CN&user=DhtAFkwAAAAJ&view_op=list_works&sortby=pubdate
Diffuse and Disperse: Image Generation with Representation Regularization
地址:https://arxiv.org/pdf/2506.09027
主要内容:
这项研究由麻省理工学院的何恺明团队提出,旨在重新思考扩散模型(Diffusion Models)与表征学习(Representation Learning)之间的关系。尽管扩散生成在过去十年取得巨大进展,但其目标函数通常以回归为核心,缺乏对潜在空间结构的显式约束。为此,研究者提出了一种简洁高效的分散正则化损失(Dispersive Loss),用于促进模型内部表征在隐空间的“离散化”与信息分布,从而提升生成质量与多样性。与对比学习类似,该方法在不依赖正样本对的情况下实现特征分离,且无需额外预训练、参数或外部数据。实验表明,Dispersive Loss 在多个主流扩散模型与 ImageNet 数据集上均显著提升了生成性能,为生成建模与表征学习的融合提供了一种简洁而通用的途径。
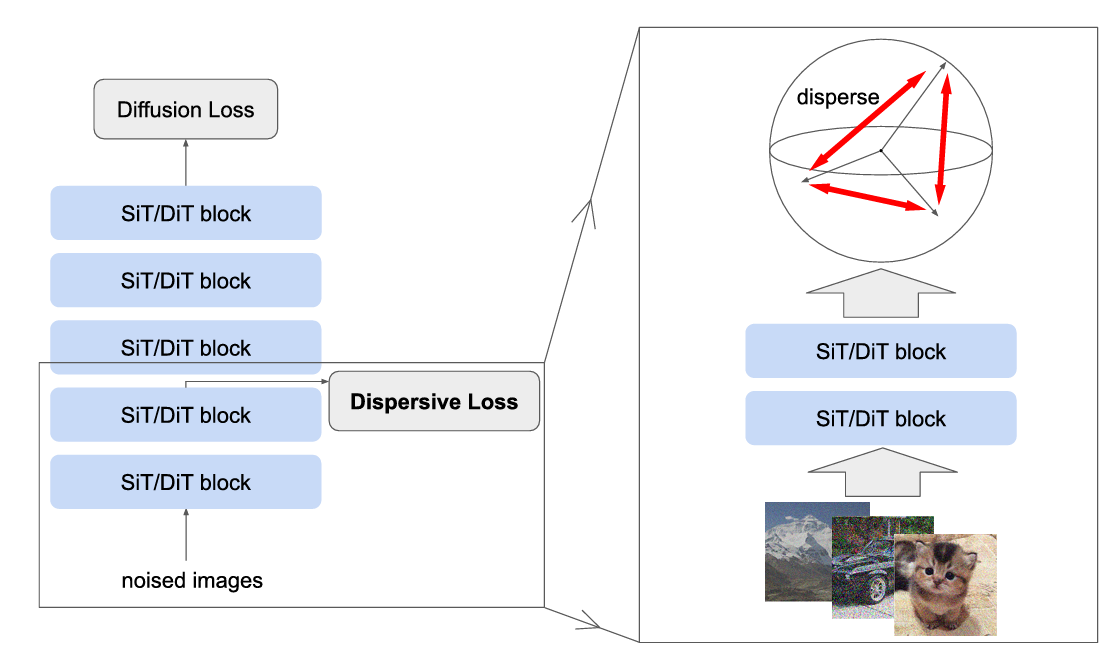
图1|Dispersive Loss 在生成模型中的作用示意。左图展示了在传统扩散模型(如 SiT 或 DiT)中加入 Dispersive Loss 的整体结构;右图放大了前几层的细节。该正则项鼓励中间层特征在隐空间中更加分散,提升生成表示的多样性与稳定性。它直接作用于同一批噪声输入,无需额外参数或外部数据,几乎不增加计算开销,却显著改善了模型的内部表征质量
Highly Compressed Tokenizer Can Generate Without Training [ICML]
地址:https://arxiv.org/pdf/2506.08257?
主要内容:
这项研究由 MIT 与 Meta 研究团队合作完成,探索了一种无需训练即可实现图像生成的新路径。传统图像 tokenizer 通常将图像编码为二维网格形式,而该研究提出的 一维高压缩 tokenizer 则将图像表示为极短的离散序列(仅约 32 个 token),但仍能保留丰富的语义与外观信息。研究者发现,通过在 latent 空间中直接对这些 token 进行简单的启发式操作(如替换或拷贝),就能实现精细的图像编辑与属性迁移。进一步地,他们利用梯度优化机制与可插拔的损失函数(如重建损失或 CLIP 相似度)构建了一套无需生成模型训练的图像生成流程,在图像修复与文本引导编辑任务中展现出高度的多样性与真实感。这项工作重新定义了“token 本身即生成器”的理念,为未来轻量级视觉生成提供了全新思路。
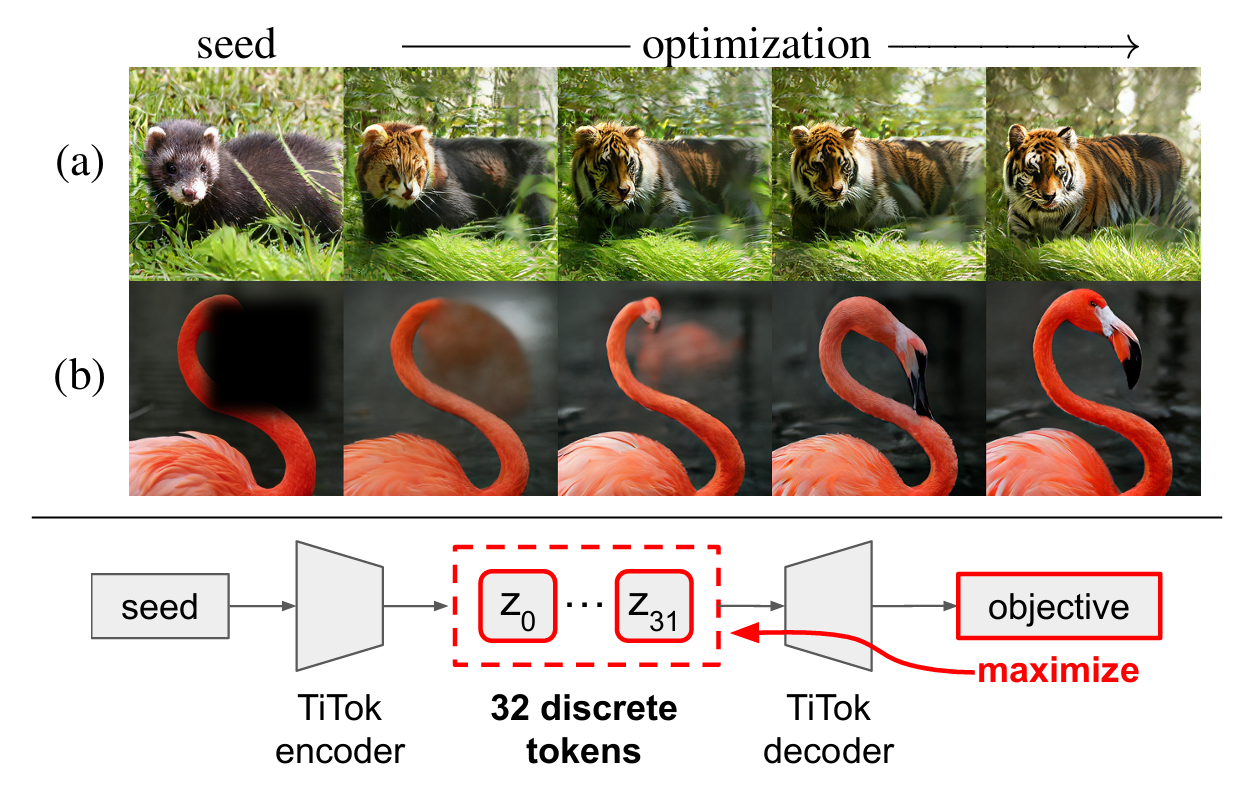
图2|无需额外训练,预训练的一维高压缩 tokenizer 便可直接执行图像生成任务。(a)基于文本的图像编辑;(b)图像修复(inpainting)。得益于其紧凑而富含语义的 latent 空间,系统仅通过在测试阶段对 token 进行梯度优化即可完成生成过程,依托 CLIP 相似度或重建目标实现高质量结果——整个流程无需训练任何生成模型
Mean Flows for One-step Generative Modeling [NeurIPS]
地址:https://arxiv.org/pdf/2505.13447?
主要内容:
这项研究由 MIT 与 CMU 合作完成,提出了一种无需多步采样的单步生成建模框架 MeanFlow,旨在突破扩散模型与流匹配模型在生成效率与精度之间的长期矛盾。传统的 Flow Matching 依赖瞬时速度场建模,而 MeanFlow 创新性地引入了平均速度(mean velocity)的概念,用以刻画数据分布在生成路径中的整体流动特性。基于这一数学定义,研究者构建了一个完全自洽、无需预训练或蒸馏的生成模型,仅通过单次网络计算即可在 ImageNet 256×256 上达到 FID 3.43 的表现,显著优于以往单步生成方法。该研究不仅极大提升了生成效率,也在理论上连接了扩散建模与流场建模的核心思想,为后续构建高效的统一生成框架奠定了重要基础。
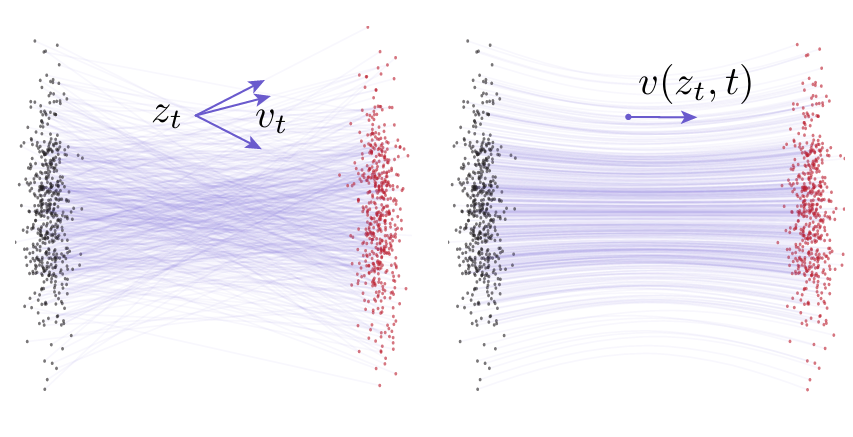
图3|流匹配(Flow Matching)中的速度场示意。左图展示了条件流模型下的瞬时速度分布,不同的噪声样本会产生不同的条件速度;右图则展示了对所有可能条件速度进行边缘化后的平均流场,可视为用于网络训练的“真实流动方向”。这些速度场均描述了数据从先验(灰点)向真实分布(红点)演化的瞬时动态。MeanFlow 在此基础上进一步引入“平均速度”概念,以捕捉整个生成路径的整体趋势,从而摆脱多步采样的束缚,让生成过程在一次前向传播中完成
Denoising Hamiltonian Network for Physical Reasoning
地址:https://arxiv.org/pdf/2503.07596?
主要内容:
这项研究提出了一个融合物理约束与神经表示的新框架——Denoising Hamiltonian Network(DHN),旨在让深度学习模型具备真实的物理推理能力。传统物理建模方法往往依赖显式的动力学方程或局部时间步模拟,而 DHN 将哈密顿力学(Hamiltonian mechanics)算子推广为可学习的神经算子,能够同时捕捉长时依赖与高层物理交互。该框架引入“去噪机制”以抵消数值积分误差,并通过全局条件化策略支持多物理系统的联合建模。与以往仅关注仿真精度的模型不同,DHN 可在预测、逆推、跨系统迁移等多类物理推理任务中统一工作,兼顾理论可解释性与神经网络的灵活表达力,展示了神经算子在物理世界建模中的巨大潜力。
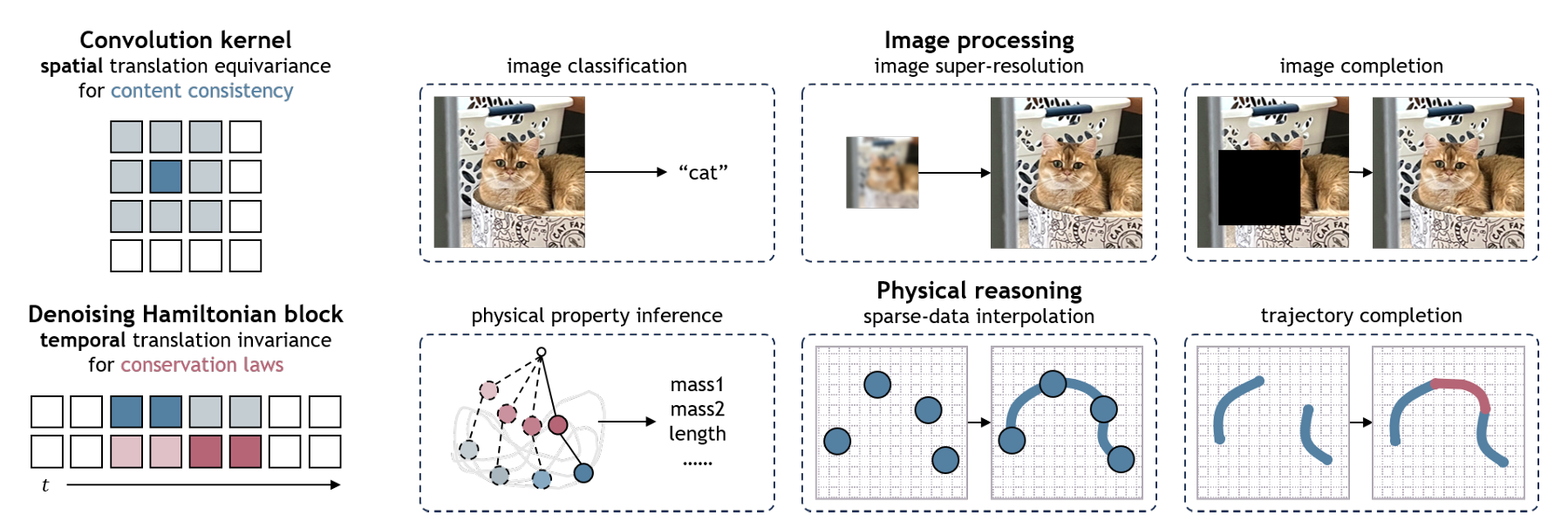
图4|Denoising Hamiltonian Network(DHN)框架概览。 模型将经典哈密顿力学拓展为可学习的神经算子,在保持物理守恒结构的同时,引入神经网络的非线性表达能力。DHN 通过去噪机制抑制积分误差,并在多系统建模中实现统一的物理约束。该设计既保留了物理规律的精确性,又赋予模型跨场景的泛化能力,为下一代“可解释的物理智能体”奠定了基础
Fractal Generative Models
地址:https://arxiv.org/pdf/2502.17437
主要内容:
这项研究提出了一种受分形思想启发的新型生成框架——Fractal Generative Models(分形生成模型),试图在深度生成建模中引入“自相似”与“递归结构”的设计理念。作者将生成模型本身视为可复用的原子模块(atomic generative module),并通过递归调用这些模块构建出跨层级自相似的生成体系,从而形成类似数学分形的层层嵌套结构。论文以自回归模型为实例,在像素级图像生成任务中验证了该框架的有效性,在似然估计与生成质量两方面均表现优异。相比传统单层架构,这种“模型生成模型”的设计为生成建模引入了全新的结构维度,展示了生成模型体系化与模块化的潜力。
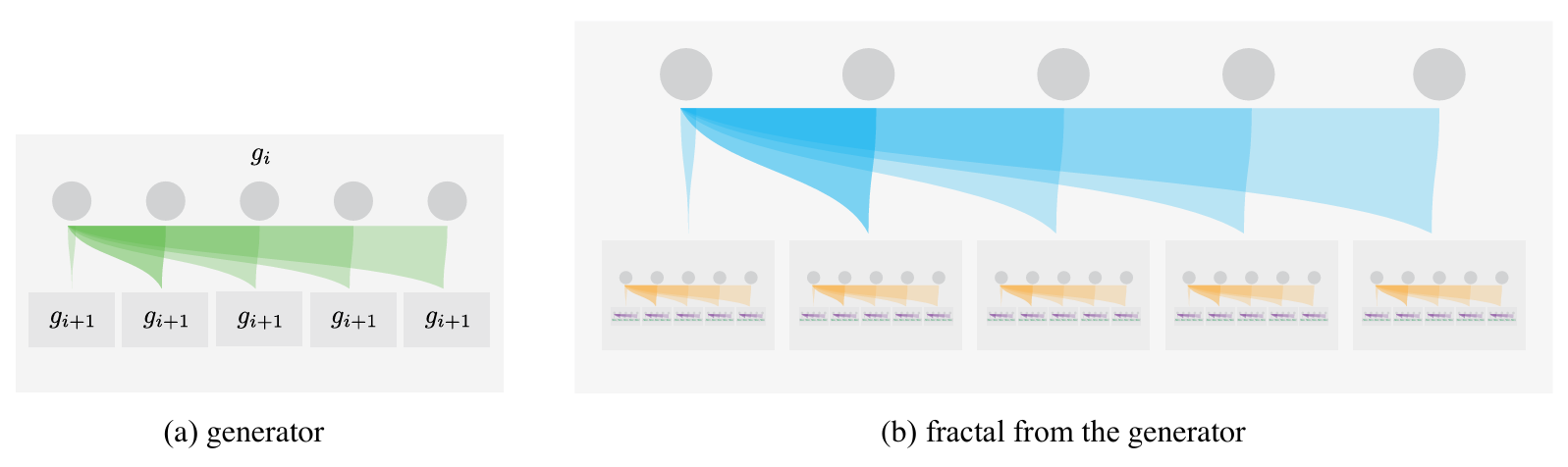
图5|分形生成模型结构示意。 左图展示生成器的层级结构,右图展示模型生成的“分形式”结果。研究者通过在自回归模型中递归调用自回归模块,构建出具有多层自相似特征的生成体系,实现了跨层结构的统一表达。该机制不仅增强了模型的可扩展性,也揭示了生成网络在不同层级间共享结构规律的可能
Is Noise Conditioning Necessary for Denoising Generative Models?【ICML】
地址:https://arxiv.org/pdf/2502.13129?
主要内容:
这项研究由何恺明团队提出,对扩散生成模型的核心假设——“噪声条件(noise conditioning)是必要的”发起了挑战。传统观点认为,扩散模型必须显式输入噪声水平(如 σₜ)以实现有效的去噪与生成,而该研究系统性地验证了在去除噪声条件输入后模型的表现。令人意外的是,多数模型在无噪声条件下仍保持平稳退化,甚至部分场景下表现更优。研究团队通过理论推导解释了去除噪声条件所引发的误差特性,并在 CIFAR-10 上训练出一个完全“无条件”的去噪模型,取得了 FID 2.23 的结果,逼近当前最优的噪声条件模型。该工作不仅揭示了噪声条件在扩散建模中的冗余性,也为未来更简洁、更可解释的生成框架奠定了理论基础。
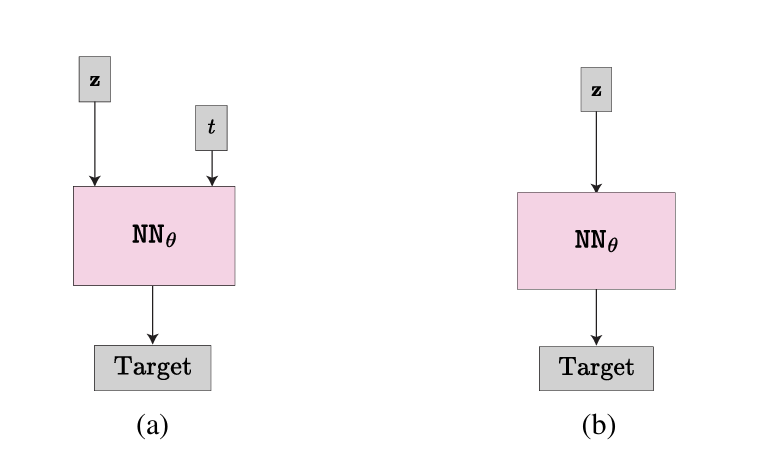
图6|噪声条件在扩散生成模型中的作用对比。 (a) 传统模型通过显式输入噪声引导神经网络进行去噪;(b) 本研究探索在不输入噪声条件的情形下,模型仍可学习隐式的噪声分布表示并保持稳定生成效果。结果显示,去除噪声条件后模型依然具备强大的生成能力,这一发现促使研究者重新思考扩散模型的基本结构假设
A Decade’s Battle on Dataset Bias: Are We There Yet? [ICLR]
地址:https://arxiv.org/pdf/2403.08632
主要内容:
本研究由 Meta FAIR 的何恺明团队发起,重访十年前 Torralba 与 Efros 提出的“数据集分类”实验,系统检验在当下大规模与高多样性数据时代中,数据集偏差(dataset bias)是否真正被解决。研究者使用现代神经网络在多个主流开放数据集(如 YFCC、CC、DataComp)上进行分类实验,结果表明模型能够以 84.7% 的准确率 判别图像来源,说明即便在更大规模、更开放的数据环境下,数据集间的分布差异依然显著存在。进一步分析发现,这些模型学习到的并非简单的记忆特征,而是具有可迁移性的语义表示,这揭示了数据偏差在更深层的结构性问题。研究呼吁社区重新思考“数据集公正性”与“泛化能力”的关系,强调仅依赖数据规模扩张无法根除偏差,这场“与数据集偏差的十年之战”仍远未结束。

图7|“猜猜这张图来自哪个数据集?”——十年后的重访实验。 研究者复刻了 Torralba 与 Efros 于 2011 年提出的经典游戏“Name That Dataset”,选取了来自 YFCC、CC 与 DataComp 三个现代大规模数据集的图像样本。虽然这些数据集看似更加多样与中立,但实验发现,神经网络仍能轻松辨别其来源,在验证集上取得极高准确率。这说明即使在大模型与大数据时代,数据集偏差依然深层存在,并且可能通过特征分布、语义风格等隐含方式渗入模型表征之中
Deconstructing Denoising Diffusion Models for Self-Supervised Learning【ICLR】
地址:https://arxiv.org/pdf/2401.14404
主要内容:
本研究由 Meta FAIR 团队提出,对扩散模型(Denoising Diffusion Models, DDM)的表征学习能力进行了系统性解构分析。研究者的核心思路是——将扩散模型逐步退化为传统的去噪自编码器(Denoising Autoencoder, DAE),以探究哪些结构组件真正对自监督表征学习至关重要。通过这一“拆解式实验”路径,团队发现现代 DDM 中仅有少数关键机制(如噪声建模与重建目标)对表征学习质量起决定作用,而大量复杂的调度与条件结构其实并非必需。最终得到的模型在形式上极为简化,却依然能学习出高质量特征。这项工作以一种“反向思考”的方式,重新连接了经典自编码思想与现代扩散框架,提醒研究者在不断追求复杂架构的同时,也应回望那些被深度学习早期奠基的简单而有效的思想。
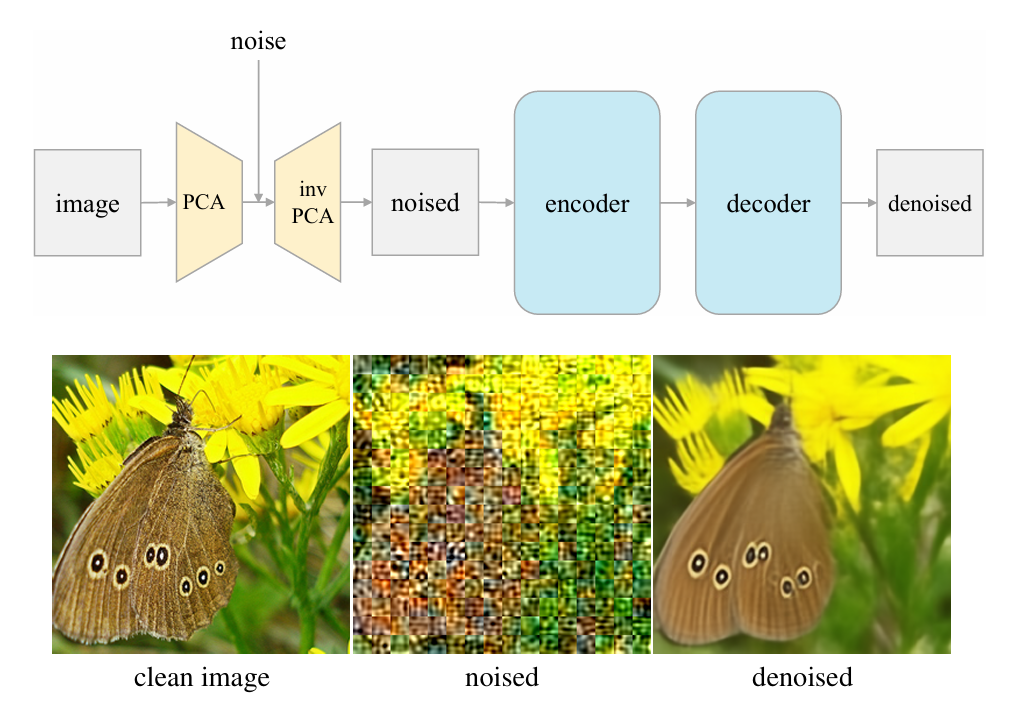
图8|从扩散模型回归“本源”的潜空间去噪自编码器(l-DAE)结构。 经过对扩散模型的系统性解构,研究者最终得到这一极为简化的框架:输入图像首先通过基于 patch 的 PCA 投影到潜空间中,并在该空间内添加噪声;随后经反向 PCA 投影回像素域,由自编码器学习重建出无噪声图像。这样的结构几乎回到了最经典的 DAE 形式,只是噪声被转移到了潜空间层面。尽管设计极简,模型依然展现出与现代扩散架构相当的自监督表征能力,凸显了“简单结构也能孕育强大特征”的思想
总结
2025 年,何恺明团队继续在深度学习的核心命题上推进结构性思考:如何让模型更简洁、更稳定、更通用地理解世界。 这一年,他们的研究从生成建模到自监督学习,从物理建模到架构优化,呈现出清晰的一条主线——以最小假设重构最大能力。
在生成领域,团队通过对扩散、流匹配与一维 token 表征的深入重构,揭示了高效生成背后的数学规律与结构约束;在表征学习中,他们以解构的方式重新连接经典自编码思想与现代扩散模型,证明了“简单”并非“落后”,反而是通往鲁棒与泛化的更深层路径;在理论层面,他们从数据偏差、噪声建模与正则约束等角度出发,持续推动对深度网络学习机制的本质理解。
可以说,2025 年的何恺明团队不再仅仅追求性能的极限,而是在追问深度学习“为何有效”。他们以系统性反思的姿态重塑了生成与表征的边界,也在隐秘处为下一阶段的人工智能架构打下基础。
2025 年关键词:简化、结构、泛化、物理性、重构。
这一年,是深度学习从“经验范式”回归“结构范式”的一年——而何恺明团队,依旧站在理解与重塑的最前沿


















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









