







 本文探讨了机器学习与统计建模的相同点和不同点。相同点在于两者都从数据中学习,目标是提取信息或规律。不同点包括学派背景、数据量处理、数据分析方式、数据使用方式、着重点和数据生成方式。机器学习侧重优化和预测能力,适合大数据处理,而统计建模注重模型的可解释性和推导,适用于小样本数据。两者的结合是数据科学的重要趋势。
本文探讨了机器学习与统计建模的相同点和不同点。相同点在于两者都从数据中学习,目标是提取信息或规律。不同点包括学派背景、数据量处理、数据分析方式、数据使用方式、着重点和数据生成方式。机器学习侧重优化和预测能力,适合大数据处理,而统计建模注重模型的可解释性和推导,适用于小样本数据。两者的结合是数据科学的重要趋势。
相同点
1、相同的目标:从数据中学习,核心都是探讨如何从数据中提取人们需要的信息或规律。
2、相同含义的常见术语:
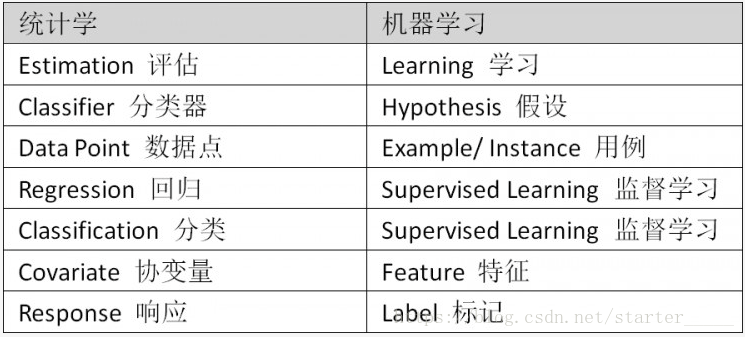
不同点
1、不同的学派:
- 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
- 统计建模(Statistical modeling)则完全是数学的分支,以概率论为基础,采用数学统计方法建立模型。
机器学习更多地强调优化和性能,而统计学则更注重推导。
2、不同的数据量:
- 机器学习应用广泛。 在线学习工具可飞速处理数据。这些机器学习工具可学习数以亿计的观测样本,预测和学习同步进行。一些算法如随机森林和梯度助推在处理大数据时速度很快。机器学习处理数据的广度和深度很大。
- 统计模型一般应用在较小的数据量和较窄的数据属性上。
3、不同的数据分析方式:
机器学习本质上是一种算法,这种算法由数据分析习得,而且不依赖于规则导向的程序设计;
统计建模则是以数据为基础,利用数学方程式来探究变量变化规律的一套规范化流程。
总结来说,机器学习的关键词是预测、监督学习和非监督学习等。而数理统计是关于抽样、统计和假设检验的科学。
4、不同的数据使用方式:
机器学习并不需要对有关变量之间的潜在关系提出先验假设。研究人员只需要将所有的可用数据导入模型,等待算法的分析并输出其中的潜在规律,然后将这一规律应用于新数据进行预测就可以了。对于研究人员来说,机器学习就像一个黑盒子,你只需要会用,但并不清楚其中的具体实现。机器学习通常应用于高维度的数据集,你的可用数据越多,预测通常就越准确。
相比之下,统计学则必须了解数据的收集方式,估计量(包括p值和无偏估计)的统计特征,被研究人群的潜在分布规律,以及多次试验的期望参数的类型。研究人员需要非常清楚自己在做什么,并提出具有预测能力的参数。而且统计建模通常用于较低维度的数据集。
5、不同的着重点:
机器学习着重于探索数据所展现的关系和结构,更关心模型的预测能力,即更注重模型的优化和性能。
统计建模着重于评估小样本数据中所体现的关系和结构在总体中推广,更关心模型的可解释性,即更注重模型的推导。
关于这一点,我们或许可以从下面这两段分别来自统计学家和机器学习研究人员针对同一数据模型的描述上得到更深的体会。
机器学习研究人员:在给定 a、b 和 c 的前提下,该模型准确预测出结果 Y 的概率达到了 85%。
统计学家:在给定 a、b 和 c 的前提下,该模型准确预测出结果 Y 的概率达到了 85%;而且我有九成的把握你也会得到与此相同的结论。
6、不同的数据生成方式:
统计建模认为,数据由某个概率模型生成。统计的目标是找出对应的概率模型
因
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









