







基于pytorch的预训练模型,结合opencv处理图像,用flask搭建本地服务器,在web给用户提供鱼类识别的项目。
目录
pytorch代码
import os
import cv2
import torch
from random import uniform
from torch import optim, nn, device, cuda, save
import torchvision.transforms as T
import torchvision
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
# opencv图像处理
def pre_handing_train(img_path):
# 读取图片,灰度化
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
# 除背景噪声
img = cv2.medianBlur(img, 3)
img = cv2.GaussianBlur(img, (3, 3), 0)
# 锐化边缘
img = cv2.equalizeHist(img)
return img
def pre_handing_test(img_path):
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
return img
# 读取图像处理
class PicDataset(Dataset):
def __init__(self, path, transform=None):
if path == "pic/":
pre_handing = pre_handing_train
else:
pre_handing = pre_handing_test
join = os.path.join
listdir = os.listdir
self.transform = transform
self.images = [] # 存储图像数据
self.labels = [] # 存储标签
appendI = self.images.append
appendL = self.labels.append
# 遍历每个分类的文件夹
for folder in listdir(path):
folder_path = join(path, folder)
# 遍历每张图片
for filename in listdir(folder_path):
# 每一张图片所在的文件路径
img_path = join(folder_path, filename)
# opencv处理
img = pre_handing(img_path)
# 存储图像信息
appendI(img)
appendL(int(folder))
# 每一张图片的存储长度
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
label = self.labels[idx]
# 转存储格式为tensor格式
if self.transform is not None:
image = self.transform(image)
return image, label
train_dir = "fishP/train"
# 构建训练集的各种操作集合,创建训练集
transform_train = T.Compose([
T.ToPILImage(), # 将图片存储格式转为PIL类型
T.Resize((32, 32)), # 将图片按比例重塑成64*64像素大小
T.Grayscale(num_output_channels=3), # 灰度化图片,输出三个通道
T.ToTensor(), # 将图片存储格式转为tensor类型
# 数据标准化,即均值为0,标准差为1。
# 简单来说就是将数据按通道进行计算,将每一个通道的数据先计算出其方差与均值,然后再将其每一个通道内的每一个数据减去均值,再除以方差,得到归一化后的结果。
# 在深度学习图像处理中,标准化处理之后,可以使数据更好的响应激活函数,提高数据的表现力,减少梯度爆炸和梯度消失的出现。
T.Normalize((0.5,), (0.5,)),
T.RandomHorizontalFlip(p=0.3), # 随机水平翻转
T.RandomRotation(10) # 随机将图片旋转10°
])
trainset = PicDataset(train_dir, transform=transform_train)
trainloader = DataLoader(trainset, batch_size=2, shuffle=True)
# 加载预训练模型vgg16并更改分类器的输出
model =torchvision.models.vgg16(weights="VGG16_Weights.DEFAULT")
for p in model.features.parameters():
p.requires_grad=False
model.classifier[-1].out_features=23
# 优先选择显卡训练
device = device("cuda:0" if cuda.is_available() else "cpu")
model.to(device)
# 损失函数计算
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=uniform(0.001, 0.01), momentum=0.9)
print('start train')
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
# 对于分类任务,output是一个概率分布,每个元素表示相应的类别的置信度得分,可使用softmax将其转化为概率值
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 取模运算,每200个小批量打印一次
if i % 200 == 199:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('Finished Train')
# 保存模型的参数
torch.save(model.state_dict(), 'model.pth')
# 测试集路径
test_dir = "fishP/valid/"
# 构建测试集的各种操作集合,创建测试级
transform_test = T.Compose([
T.ToPILImage(), # 将图片存储格式转为PIL类型
T.Resize((64, 64)), # 将图片按比例重塑成64*64像素大小
T.Grayscale(num_output_channels=3), # 灰度化图片,输出三个通道
T.Normalize((0.5,), (0.5,)),
T.ToTensor(), # 将图片存储格式转为tensor类型
])
testset = PicDataset(test_dir, transform=transform_test)
testloader = DataLoader(testset, batch_size=64, shuffle=True)
# 测试模型
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (
100 * correct / total))
flask本地服务器代码
import os
from flask import Flask, request, render_template
from werkzeug.utils import secure_filename
import torch
import torch.nn.functional as F
from torchvision import transforms
from PIL import Image
import torchvision.models as models
app = Flask(__name__)
# 用户上传的文件的保存路径
UPLOAD_FOLDER = 'static'
ALLOWED_EXTENSIONS = {'jpg', 'jpeg', 'png', 'gif'}
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/')
def index():
return render_template('index.html')
@app.route('/1.html', methods=["GET"])
def loop1():
return render_template('1.html')
@app.route('/2.html', methods=["GET"])
def loop2():
return render_template('2.html')
@app.route('/3.html', methods=["GET"])
def loop3():
return render_template('3.html')
@app.route('/4.html', methods=["GET"])
def loop4():
return render_template('4.html')
@app.route('/5.html', methods=["GET"])
def loop5():
return render_template('5.html')
@app.route('/upload', methods=["POST"])
def upload():
file = request.files["image"]
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
# 参数=路径+文件名
result = classify_fish(os.path.join(UPLOAD_FOLDER, filename))
return render_template('2.html', result=result, statement="当前文件:" + filename)
else:
return render_template('2.html', statement="未选择文件或文件有误")
def classify_fish(image_file):
# 加载模型
model = models.vgg16()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# 图像预处理和归一化
preprocess = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 将图像转换为 PyTorch 张量
image = Image.open(image_file).convert('RGB')
image = preprocess(image)
image = image.unsqueeze(0)
with torch.no_grad():
output = model(image)
# torch.max()表示在张量中取最大值,参数:操作对象,操作维度
# 操作维度是1,表示类别维度上取最大值
# torch.max(output.data, 1)返回的是一个元组,(最大值,最大值对应的索引)
# predict是一个张一维量,表示分类物品的编号
_, predict = torch.max(output.data, 1)
return predict.item()
if __name__ == '__main__':
app.secret_key = 'supersecretkey'
app.config['SESSION_TYPE'] = 'filesystem'
# 只允许用户上传图片文件
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.run(debug=True)
以下是我的文件目录,fishR文件夹是我的项目文件目录
fishP文件夹存放训练集和测试集,static文件夹存放一些用户上传的文件和js文件,templates文件夹存放html文件,test文件夹是存放一些无关紧要的测试文件,不需要建立,app.py存放基于flask建立的本地服务器,p3.py存放着pytorch训练代码。文件夹(static,templates)的命名一定要和我的一样,不然会出问题。
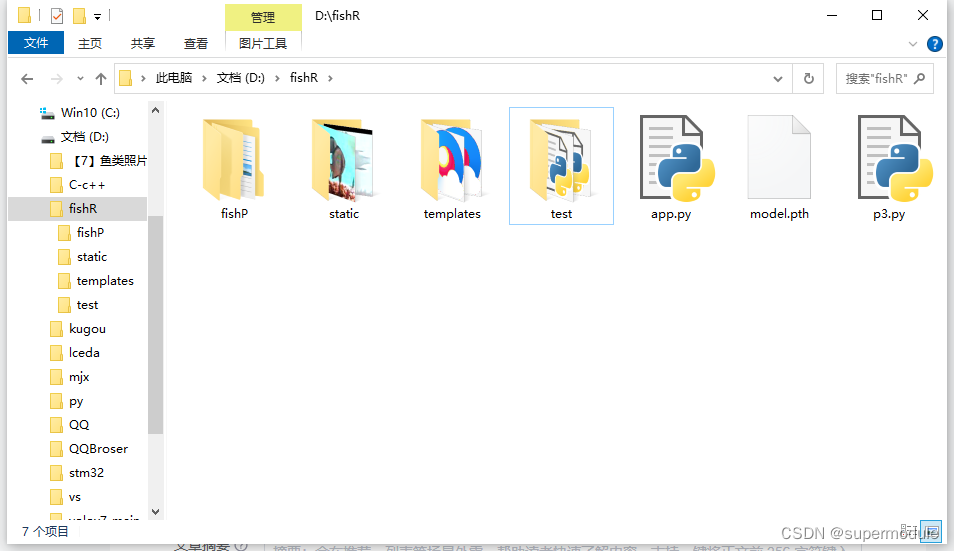
我的templates文件夹下的目录
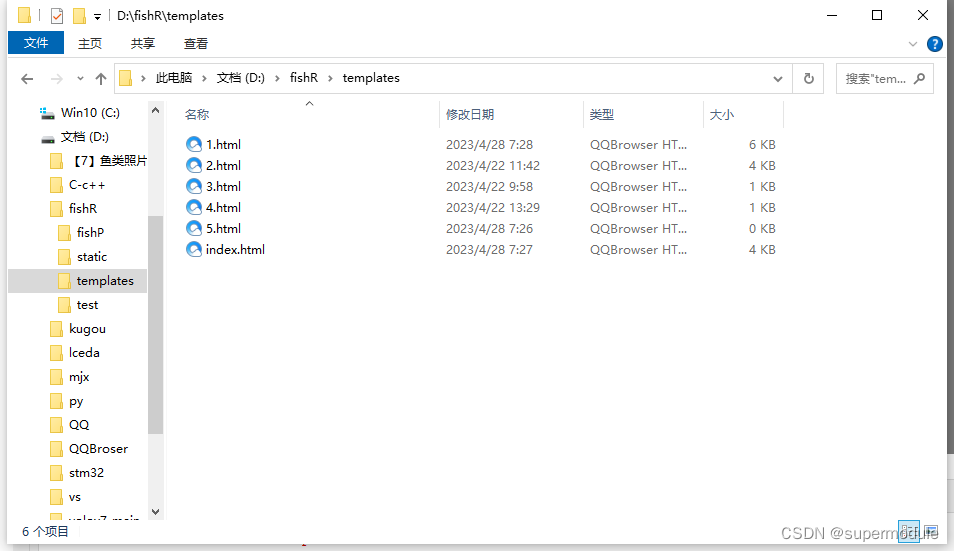
fishP下的文件目录
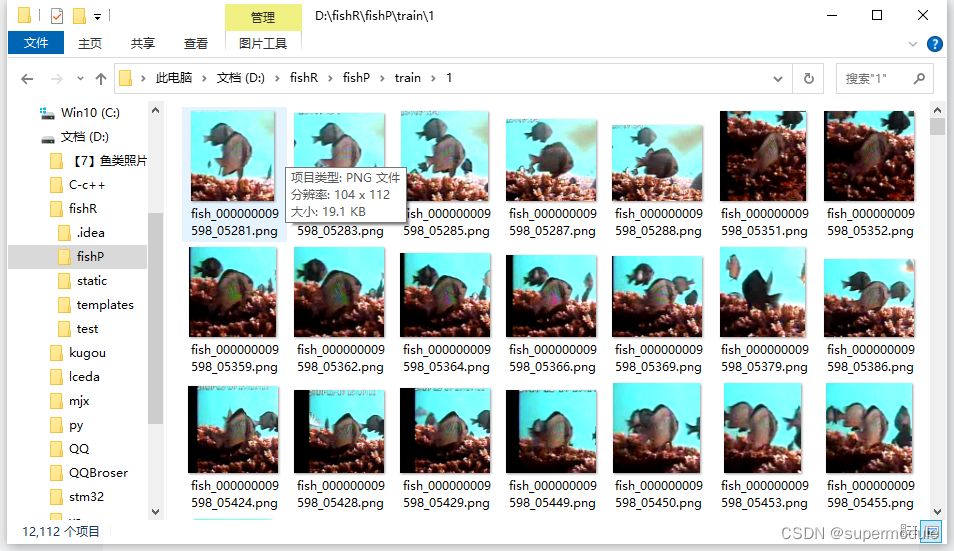
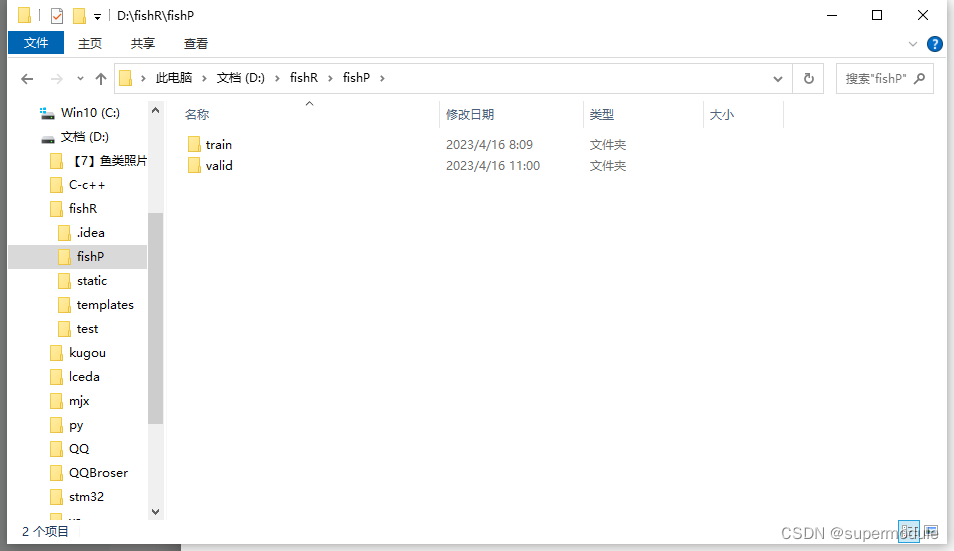 train (训练集)文件夹下放着每一种鱼的文件夹
train (训练集)文件夹下放着每一种鱼的文件夹
valid (测试集或者叫验证集)文件夹下放着每一种鱼的文件夹

这里用数字表示鱼的种类
以下是我的html文件的代码
有部分html文件我没贴出来,是因为那些文件暂时是空的,作为我以后的功能拓展。可以根据个人需求建立相应的html文件
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>鱼型识别系统</title>
<style>
h1 {text-align: center;padding: 30px;color: #ff4800}
body {
background-image: url("https://img2.baidu.com/it/u=1029016406,1880474304&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=500");
background-size: cover;
background-attachment: fixed;
opacity: 0.9;
background-color: cornflowerblue;
}
input[type="submit"] {
background-color: #ff4800;
border: none;
padding: 10px 20px;
text-decoration: none;
margin: 20px 0;
border-radius: 5px;
color: white;
}
#d0 {
text-align: center;
display: flex;
justify-content: center;
align-items: center;
}
#d1 {
width: 30%;
height: 75%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
}
#d1:hover {
background-color:rgba(255,255,255,0.6);
}
#d2 {
width: 30%;
height: 75%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
}
#d2:hover {
background-color:rgba(255,255,255,0.6);
}
#d2 > p {
padding: 70px;
color: red;
font-size: 15px;
}
#d3 {
width: 30%;
height: 75%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
}
#d3:hover {
background-color:rgba(255,255,255,0.6);
}
#d4 {
text-align: center;
display: flex;
justify-content: center;
align-items: center;
}
#d5 {
width: 30%;
height: 75%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
}
#d5:hover {
background-color:rgba(255,255,255,0.6);
}
#d6 {
width: 30%;
height: 75%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
}
#d6:hover {
background-color:rgba(255,255,255,0.6);
}
</style>
</head>
<body>
<h1>辅助鱼类研究系统</h1>
<div id="d0">
<div id="d1" onclick="window.location.href='1.html'">
<h1>3维追踪</h1>
</div>
<div id="d2"
onclick="window.location.href='2.html'">
<h1>快速识别</h1>
</div>
<div id="d3"
onclick="window.location.href='3.html'">
<h1>使用指南</h1>
</div>
</div>
<br>
<div id="d4">
<div id="d5"
onclick="window.location.href='4.html'">
<h1>鱼类种质库</h1>
</div>
<div id="d6"
onclick="window.location.href='5.html'">
<h1>信息记录</h1>
</div>
</div>
</body>
</html>2.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
body {
/*渐变色*/
background: radial-gradient(circle at center,cornflowerblue,cadetblue);
}
h1 {text-align: center}
form{
margin: auto;
width: 50%;
padding: 10px;
text-align: center;
}
.result p{
font-weight: bold;
}
button {
background-color: #ff4800;
border: none;
padding: 10px 20px;
text-decoration: none;
margin: 20px 0;
border-radius: 5px;
color: white;
}
button:hover {
box-shadow: 0 0 25px orangered;
box-reflect: below 1px linear-gradient(transparent,rgba(0,0,0,0.3));
}
input[type="button"] {
background-color: #ff4800;
border: none;
padding: 10px 20px;
text-decoration: none;
margin: 20px 0;
border-radius: 5px;
color: white;
}
input[type="button"]:hover {
box-shadow: 0 0 25px orangered;
box-reflect: below 1px linear-gradient(transparent,rgba(0,0,0,0.3));
}
main {
width: 50%;
height: 50%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
padding: 1%;
}
div {
display: flex;
}
#s1 {
width: 33%;
height: 30%;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
margin: auto;
padding: 10%;
}
#uploadFile {
display: none;
}
</style>
<script>
function clickFile(){
const input=document.querySelector('#uploadFile')
input.click()
// let f = document.getElementById('uploadFile').files;
// let [fileName, fileSize, fileType] = [f[0].name,f[0].size, f[0].type];
// /*分别获取 文件名 文件大小 文件类型*/
// document.getElementById("stmend").innerHTML="当前选择的文件是"+fileName
}
</script>
</head>
<body>
<header>
<h1>鱼种属快速识别</h1>
</header>
<div>
<main>
<form enctype="multipart/form-data" method="POST" action="/upload">
<input type="hidden" name="MAX_FILE_SIZE" value="100000">
<input id="uploadFile" type="file" name="image">
<section id="s2">
{% if statement %}
<div class="statement">
<p>{{ statement }}</p>
</div>
{% endif %}
</section>
<input type="button" value="上传图片" class="btn" onclick="clickFile()">
<button type="submit">查询</button>
</form>
</main>
</div>
<br>
<div>
<section id="s1">
{% if result %}
<div class="result">
<p>这张图片上的鱼是 {{ result }}</p>
</div>
{% endif %}
</section>
</div>
</body>
</html>1.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<meta http-equiv="Content-Type" content="text/html" charset="UTF-8">
<title>3d建模</title>
<style>
html {height: 100%}
body {height: 100%;margin: 0;padding: 0
}
#container {
height: 100%;
}
#d1 {
height: 100%;
width: 100%;
display: grid;
grid-template-columns: 3fr 1fr;
}
main {
background-color: rgba(195,150,255,0.5);
border: 1px solid rgba(195,191,255,0.5);
text-align: center;
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
}
button {
background-color: orange;
}
#d2:hover {
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
}
p:hover {
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(255,255,255,0.3);
text-align: center;
}
p {
border: 2px solid rgba(195,150,255,1);
border-radius: 20px;
}
#d2 {
background-color: rgba(195,150,255,0.5);
font-size: 20px;
border: 2px solid rgba(195,150,255,1);
border-radius: 20px;
}
#d3 {
background-color: rgba(195,150,255,0.5);
font-size: 20px;
border: 2px solid rgba(195,150,255,1);
border-radius: 20px;
}
#d3:hover {
background-blend-mode: normal,soft-light;
-webkit-backdrop-filter: blur(50px);
border-radius: 20px;
background-color:rgba(195,150,255,0.9);
text-align: center;
}
</style>
<script type="text/javascript" src="https://api.map.baidu.com/api?v=3.0&ak=你的百度地图密钥"></script>
</head>
<body>
<div id="d1">
<div id="container"></div>
<div>
<main>
<h1 style="color: #ff4800">西湖鱼群信息</h1>
<p>时间:<script>
var d=new Date()
document.write(d)
</script></p>
<p>气温:</p>
<p>空气湿度:</p>
<p>水温:</p>
<p>溶氧量:</p>
<p>水pH:</p>
<p>气压:</p>
<p>绿藻含量</p>
<p>鱼群数量:</p>
<p>检测到:</p>
<p>罗非鱼</p>
<p>草鱼</p>
<div id="d2" onclick="window.location.href='2.html'">历史记录</div><br>
<div id="d3" onclick="window.location.href='index.html'">回到主页</div>
</main>
</div>
</div>
<script type="text/javascript">
// 定义一个自定义控件
function resZoomControl(){
//设置默认停靠位置和偏移量
this.defaultAnchor=BMAP_ANCHOR_TOP_LEFT
this.defaultOffset=new BMap.Size(10,10)
}
// 通过JavaScript的prototype属性继承于BMap.Control
resZoomControl.prototype=new BMap.Control()
resZoomControl.prototype.initialize=function(map){
// 创建一个DOM元素
var div=document.createElement("div")
// 添加文字说明
div.appendChild(document.createTextNode("回中"))
// 设置样式
div.style.cursor="pointer"
div.style.border="1px solid gray"
div.style.backgroundColor="red"
// 绑定事件,点击回到中心处
div.onclick=function(e){
map.panTo(new BMap.Point(113.370,23.170))
}
}
</script>
<script type="text/javascript">
// 创建地图实例
var map =new BMap.Map("container");
// 创建点坐标,华南农业大学西湖
var point=new BMap.Point(113.370,23.170);
// 初始化地图设置中心点坐标和地图级别
map.centerAndZoom(point,15);
// 或者,你可以设置城市名为中心点
// map.centerAndZoom("广州",15);
//创建自定义控件实例
var myZoomCtrl = new resZoomControl();
// 添加到地图当中
map.addControl(myZoomCtrl);
// 开启鼠标滚轮缩放
map.enableScrollWheelZoom(true);
// 添加控件
map.addControl(new BMap.NavigationControl());// 平移缩放功能
map.addControl(new BMap.ScaleControl());// 比例尺
map.addControl(new BMap.OverviewMapControl());// 可折叠的缩略地图
map.addControl(new BMap.GeolocationControl());// 定位
map.addControl(new BMap.MapTypeControl());// 设置地图类型
map.setCurrentCity("广州"); // 仅当设置城市信息时,MapTypeControl的切换功能才能可用
</script>
</body>
</html>
html效果

















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









