







1. Frequency-domain MLPs are More Effective Learners in Time Series Forecasting
作者:Kun Yi, Qi Zhang, Wei Fan, Hui He, Pengyang Wang, Shoujin Wang, Ning An, Defu Lian, Longbing Cao, Zhendong Niu
链接:Frequency-domain MLPs are More Effective Learners in Time Series Forecasting
代码:https://github.com/aikunyi/FreTS
关键词:频域、MLP(疑似又是化繁为简的工作,类似DLinear),时间序列预测
摘要:时间序列预测在金融、交通、能源、医疗等不同行业中发挥着关键作用。 虽然现有文献设计了许多基于 RNN、GNN 或 Transformer 的复杂架构,但提出了另一种基于多层感知器(MLP)的方法,其结构简单、复杂度低且性能优越。 然而,大多数基于MLP的预测方法都存在逐点映射和信息瓶颈,这在很大程度上阻碍了预测性能。 为了克服这个问题,本文探索了在频域中应用 MLP 进行时间序列预测的新方向。 研究了频域 MLP 的学习模式,发现了它们有利于预测的两个固有特征:(i)全局视图:频谱使 MLP 拥有完整的信号视图并更容易学习全局依赖性,以及(ii)能量压缩:频率 域 MLP 集中于具有紧凑信号能量的频率分量的较小关键部分。 然后,本文提出了 FreTS,这是一种基于频域 MLP 的简单而有效的架构,用于时间序列预测。 FreTS主要涉及两个阶段,(i)域转换,将时域信号转换为频域复数; (ii) 频率学习,执行重新设计的 MLP,以学习频率分量的实部和虚部。 上述在系列间和系列内尺度上运行的阶段进一步有助于通道方面和时间方面的依赖性学习。 对 13 个现实世界基准(包括 7 个短期预测基准和 6 个长期预测基准)进行的广泛实验证明了相对于最先进方法的一贯优势。
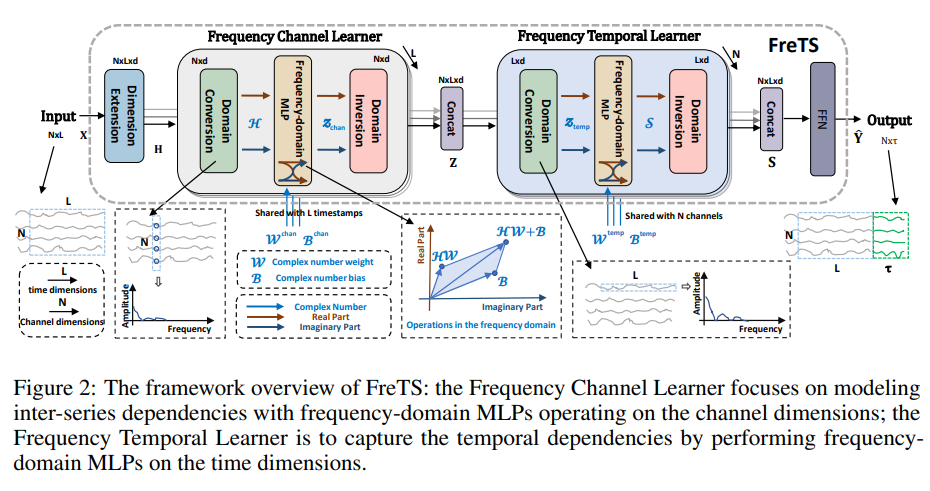

2. FourierGNN: Rethinking Multivariate Time Series Forecasting from a Pure Graph Perspective
作者:Kun Yi, Qi Zhang, Wei Fan, Hui He, Liang Hu, Pengyang Wang, Ning An, Longbing Cao, Zhendong Niu
链接:https://neurips.cc/virtual/2023/poster/71159
代码:https://github.com/aikunyi/FourierGNN
关键词:图神经网络、多元时间序列预测
摘要:多元时间序列 (MTS) 预测在许多行业中表现出非常重要的作用。 当前最先进的基于图神经网络(GNN)的预测方法通常需要图网络(例如 GCN)和时间网络(例如 LSTM)来捕获系列间(空间)动态和系列内( 分别是时间)依赖性。 然而,两个网络的不确定兼容性给模型手动设计带来了额外的负担。 此外,分离的时空建模自然违反了现实世界中统一的时空相互依赖关系,这在很大程度上阻碍了预测性能。 为了克服这些问题,本文探索了直接应用图网络的有趣方向,并从纯图的角度重新思考 MTS 预测。 首先定义了一种新颖的数据结构——超变量图,它将每个序列值(无论变量或时间戳)视为图节点,并将滑动窗口表示为时空全连接图。 该观点统一考虑时空动力学,并将经典 MTS 预测重新表述为超变量图的预测。 然后,本文提出了一种新颖的架构傅里叶图神经网络(FourierGNN),通过堆叠本文提出的傅里叶图运算符(FGO)来在傅里叶空间中执行矩阵乘法。 FourierGNN 提供了足够的表达能力并实现了低得多的复杂度,可以有效且高效地完成预测。 此外,理论分析揭示了 FGO 在时域上与图卷积的等价性,这进一步验证了 FourierGNN 的有效性。 对七个数据集的广泛实验证明了与最先进的方法相比,具有更高的效率和更少的参数的卓越性能。
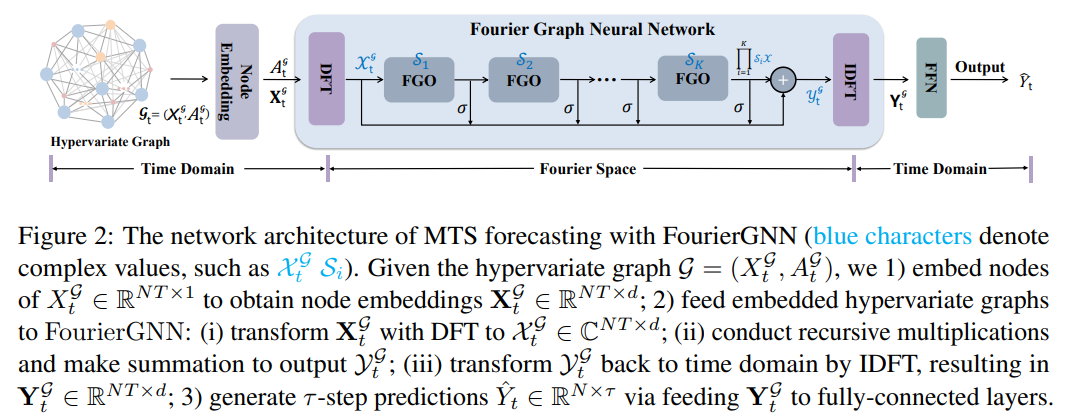
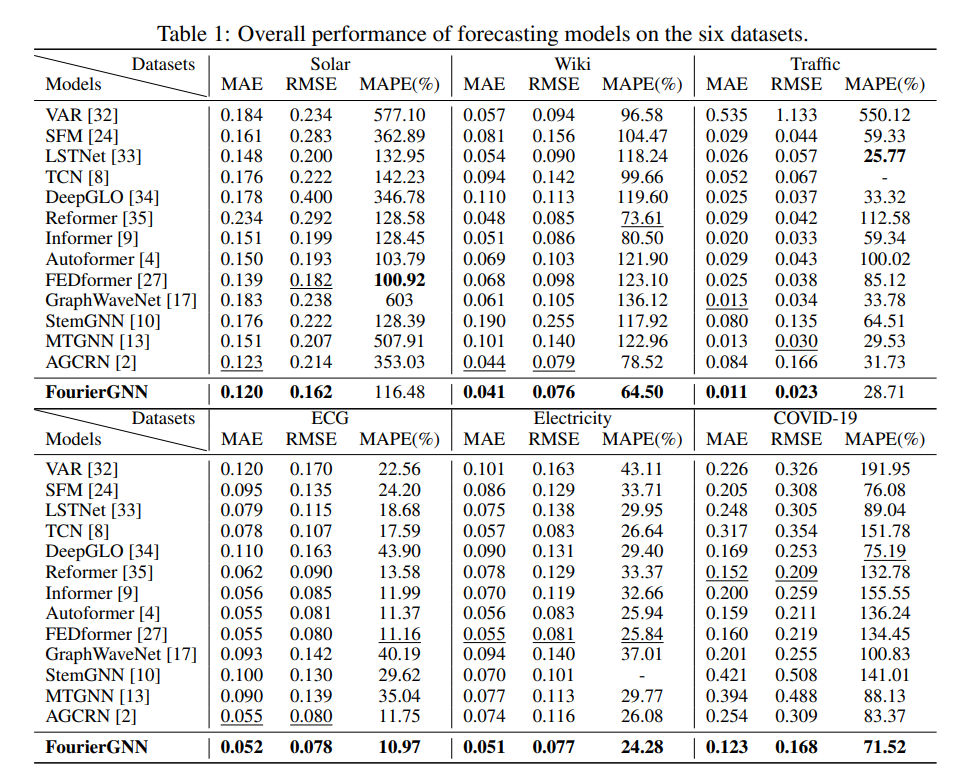
3. CrossGNN: Confronting Noisy Multivariate Time Series Via Cross Interaction Refinement
作者:qihe huang, Lei Shen, Ruixin Zhang, Shouhong Ding, Binwu Wang, Zhengyang Zhou, Yang Wang
链接:https://neurips.cc/virtual/2023/poster/70010
代码:https://github.com/hqh0728/CrossGNN
关键词:图神经网络、多元时间序列预测
摘要:近年来,多元时间序列(MTS)预测技术得到了快速发展并在各个领域得到广泛应用。 基于 Transformer 和基于 GNN 的方法由于其对时间和变量交互建模的强大能力而显示出巨大的潜力。 然而,通过对现实世界数据进行全面分析,发现现有方法并不能很好地处理变量之间的时间波动和异质性。 为了解决上述问题,本文提出了 CrossGNN,一种线性复杂性 GNN 模型,用于细化 MTS 的跨尺度和跨变量交互。 为了处理时间维度上的意外噪声,利用自适应多尺度标识符(AMSI)来构建降噪的多尺度时间序列。 提出了 Cross-Scale GNN 来提取趋势更清晰、噪声更弱的尺度。 跨变量 GNN 的提出是为了利用不同变量之间的同质性和异质性。 通过同时关注具有较高显着性分数的边缘并限制具有较低分数的边缘,时间和空间复杂度(即,CrossGNN 的 ) 可以与输入序列长度呈线性关系。 在 8 个真实 MTS 数据集上的广泛实验结果证明了 CrossGNN 与最先进方法相比的有效性。
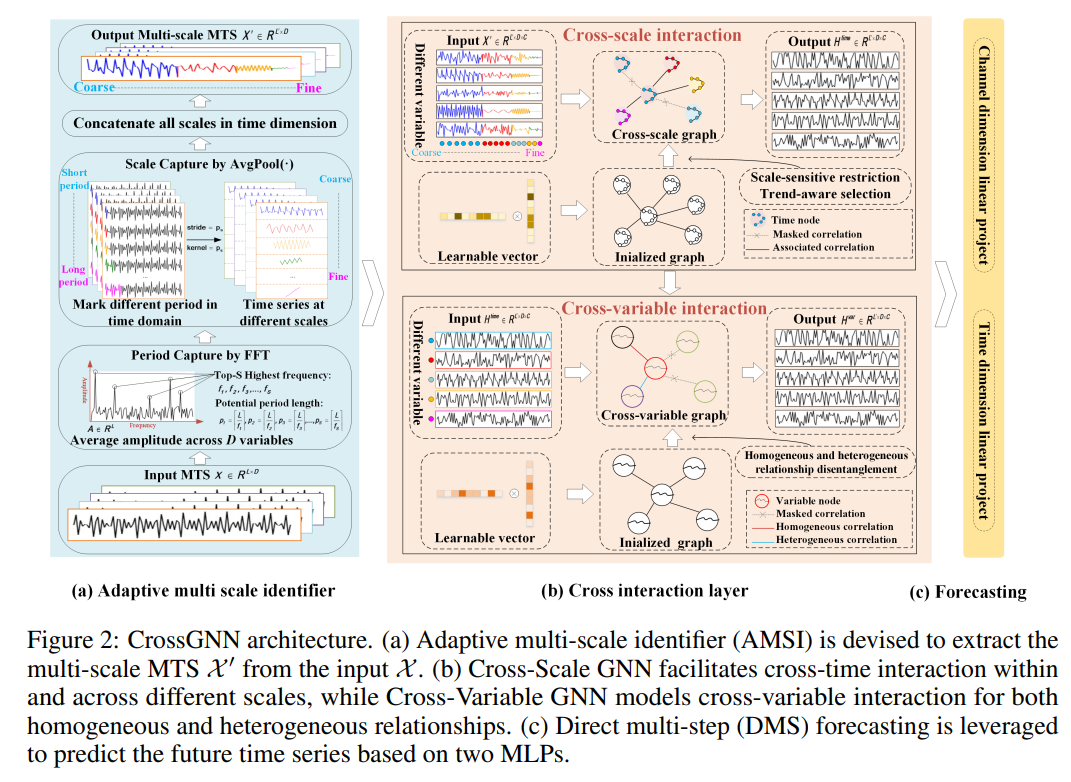
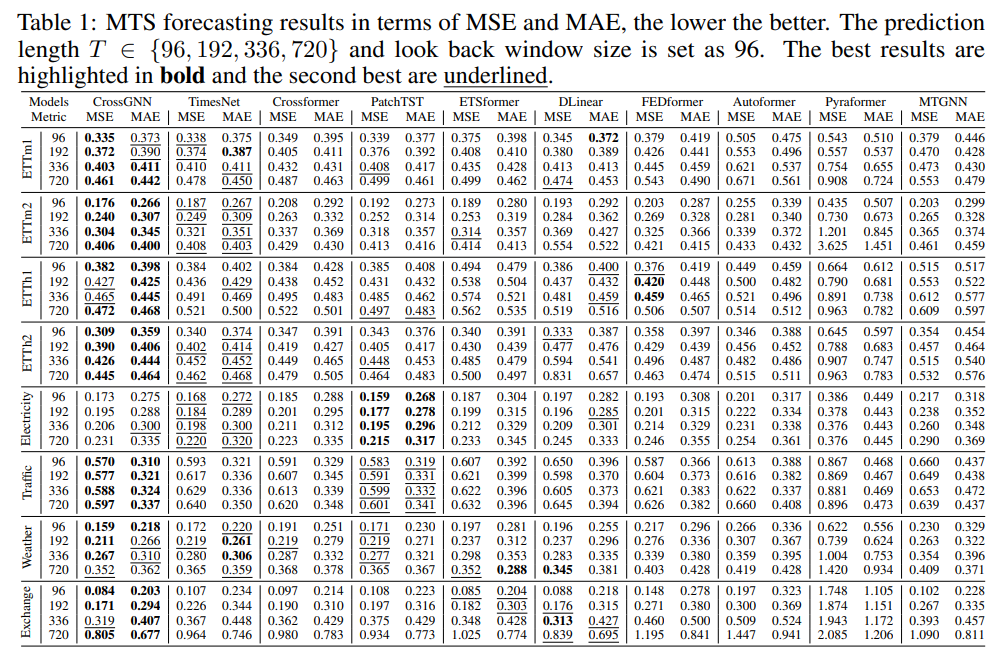
4. Adaptive Normalization for Non-stationary Time Series Forecasting: A Temporal Slice Perspective
作者:Zhiding Liu, Mingyue Cheng, Zhi Li, Zhenya Huang, Qi Liu, Yanhu Xie, Enhong Chen
链接:https://neurips.cc/virtual/2023/poster/72816
代码:https://github.com/icantnamemyself/SAN
摘要:深度学习模型由于其捕获序列依赖性的强大能力而逐渐提高了时间序列预测的性能。 然而,由于现实世界数据存在非平稳性,即数据分布随着时间的推移而快速变化,做出准确的预测仍然具有挑战性。 为了缓解这种困境,人们做出了一些努力,通过标准化操作来减少非平稳性。 然而,这些方法通常忽略了输入序列和水平序列之间的分布差异,并假设同一实例内的所有时间点具有相同的统计属性,这过于理想,可能导致相对改进不理想。 为此,提出了一种新颖的切片级自适应归一化,称为 SAN \textbf{SAN} SAN,这是一种通过更灵活的归一化和反归一化来增强时间序列预测的新颖方案。 SAN 包括两个关键设计。 首先,SAN 试图消除以局部时间片(即子序列)为单位而不是全局实例的时间序列的非平稳性。 其次,SAN采用轻微的网络模块来独立建模原始时间序列统计特性的演变趋势。 因此,SAN 可以作为通用的模型无关插件,更好地减轻时间序列数据非平稳特性的影响。 在四种广泛使用的预测模型上实例化了所提出的 SAN,并在基准数据集上测试它们的预测结果以评估其有效性。 此外,还报告了一些富有洞察力的发现,以深入分析和理解提出的 SAN。
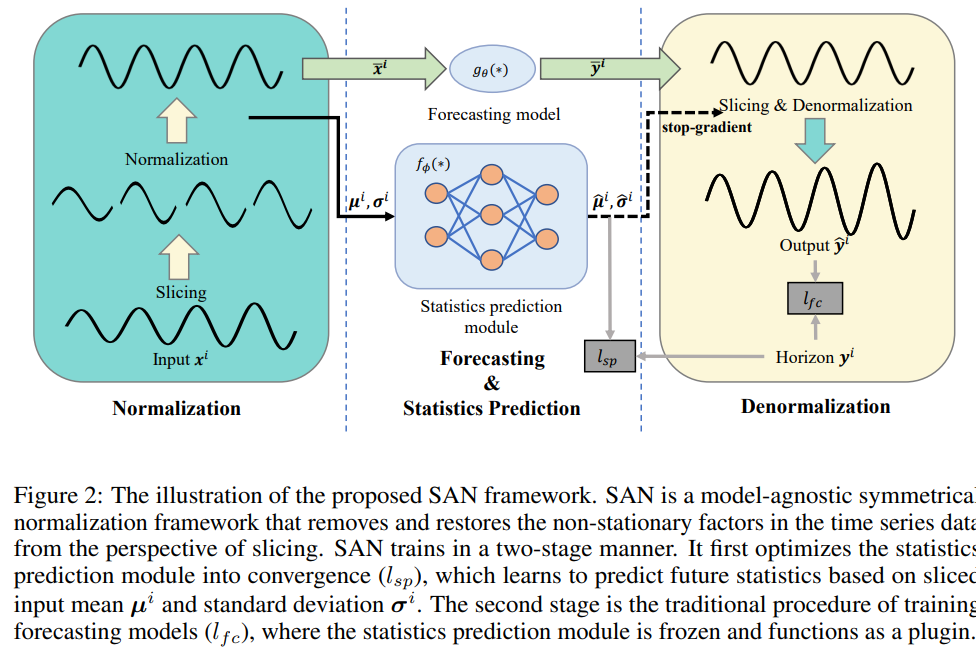
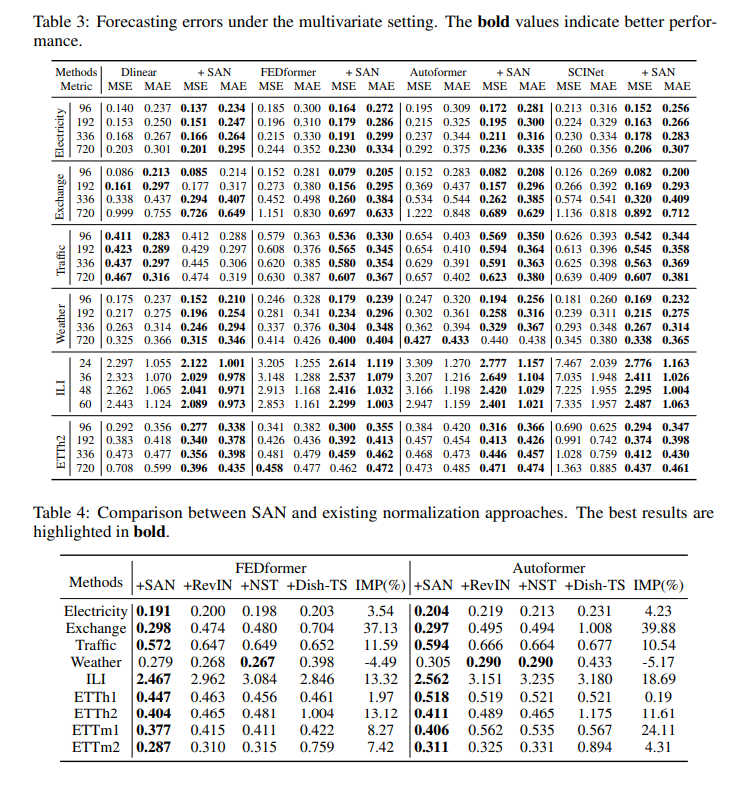
5. Koopa: Learning Non-stationary Time Series Dynamics with Koopman Predictors
作者:Yong Liu, Chenyu Li, Jianmin Wang, Mingsheng Long
链接:https://neurips.cc/virtual/2023/poster/72562 arXiv:https://arxiv.org/abs/2305.18803
代码:https://github.com/thuml/Koopa
关键词:非平稳时间序列预测
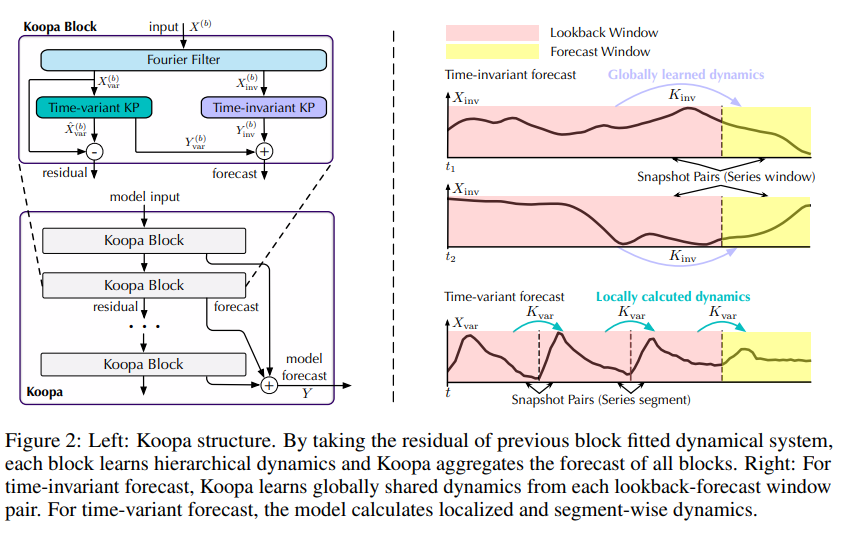
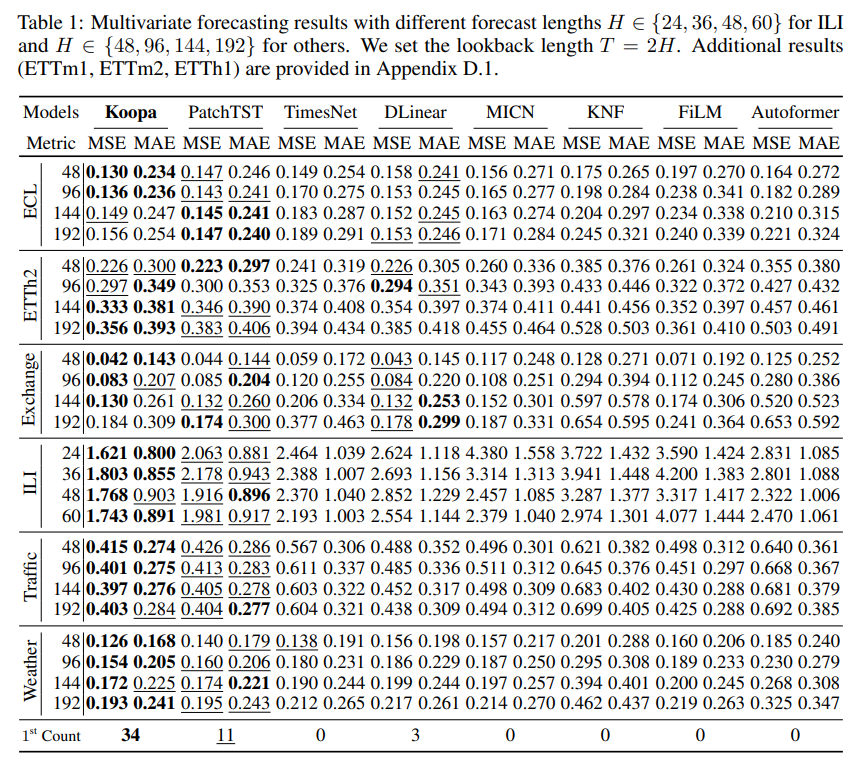
摘要:现实世界的时间序列具有内在的非平稳性,这对深度预测模型提出了主要挑战。 虽然以前的模型因时间分布变化而引起复杂的序列变化,但用现代库普曼理论(Koopman)来处理非平稳时间序列,该理论从根本上考虑了潜在的时变动力学。 受描述复杂动力系统的库普曼理论的启发,通过傅里叶滤波器从复杂的非平稳序列中分离出时变和时不变分量,并设计库普曼预测器来推进各自的动力学。 从技术上讲,建议 Koopa 作为一种新颖的 Koopman 预测器,由可学习分层动态的可堆叠块组成。 Koopa 寻求 Koopman 嵌入的测量函数,并利用 Koopman 算子作为隐式转换的线性描述。 为了应对表现出较强局部性的时变动态,Koopa 计算时间邻域中的上下文感知算子,并能够利用传入的地面实况来扩大预测范围。 此外,通过将库普曼预测器集成到深度残差结构中,阐明了先前库普曼预测器中的约束重建损失,并实现了端到端的预测目标优化。 与最先进的模型相比,Koopa 实现了具有竞争力的性能,同时节省了 77.3% 的训练时间和 76.0% 的内存。
6. SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
作者:Jiaxiang Dong, Haixu Wu, Haoran Zhang, Li Zhang, Jianmin Wang, Mingsheng Long
链接: https://neurips.cc/virtual/2023/poster/70829 arXiv:https://arxiv.org/abs/2302.00861
代码:https://github.com/thuml/SimMTM
关键词:预训练、统一框架建模
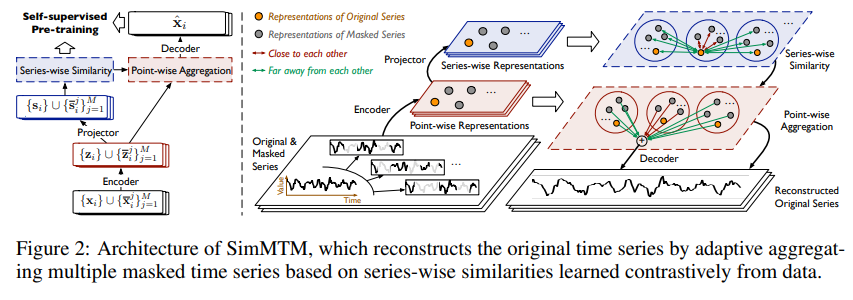
摘要:时间序列分析有着广泛的应用领域。 最近,为了减少标签费用并有利于各种任务,自监督预训练引起了人们的极大兴趣。 一种主流范式是屏蔽建模(mask),它通过学习基于未屏蔽部分重建屏蔽内容来成功地预训练深度模型。 然而,由于时间序列的语义信息主要包含在时间变化中,随机屏蔽部分时间点的标准方法将严重破坏时间序列的重要时间变化,使得重建任务难以指导表示学习。 因此,本文提出了 SimMTM,一个用于屏蔽时间序列建模的简单预训练框架。 通过将屏蔽建模与流形学习相关联,SimMTM 提出通过流形外部多个邻居的加权聚合来恢复屏蔽时间点,这通过组装多个屏蔽序列中被破坏但互补的时间变化来简化重建任务。 SimMTM 进一步学习揭示流形的局部结构,这有助于屏蔽建模。 实验上,与最先进的时间序列预训练方法相比,SimMTM 在预测和分类这两个典型时间序列分析任务中实现了最先进的微调性能,涵盖域内和跨域设置。
7. ContiFormer: Continuous-Time Transformer for Irregular Time Series Modeling
作者:Yuqi Chen, Kan Ren, Yansen Wang, Yuchen Fang, Weiwei Sun, Dongsheng Li
链接:https://neurips.cc/virtual/2023/poster/71304
关键词:(喜闻乐见的)Former改动、不规则时间序列,神经常微分方程
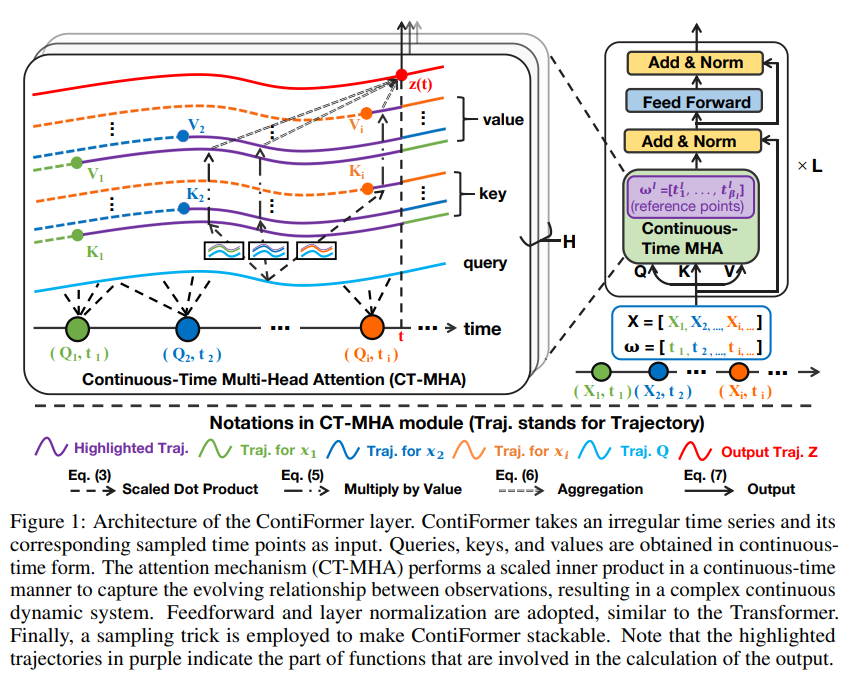
摘要:对不规则时间序列的连续时间动态进行建模对于解释连续发生的数据演变和相关性至关重要。 包括循环神经网络或 Transformer 模型在内的传统方法通过强大的神经架构利用归纳偏差来捕获复杂的模式。 然而,由于其离散特性,它们在推广到连续时间数据范式方面存在局限性。 尽管神经常微分方程(神经常微分方程)及其变体在处理不规则时间序列方面显示出有希望的结果,但它们通常无法捕获这些序列内复杂的相关性。 同时对输入数据点之间的关系进行建模并捕获连续时间系统的动态变化是具有挑战性和要求的。 为了解决这个问题,提出了 ContiFormer,它将普通 Transformer 的关系建模扩展到连续时间域,明确地将神经常微分方程的连续动态建模能力与 Transformer 的注意力机制结合起来。 从数学上描述了 ContiFormer 的表达能力,并说明,通过函数假设的精心设计,许多专门用于不规则时间序列建模的 Transformer 变体可以被视为 ContiFormer 的特例。 对合成数据集和真实数据集进行的广泛实验表明,ContiFormer 对不规则时间序列数据具有卓越的建模能力和预测性能。
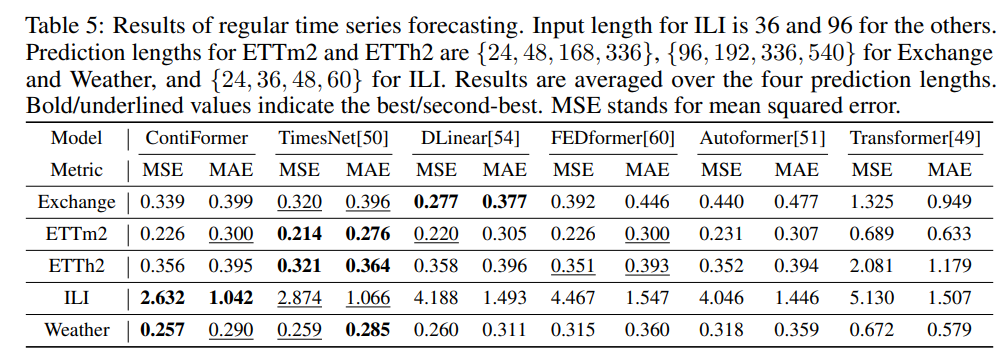
8. BasisFormer: Attention-based Time Series Forecasting with Learnable and Interpretable Basis
链接:https://neurips.cc/virtual/2023/poster/69976
代码:https://github.com/nzl5116190/Basisformer
关键词:(喜闻乐见的)Former改动、时间序列预测
摘要:Bases能够充当特征提取器或未来参考,因此Bases已成为基于深度学习的现代时间序列预测模型不可或缺的一部分。 为了有效,Bases必须针对特定的时间序列数据集进行定制,并与该集中的每个时间序列表现出明显的相关性。 然而,当前最先进的方法在同时满足这两个要求的能力方面受到限制。 为了应对这一挑战,提出了 BasisFormer,这是一种利用可学习和可解释基础的端到端时间序列预测架构。 该架构包含三个组成部分:首先,通过自适应自监督学习获取基础,它将时间序列的历史部分和未来部分视为两种不同的视图,并采用对比学习。 接下来,设计一个 Coef 模块,通过双向交叉注意力计算历史视图中时间序列和基数之间的相似性系数。 最后,提出了一个预测模块,它根据相似系数选择并巩固未来视图中的基础,从而产生准确的未来预测。 通过对六个数据集的广泛实验,证明 BasisFormer 在单变量和多变量预测任务上分别比之前最先进的方法高出 11.04% 和 15.78%。
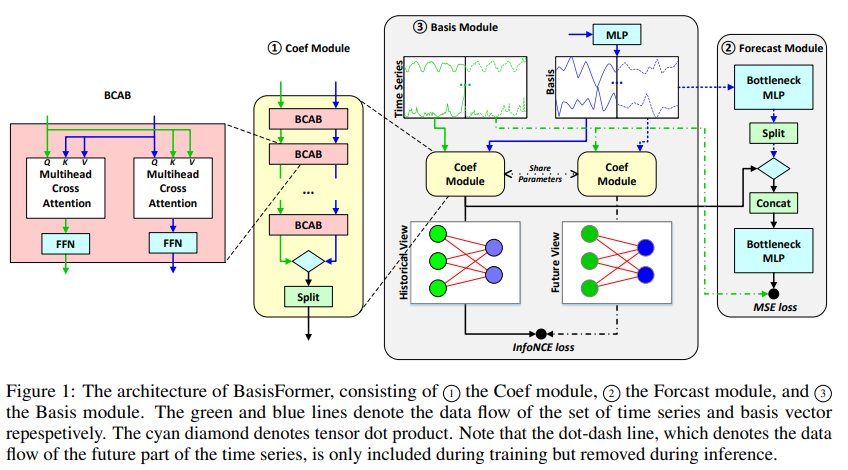
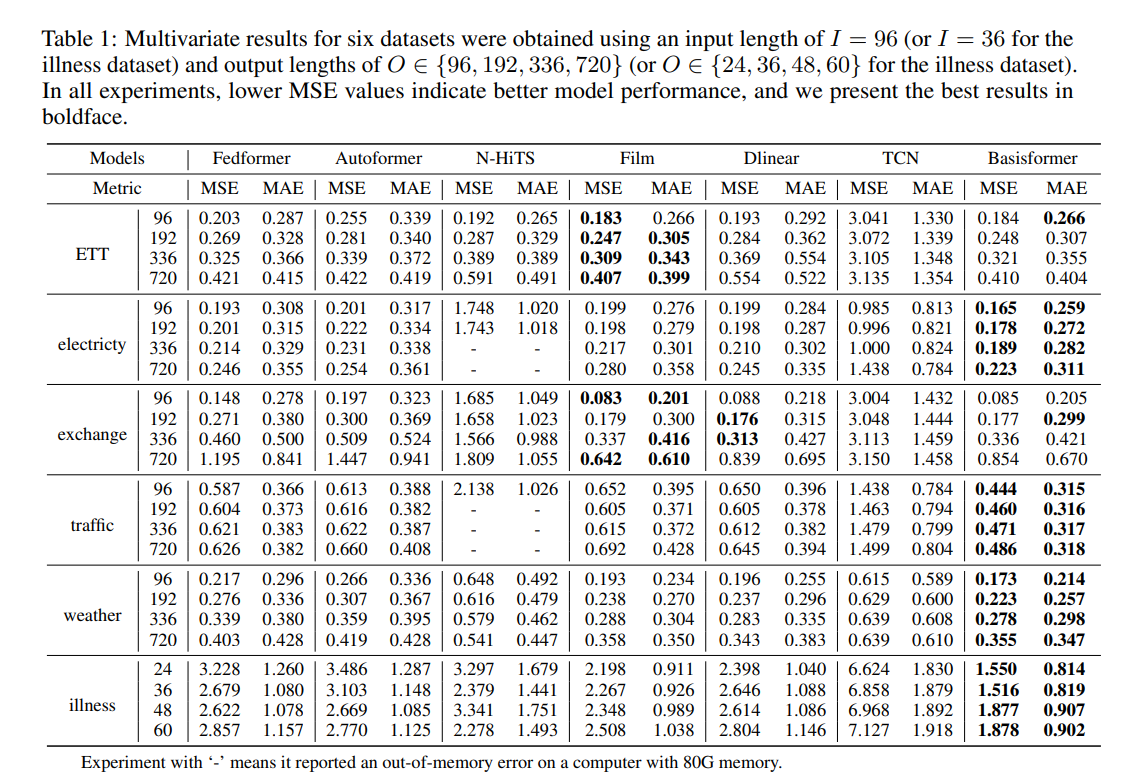
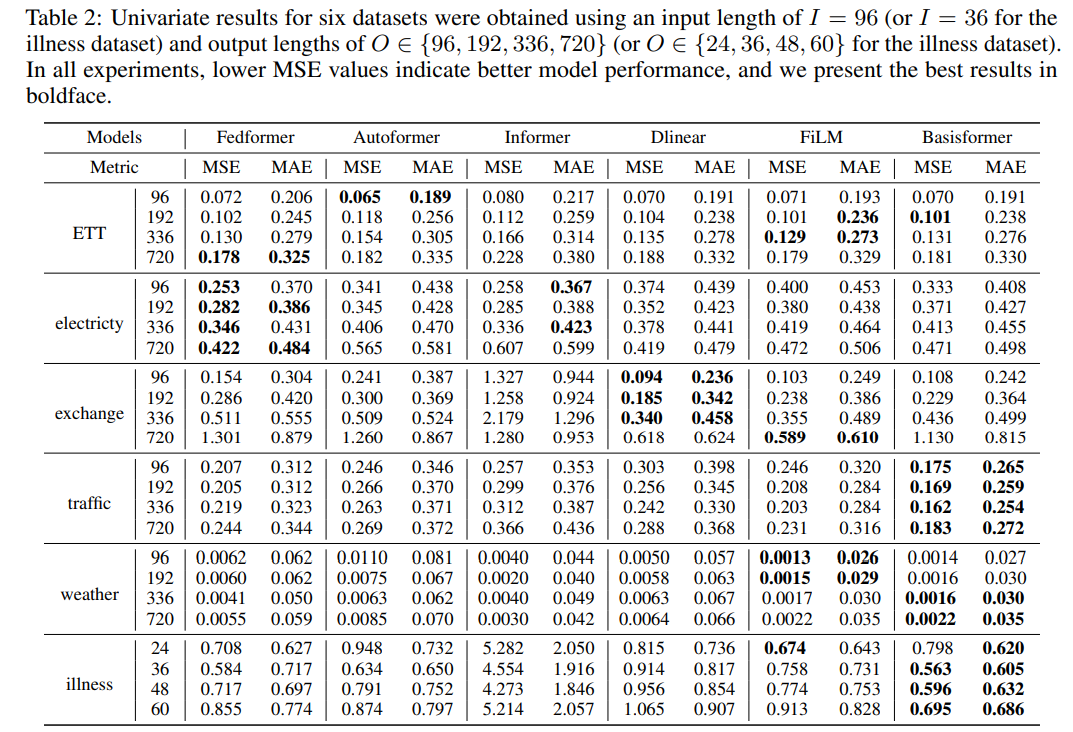
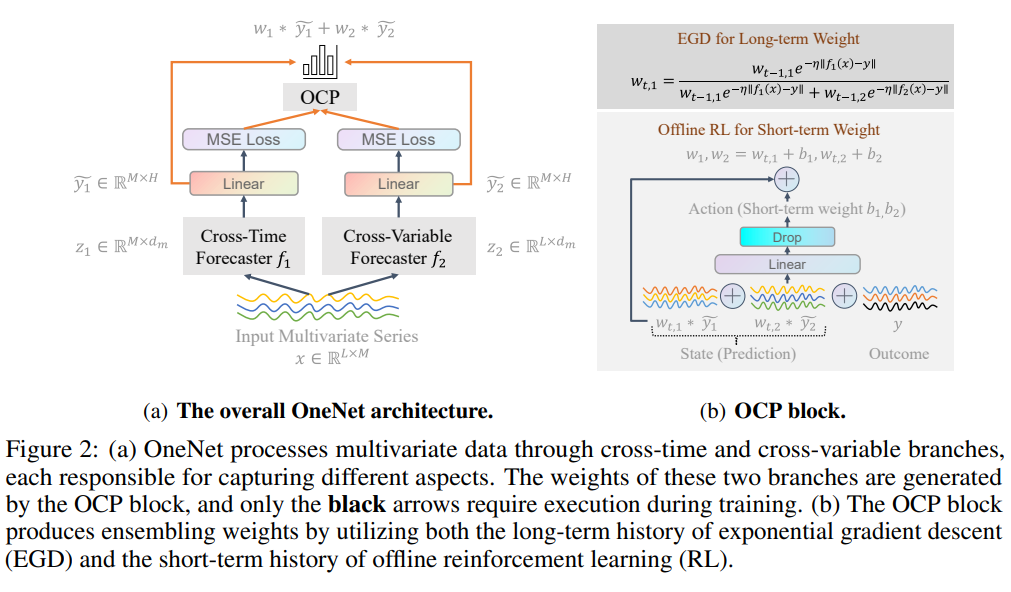
9. OneNet: Enhancing Time Series Forecasting Models under Concept Drift by Online Ensembling
作者:yifan zhang, Qingsong Wen, xue wang, Weiqi Chen, Liang Sun, Zhang Zhang, Liang Wang, Rong Jin, Tieniu Tan
链接:https://neurips.cc/virtual/2023/poster/71725 arXiv:OneNet: Enhancing Time Series Forecasting Models under Concept Drift by Online Ensembling
代码:https://github.com/yfzhang114/OneNet
关键词:时间序列预测、概念漂移
摘要:时间序列预测模型在线更新旨在通过基于流数据高效更新预测模型来解决概念漂移问题。 许多算法都是为在线时间序列预测而设计的,其中一些算法利用交叉变量依赖性,而另一些则假设变量之间的独立性。 鉴于每个数据假设在在线时间序列建模中都有其自身的优点和缺点,提出了在线集成网络(OneNet)。 它动态更新和组合两个模型,一个专注于跨时间维度的依赖关系建模,另一个专注于跨变量依赖关系建模。 OneNet将基于强化学习的方法融入到传统的在线凸编程框架中,允许动态调整权重的两个模型的线性组合。 OneNet 解决了经典在线学习方法的主要缺点,即适应概念漂移的速度往往较慢。 实证结果表明,与最先进的(SOTA)方法相比,OneNet 将在线预测误差降低了超过了50%
10. One Fits All: Power General Time Series Analysis by Pretrained LM (Spotlight)
这篇热度之前应该就很高,在各大平台应该都有针对的解读
作者:Tian Zhou(FEDFormer(ICML 22) FilM(NeurIPS 22)一作), Peisong Niu, xue wang, Liang Sun, Rong Jin
链接:https://neurips.cc/virtual/2023/poster/70856 https://arxiv.org/abs/2302.11939
代码:https://github.com/DAMO-DI-ML/NeurIPS2023-One-Fits-All
关键词:大模型、时间序列统一任务
 ](https://gitee.com/bestZKS/note-pic/raw/master/img/20231112184559.png)
](https://gitee.com/bestZKS/note-pic/raw/master/img/20231112184559.png)
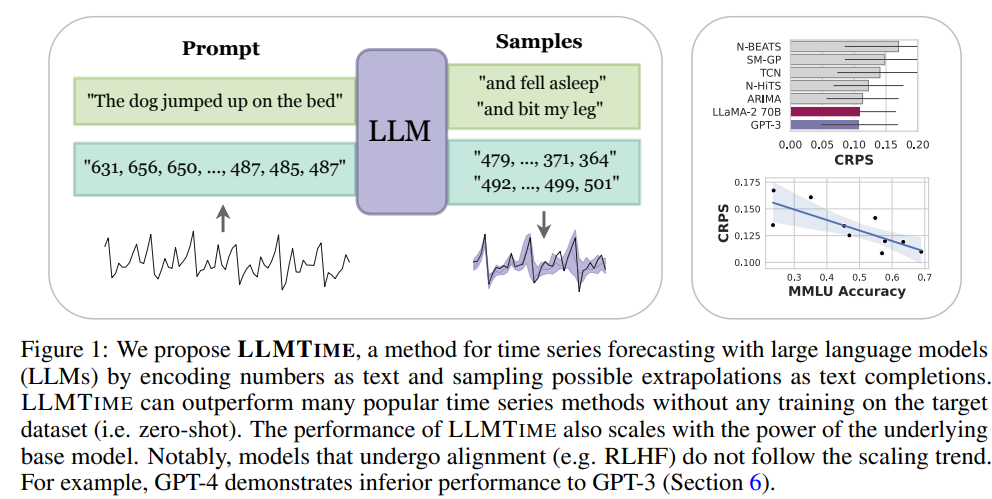
11. Large Language Models Are Zero Shot Time Series Forecasters
作者:Marc Finzi, Nate Gruver, Shikai Qiu, Andrew Wilson
链接:https://neurips.cc/virtual/2023/poster/70543
代码:https://github.com/ngruver/llmtime
关键词:大模型、零样本、时间预测
摘要:通过将时间序列编码为一串数字,可以将时间序列预测构建为文本中的下一个标记预测。 通过开发这种方法,发现 GPT-3 和 LLaMA-2 等大型语言模型 (LLM) 可以令人惊讶地以零样本推断时间序列,其水平可与或超过在下游训练的专用时间序列模型的性能 任务。 为了促进这种性能,提出了有效标记时间序列数据并将标记上的离散分布转换为连续值上的高度灵活的密度的程序。 认为时间序列LLM的成功源于它们自然地表示多模态分布的能力,再加上简单性和重复性的偏差,这与许多时间序列中的显着特征相一致,例如重复的季节性趋势。 还展示了LLM如何自然地处理缺失数据,而无需通过非数字文本进行插补,容纳文本辅助信息,并回答问题以帮助解释预测。 虽然发现增加模型大小通常会提高时间序列的性能,但发现 GPT-4 的性能可能比 GPT-3 差,因为它对数字进行标记的方式以及较差的不确定性校准,这可能是 RLHF 等对齐干预的结果。
显着特征相一致,例如重复的季节性趋势。 还展示了LLM如何自然地处理缺失数据,而无需通过非数字文本进行插补,容纳文本辅助信息,并回答问题以帮助解释预测。 虽然发现增加模型大小通常会提高时间序列的性能,但发现 GPT-4 的性能可能比 GPT-3 差,因为它对数字进行标记的方式以及较差的不确定性校准,这可能是 RLHF 等对齐干预的结果。
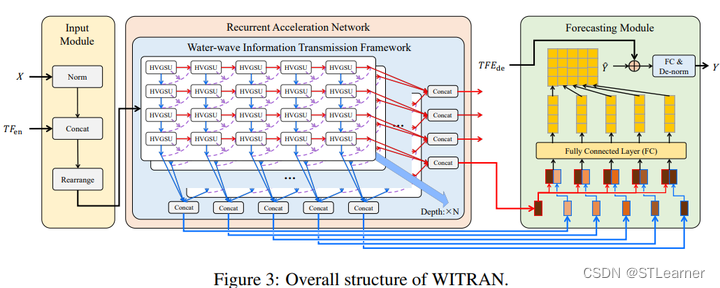
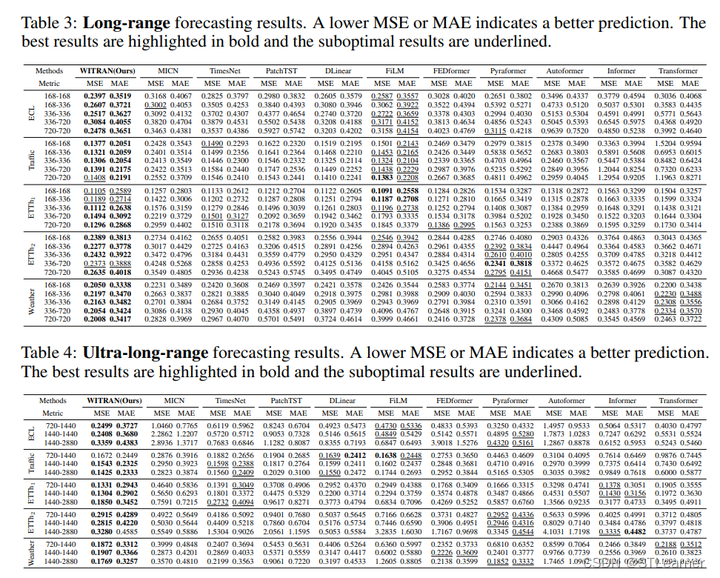
12. WITRAN: Water-wave Information Transmission and Recurrent Acceleration Network for Long-range Time Series Forecasting(Spotlight)
作者:Yuxin Jia, Youfang Lin, Xinyan Hao, Yan Lin, Shengnan Guo, Huaiyu Wan
链接:https://neurips.cc/virtual/2023/poster/69972
代码:GitHub - Water2sea/WITRAN
关键词:RNN,长时预测
摘要:捕获语义信息对于长程时间序列的准确预测至关重要,其中包括两大方面:(1)建模全局和局部相关性,(2)挖掘长期和短期的重复模式。以往的研究工作能够一定程度上捕获这些方面中的一部分,但无法完成它们的同时捕获。此外,以往研究工作的时间和空间复杂性仍然很高。基于此,本文提出了一种新颖的水波信息传递(Water-wave Information Transmission,简称WIT)框架,能够通过双粒度的信息传递捕捉短期和长期的重复模式。在WIT框架中,设计了一种新型水平垂直门控选择单元(Horizontal Vertical Gated Selective Unit,简称HVGSU),通过循环地融合和选择信息,来建模全局和局部相关性。此外,在提高计算效率方面,提出了一种通用的循环加速网络(Recurrent Acceleration Network,简称RAN),能够在保证空间复杂度为O(L)的同时,将时间复杂度降低到为O(√L)。综上,将提出的方法命名为:水波信息传递和循环加速网络(Water-wave Information Transmission and Recurrent Acceleration Network,简称WITRAN)。通过在能源、交通、天气等领域的四个大型公开数据集上的实验证明,相对于现有方法,WITRAN在长程和超长程时间序列预测任务上成为了最佳方法(SOTA)。
相关链接:
NeurIPS 2023 时间序列(Time Series)论文总结

















 1525
1525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









