









本文主要介绍:从LM Studio安装到maxKB使用LM Studio发布的llama3中文大模型接口,实现客服助手。
llama3 硬件配置:
显卡:最低6GB GPU,最好支持CUDA的NVIDIA GPU
内存:llama3 8B 至少16GB,llama3 70B至少64GB
磁盘:llama3 8B 约4GB,llama3 70B 约20GB
其实配置比上面低或者没有显卡也没关系,就是回答问题慢,多等会儿。
1.LM Studio简介
LM Studio 是一款功能强大、易于使用的桌面应用程序,用于在本地机器上实验和评估大型语言模型(LLMs)。它允许用户轻松地比较不同的模型,并支持使用 NVIDIA/AMD GPU 加速计算。
2.LM Studio安装
2.1 下载
官网:https://lmstudio.ai/

根据实际运行环境选择对应版本,本文以windows为例。
2.2 配置hf-mirror.com
由于LM Studio会到huggingface.co下载相关模型,但其无法访问,所以需要把LM Studio中所有出现的huggingface.co改为hf-mirror.com。hf-mirror.com为huggingface.co国内镜像。
找到LM Studio安装路径:右键桌面快捷方式,在“目标”里面可以看到。
比如我这路径是“C:\Users\PC2023\AppData\Local\LM-Studio”。

用VSCode打开:

使用VSCode查找、替换:

重启LM Studio。
3.下载模型

下载过程可能会失败或者下载速度比较慢,没关系,多点几次“Try Resume”。某一次下载速度就快了,如下图。

4.对话
LM Studio实现基于特定模型对话。

5.发布接口
LM Studio可以发布类似open AI的接口,供外部调用。

启动后,在日志可以看到接口地址:

6.扩展
MaxKB调用LM Studio服务。由于LM Studio发布的接口跟openAI一样,所以在MaxKB配置时,选择openAI就行。具体配置,如下图所示:

MaxKB是个啥,见我的这个博客https://blog.csdn.net/taotao_guiwang/article/details/138190431。
MaxKB调用LM Studio日志如下:

7.其它问题
7.1 加载模型报错(v0.3.10)
机器配置:无GPU(显卡)
错误信息:Exit code: 18446744072635812000
解决方法,详见下图配置:
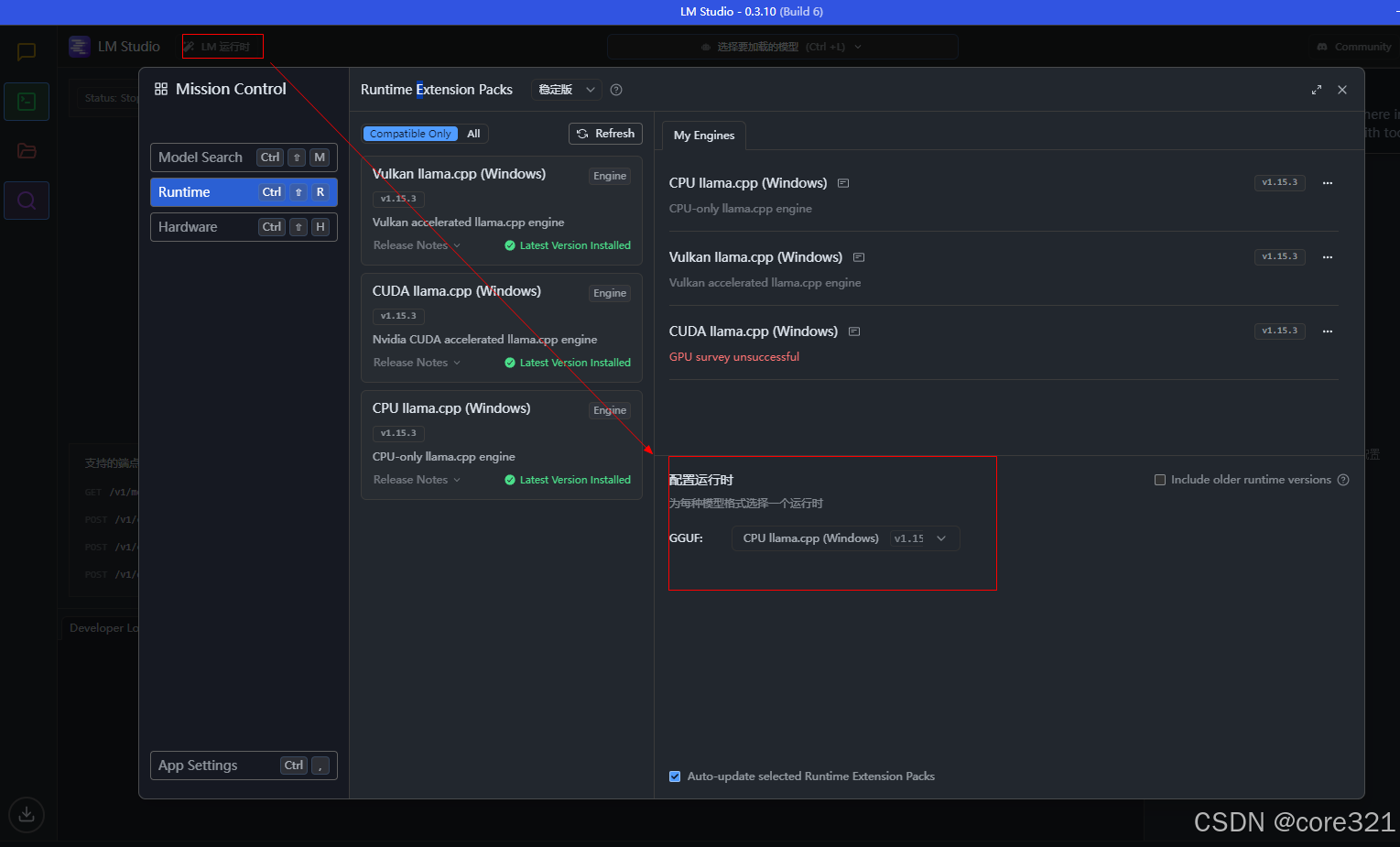
LM Studio一些常见错误,可以在这查找:https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues



















 7965
7965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











