







扩散模型作为新一代强大的图像生成模型,正受到广泛关注。要理解其核心机制,我们首先需要认识在图像处理领域具有重要影响的 U-Net。U-Net 最初用于图像分割,其独特的编码器-解码器结构和跳跃连接为包括扩散模型在内的众多生成模型提供了关键的架构基础。本文将深入介绍 U-Net 的结构、原理和应用,为后续理解扩散模型如何借鉴和发展 U-Net 的思想铺平道路。
文章目录
1 介绍
U-Net 是一种卷积神经网络架构,最初专为生物医学图像分割任务设计。该模型于 2015 年提出,凭借其高效性和出色的性能,已成为图像分割领域中的主流架构之一。
U-Net 之所以得名,是因为它具有对称的 U 形结构,整体由两部分组成:
- 编码路径(
Encoding Path):通过多层卷积和最大池化操作,对输入图像进行逐步下采样,提取图像的上下文信息,即“压缩”图像。 - 解码路径(
Decoding Path):通过上采样与卷积操作,将编码过程中的特征图还原为与原图大小一致的分割图,即“扩展”图像。
U-Net 的核心优势来自于它的跳跃连接(skip connections)——连接编码器和解码器中相同层级的特征图。这些连接将编码路径中保留的空间细节信息传递给解码路径,有效弥补了下采样过程中信息的损失,使模型在保持语义理解的同时也能精准还原图像细节,从而得到更准确的分割结果。
U-Net 的“跳跃连接”就像是搭了一座桥,把压缩过程中遗失的细节信息送回了解码器。原理是在每次下采样前(即 MaxPooling 前),我们将卷积后的特征图单独保留下来
在下采样(压缩)过程中,虽然我们得到了抽象的语义信息,比如“这是一辆车”,但很多细节特征(比如车轮的轮廓、边缘的位置)却丢失了。
如果没有这些跳跃连接,解码器只能依靠模糊的全局信息去“猜”图像结构,会造成还原模糊、分割不准。
而有了跳跃连接,每一层解码器在“还原图像”时,都能拿到与之对应的、细节丰富的编码器输出,帮助它更精确地恢复图像结构。
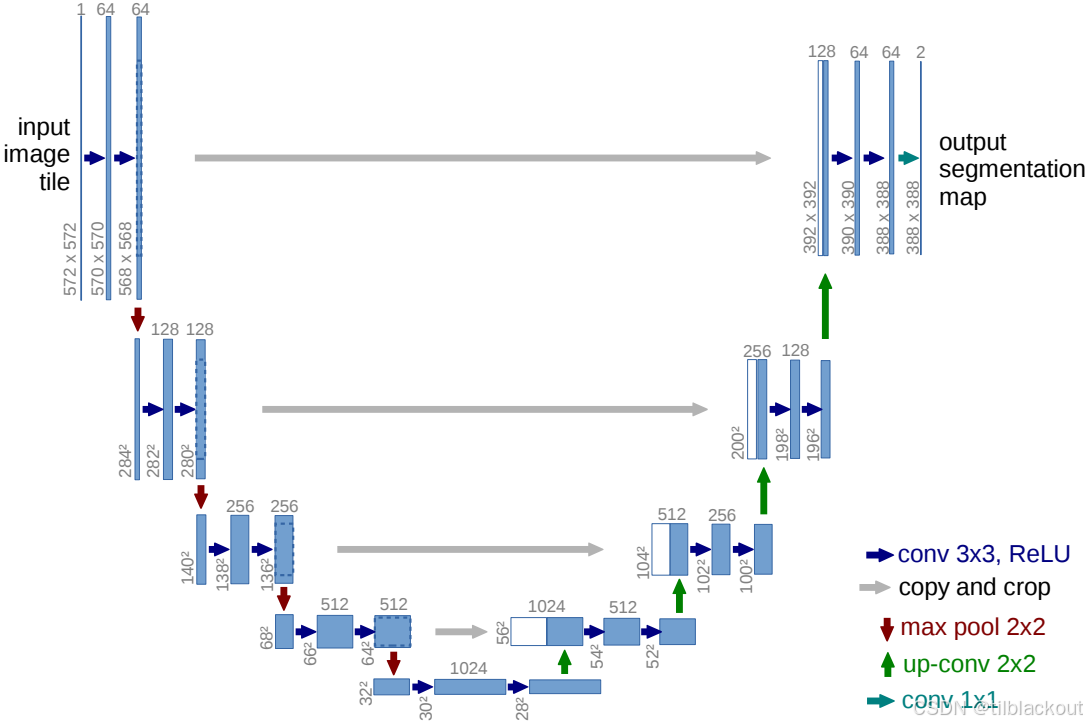
编码器部分(左半边)
从上往下看:
- 每一层会进行两次 3×3 的卷积(深蓝色箭头),激活函数为 ReLU;
- 然后使用 2×2 的最大池化(红色箭头),将图像尺寸缩小一半,同时通道数增加。
例如:
- 输入是
572×572,通道数为 1; - 第一层卷积后变成
568×568,通道数变为 64; - 然后经过池化变成
284×284,通道数为 128; - 一直这样下采样直到图像尺寸最小,通道最多(底部
1024通道)。
这部分提取了图像的全局语义信息。
解码器部分(右半边)
从下往上看:
- 每一层先通过 上采样(绿箭头,转置卷积) 将尺寸扩大一倍,通道数减半;
- 然后将它与编码器中同层的输出进行连接(灰色箭头);
- 最后再做两次卷积(深蓝色箭头)处理这个融合后的特征图。
例如:
- 一个
28×28的特征图被上采样成56×56; - 然后与编码器中
56×56、512通道的特征图进行拼接; - 拼接后再卷积生成新的特征图。
最终通过一个 1×1 的卷积(青色箭头) 输出分割图,每个像素属于哪个类别。
2 代码实现
现在我们通过代码来理解U-Net的实现原理,这里我们实现一个U-Net图像分割的例子。完整的代码在UNET Segmentation on Carvana Dataset。
2.1 背景
在传统二手车市场中,图片质量参差不齐、背景杂乱、车辆边缘不清晰,严重影响了线上购买体验。而 Carvana 这家在线二手车销售平台,致力于打造透明、自动化的购车流程。
为了提升照片专业度,Carvana 自主搭建了旋转摄影棚,每辆车都会被自动拍摄 16 张不同角度的照片。然而即便如此,仍存在以下问题:
- 明亮反光导致车辆边缘识别困难
- 车身颜色与背景相近时,分割容易出错
- 需耗费大量人力进行人工抠图处理
因此,这个数据集和比赛的核心任务就是:实现高质量的车辆前景提取(语义分割),以便实现后续背景替换和商品展示自动化。

2.2 数据结构定义
2.2.1 Double Convolution(双卷积)
在U-Net结构中,每一个编码或解码模块的核心操作是重复的双卷积(图中蓝色箭头)。具体而言,它包含两个 3 × 3 3 \times 3 3×3的卷积操作,每个卷积后接一个ReLU激活函数。对应的代码如下:
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv_op = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_op(x)
2.2.2 Downsampling(下采样)
下采样部分是U-Net左侧的编码路径(图中红色箭头),每个步骤由双卷积和一次最大池化组成。在进行最大池化之前,我们会保留卷积之后的特征图,用于后续的跳跃连接。对应的代码如下:
class DownSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = DoubleConv(in_channels, out_channels)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
down = self.conv(x)
p = self.pool(down)
return down, p
注意,这里返回两个变量:down 表示卷积后的特征图,p 是池化后的特征图。down 会被保存下来,后续在解码阶段与上采样结果进行拼接。
2.2.3 Upsampling(上采样)
上采样部分位于U-Net右侧的解码路径(图中绿色箭头)。它包括一次反卷积操作(也叫转置卷积)以及一次双卷积。在每一次上采样之前,都会将上采样结果与编码路径中对应的特征图进行拼接(图中灰色箭头表示“复制与裁剪”)。对应的代码如下:
class UpSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x1, x2], 1)
return self.conv(x)
在这里,我们传入两个张量 x 1 x_1 x1和 x 2 x_2 x2。 x 1 x_1 x1 是来自上一层的上采样结果, x 2 x_2 x2 是跳跃连接中保存的特征图。二者在通道维度上拼接,然后送入双卷积中进行融合。
相比之下,DownSample 只接收一个输入张量,是因为跳跃连接操作仅应用于解码路径,而不是编码路径。
2.2.4 UNet架构整合
我们现在将之前定义的所有模块整合成完整的 U-Net 架构:
class UNet(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.down_convolution_1 = DownSample(in_channels, 64)
self.down_convolution_2 = DownSample(64, 128)
self.down_convolution_3 = DownSample(128, 256)
self.down_convolution_4 = DownSample(256, 512)
self.bottle_neck = DoubleConv(512, 1024)
self.up_convolution_1 = UpSample(1024, 512)
self.up_convolution_2 = UpSample(512, 256)
self.up_convolution_3 = UpSample(256, 128)
self.up_convolution_4 = UpSample(128, 64)
self.out = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=1)
def forward(self, x):
down_1, p1 = self.down_convolution_1(x)
down_2, p2 = self.down_convolution_2(p1)
down_3, p3 = self.down_convolution_3(p2)
down_4, p4 = self.down_convolution_4(p3)
b = self.bottle_neck(p4)
up_1 = self.up_convolution_1(b, down_4)
up_2 = self.up_convolution_2(up_1, down_3)
up_3 = self.up_convolution_3(up_2, down_2)
up_4 = self.up_convolution_4(up_3, down_1)
out = self.out(up_4)
return out
这个类就是完整的 U-Net 模型,它包括:
- 四层下采样模块(编码路径),每层使用双卷积 + 最大池化
- 一个 bottleneck(瓶颈)层,用于桥接编码器和解码器
- 四层上采样模块(解码路径),每层包括反卷积 + 拼接 + 双卷积
- 一个 1 × 1 1 \times 1 1×1 卷积,用于将特征图转换为指定的类别数
跳跃连接的实现是通过 down_1 到 down_4 的保存,并在解码时拼接回来,从而增强局部特征。
前向传播过程说明
输入 x x x 依次通过编码路径获取下采样的特征图,并保存中间的卷积结果作为跳跃连接:
-
x
→
x \rightarrow
x→
down_convolution_1→ \rightarrow → 得到down_1,p1 p1→ \rightarrow →down_convolution_2→ \rightarrow → 得到down_2,p2p2→ \rightarrow →down_convolution_3→ \rightarrow → 得到down_3,p3p3→ \rightarrow →down_convolution_4→ \rightarrow → 得到down_4,p4p4→ \rightarrow →bottle_neck
之后依次进行上采样,并与对应的 down_i 结果拼接:
b和down_4拼接 → \rightarrow →up_convolution_1up_1和down_3拼接 → \rightarrow →up_convolution_2up_2和down_2拼接 → \rightarrow →up_convolution_3up_3和down_1拼接 → \rightarrow →up_convolution_4
最终通过 1 × 1 1 \times 1 1×1 卷积生成每个像素的分类结果。
2.2.5 模型测试
我们可以使用一个随机的测试张量验证这个模型结构是否正确:
input_image = torch.rand((1, 3, 512, 512))
model = UNet(3, 10)
output = model(input_image)
print(output.size())
# 输出应为 torch.Size([1, 10, 512, 512])
我们传入的是形状为 [ 1 , 3 , 512 , 512 ] [1, 3, 512, 512] [1,3,512,512] 的输入图像,模型输出的应该是 [ 1 , 10 , 512 , 512 ] [1, 10, 512, 512] [1,10,512,512],表示每个像素在 10 个类别上的预测值。
U-Net 架构中每一次上采样后的结果都与下采样路径中对应尺寸的特征图进行拼接(concatenation),这样能更好地保留图像的空间结构信息,从而获得更准确的分割结果。
现在我们已经构建好了完整的 U-Net 架构,并验证了其输入输出维度一致,接下来可以进行训练了!
2.3 数据集预处理
我们首先定义一个 Dataset 类来加载 Carvana数据集 图像与掩码数据,并进行预处理(例如调整尺寸与归一化)。我们的数据集中,有5088张车的图像和掩码,分别在train和train_masks目录下。
- 对于
train_masks中的内容来说,掩码是每个像素的类别标签,在这里是二值掩码(车=1,背景=0)。
# 引入 PyTorch 数据集基类
class CarvanaDataset(Dataset):
def __init__(self, root_path, limit=None):
self.root_path = root_path # 数据集的根路径
self.limit = limit # 可选参数,限制加载样本数量
# 加载图像路径列表,并按文件名排序;[:self.limit]表示取前limit个元素,限制样本数量
self.images = sorted([
root_path + "/train/" + i for i in os.listdir(root_path + "/train/")
])[:self.limit]
# 加载对应的掩码路径(ground truth),与图像一一对应;同样进行排序与限制
self.masks = sorted([
root_path + "/train_masks/" + i for i in os.listdir(root_path + "/train_masks/")
])[:self.limit]
# 定义图像与掩码的预处理操作:
# - Resize:统一调整为 512x512
# - ToTensor:转换为 PyTorch Tensor,并将像素值归一化到[0,1]
self.transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()
])
# 如果没有指定 limit,默认使用所有图像
if self.limit is None:
self.limit = len(self.images)
def __getitem__(self, index):
# 根据索引读取对应的原始图像,并转为 RGB(三通道)
img = Image.open(self.images[index]).convert("RGB")
# 读取对应的掩码图像,并转为 L(灰度图,一通道)
mask = Image.open(self.masks[index]).convert("L")
# 返回三项内容:
# - 图像(Tensor)
# - 掩码(Tensor)
# - 图像路径(可用于 debug 或可视化)
return self.transform(img), self.transform(mask), self.images[index]
def __len__(self):
# 返回数据集的长度:取 images 长度和 limit 中的最小值(防止越界)
return min(len(self.images), self.limit)
接下来构造训练、验证、测试集:
WORKING_DIR = '/working/'
train_dataset = CarvanaDataset(WORKING_DIR)
# 创建一个随机数生成器,并设定一个固定的种子值
generator = torch.Generator().manual_seed(25)
from torch.utils.data import random_split
dataset_len = len(train_dataset) # 原始是5088
train_len = int(0.8 * dataset_len) # 4060
temp_len = dataset_len - train_len # 1028
# 第一步:80%训练 + 20%临时数据
train_dataset, temp_dataset = random_split(train_dataset, [train_len, temp_len], generator=generator)
# 第二步:把临时数据再分成50%验证 + 50%测试
val_len = test_len = temp_len // 2 # 各 514,如果是奇数,可以调整
val_dataset, test_dataset = random_split(temp_dataset, [val_len, test_len], generator=generator)
训练超参数与 DataLoader 构建:
考虑到数据集的大小,我们将批量大小(batch size)设置为 8,以防止 GPU 内存溢出。此外,我们将 pin_memory 参数设为 False,以避免潜在的内存问题。虽然将 pin_memory 设为 True 可以加快数据传输至 GPU 的速度,但也可能导致内存分配方面的问题。
LEARNING_RATE = 3e-4
BATCH_SIZE = 8
num_workers = 4 # 建议有GPU的设置为4
train_dataloader = DataLoader(
dataset=train_dataset, # 你的训练数据集对象
num_workers=num_workers, # 使用的 CPU 线程数,提升数据加载速度
pin_memory=False, # 是否使用“页锁定内存”,加快从 CPU 到 GPU 的拷贝速度
batch_size=BATCH_SIZE, # 每个 mini-batch 的样本数量
shuffle=True # 每个 epoch 是否打乱数据顺序(训练集通常设置为 True)
)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers, pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
test_dataloader = DataLoader(dataset=test_dataset,
num_workers=num_workers, pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
构建模型与优化器:
model = UNet(in_channels=3, num_classes=1).to(device)
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
由于输入的是RGB图像,所以in_channels=3。此处我们构建了一个 U-Net 二分类模型,由于任务是将图像中的车辆与背景进行分割,因此设置 num_classes=1。使用 AdamW 优化器和 BCEWithLogitsLoss 作为损失函数,适用于二值分割任务。
2.4 训练模型
以下是完整的训练循环代码,同时包括训练集与验证集的 loss 和 DICE 系数计算,并保存最终模型。
2.4.1 Dice系数
在图像分割中评估模型性能时,使用可靠的度量指标至关重要。DICE 系数是广泛使用的指标之一。DICE 用于衡量两个集合之间的相似性。在图像分割中,这两个集合分别是模型预测的分割结果与真实分割标签(ground truth)。它计算两者的重叠程度,同时考虑假阳性和假阴性。
数学上,DICE 得分定义为:
D
I
C
E
=
2
⋅
∣
A
∩
B
∣
∣
A
∣
+
∣
B
∣
DICE = \frac{2 \cdot |A \cap B|}{|A| + |B|}
DICE=∣A∣+∣B∣2⋅∣A∩B∣
可以理解为:
D
I
C
E
=
2
×
共同元素数量
集合A元素数
+
集合B元素数
DICE = 2 \times \frac{\text{共同元素数量}}{\text{集合A元素数} + \text{集合B元素数}}
DICE=2×集合A元素数+集合B元素数共同元素数量
DICE 的取值范围为
0
0
0 到
1
1
1:
- 越接近 1 1 1,表示预测与真实分割越一致。
- DICE = 1 表示完全重叠,DICE = 0 表示没有重叠。
图示中, A A A 和 B B B 分别代表预测掩码和参考掩码, A ∩ B A \cap B A∩B 表示两者的交集。
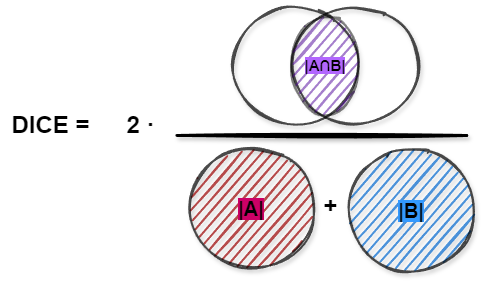
实际应用
在分割任务中,我们比较两个矩阵:
- 矩阵 A A A:表示预测掩码,只有一个通道,元素值为 0 0 0 或 1 1 1。
- 矩阵
B
B
B:表示真实掩码(
reference mask),元素值也为 0 0 0 或 1 1 1。
将矩阵 A A A 和 B B B 做逐元素乘法(用 ∗ * ∗ 运算符),只有当 A [ i , j ] = 1 A[i,j] = 1 A[i,j]=1 且 B [ i , j ] = 1 B[i,j] = 1 B[i,j]=1 时,结果矩阵 C [ i , j ] = 1 C[i,j] = 1 C[i,j]=1,其余为 0 0 0。这就得到了两者的交集大小。
- 注意:这里的 ∗ * ∗ 是 Python 中的逐元素乘法,不是标准矩阵乘法。
实践案例说明
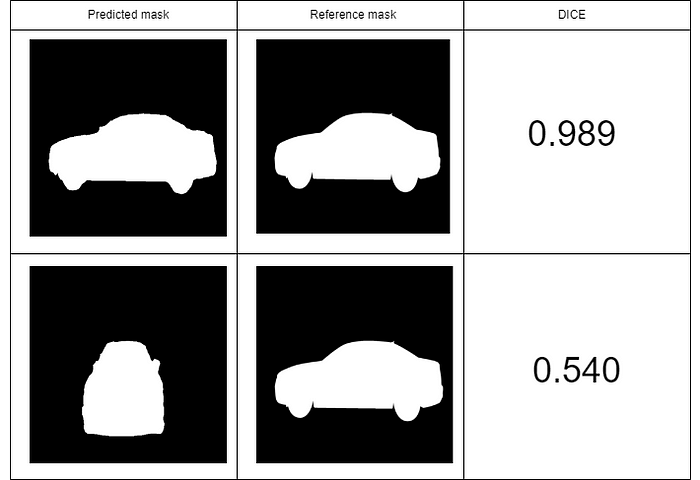
- 第一组图像中,预测掩码与参考掩码高度一致,DICE 得分为 0.989 0.989 0.989。
- 第二组图像中,预测结果与真实掩码差异较大,DICE 下降为 0.540 0.540 0.540。
这说明 DICE 得分能够有效反映预测与真实标签之间的重叠程度。基于这些原理,我们定义以下函数:
# 定义 DICE 系数评估函数,用于评估预测与真实掩码的重叠程度(常用于分割任务)
def dice_coefficient(prediction, target, epsilon=1e-07):
prediction_copy = prediction.clone() # 克隆一份预测结果,防止原始张量被修改
# 将预测值进行二值化(阈值0)处理为 0 或 1,用于计算 IOU/重叠面积
prediction_copy[prediction_copy < 0] = 0
prediction_copy[prediction_copy > 0] = 1
# 计算交集和并集
intersection = abs(torch.sum(prediction_copy * target))
union = abs(torch.sum(prediction_copy) + torch.sum(target))
# 计算 DICE 系数(加 epsilon 防止除以 0)
dice = (2. * intersection + epsilon) / (union + epsilon)
return dice
2.4.2 模型训练
当使用 PyTorch 配合 CUDA 进行 GPU 加速训练时,一个常见的做法是调用 torch.cuda.empty_cache()。这个函数的作用是释放 CUDA 上所有未使用的缓存显存,有助于清理那些可能导致训练过程中显存溢出的内存资源。
# 清空 GPU 缓存,释放显存
torch.cuda.empty_cache()
接下来训练模型:
# 设置训练轮数
EPOCHS = 10
# 记录每轮的训练和验证指标
train_losses = []
train_dcs = []
val_losses = []
val_dcs = []
# 开始训练
for epoch in tqdm(range(EPOCHS)):
model.train() # 设置为训练模式
train_running_loss = 0
train_running_dc = 0
# 遍历训练数据集
for idx, img_mask in enumerate(tqdm(train_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device) # 图像数据转 float 并搬到 GPU
mask = img_mask[1].float().to(device) # 掩码也一样处理
y_pred = model(img) # 前向传播得到预测结果
optimizer.zero_grad() # 梯度清零
dc = dice_coefficient(y_pred, mask) # 计算 DICE
loss = criterion(y_pred, mask) # 计算 BCEWithLogitsLoss
train_running_loss += loss.item() # 累计损失
train_running_dc += dc.item() # 累计 DICE
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 平均每轮的训练损失与 DICE
train_loss = train_running_loss / (idx + 1)
train_dc = train_running_dc / (idx + 1)
# 保存指标
train_losses.append(train_loss)
train_dcs.append(train_dc)
# 进入验证模式
model.eval()
val_running_loss = 0
val_running_dc = 0
# 不进行梯度计算(节省内存,加快速度)
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(val_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
loss = criterion(y_pred, mask)
dc = dice_coefficient(y_pred, mask)
val_running_loss += loss.item()
val_running_dc += dc.item()
# 验证集平均 loss 与 DICE
val_loss = val_running_loss / (idx + 1)
val_dc = val_running_dc / (idx + 1)
# 保存验证结果
val_losses.append(val_loss)
val_dcs.append(val_dc)
# 打印训练与验证信息
print("-" * 30)
print(f"Training Loss EPOCH {epoch + 1}: {train_loss:.4f}")
print(f"Training DICE EPOCH {epoch + 1}: {train_dc:.4f}")
print("\n")
print(f"Validation Loss EPOCH {epoch + 1}: {val_loss:.4f}")
print(f"Validation DICE EPOCH {epoch + 1}: {val_dc:.4f}")
print("-" * 30)
# 保存模型权重
torch.save(model.state_dict(), 'my_checkpoint.pth')
2.5 结果
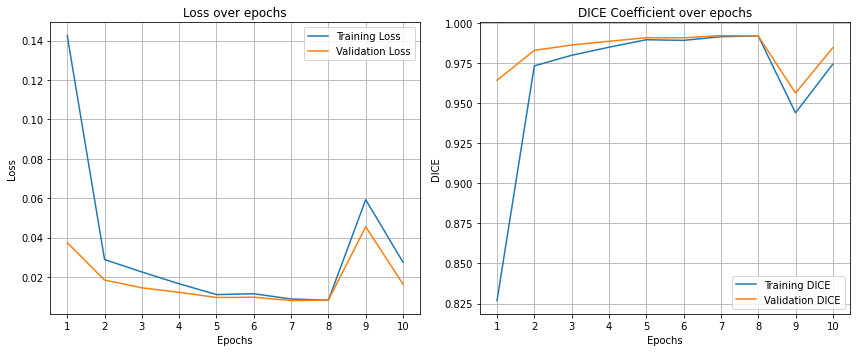
2.5.1 训练可视化
为了可视化模型在训练过程中的表现,我们绘制:训练集与验证集的损失变化趋势和训练集与验证集的 DICE 系数变化趋势。通过这些图,可以直观观察模型是否收敛、是否过拟合,以及训练效果是否稳步提升。
epochs_list = list(range(1, EPOCHS + 1))
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs_list, train_losses, label='Training Loss')
plt.plot(epochs_list, val_losses, label='Validation Loss')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.title('Loss over epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid()
plt.tight_layout()
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs_list, train_dcs, label='Training DICE')
plt.plot(epochs_list, val_dcs, label='Validation DICE')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.title('DICE Coefficient over epochs')
plt.xlabel('Epochs')
plt.ylabel('DICE')
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()
结果输出如下:
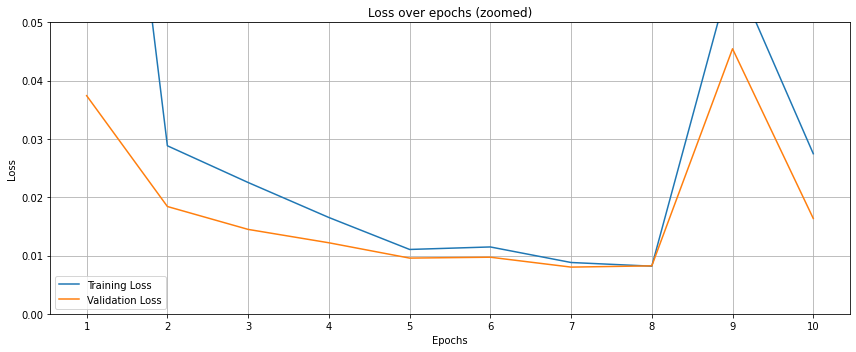
现在对前面训练过程的损失函数变化趋势图进行“放大观察”,更清晰地看到 loss 在低数值区域的细微变化。
epochs_list = list(range(1, EPOCHS + 1))
plt.figure(figsize=(12, 5))
plt.plot(epochs_list, train_losses, label='Training Loss')
plt.plot(epochs_list, val_losses, label='Validation Loss')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.ylim(0, 0.05) # y 轴范围限制在 $[0, 0.05]$,方便查看 loss 收敛的细节
plt.title('Loss over epochs (zoomed)')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid()
plt.tight_layout()
plt.legend()
plt.show()
结果如下:
2.5.2 模型评估
接下来我们加载已训练模型并在测试集上评估 Loss 和 DICE 系数,然后从测试集中随机选取图像进行推理,并可视化原图、真实掩码与预测结果
加载模型并评估测试集性能
model_pth = '/working/my_checkpoint.pth'
trained_model = UNet(in_channels=3, num_classes=1).to(device)
trained_model.load_state_dict(torch.load(model_pth, map_location=torch.device(device)))
- 加载保存的模型参数
my_checkpoint.pth - 初始化一个新的
UNet模型并加载这些参数 - 使用
map_location保证能在当前设备(CPU 或 GPU)上运行
接下来看一下测试集的评估结果:
test_running_loss = 0
test_running_dc = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(test_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = trained_model(img)
loss = criterion(y_pred, mask)
dc = dice_coefficient(y_pred, mask)
test_running_loss += loss.item()
test_running_dc += dc.item()
test_loss = test_running_loss / (idx + 1)
test_dc = test_running_dc / (idx + 1)
- 使用
no_grad()关闭梯度计算,提升推理速度、减少显存占用 - 遍历整个测试集,累计 loss 和 DICE 值
- 最后除以批次数,得到平均损失与平均 DICE 系数
输出结果:
test_loss # 0.016588360478635877
test_dc # 0.9845270849764347
表示模型在测试集上表现良好,分割精度高。
2.5.3 随机选择图片推理
def random_images_inference(image_tensors, mask_tensors, image_paths, model_pth, device):
# 初始化 UNet 模型,并加载训练好的权重
model = UNet(in_channels=3, num_classes=1).to(device)
model.load_state_dict(torch.load(model_pth, map_location=torch.device(device)))
# 定义图像变换操作,这里仅调整图像大小为 512x512
transform = transforms.Compose([
transforms.Resize((512, 512))
])
# 遍历图像张量、掩码张量和图像路径(用于打印文件名)
for image_pth, mask_pth, image_paths in zip(image_tensors, mask_tensors, image_paths):
# 加载并预处理图像(调整大小)
img = transform(image_pth)
# 使用模型对图像进行预测,输出的是掩码(mask)
pred_mask = model(img.unsqueeze(0)) # 增加 batch 维度 [1, C, H, W]
pred_mask = pred_mask.squeeze(0).permute(1,2,0) # 去除 batch 维度并调换通道顺序为 [H, W, C]
# 加载并预处理真实掩码(用于计算 DICE 相似度)
mask = transform(mask_pth).permute(1, 2, 0).to(device) # 转为 [H, W, C] 并放入 device 上
# 计算 DICE 系数,并打印图像文件名与分数
print(f"Image: {os.path.basename(image_paths)}, DICE coefficient: {round(float(dice_coefficient(pred_mask, mask)),5)}")
# 准备图像和预测结果用于显示
img = img.cpu().detach().permute(1, 2, 0) # 转为 [H, W, C] 并移至 CPU
pred_mask = pred_mask.cpu().detach() # 预测掩码移至 CPU,准备处理
# 二值化预测结果(阈值为 0)
pred_mask[pred_mask < 0] = 0
pred_mask[pred_mask > 0] = 1
# 可视化:原图、预测掩码、真实掩码
plt.figure(figsize=(15, 16))
plt.subplot(131), plt.imshow(img), plt.title("original") # 原图
plt.subplot(132), plt.imshow(pred_mask, cmap="gray"), plt.title("predicted") # 预测掩码
plt.subplot(133), plt.imshow(mask, cmap="gray"), plt.title("mask") # 真实掩码
plt.show()
现在我们从test_dataloader中随机选取10张图像进行测试:
n = 10 # 随机选取 10 张图像
image_tensors = []
mask_tensors = []
image_paths = []
for _ in range(n):
random_index = random.randint(0, len(test_dataloader.dataset) - 1)
random_sample = test_dataloader.dataset[random_index]
image_tensors.append(random_sample[0])
mask_tensors.append(random_sample[1])
image_paths.append(random_sample[2])
调用前面定义的函数,输出图像预测效果与每张图的 DICE 分数
model_path = '/kaggle/working/my_checkpoint.pth'
random_images_inference(image_tensors, mask_tensors, image_paths, model_path, device="cpu")
输出如下:

3 总结
通过本文的实践,我们不仅深入理解了 U-Net 这一经典架构在图像分割中的核心设计思想与具体实现,更亲手完成了一个端到端的图像分割任务。然而,U-Net 的能力并不止于此。在许多前沿生成模型中,尤其是近两年大热的**扩散模型(Diffusion Models)**中,U-Net 作为核心结构再次大放异彩。
扩散模型本质上是一种逐步去噪、还原图像的生成方法,它的“解码器”阶段往往正是基于 U-Net 实现的。不同的是,这一次 U-Net 不再是用于图像“分割”,而是扮演了从纯噪声中生成高质量图像的关键角色。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











