










saver.save简单例子
https://blog.csdn.net/weixin_30788619/article/details/99875143
#保存变量
import tensorflow as tf
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
# 创建两个变量
v1= tf.Variable(tf.random_normal([5, 2], stddev=0.35), name="v_1")
v2= tf.Variable(tf.zeros([2]), name="v_2")
# 添加用于初始化变量的节点
init_op = tf.global_variables_initializer()
basicpath="./"
**# Create a saver, 只存变量?用 tf.train.Saver()就好了
**saver = tf.train.Saver(tf.global_variables())****
# 运行,保存变量
with tf.Session() as sess:
tf.global_variables_initializer().run()
for step in range(2):
sess.run(init_op)
# if step % 1000 == 0:
**saver.save(sess,basicpath+'my-model', global_step=step)**
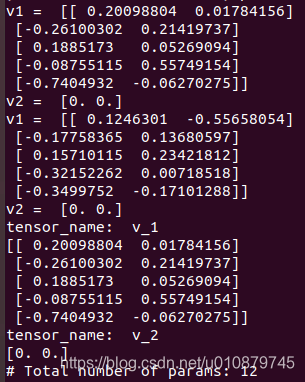
print("v1 = ", v1.eval())
print("v2 = ", v2.eval())
**print_tensors_in_checkpoint_file(basicpath+"my-model-0", None, True)**
#print_tensors_in_checkpoint_file(file_name, #ckpt文件名字
#tensor_name, # 如果为None,则默认为ckpt里的所有变量
#all_tensors, # bool 是否打印所有的tensor,打印出的是tensor的值,一般不推荐,这里设置为False
亦可以使用第二种方法打印变量:
#使用NewCheckpointReader来读取ckpt里的变量
from tensorflow.python import pywrap_tensorflow
checkpoint_path = os.path.join(model_dir, "model.ckpt")
reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path) #tf.train.NewCheckpointReader
var_to_shape_map = reader.get_variable_to_shape_map()
for key in var_to_shape_map:
print("tensor_name: ", key)
#print(reader.get_tensor(key))
看到了三个有用的命令:
**# Create a saver, 只存变量?用 tf.train.Saver()就好了
saver = tf.train.Saver(tf.global_variables())
saver.save(sess,basicpath+‘my-model’, global_step=step)
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
print_tensors_in_checkpoint_file(basicpath+“my-model-0”, None, True)
reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path) #tf.train.NewCheckpointReader
var_to_shape_map = reader.get_variable_to_shape_map()
saver.restore简单例子
import tensorflow as tf
v1= tf.Variable(tf.random_normal([5, 2], stddev=0.35), name="v_1")
v2= tf.Variable(tf.zeros([2]), name="v_2")
saver = tf.train.Saver()
with tf.Session() as sess:
#tf.global_variables_initializer().run()
module_file = tf.train.latest_checkpoint('./')
**saver.restore(sess, module_file)**
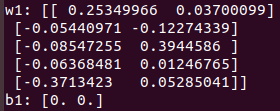
print("w1:", sess.run(v1))
print("b1:", sess.run(v2))
以上要点:
需要保存的变量应在 之前
恢复变量虽不需要初始化,但需要有初始化语句
要定义global_step变量,在训练完一个批次或者一个样本之后,要将其进行加1的操作
一个有用的语句
saver.restore(sess, module_file)
saver.save和saver.restore定义
saver定义:
https://blog.csdn.net/fly_time2012/article/details/82889418
save定义
https://blog.csdn.net/jeryjeryjery/article/details/79880475
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix=‘meta’,
write_meta_graph=True,
write_state=True,
strip_default_attrs=False)
保存变量。
这个方法用来保存变量,它需要一个session参数来指明哪个图。保存的参数必须已经被初始化过了。
args:
sess:保存变量需要的session
save_path:checkpoint文件保存的路径。
global_step:如果指定了,则会将这个数字添加到save_path后面,用于唯一标识checkpoint文件。
latest_filename:和save_path在同一个文件夹中,用于最后一个checkpoint文件的命名。默认为checkpoint。
其他不常用。
restore(
sess,
save_path)
从save_path中恢复模型的参数。
它需要一个session,需要恢复的参数不需要初始化,因为恢复本身就是一种初始化变量的方法。而参数save_path
就是save()函数产生的文件的路径名。
args:
sess:一个session
save_path:保存的路径
只恢复第一个
import tensorflow as tf
v1= tf.Variable(tf.random_normal([5, 2], stddev=0.35), name="v_1")
v2= tf.Variable(tf.zeros([2]), name="v_2")
saver = tf.train.Saver()
# with tf.Session() as sess:
# #tf.global_variables_initializer().run()
# module_file = tf.train.latest_checkpoint('./')
# saver.restore(sess, module_file)
# print("w1:", sess.run(v1))
# print("b1:", sess.run(v2))
with tf.Session() as sess2:
sess2.run(tf.global_variables_initializer())
# saver.restore(sess2, savedir + "linear.cpkt-" + str(load_epoch))
# print(sess2.run([w, b], feed_dict={X: train_x, Y: train_y}))
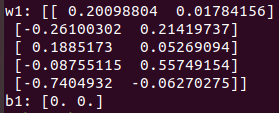
saver.restore(sess2, "my-model-0")
print("w1:", sess2.run(v1))
print("b1:", sess2.run(v2))
使用tools里的freeze_graph来读取ckpt
from tensorflow.python.tools import freeze_graph
freeze_graph(input_graph, #=some_graph_def.pb
input_saver,
input_binary,
input_checkpoint, #=model.ckpt
output_node_names, #=softmax
restore_op_name,
filename_tensor_name,
output_graph, #=’./tmp/frozen_graph.pb’
clear_devices,
initializer_nodes,
variable_names_whitelist=’’,
variable_names_blacklist=’’,
input_meta_graph=None,
input_saved_model_dir=None,
saved_model_tags=‘serve’,
checkpoint_version=2)
#freeze_graph_test.py讲述了怎么使用freeze_grapg。
使用freeze_graph可以将图和ckpt进行合并。
导入模型构造网络图和加载参数
tensorflow将图和变量数据分开保存为不同的文件。因此,在导入模型时,也要分为2步:构造网络图和加载参数
构造网络图:
saver=tf.train.import_meta_graph(’./checkpoint_dir/MyModel-1000.meta’)
def import_graph_def(graph_def, input_map=None, return_elements=None, name=None, op_dict=None, producer_op_list=None):
该函数可加载已存储的"graph_def"到当前默认图里,并从系列化的tensorflow [GraphDef]协议缓冲里提取所有的tf.Tensor和tf.Operation到当前图里,其参数如下:
graph_def:一个包含图操作OP且要导入GraphDef的默认图;
input_map:字典关键字映射,用以从已保存图里恢复出对应的张量值;
return_elements:从已保存模型恢复的Ops或Tensor对象;
return:从已保存模型恢复后的Ops和Tensorflow列表,其名字位于return_elements;
import tensorflow as tf
with tf.Session() as sess:
saver = tf.train.import_meta_graph(’./checkpoint_dir/MyModel-1000.meta’)
saver.restore(sess,tf.train.latest_checkpoint(’./checkpoint_dir’))
print(sess.run(‘w1:0’))
##Model has been restored. Above statement will print the saved value
下面博客莫名其妙搞得很复杂,不理解
https://blog.csdn.net/fly_time2012/article/details/82889418
图存储方法:
v = tf.Variable(0, name=‘my_variable’)
sess = tf.Session()
#tf.train.write_graph(sess.graph, ‘/tmp/my-model’, ‘train.pbtxt’) --> that is ok
tf.train.write_graph(sess.graph_def, ‘/tmp/my-model’, ‘train.pbtxt’)
图加载方法:
使用例子如下:
with tf.Session() as _sess:
with gfile.FastGFile("/tmp/tfmodel/train.pbtxt",‘rb’) as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_sess.graph.as_default()
tf.import_graph_def(graph_def, name=‘tfgraph’)
从graph恢复模型计算中间值
https://blog.csdn.net/loveliuzz/article/details/81661875?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
我们可能需要获取训练好的模型中的一些中间结果值,可以通过graph.get_tensor_by_name(‘w1:0’)来获取,注意w1:0是tensor的name。
假设我们有一个简单的网络模型,代码如下:
import tensorflow as tf
w1 = tf.placeholder(“float”, name=“w1”)
w2 = tf.placeholder(“float”, name=“w2”)
b1= tf.Variable(2.0,name=“bias”)
#定义一个op,用于后面恢复
w3 = tf.add(w1,w2)
w4 = tf.multiply(w3,b1,name=“op_to_restore”)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#创建一个Saver对象,用于保存所有变量
saver = tf.train.Saver()
#通过传入数据,执行op
print(sess.run(w4,feed_dict ={w1:4,w2:8}))
#打印 24.0 ==>(w1+w2)*b1
#现在保存模型
saver.save(sess, ‘./checkpoint_dir/MyModel’,global_step=1000)
接下来我们使用graph.get_tensor_by_name()方法来操纵这个保存的模型。
import tensorflow as tf
sess=tf.Session()
#先加载图和参数变量
saver = tf.train.import_meta_graph(’./checkpoint_dir/MyModel-1000.meta’)
saver.restore(sess, tf.train.latest_checkpoint(’./checkpoint_dir’))
访问placeholders变量,并且创建feed-dict来作为placeholders的新值
graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name(“w1:0”)
w2 = graph.get_tensor_by_name(“w2:0”)
feed_dict ={w1:13.0,w2:17.0}
#接下来,访问你想要执行的op
op_to_restore = graph.get_tensor_by_name(“op_to_restore:0”)
print(sess.run(op_to_restore,feed_dict))
#打印结果为60.0==>(13+17)*2
saver保存和恢复部分变量
vgg_ref_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=‘vgg_feat_fc’)#获取指定scope的tensor
saver = tf.train.Saver(vgg_ref_vars)#初始化saver时,传入一个var_list的参数
新图引入老图变量
vgg_graph_weight = params[‘vgg_graph_weight’] # 后缀是’.ckpt’的文件,里面是各个tensor的值
saver_vgg = tf.train.import_meta_graph(vgg_meta_path) # 导入graph到当前的默认graph中,返回导入graph的saver
x_vgg_feat = tf.get_collection(‘inputs_vgg’)[0] #placeholder, [None, 4096],获取输入的placeholder
feat_decode = tf.get_collection(‘feat_encode’)[0] #[None, 1024],获取要使用的tensor
“”"
以上两个获取tensor的方式也可以为:
graph = tf.get_default_graph()
centers = graph.get_tensor_by_name(‘loss/intra/center_loss/centers:0’)
当然,前提是有tensor的名字
“”"
…
init = tf.global_variables_initializer()
saver = tf.train.Saver() # 这个是当前新图的saver
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:
sess.run(init)
…
saver_vgg.restore(sess, vgg_graph_weight)#使用导入图的saver来恢复
builder/loader方法
https://blog.csdn.net/fly_time2012/article/details/82889418
sess = tf.InteractiveSession()
tf.summary.scalar(‘accuracy’, accuracy)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.log_dir + ‘/train’, sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + ‘/test’)
tf.global_variables_initializer().run()
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print(‘Accuracy at step %s: %s’ % (i, acc))
train_writer.add_run_metadata(run_metadata, ‘step%03d’ % i)
train_writer.add_summary(summary, i)
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
builder = tf.saved_model.builder.SavedModelBuilder("/home/xsr-ai/study/mnist/saved-model")
builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.TRAINING])
builder.save()
train_writer.close()
test_writer.close()
进入到SavedModelBuilder指定的路径“/home/xsr-ai/study/mnist/saved-model”,发现生成了如下东西:
一个pb文件,以及一个variables文件夹,里面存放的是variables.data-00000-of-00001和
variables.index,与save/restore方法比,没有checkpoint检查点文件以及以“.meta”为后缀的元数据文件,但是多了一个pb文件,这是这两种tensorflow保存和恢复模型方法的区别。
恢复模型方法load
import tensorflow as tf
with tf.Session() as sess:
tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.TRAINING], “/home/xsr-ai/study/mnist/saved-model”)
var = sess.run(‘layer2/biases/Variable:0’)
print(var)
##saved_model.builder.SavedModelBuilder
https://blog.csdn.net/thriving_fcl/article/details/75213361
最简单的场景,只是保存/载入模型
###保存
要保存一个已经训练好的模型,使用下面三行代码就可以了。
builder = tf.saved_model.builder.SavedModelBuilder(saved_model_dir)
builder.add_meta_graph_and_variables(sess, ['tag_string'])
builder.save()
首先构造SavedModelBuilder对象,初始化方法只需要传入用于保存模型的目录名,目录不用预先创建。
add_meta_graph_and_variables方法导入graph的信息以及变量,这个方法假设变量都已经初始化好了,对于每个SavedModelBuilder这个方法一定要执行一次用于导入第一个meta graph。
第一个参数传入当前的session,包含了graph的结构与所有变量。
第二个参数是给当前需要保存的meta graph一个标签,标签名可以自定义,在之后载入模型的时候,需要根据这个标签名去查找对应的MetaGraphDef,找不到就会报如RuntimeError: MetaGraphDef associated with tags ‘foo’ could not be found in SavedModel这样的错。标签也可以选用系统定义好的参数,如tf.saved_model.tag_constants.SERVING与tf.saved_model.tag_constants.TRAINING。
save方法就是将模型序列化到指定目录底下。
保存好以后到saved_model_dir目录下,会有一个saved_model.pb文件以及variables文件夹。顾名思义,variables保存所有变量,saved_model.pb用于保存模型结构等信息。
###载入
使用tf.saved_model.loader.load方法就可以载入模型。如
meta_graph_def = tf.saved_model.loader.load(sess, [‘tag_string’], saved_model_dir)
第一个参数就是当前的session,第二个参数是在保存的时候定义的meta graph的标签,标签一致才能找到对应的meta graph。第三个参数就是模型保存的目录。
load完以后,也是从sess对应的graph中获取需要的tensor来inference。如
x = sess.graph.get_tensor_by_name(‘input_x:0’)
y = sess.graph.get_tensor_by_name(‘predict_y:0’)
实际的待inference的样本
_x = …
sess.run(y, feed_dict={x: _x})
这样和之前的第二种方法一样,也是要知道tensor的name。那么如何可以在不知道tensor name的情况下使用呢? 那就需要给add_meta_graph_and_variables方法传入第三个参数,signature_def_map
使用SignatureDef
关于SignatureDef我的理解是,它定义了一些协议,对我们所需的信息进行封装,我们根据这套协议来获取信息,从而实现创建与使用模型的解耦。SignatureDef的结构以及相关详细的文档在:https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/signature_defs.md
相关API
构建signature
tf.saved_model.signature_def_utils.build_signature_def(
inputs=None,
outputs=None,
method_name=None
)
构建tensor info
tf.saved_model.utils.build_tensor_info(tensor)
SignatureDef,将输入输出tensor的信息都进行了封装,并且给他们一个自定义的别名,所以在构建模型的阶段,可以随便给tensor命名,只要在保存训练好的模型的时候,在SignatureDef中给出统一的别名即可。
TensorFlow的关于这部分的例子中用到了不少signature_constants,这些constants的用处主要是提供了一个方便统一的命名。在我们自己理解SignatureDef的作用的时候,可以先不用管这些,遇到需要命名的时候,想怎么写怎么写。
保存
假设定义模型输入的别名为“input_x”,输出的别名为“output” ,使用SignatureDef的代码如下
builder = tf.saved_model.builder.SavedModelBuilder(saved_model_dir)
x 为输入tensor, keep_prob为dropout的prob tensor
inputs = {‘input_x’: tf.saved_model.utils.build_tensor_info(x),
‘keep_prob’: tf.saved_model.utils.build_tensor_info(keep_prob)}
y 为最终需要的输出结果tensor
outputs = {‘output’ : tf.saved_model.utils.build_tensor_info(y)}
signature = tf.saved_model.signature_def_utils.build_signature_def(inputs, outputs, ‘test_sig_name’)
builder.add_meta_graph_and_variables(sess, [‘test_saved_model’], {‘test_signature’:signature})
builder.save()
上述inputs增加一个keep_prob是为了说明inputs可以有多个, build_tensor_info方法将tensor相关的信息序列化为TensorInfo protocol buffer。
inputs,outputs都是dict,key是我们约定的输入输出别名,value就是对具体tensor包装得到的TensorInfo。
然后使用build_signature_def方法构建SignatureDef,第三个参数method_name暂时先随便给一个。
创建好的SignatureDef是用在add_meta_graph_and_variables的第三个参数signature_def_map中,但不是直接传入SignatureDef对象。事实上signature_def_map接收的是一个dict,key是我们自己命名的signature名称,value是SignatureDef对象。
载入
载入与使用的代码如下
略去构建sess的代码
signature_key = 'test_signature'
input_key = 'input_x'
output_key = 'output'
meta_graph_def = tf.saved_model.loader.load(sess, ['test_saved_model'], saved_model_dir)
#从meta_graph_def中取出SignatureDef对象
signature = meta_graph_def.signature_def
#从signature中找出具体输入输出的tensor name
x_tensor_name = signature[signature_key].inputs[input_key].name
y_tensor_name = signature[signature_key].outputs[output_key].name
#获取tensor 并inference
x = sess.graph.get_tensor_by_name(x_tensor_name)
y = sess.graph.get_tensor_by_name(y_tensor_name)
#_x 实际输入待inference的data
sess.run(y, feed_dict={x:_x})
从上面两段代码可以知道,我们只需要约定好输入输出的别名,在保存模型的时候使用这些别名创建signature,输入输出tensor的具体名称已经完全隐藏,这就实现创建模型与使用模耦。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









