









- 进入KEGG物种列表,网址:https://www.kegg.jp/kegg/catalog/org_list.html
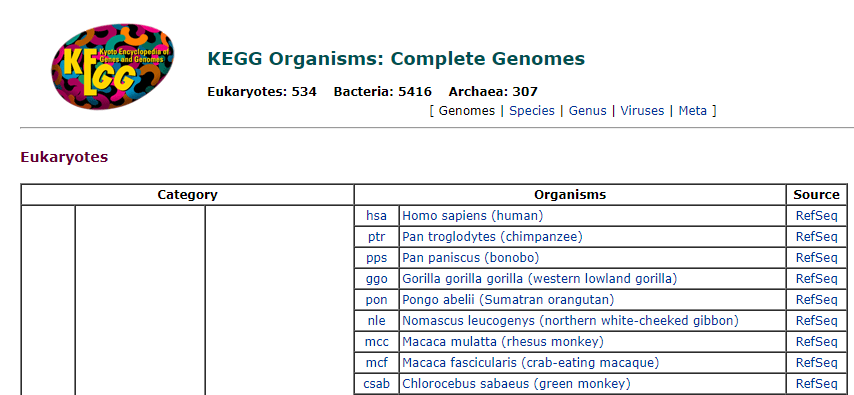
-
这里以小鼠为例,点击
Ctrl+F查找物种小鼠的拉丁名Mus musculus这里也可以用
mouse来搜索,不过可以看到在kegg中含有三种鼠的信息。为了信息准确,最好使用拉丁名作为搜索条件。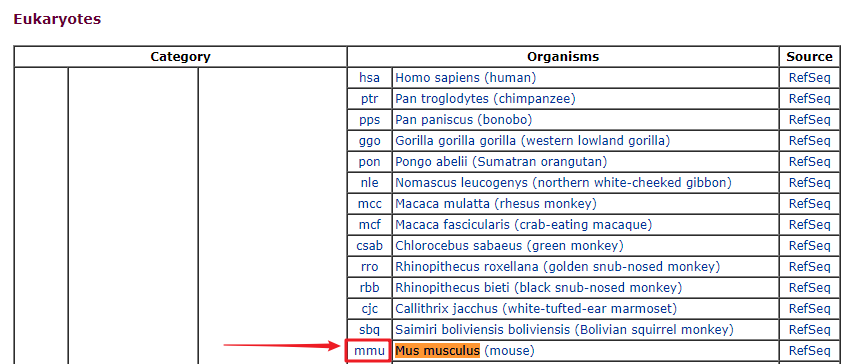
-
点击
Brite hierarchy
-
进入
KEGG Orthology (KO)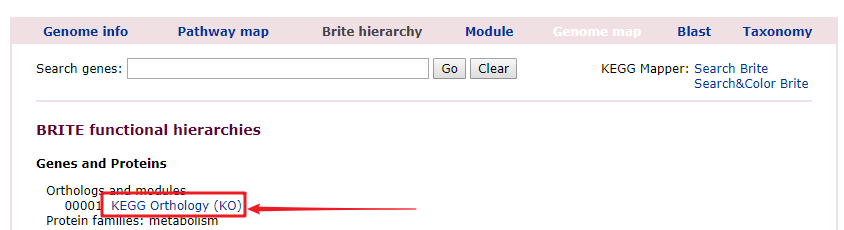
-
KEGG Orthology 提供了两种可供下载的格式,比如下载
htext格式如果提示连接不到网络,可以多次点击,国外网的原因。。。
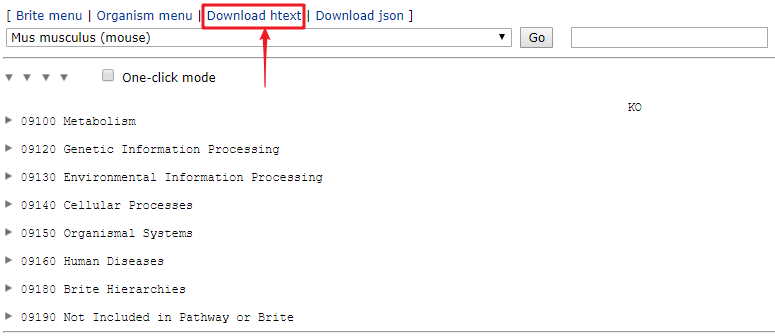
-
htext格式如下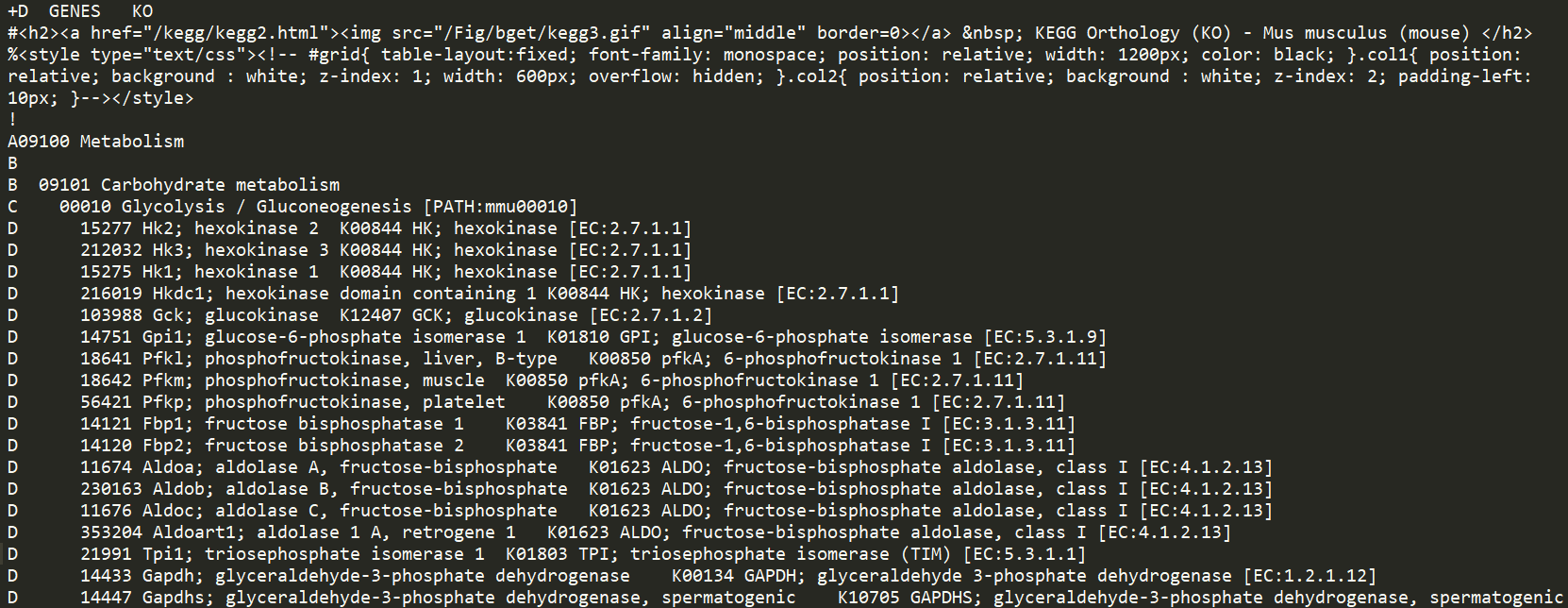
-
下载
json格式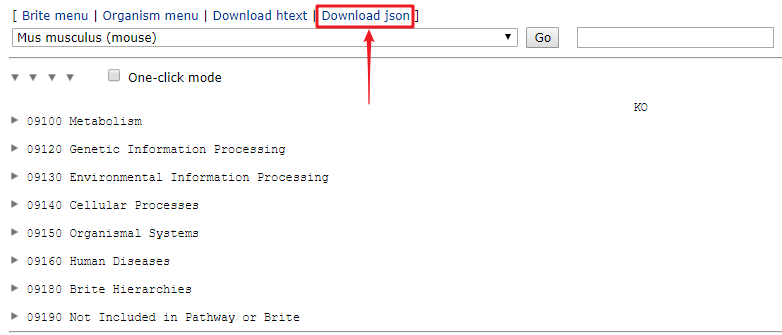
-
json格式如下,这种格式更适合提取数据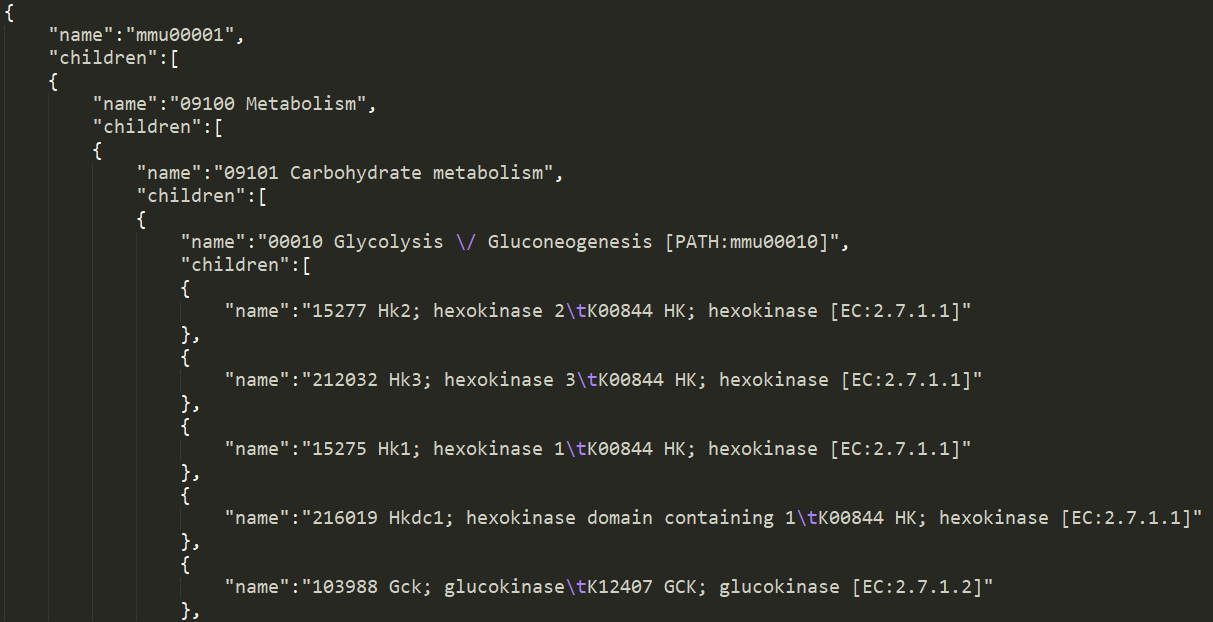


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











