







文章目录
在大模型推理过程中,常常能看到以下参数:
{
"top_k": 10,
"temperature": 0.95,
"num_beams": 1,
"top_p": 0.8,
"repetition_penalty": 1.5,
"max_tokens": 30000,
"message": [
{
"content": "你好!",
"role": "user"
}
]
}
今天这篇文章就是主要介绍 top_k、top_p、temperature 这几个核心参数的含义及使用技巧。
0. 前言
我们熟悉的大多数语言模型都是通过重复生成token序列(sequence)中的下一个token来运作的。每次模型想要生成另一个token时,会重新阅读整个token序列并预测接下来应该出现的token。这种策略被称为自回归生成(autoregressive generation)。

在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,我们需要让模型逐个预测每个 token ,直到达到一个终止条件(如一个标点符号或一个最大长度)。在每一步,模型会给出一个概率分布,表示它对下一个单词的预测。
例如,如果输入的文本是“我最喜欢的”,那么模型可能会给出下面的概率分布:
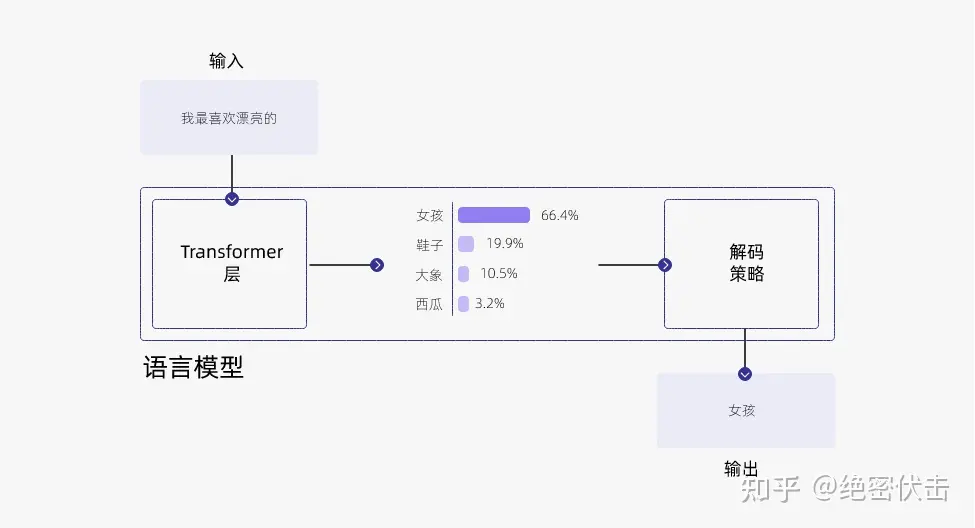
那么,我们应该如何从这个概率分布中选择下一个单词呢?以下是几种常用的方法:
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
- 随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
- Beam Search:维护一个大小为 k 的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k 个单词,然后保留总概率最高的 k 个候选序列。这种方法可以平衡生成的质量和多样性,但是可能会导致生成的文本过于保守和不自然。
以上方法都有各自的问题,而 top-k 采样和 top-p 采样是介于贪心解码和随机采样之间的方法,也是目前大模型解码策略中常用的方法。
1. top-k采样
在上面的例子中,如果使用贪心策略,那么选择的 token 必然就是“女孩”。
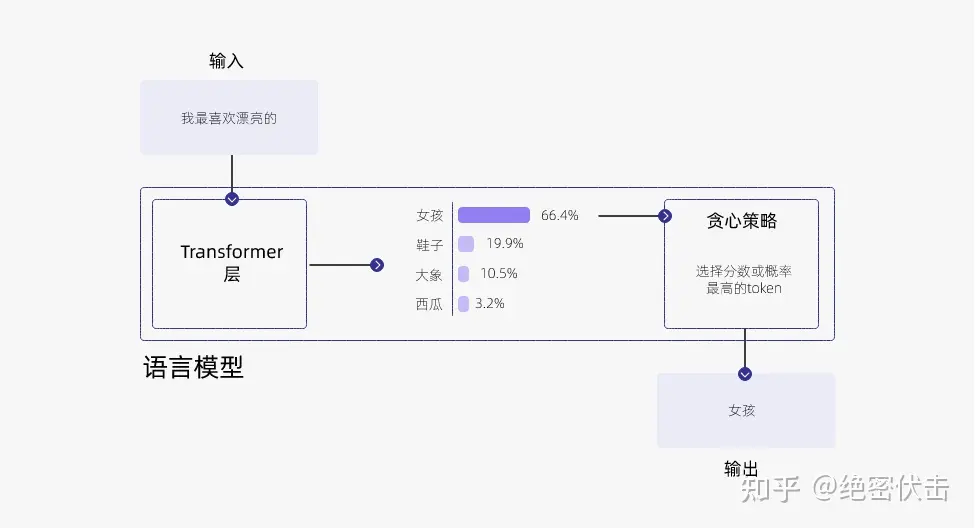
贪心解码是一种合理的策略,但也有一些缺点。例如,输出可能会陷入重复循环。当你不断地选择建议最高的单词时,它可能会变成重复的句子。
Top-k 采样是对前面“贪心策略”的优化,它从排名前 k 的 token 中进行抽样,允许其他分数或概率较高的token 也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
【top-k 采样思路】:在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
例如,如果 k=2,那么我们只从女孩、鞋子中选择一个单词,而不考虑大象、西瓜等其他单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
下面是 top-k 采样的例子:
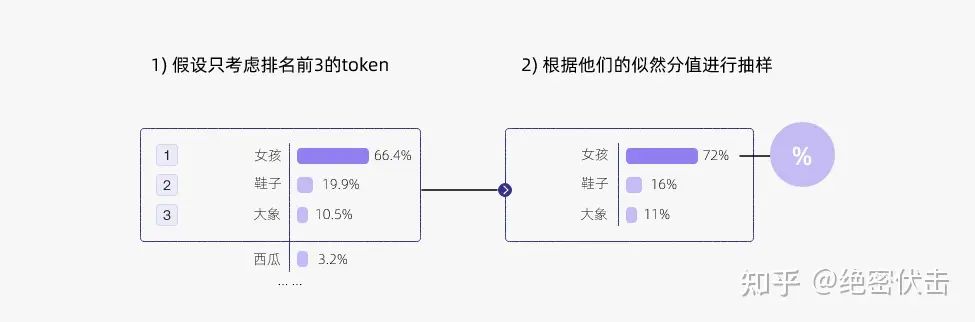
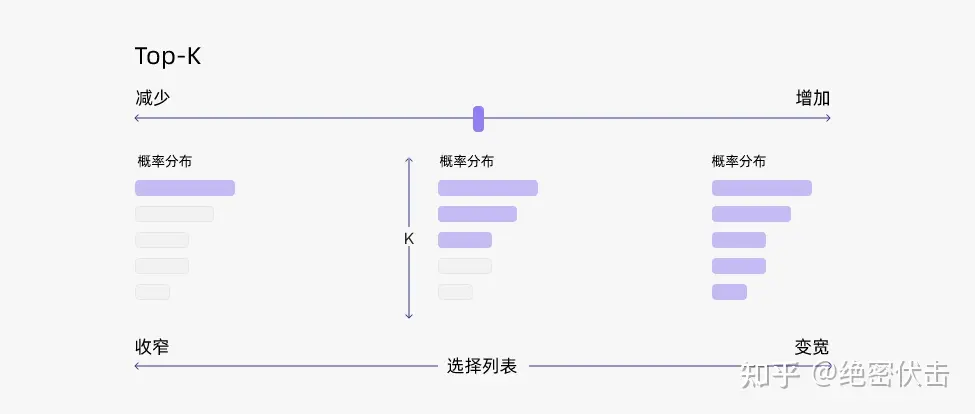
通过调整 k 的大小,即可控制采样列表的大小。“贪心策略”其实就是 k = 1的 top-k 采样。
下面是top-k 的代码实现:
import torch
from labml_nn.sampling import Sampler
# Top-k Sampler
class TopKSampler(Sampler):
# k is the number of tokens to pick
# sampler is the sampler to use for the top-k tokens
# sampler can be any sampler that takes a logits tensor as input and returns a token tensor; e.g. `TemperatureSampler`.
def __init__(self, k: int, sampler: Sampler):
self.k = k
self.sampler = sampler
# Sample from logits
def __call__(self, logits: torch.Tensor):
# New logits filled with −∞; i.e. zero probability
zeros = logits.new_ones(logits.shape) * float('-inf')
# Pick the largest k logits and their indices
values, indices = torch.topk(logits, self.k, dim=-1)
# Set the values of the top-k selected indices to actual logits.
# Logits of other tokens remain −∞
zeros.scatter_(-1, indices, values)
# Sample from the top-k logits with the specified sampler.
return self.sampler(zeros)
下面我们来总结一下top-k方法的优点与缺点:
(1)top-k 优点:
- 它可以根据不同的输入文本动态调整候选单词的数量,而不是固定为 k 个。这是因为不同的输入文本可能会导致不同的概率分布,有些分布可能比较平坦,有些分布可能比较尖锐。如果分布比较平坦,那么前 k 个单词可能都有相近的概率,那么我们就可以从中进行随机采样;如果分布比较尖锐,那么前 k 个单词可能会占据绝大部分概率,那么我们就可以近似地进行贪心解码。
- 它可以通过调整 k 的大小来控制生成的多样性和质量。一般来说,k 越大,生成的多样性越高,但是生成的质量越低;k 越小,生成的质量越高,但是生成的多样性越低。因此,我们可以根据不同的任务和场景来选择合适的k 值。
- 它可以与其他解码策略结合使用,例如温度调节(Temperature Scaling)、重复惩罚(Repetition Penalty)、长度惩罚(Length Penalty)等,来进一步优化生成的效果。
(2)top-k 缺点:
- 它可能会导致生成的文本不符合常识或逻辑。这是因为 top-k 采样只考虑了单词的概率,而没有考虑单词之间的语义和语法关系。例如,如果输入文本是“我喜欢吃”,那么即使饺子的概率最高,也不一定是最合适的选择,因为可能用户更喜欢吃其他食物。
- 它可能会导致生成的文本过于简单或无聊。这是因为 top-k 采样只考虑了概率最高的 k 个单词,而没有考虑其他低概率但有意义或有创意的单词。例如,如果输入文本是“我喜欢吃”,那么即使苹果、饺子和火锅都是合理的选择,也不一定是最有趣或最惊喜的选择,因为可能用户更喜欢吃一些特别或新奇的食物。
因此,我们通常会考虑 top-k 和其它策略结合,比如 top-p。
2. top-p采样
top-k 有一个缺陷,那就是“k 值取多少是最优的?”非常难确定。于是出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)。
【top-p 采样:思路】:在每一步,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的单词。这种方法也被称为核采样(nucleus sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分。
例如,如果 p=0.9,那么我们只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
下图展示了 top-p 值为 0.9 的 Top-p 采样效果:
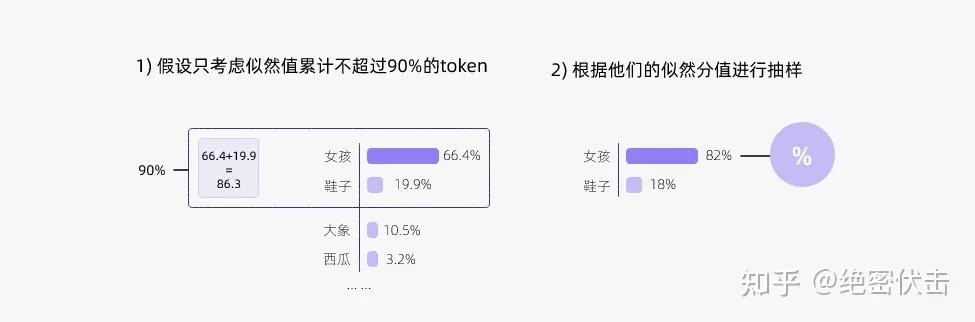
top-p 值通常设置为比较高的值(如0.75),目的是限制低概率 token 的长尾。我们可以同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
下面是 top-p 代码实现的例子:
import torch
from torch import nn
from labml_nn.sampling import Sampler
class NucleusSampler(Sampler):
"""
## Nucleus Sampler
"""
def __init__(self, p: float, sampler: Sampler):
"""
:param p: is the sum of probabilities of tokens to pick $p$
:param sampler: is the sampler to use for the selected tokens
"""
self.p = p
self.sampler = sampler
# Softmax to compute $P(x_i | x_{1:i-1})$ from the logits
self.softmax = nn.Softmax(dim=-1)
def __call__(self, logits: torch.Tensor):
"""
Sample from logits with Nucleus Sampling
"""
# Get probabilities $P(x_i | x_{1:i-1})$
probs = self.softmax(logits)
# Sort probabilities in descending order
sorted_probs, indices = torch.sort(probs, dim=-1, descending=True)
# Get the cumulative sum of probabilities in the sorted order
cum_sum_probs = torch.cumsum(sorted_probs, dim=-1)
# Find the cumulative sums less than $p$.
nucleus = cum_sum_probs < self.p
# Prepend ones so that we add one token after the minimum number
# of tokens with cumulative probability less that $p$.
nucleus = torch.cat([nucleus.new_ones(nucleus.shape[:-1] + (1,)), nucleus[..., :-1]], dim=-1)
# Get log probabilities and mask out the non-nucleus
sorted_log_probs = torch.log(sorted_probs)
sorted_log_probs[~nucleus] = float('-inf')
# Sample from the sampler
sampled_sorted_indexes = self.sampler(sorted_log_probs)
# Get the actual indexes
res = indices.gather(-1, sampled_sorted_indexes.unsqueeze(-1))
#
return res.squeeze(-1)
3. Temperature采样
Temperature 采样受统计热力学的启发,高温意味着更可能遇到低能态。
在概率模型中,logits 扮演着能量的角色,我们可以通过将 logits 除以温度来实现温度采样,然后将其输入 Softmax 并获得采样概率。
temperature这个参数可以告诉机器如何在质量和多样性之间进行权衡。较低的 temperature 意味着更高的质量,而较高的 temperature 意味着更高的多样性。当 temperature 设置为零时,模型总是会选择具有最高可能性分数的token,从而导致模型生成的回复缺乏多样性,但却能确保总是选择模型评估出的最高质量的token来生成回复。
Temperature 采样中的温度与玻尔兹曼分布有关,其公式如下所示:
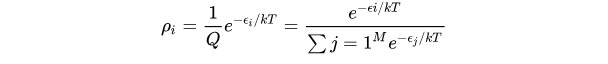
其中 ρ i \rho_i ρi 是状态 i i i 的概率, ϵ i \epsilon_i ϵi 是状态 i i i 的能量, k k k 是波兹曼常数, T T T 是系统的温度, M M M 是系统所能到达的所有量子态的数目。
有机器学习背景的朋友第一眼看到上面的公式会觉得似曾相识。没错,上面的公式跟 Softmax 函数 :
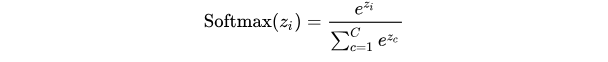
很相似,本质上就是在 Softmax 函数上添加了温度(T)这个参数。Logits 根据我们的温度值进行缩放,然后传递到 Softmax 函数以计算新的概率分布。
上面“我喜欢漂亮的___”这个例子中,初始温度 T=1 ,我们直观看一下 T 取不同值的情况下,概率会发生什么变化:
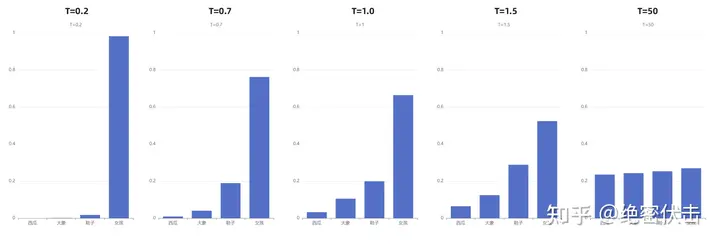
通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当 T=50 时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。

通常来说,温度与模型的“创造力”有关。但事实并非如此。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
下面是 Temperature 采样的代码实现:
import torch
from torch.distributions import Categorical
from labml_nn.sampling import Sampler
class TemperatureSampler(Sampler):
"""
## Sampler with Temperature
"""
def __init__(self, temperature: float = 1.0):
"""
:param temperature: is the temperature to sample with
"""
self.temperature = temperature
def __call__(self, logits: torch.Tensor):
"""
Sample from logits
"""
# Create a categorical distribution with temperature adjusted logits
dist = Categorical(logits=logits / self.temperature)
# Sample
return dist.sample()
4. 联合采样(top-k & top-p & Temperature)
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
(1)首先我们设置 top-k = 3,表示保留概率最高的3个 token。这样就会保留女孩、鞋子、大象这3个 token。
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
(2)接下来,我们可以使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。
(3)接着我们使用 Temperature = 0.7 进行归一化,变成:
- 女孩:0.660
- 鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
4. frequency penalty 和 presence penalty
最后,让我们来讨论本文中的最后两个参数:频率惩罚和存在惩罚(frequency and presence penalties)。 这些参数是另一种让模型在质量和多样性之间进行权衡的方法。temperature 参数通过在token选择(token sampling)过程中添加随机性来实现输出内容的多样性,而频率惩罚和存在惩罚则通过对已在文本中出现的token施加惩罚以增加输出内容的多样性。 这使得对旧的和过度使用的token进行选择变得不太可能,从而让模型选择更新颖的token。
- 频率惩罚(frequency penalty):让token每次在文本中出现都受到惩罚。这可以阻止重复使用相同的token/单词/短语,同时也会使模型讨论的主题更加多样化,更频繁地更换主题。
- 存在惩罚(presence penalty):一种固定的惩罚,如果一个token已经在文本中出现过,就会受到惩罚。这会导致模型引入更多新的token/单词/短语,从而使其讨论的主题更加多样化,话题变化更加频繁,而不会明显抑制常用词的重复。
就像 temperature 一样,频率惩罚和存在惩罚(frequency and presence penalties)会引导我们远离“最佳的”可能回复,朝着更有创意的方向前进。然而,它们不像 temperature 那样通过引入随机性,而是通过精心计算的针对性惩罚,为模型生成内容增添多样性在一些罕见的、需要非零 temperature 的任务中(需要对同一个提示语给出多个答案时),可能还需要考虑将小的频率惩罚或存在惩罚加入其中,以提高创造性。但是,对于只有一个正确答案且您希望一次性找到合理回复的提示语,当您将所有这些参数设为零时,成功的几率就会最高。
一般来说,如果只存在一个正确答案,并且您只想问一次时,就应该将频率惩罚和存在惩罚的数值设为零。但如果存在多个正确答案(比如在文本摘要中),在这些参数上就可以进行灵活处理。如果您发现模型的输出乏味、缺乏创意、内容重复或内容范围有限,谨慎地应用频率惩罚或存在惩罚可能是一种激发活力的好方法。但对于这些参数的最终建议与 temperature 的建议相同:在不确定的情况下,将它们设置为零是一个最安全的选择!
5. 参数调整技巧
下面总结一些常用的调参技巧。
- 将参数设为零的规则:
-
temperature:
- 对于每个提示语只需要单个答案:零。
- 对于每个提示语需要多个答案:非零。
-
频率惩罚和存在惩罚:
- 当问题仅存在一个正确答案时:零。
- 当问题存在多个正确答案时:可自由选择。
-
Top-p/Top-k:
- 在 temperature 为零的情况下:输出不受影响。
- 在 temperature 不为零的情况下:非零。
如果您使用的语言模型具有此处未列出的其他参数,将其保留为默认值始终是可以的。
- 当参数非0时,参数调整的技巧:
先列出那些应该设置为非零值的参数,然后去 playground 尝试一些用于测试的提示语,看看哪些效果好。但是,如果上述规则说要将参数值保持为零,则应当将其保持为零!
- 调整temperature/top-p/top-k的技巧:
- 为了使模型输入内容拥有更多的多样性或随机性,应当增加temperature。
- 在 temperature 非零的情况下,从 0.95 左右的 top-p(或 250 左右的 top-k )开始,根据需要降低 temperature。
注意:
- 如果有太多无意义的内容、垃圾内容或产生幻觉,应当降低 temperature 和 降低top-p/top-k。
- 如果 temperature 很高而模型输出内容的多样性却很低,应当增加top-p/top-k。
Tip: 虽然有些模型能够让我们同时调整 top-p 和 top-k ,但我更倾向于只调整其中一个参数。top-k 更容易使用和理解,但 top-p 通常更有效。
- 调整频率惩罚和存在惩罚的技巧:
- 为了获得更多样化的主题,应当增加存在惩罚值。
- 为了获得更多样化且更少重复内容的模型输出,应当增加频率惩罚。
注意:
- 如果模型输出的内容看起来零散并且话题变化太快,应当降低存在惩罚。
- 如果有太多新奇和不寻常的词语,或者存在惩罚设置为零但仍然存在很多话题变化,应当降低频率惩罚。

















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









