






兰佳华1 张森2 潘海霞1 刘瑞军1 沈力3 陶大程4
摘要
与人类持续获取知识的能力相比,代理在深度强化学习(DRL)中面临着稳定性和可塑性的两难困境,这指的是保留现有技能(稳定性)和学习新知识(可塑性)之间的权衡。当前方法主要集中在网络层面平衡这两个方面,缺乏对单个神经元的充分区分和细粒度控制。为克服这一限制,我们提出了神经元层面稳定性与可塑性平衡(NBSP)方法,灵感来源于观察到特定神经元与任务相关技能高度相关。具体而言,NBSP首先(1)通过目标导向的方法定义并识别对知识保留至关重要的RL技能神经元,然后(2)通过针对这些神经元使用梯度掩码和经验回放技术引入一个框架,在保留已编码现有技能的同时使适应新任务成为可能。在Meta-World和Atari基准上的大量实验结果表明,NBSP在平衡稳定性和可塑性方面显著优于现有方法。
1. 引言
深度强化学习(DRL)已在一系列复杂场景中展现出卓越能力,例如游戏(Mnih et al., [2013)
现有的平衡稳定性和可塑性的方法通常分为三类,即(1)正则化方法(Kirkpatrick et al., [2017;
通过分析DRL网络中神经元的激活情况,我们观察到任务学习后,某些神经元的激活与任务目标高度相关。例如,图1展示了在Meta-World基准上训练drawer-open任务后网络中特定神经元的激活分布[(Yu et al.,
1 北京航空航天大学软件学院,北京,中国 2 TikTok,悉尼,澳大利亚 3 中山大学深圳校区网络空间科学与技术学院,深圳,中国 4 新加坡南洋理工大学。联系人:潘海霞 haixiapan@buaa.edu.cn.
2020)。该神经元的激活可以作为任务成功的一个可靠预测指标。较高的激活水平对应更高的任务完成可能性,表明此神经元编码了任务所需的关键技能。因此,它在保留任务特定记忆方面发挥了重要作用。
受上述观察的启发,在本研究中,我们从神经元的角度解决了稳定性和可塑性困境,并提出了神经元层面稳定性与可塑性平衡(NBSP),这是一种新的DRL框架,作用于单个神经元层面。特别是,(1)我们首次引入了RL技能神经元,它们编码了知识保留所需的必要技能。虽然技能神经元在各种领域已被广泛研究和成功利用,如预训练语言模型(Wang et al., [2022)
我们在Meta-World (Yu et al., [2020)
总结来说,我们的主要贡献包括:
- 我们首次引入了RL技能神经元的概念,这些神经元编码了任务技能,对于知识保留至关重要,并提出了一种专门针对DRL的目标导向策略进行识别。
- 我们通过在这些神经元上应用梯度掩蔽和经验回放来解决DRL中的稳定性和可塑性困境,无需复杂的网络设计或附加参数。
-
- 我们在Meta-World和Atari基准上进行了广泛的实验,证明了我们方法在平衡稳定性和可塑性方面的有效性。
2. 相关工作
稳定性和可塑性之间的平衡。在DRL中,解决稳定性和可塑性困境(Carpenter & Grossberg, [1988)
神经元层面研究。最近的研究表明,神经元稀疏性往往与任务特定性能相关(Xu et al., [2024)
3. 稳定性与可塑性之间的平衡
在本节中,我们首先介绍RL技能神经元的术语,然后提出神经元层面稳定性与可塑性平衡(NBSP)方法。
3.1. 问题设定
在DRL中,代理连续学习一系列任务τ ∈ {τ1, τ2, …},每个任务τ对应一个独特的马尔可夫决策过程(MDP)Mτ = (S τ , Aτ , Pτ , Rτ , γτ ),其中S τ , Aτ , P τ , Rτ 和γ τ 分别表示状态空间、动作空间、转移动态、奖励函数和折扣因子。目标不是解决单一的MDP,而是使用通用策略π(a|s)和Q函数Q(s, a)逐一解决一系列MDP。主要挑战在于实现可塑性和稳定性的平衡。具体来说,可塑性指的是最大化当前任务的折现回报,而稳定性则强调最大化所有先前任务的预期折现回报的平均值。如何平衡这种权衡是我们在这项工作中研究的主要问题。
3.2. 识别RL技能神经元
在本研究中,我们做出一个关键观察,即代理网络的稳定性和可塑性与其表达能力密切相关,而这又受到单个神经元行为的显著影响。正如Molchanov et al. [(2022)
几项研究展示了神经元的多方面能力,如存储事实知识(Dai et al., [2022)
在本研究中,我们正式将这些特殊神经元定义为RL技能神经元,它们编码了对于知识保留至关重要的关键技能。此外,我们提出了一种目标导向的方法来识别这些神经元。与之前主要关注触发神经元激活的输入的方法不同,我们的方法强调它们对实现最终目标的影响,即成功完成Meta-World任务并在Atari游戏中获得高分,通过比较表现水平不同的代理的神经元激活模式。在第4.2节中,我们实证显示所提出的目标准确方法可以更好地识别真正编码任务特定RL技能的神经元。
对于特定神经元N,令a(N, t)表示其在步骤t的激活。在全连接层中,每个输出维度对应特定神经元的激活,而在卷积层中,每个输出通道的平均值代表神经元的激活。为了量化神经元N的激活水平,我们定义标准激活如下:
a
‾
(
N
)
=
1
T
∑
t
=
1
T
a
(
N
,
t
)
,
(1)
\overline{a}(\mathcal{N}) = \frac{1}{T} \sum_{t=1}^{T} a(\mathcal{N}, t), \tag{1}
a(N)=T1t=1∑Ta(N,t),(1)
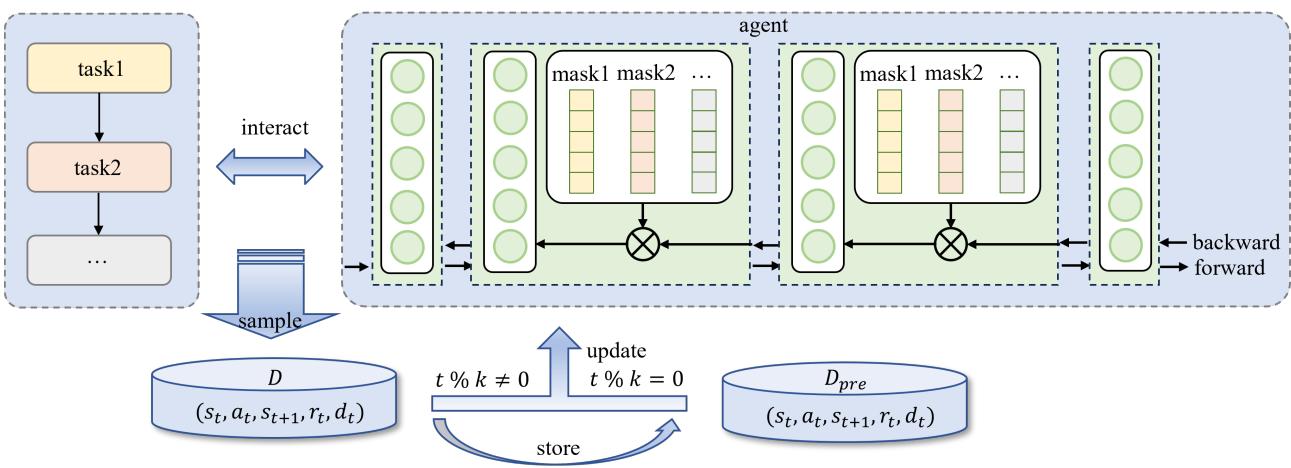
图2. NBSP框架。代理对每个任务评分并识别RL技能神经元。在学习新任务时,根据这些神经元的评分对其梯度进行掩码,以保留编码的技能,同时仍允许微调以学习新任务。此外,使用重放缓冲区存储来自先前任务的一部分经验,周期性采样以更新代理,确保保留早期任务的知识。
其中T表示评估步数。通过将其当前激活与标准激活进行比较,可以评估神经元的激活水平。
为了评估代理在步骤t的性能,我们引入了目标接近度量(GPM),记为q(t)。该度量量化了代理朝着任务目标进展的程度,根据任务的具体目标有所不同。例如,在Meta-World基准上,GPM通常是二进制的,表示代理是否成功完成任务。相比之下,GPM在Atari基准上根据一集中的回报计算。此外,我们定义了代理的标准目标接近度量(GPM),如下所示,用作通过将其与当前GPM比较来评估性能的基线。
q
‾
=
1
T
∑
t
=
1
T
q
(
t
)
.
(2)
\overline{q} = \frac{1}{T} \sum_{t=1}^{T} q(t). \tag{2}
q=T1t=1∑Tq(t).(2)
为了区分各种任务中神经元的角色,有必要评估神经元激活与特定目标的关系。直观上,当神经元N在步骤t的激活a(N, t)超过标准激活a(N),即a(N, t) > a(N),同时该步骤的GPM也超过其标准,即q(t) > q时,我们可以认为神经元N对目标有积极贡献。为了量化这种贡献,我们累积一批结果并定义正准确率为如下:
A
c
c
(
N
)
=
∑
t
=
1
T
1
[
1
[
a
(
N
,
t
)
)
>
T
(
N
)
]
=
1
[
q
(
t
)
>
η
‾
]
T
T
.
(3)
Acc(\mathcal{N}) = \frac{\sum_{t=1}^{T} \mathbf{1}_{[1_{[a(\mathcal{N},t)) > \mathfrak{T}(\mathcal{N})]} = \mathbf{1}_{[q(t) > \overline{\eta}]}}{T}}{T}. \tag{3}
Acc(N)=T∑t=1T1[1[a(N,t))>T(N)]=1[q(t)>η]T.(3)
这里,1[条件] ∈ {0, 1}表示指示函数,仅当指定条件满足时返回1。虽然式(3)评估了神经元对实现目标的正向贡献,其中较高的准确性意味着神经元在产生更好结果方面的重要性更大,但它忽略了那些与目标呈负相关的神经元,而这些神经元仍携带了有价值的与任务相关知识。具体来说,当神经元的激活低于其标准激活时,代理的表现反而更好。为此,我们定义了一个全面得分Score(N),考虑了神经元的正向和负向影响:
S
c
o
r
e
(
N
)
=
max
(
A
c
c
(
N
)
,
1
−
A
c
c
(
N
)
)
.
(
4
)
Score(\mathcal{N}) = \max(Acc(\mathcal{N}), 1 - Acc(\mathcal{N})).\qquad(4)
Score(N)=max(Acc(N),1−Acc(N)).(4)
随后,我们根据得分对代理网络中的所有神经元(最后一层除外)进行降序排列。得分最高的神经元被识别为RL技能神经元,因为它们在保留任务特定知识方面起到了关键作用。识别方法的算法见附录[D.] (#page-18-0)
3.3. 神经元层面稳定性与可塑性平衡
基于RL技能神经元的概念,我们提出了一个新的DRL框架——神经元层面稳定性与可塑性平衡(NBSP),如图2. 所示。与以前的方法[(Bai et al.,
简单冻结RL技能神经元会阻碍代理适应新任务的能力。为解决这一挑战,NBSP采用梯度掩码技术来平衡稳定性和可塑性。具体来说,在连续学习过程中的每次训练更新中,选择性地对RL技能神经元的梯度进行掩码,以限制其激活模式的变化,同时允许其他神经元自由适应。此过程形式化表达如下:
Δ W : , j ′ ( l ) = m a s k j ( l ) ⋅ Δ W : , j ( l ) , (5) \Delta W_{:,j}^{\prime(l)} = mask_j^{(l)} \cdot \Delta W_{:,j}^{(l)}, \tag{5} ΔW:,j′(l)=maskj(l)⋅ΔW:,j(l),(5)
其中 ∆W (l) :,j 表示相对于网络第 l 层权重 W (l) :,j 的梯度,j 是该层输出神经元的索引。mask(l) j 与第 l 层第 j 个神经元的得分相关联,可以计算如下:
m
a
s
k
(
N
)
=
{
α
(
1
−
S
c
o
r
e
(
N
)
)
if
N
∈
{
N
R
L
s
k
i
l
l
}
1
if
N
∉
{
N
R
L
s
k
i
l
l
}
,
(6)
mask(\mathcal{N}) = \begin{cases} \alpha (1 - Score(\mathcal{N})) & \text{if } \mathcal{N} \in \{\mathcal{N}_{RL\,skill}\} \\ 1 & \text{if } \mathcal{N} \notin \{\mathcal{N}_{RL\,skill}\} \end{cases},\tag{6}
mask(N)={α(1−Score(N))1if N∈{NRLskill}if N∈/{NRLskill},(6)
其中 {NRL skill} 表示 RL 技能神经元的集合,α 是一个决定这些神经元激活模式限制程度的参数,实验中配置为 0.2。通过采用梯度掩码,NBSP 有效地保护了 RL 技能神经元中编码的技能免受新任务学习期间的干扰,从而增强了稳定性。同时,RL 技能神经元仍然具有可调性,允许微调以适应新任务并保持高可塑性。此外,除了 RL 技能神经元外的神经元可以完全参与学习新任务特定知识,确保跨任务的全面学习。
为了减轻对先前任务知识的过度漂移,我们整合了经验回放技术,定期在特定间隔 k 处采样先前经验。在任务训练完成后,部分经验而非全部被存储在一个统一的重放缓冲区 Dpre 中,只需适度的内存占用。通过结合经验回放,DRL 代理的稳定性得到了进一步增强。相应的损失函数定义如下:
L = R ( t ) ⋅ E ( s t , a t , s t + 1 , r t , d t ) ∼ D p r s [ L ] + ( 1 − R ( t ) ) ⋅ E ( s t , a t , s t + 1 , r t , d t ) ∼ D [ L ] , (7) \begin{split} \mathcal{L} &= R(t) \cdot \mathbb{E}_{\left(s_t, a_t, s_{t+1}, r_t, d_t\right) \sim D_{prs}} [L] \\ &+ (1 - R(t)) \cdot \mathbb{E}_{\left(s_t, a_t, s_{t+1}, r_t, d_t\right) \sim D} [L], \end{split} \tag{7} L=R(t)⋅E(st,at,st+1,rt,dt)∼Dprs[L]+(1−R(t))⋅E(st,at,st+1,rt,dt)∼D[L],(7)
其中 L 表示原始损失函数,R(t) 是一个二元函数,仅当当前步骤 t 处于间隔时才评估为 1。D 表示当前任务的重放缓冲区,(st, at, st+1, rt, dt) 表示从重放缓冲区采样的当前状态、动作、下一个状态、奖励和是否结束的一组元组。NBSP 的整体算法见附录 [D.] (#page-18-0)
4. 实验
在本节中,我们在 Meta-World (Yu et al., [2020)
实验设置。我们遵循 [Abbas et al.] (#page-8-2) (2023); [Liu et al.] (#page-9-14) [(2024)
对于所有实验,我们使用 CleanRL (Huang et al., [2022)
度量。总体性能通常使用平均成功率 (ASR) 进行评估,类似于平均增量精度 (AIA) 度量 (Wang et al., [2024)
A
S
R
=
1
k
∑
i
=
1
k
1
i
∑
i
≥
j
s
r
i
,
j
,
(8)
ASR = \frac{1}{k} \sum_{i=1}^{k} \frac{1}{i} \sum_{i \ge j} sr_{i,j},\tag{8}
ASR=k1i=1∑ki1i≥j∑sri,j,(8)
其中 k 表示任务数量。ASR 越高,方法在平衡稳定性和可塑性方面表现越好。
为了评估代理的稳定性,我们使用遗忘度量 (FM) (Chaudhry et al., [2018a)
| 循环顺序任务 | 度量 | 方法 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| EWC | NPC | ANCL | CoTASP | CRelu | CBP | PI | NBSP | ||
| (window-open → window-close) | ASR ↑ | 0.63 ± 0.03 | 0.26 ± 0.01 | 0.66 ± 0.04 | 0.05 ± 0.01 | 0.26 ± 0.14 | 0.67 ± 0.05 | 0.61 ± 0.02 | 0.90 ± 0.04 |
| FM ↓ | 0.89 ± 0.07 | 0.68 ± 0.04 | 0.84 ± 0.10 | 0.01 ± 0.01 | 0.66 ± 0.42 | 0.78 ± 0.13 | 0.91 ± 0.07 | 0.18 ± 0.01 | |
| FWT ↑ | 0.97 ± 0.02 | 0.26 ± 0.01 | 0.97 ± 0.03 | 0.04 ± 0.01 | 0.33 ± 0.19 | 0.95 ± 0.02 | 0.95 ± 0.01 | 0.96 ± 0.02 | |
| (drawer-open | ASR ↑ | 0.68 ± 0.06 | 0.35 ± 0.05 | 0.64 ± 0.02 | 0.07 ± 0.01 | 0.29 ± 0.20 | 0.61 ± 0.03 | 0.60 ± 0.07 | 0.96 ± 0.02 |
| → drawer-close) | FM ↓ | 0.80 ± 0.15 | 0.69 ± 0.05 | 0.88 ± 0.09 | 0.01 ± 0.01 | 0.31 ± 0.32 | 0.91 ± 0.03 | 0.71 ± 0.30 | 0.07 ± 0.06 |
| FWT ↑ | 0.98 ± 0.01 | 0.39 ± 0.09 | 0.96 ± 0.01 | 0.09 ± 0.00 | 0.42 ± 0.28 | 0.93 ± 0.04 | 0.88 ± 0.15 | 0.98 ± 0.01 | |
| (button-press-topdown | ASR ↑ | 0.66 ± 0.06 | 0.25 ± 0.00 | 0.61 ± 0.01 | 0.03 ± 0.00 | 0.33 ± 0.10 | 0.62 ± 0.01 | 0.63 ± 0.02 | 0.95 ± 0.05 |
| → window-open) | FM ↓ | 0.85 ± 0.14 | 0.67 ± 0.00 | 0.95 ± 0.05 | 0.01 ± 0.00 | 0.94 ± 0.01 | 0.97 ± 0.03 | 0.97 ± 0.05 | 0.08 ± 0.12 |
| FWT ↑ | 0.96 ± 0.01 | 0.25 ± 0.01 | 0.95 ± 0.03 | 0.04 ± 0.01 | 0.42 ± 0.20 | 0.98 ± 0.02 | 0.98 ± 0.02 | 0.98 ± 0.01 | |
| (window-open → window-close → drawer-open → drawer-close) | ASR ↑ | 0.44 ± 0.05 | 0.19 ± 0.04 | 0.48 ± 0.04 | 0.04 ± 0.01 | 0.10 ± 0.06 | 0.43 ± 0.03 | 0.41 ± 0.06 | 0.66 ± 0.14 |
| FM ↓ | 0.74 ± 0.11 | 0.50 ± 0.02 | 0.80 ± 0.04 | 0.04 ± 0.01 | 0.39 ± 0.02 | 0.91 ± 0.05 | 0.84 ± 0.05 | 0.48 ± 0.18 | |
| FWT ↑ | 0.83 ± 0.10 | 0.20 ± 0.05 | 0.89 ± 0.06 | 0.08 ± 0.01 | 0.13 ± 0.10 | 0.97 ± 0.02 | 0.82 ± 0.10 | 0.89 ± 0.12 | |
| (button-press-topdown → window-close → door-open → drawer-close) | ASR ↑ | 0.43 ± 0.03 | 0.17 ± 0.01 | 0.44 ± 0.03 | 0.04 ± 0.01 | 0.14 ± 0.11 | 0.41 ± 0.02 | 0.38 ± 0.01 | 0.74 ± 0.07 |
| FM ↓ | 0.81 ± 0.09 | 0.47 ± 0.01 | 0.87 ± 0.02 | 0.04 ± 0.00 | 0.62 ± 0.16 | 0.94 ± 0.02 | 0.97 ± 0.02 | 0.34 ± 0.15 | |
| FWT ↑ | 0.88 ± 0.10 | 0.19 ± 0.02 | 0.91 ± 0.08 | 0.07 ± 0.02 | 0.17 ± 0.15 | 0.97 ± 0.01 | 0.92 ± 0.07 | 0.95 ± 0.06 |
表1. NBSP与其他基线在Meta-World基准上的结果。

图3. NBSP在Meta-World基准上的训练过程。虚线左右的段分别表示第一和第二循环的训练过程。
实验中,FM 计算如下:
F M = 1 k − 1 ∑ i = 2 k 1 i − 1 ∑ i ≥ j max l ∈ { 1 , … , i − 1 } ( s r l , j − s r i , j ) . ( 9 ) FM = \frac{1}{k-1} \sum_{i=2}^{k} \frac{1}{i-1} \sum_{i \ge j} \max_{l \in \{1, \dots, i-1\}} (sr_{l,j} - sr_{i,j}). \quad (9) FM=k−11i=2∑ki−11i≥j∑l∈{1,…,i−1}max(srl,j−sri,j).(9)
为了评估代理的可塑性,我们采用前向迁移(FWT)度量(Lopez-Paz & Ranzato, 20------
17),其计算方法如下:
F W T = 1 k ∑ i = 1 k s r i , i . (10) FWT = \frac{1}{k} \sum_{i=1}^{k} sr_{i,i}.\tag{10} FWT=k1i=1∑ksri,i.(10)
FWT 越高,方法在保持可塑性方面的表现越好。关于评估度量的更多细节见附录 [C.4.] (#page-15-0)
基线。为了评估我们提出的 NBSP 框架的有效性,我们将它与七种处理稳定性与可塑性平衡问题的基线方法进行比较。EWC
------ (Kirkpatrick et al., [2017)
(Nikishin et al., [2024)
4.1. Meta-World 基准上的实验
NBSP 在 Meta-World 基准上与其他基线的实验结果如表 [1.] (#page-5-0) 所示。如最后一列所示,NBSP 在所有评估指标(包括 ASR、FM 和 FWT)上显著优于其他方法。对于双任务循环任务,NBSP 的 ASR 一致高于 0.9,远超其他基线。其稳定性度量 FM 显著较低,而可塑性度量 FWT 仍保持在高水平。此外,NBSP 在四任务循环任务中也表现出色,保持对所有基线的显著领先。
| 组件 | 度量 | ||||||
|---|---|---|---|---|---|---|---|
| 梯度 掩码 | 经验 回放 | ASR ↑ | FM ↓ | FT ↑ | |||
| × | × | 0.62 ± 0.01 | 0.99 ± 0.02 | 0.98 ± 0.02 | |||
| × | ✓ | 0.70 ± 0.08 | 0.50 ± 0.16 | 0.92 ± 0.05 | |||
| ✓ | × | 0.71 ± 0.06 | 0.73 ± 0.21 | 0.97 ± 0.02 | |||
| ✓ | ✓ | 0.95 ± 0.05 | 0.08 ± 0.12 | 0.98 ± 0.01 |
表 2. 梯度掩码和经验回放技术消融研究的结果。
表 3. 神经元识别方法消融研究的结果。
| 循环顺序任务 | 方法 | 度量 | ||||
|---|---|---|---|---|---|---|
| ASR ↑ | FM ↓ | FT ↑ | ||||
| (window-open | 随机 | 0.78 ± 0.09 | 0.42 ± 0.13 | 0.90 ± 0.06 | ||
| → window-close) | 我们的 | 0.90 ± 0.04 | 0.18 ± 0.01 | 0.96 ± 0.02 | ||
| (drawer-open | 随机 | 0.72 ± 0.26 | 0.41 ± 0.28 | 0.83 ± 0.23 | ||
| → drawer-close) | 我们的 | 0.96 ± 0.02 | 0.07 ± 0.06 | 0.98 ± 0.01 | ||
| (button-press-topdown | 随机 | 0.72 ± 0.01 | 0.70 ± 0.05 | 0.96 ± 0.02 | ||
| → window-open) | 我们的 | 0.95 ± 0.05 | 0.08 ± 0.12 | 0.98 ± 0.01 |
对于以稳定性为重点的基线,EWC 相比其他基线实现了相对较好的 ASR,但仍不及 NBSP。此外,EWC 因其高 FM 值表现出较差的稳定性。NPC 表现更差,未能有效保持稳定性和可塑性。在以可塑性为重点的基线中,CBP 和 PI 实现了与 NBSP 可比的可塑性,这反映在其高的 FWT 分数上。然而,两者都因较高的 FM 值而遭受严重的稳定性损失。另一种以可塑性为重点的方法 CRelu 在稳定性和可塑性方面表现不佳。对于试图平衡稳定性和可塑性的基线,ANCL 保持高可塑性,具有竞争力的 FWT 分数,但在保留先前知识方面表现不佳,这由其较差的 FM 性能所表明。CoTASP,设计用于平衡稳定性和可塑性,在整体表现上较差。
图 3, 进一步展示了 NBSP 的有效性,该图展示了 NBSP 的训练动态。具体来说,在第二次学习相同任务时,代理在再训练前就表现出较高的成功率,表明它已保留了显著的任务知识。因此,代理能够更快地掌握任务。这突显了 NBSP 在保留先前任务知识的同时,同时保持适应新任务所需的可塑性的能力。其他训练过程见附录 [C.5.] (#page-16-0) 总之,NBSP 在不损害可塑性的情况下显著提高了保持稳定性,实现了 DRL 中良好的平衡。
4.2. 消融研究
在消融研究中,我们进一步评估了(1)NBSP 的两个主要组件:梯度掩码技术和经验回放技术,(2)表 4. 演员和评论家模块消融研究的结果。
| 循环顺序任务 | 模块 | 度量 | ||||
|---|---|---|---|---|---|---|
| ASR ↑ | FM ↓ | FT ↑ | ||||
| (window-open | 演员 | 0.76 ± 0.10 | 0.58 ± 0.19 | 0.97 ± 0.04 | ||
| → window-close) | 评论家 | 0.79 ± 0.05 | 0.48 ± 0.09 | 0.94 ± 0.05 | ||
| 两者 | 0.90 ± 0.04 | 0.18 ± 0.01 | 0.96 ± 0.02 | |||
| (drawer-open | 演员 | 0.79 ± 0.05 | 0.55 ± 0.15 | 0.99 ± 0.01 | ||
| → drawer-close) | 评论家 | 0.86 ± 0.02 | 0.31 ± 0.03 | 0.96 ± 0.02 | ||
| 两者 | 0.96 ± 0.02 | 0.07 ± 0.06 | 0.98 ± 0.01 | |||
| (button-press-topdown | 演员 | 0.81 ± 0.11 | 0.45 ± 0.28 | 0.95 ± 0.01 | ||
| → window-open) | 评论家 | 0.85 ± 0.16 | 0.35 ± 0.38 | 0.95 ± 0.03 | ||
| 两者 | 0.95 ± 0.05 | 0.08 ± 0.12 | 0.98 ± 0.01 |
神经元识别方法,以及(3)DRL 的两个关键模块:演员和评论家。此外,我们分析了 RL 技能神经元的比例如何影响 NBSP 的性能。
梯度掩码和经验回放。为了评估 NBSP 的两个主要组件的影响,我们设计了四种实验设置:(1)基准:直接训练而不使用任何附加技术。(2)仅掩码:仅使用梯度掩码技术进行训练。(3)仅回放:仅使用经验回放技术进行训练。(4)NBSP:同时使用这两种技术进行训练。
(button-press-topdown → window-open) 循环顺序任务的结果如表 [2.] (#page-6-0) 所示。从结果中,我们观察到以下几点:(1)基准设置显示出显著的稳定性损失,这由其高的 FM 值表示。这一结果突显了在没有特定机制保存任务知识的情况下维持稳定性的挑战。(2)仅掩码和仅回放设置在一定程度上缓解了稳定性损失。这确认了梯度掩码和经验回放技术在减轻遗忘和维持稳定性方面的单独贡献。(3)NBSP 中结合这两种技术产生了优越的性能,与仅使用一种相比有显著改进。这由显著降低的 FM 值(表明增强的稳定性)和高的 FWT 值(表明保持的可塑性)证明。这些发现表明,虽然每种技术独立地有助于提高稳定性和保持可塑性,但它们在 NBSP 中的协同作用对于在循环顺序学习场景中实现最佳性能至关重要。 不同任务设置的其他结果见附录 [C.6.] (#page-16-1)
神经元识别方法。为了评估所提出的目标导向神经元识别方法,我们将其与随机选择进行了比较。如表 [3] (#page-6-1) 所示,我们的目标导向方法在所有三个度量(ASR、FM 和 FWT)上始终优于随机选择。这一结果证实了我们的方法能够有效地识别对知识保留至关重要的神经元,确保在循环顺序任务学习中更好地保持稳定性和可塑性。相比之下,随机选择未能优先考虑关键神经元,导致整体表现较差。这些发现验证了在增强稳定性和可塑性平衡时,采用任务特定、目标导向的神经元识别的必要性。
演员和评论家。为了更深入地了解演员和评论家在 DRL 代理中的个体角色,我们将 NBSP 的表现与其仅应用于演员和评论家的表现进行了比较。结果如表 [4.] (#page-6-2) 所示。
结果表明,演员和评论家网络对于在稳定性和可塑性之间达到最佳平衡都是必不可少的。值得注意的是,评论家在平衡这种权衡方面更为关键模块,这与 [Ma et al.] (#page-9-18) (2024) 的见解一致,即评论家中的可塑性损失是阻碍 DRL 高效训练的主要瓶颈。我们通过剖析演员-评论家强化学习方法的内在训练机制进一步研究了这一现象,并得出以下关键观察:(1)演员的更新由评论家的反馈引导。因此,即使演员中的 RL 技能神经元被掩码,它们仍然受到评论家的影响,评论家可能逐渐适应新任务,从而牺牲保留先前知识的能力;(2)相反,将 NBSP 应用于评论家网络间接约束了演员;(3)评论家网络的更新过程是递归的,其目标网络通过指数移动平均进行更新,使其能够在整合新技能的同时保留先前任务的知识。因此,NBSP 在评论家上的表现优于在演员上的表现。这展示了演员和评论家在平衡稳定性和可塑性方面的不同角色,为该领域的未来研究提供了有价值的见解。
RL 技能神经元的比例。为了评估 RL 技能神经元比例对 NBSP 性能的影响,我们在 (button-press-topdown → window-open) 循环任务上进行了各种比例的实验。结果如图 [4.] (#page-7-1) 所示,揭示了一个有趣的趋势:随着 RL 技能神经元比例的增加,ASR 最初有所提高,但在达到某个阈值后开始下降。具体来说,当比例较小时,未识别出所有编码任务特定技能的神经元,导致未选择的神经元中存储的知识丢失。另一方面,当比例过大时,可能错误地将不编码技能的神经元选为 RL 技能神经元,这削弱了它们的学习能力,并使真正的 RL 技能神经元调整其激活以适应新任务,最终降低了稳定性。因此,确定 RL 技能神经元的最佳比例对于实现最佳性能至关重要。我们的实验表明,比例为 0.2 是平衡稳定性和可塑性的理想选择。
4.3. Atari 基准上的实验
我们进一步在 Atari 基准上评估 NBSP,以评估其泛化能力。与 Meta-World 的连续动作空间不同,Atari 游戏具有离散动作空间,并使用一集回报来评估每个游戏的性能。结果如表 [5.] (#page-7-0) 所示。与 Meta-World 基准一样,NBSP 在平衡稳定性和可塑性方面表现出色,在关键评估指标(包括 AR(平均回报)、FM 和 FWT)上优于其他基线。总之,NBSP 在不同基准上展现了出色的平衡稳定性和可塑性的泛化能力。
5. 结论
本工作解决了深度强化学习中的稳定性-可塑性困境这一基本问题。为解决此问题,我们通过识别对知识保留有显著贡献的神经元引入了 RL 技能神经元的概念,并在此基础上提出了神经元层面稳定性与可塑性平衡框架,通过在 RL 技能神经元上应用梯度掩码和经验回放技术。Meta-World 和 Atari 基准上的实验结果表明,NBSP 在管理稳定性-可塑性权衡方面显著优于现有方法。未来的研究可以探索 RL 技能神经元的应用,如模型蒸馏,并将 NBSP 扩展到其他学习范式,如监督学习。
影响声明
在深度强化学习中,稳定性-可塑性困境指的是在保留现有技能(稳定性)与获取新知识(可塑性)之间取得平衡的挑战。这一困境极大地阻碍了代理在顺序任务学习中的表现,对实际应用构成了障碍。在本工作中,我们发现代理网络中的某些神经元在塑造代理行为方面起着关键作用。利用这一见解,我们将负责编码关键任务相关技能的神经元定义为 RL 技能神经元,并提出了一种目标导向的方法来识别它们。为解决稳定性-可塑性困境,我们针对这些神经元引入了梯度掩码和经验回放技术。这些技术保留了从先前学习任务中获得的知识,同时允许微调以适应新任务。我们提出的方法 NBSP 在 DRL 中实现了优越的稳定性与可塑性平衡。本研究不存在伦理问题,也不会对社会造成负面影响。
参考文献
-
Abbas, Z., Zhao, R., Modayil, J., White, A., and Machado, M. C. Loss of plasticity in continual deep reinforcement learning. In Conference on Lifelong Learning Agents, pp. 620–636. PMLR, 2023.
-
- Ahn, H., Hyeon, J., Oh, Y., Hwang, B., and Moon, T. Reset & distill: A recipe for overcoming negative transfer in continual reinforcement learning. arXiv preprint arXiv:2403.05066, 2024.
-
- Anand, N. and Precup, D. Prediction and control in continual reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
-
- Andrychowicz, O. M., Baker, B., Chociej, M., Jozefowicz, R., McGrew, B., Pachocki, J., Petron, A., Plappert, M., Powell, G., Ray, A., et al. Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1):3–20, 2020.
-
- Atkinson, C., McCane, B., Szymanski, L., and Robins, A. Pseudo-rehearsal: Achieving deep reinforcement learning
without catastrophic forgetting. Neurocomputing, 428: 291–307, 2021a.
- Atkinson, C., McCane, B., Szymanski, L., and Robins, A. Pseudo-rehearsal: Achieving deep reinforcement learning
-
Atkinson, C., McCane, B., Szymanski, L., and Robins, A. Pseudo-rehearsal: Achieving deep reinforcement learning without catastrophic forgetting. Neurocomputing, pp. 291–307, Mar 2021b. doi: 10.1016/j.neucom.2020. 11.050. URL http://dx.doi.org/10.1016/j. [neucom.2020.11.050- Bai, F., Zhang, H., Tao, T., Wu, Z., Wang, Y., and Xu, B. Picor: Multi-task deep reinforcement learning with policy correction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 6728–6736, 2023.
-
- Bau, A., Belinkov, Y., Sajjad, H., Durrani, N., Dalvi, F., and Glass, J. Identifying and controlling important neurons in neural machine translation. In International Conference on Learning Representations, 2018.
-
- Bau, D., Zhu, J.-Y., Strobelt, H., Lapedriza, A., Zhou, B., and Torralba, A. Understanding the role of individual units in a deep neural network. Proceedings of the National Academy of Sciences, 117(48):30071–30078, 2020.
-
- Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
-
- Carpenter, G. A. and Grossberg, S. A massively parallel architecture for a self-organizing neural pattern recognition machine. Computer vision, graphics, and image processing, 37(1):54–115, 1987.
-
- Carpenter, G. A. and Grossberg, S. Art 2: Self-organization of stable category recognition codes for analog input patterns. In SPIE Proceedings,Intelligent Robots and Computer Vision VI, Feb 1988. doi: 10.1117/12.942747. URL http://dx.doi.org/10.1117/12.942747.
-
- Chaudhry, A., Dokania, P. K., Ajanthan, T., and Torr, P. H. Riemannian walk for incremental learning: Understanding forgetting and intransigence. In Proceedings of the European conference on computer vision (ECCV), pp. 532–547, 2018a.
-
- Chaudhry, A., Ranzato, M., Rohrbach, M., and Elhoseiny, M. Efficient lifelong learning with a-gem. In International Conference on Learning Representations, 2018b.
-
- Chen, J., Wang, X., Yao, Z., Bai, Y., Hou, L., and Li, J. Finding safety neurons in large language models. arXiv preprint arXiv:2406.14144, 2024.
-
- Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. Knowledge neurons in pretrained transformers. In
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jan 2022. doi: 10.18653/v1/2022.acl-long. 581. URL http://dx.doi.org/10.18653/v1/ [2022.acl-long.581
- Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. Knowledge neurons in pretrained transformers. In
-
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. Loss of plasticity in deep continual learning. Nature, 632(8026):768–774, 2024.
-
- Dravid, A., Gandelsman, Y., Efros, A. A., and Shocher, A. Rosetta neurons: Mining the common units in a model zoo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1934–1943, 2023.
-
- eMermillod, M., eBugaiska, A., and eBONIN, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Frontiers in Psychology,Frontiers in Psychology, Aug 2013.
-
- Foundation, F. Atari environments in gymnasium. https: [//gymnasium.farama.org/environments/- Goodfellow, I. J., Mirza, M., Courville, A., and Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. stat, 1050:4, 2015.
-
- Gurnee, W. and Tegmark, M. Language models represent space and time. In The Twelfth International Conference on Learning Representations, Oct 2023.
-
- Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pp. 1861–1870. PMLR, 2018.
-
- Huang, S., Dossa, R. F. J., Ye, C., Braga, J., Chakraborty, D., Mehta, K., and AraA˜ sjo, J. G. Cleanrl: High-quality ˇ single-file implementations of deep reinforcement learning algorithms. Journal of Machine Learning Research, 23(274):1–18, 2022.
-
- Kim, S., Noci, L., Orvieto, A., and Hofmann, T. Achieving a better stability-plasticity trade-off via auxiliary networks in continual learning. CVPR2023, Mar 2023.
-
- Kiran, B. R., Sobh, I., Talpaert, V., Mannion, P., Al Sallab, A. A., Yogamani, S., and Perez, P. Deep reinforce- ´ ment learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 23 (6):4909–4926, 2021.
-
- Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., and Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, pp. 3521–3526, Mar 2017. doi: 10.1073/pnas.1611835114. URL http: [//dx.doi.org/10.1073/pnas.1611835114- Kumar, S., Marklund, H., and Van Roy, B. Maintaining plasticity in continual learning via regenerative regularization. 2023.
-
- Liu, J., Obando-Ceron, J., Courville, A., and Pan, L. Neuroplastic expansion in deep reinforcement learning. arXiv preprint arXiv:2410.07994, 2024.
-
- Lopez-Paz, D. and Ranzato, M. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017.
-
- Ma, G., Li, L., Zhang, S., Liu, Z., Wang, Z., Chen, Y., Shen, L., Wang, X., and Tao, D. Revisiting plasticity in visual reinforcement learning: Data, modules and training stages. In The Twelfth International Conference on Learning Representations, 2024.
-
- Mallya, A. and Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 7765–7773, 2018.
-
- McCloskey, M. and Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pp. 109–165. Elsevier, 1989.
-
- Mendez, J. A., van Seijen, H., and Eaton, E. Modular lifelong reinforcement learning via neural composition. arXiv preprint arXiv:2207.00429, 2022.
-
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
-
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning. nature, 518(7540): 529–533, 2015.
-
- Molchanov, P., Tyree, S., Karras, T., Aila, T., and Kautz, J. Pruning convolutional neural networks for resource efficient inference. In International Conference on Learning Representations, 2022.
-
- Nikishin, E., Schwarzer, M., D’Oro, P., Bacon, P.-L., and Courville, A. The primacy bias in deep reinforcement learning. In International conference on machine learning, pp. 16828–16847. PMLR, 2022a.
-
- Nikishin, E., Schwarzer, M., D’Oro, P., Bacon, P.-L., and Courville, A. The primacy bias in deep reinforcement learning. In International conference on machine learning, pp. 16828–16847. PMLR, 2022b.
-
- Nikishin, E., Oh, J., Ostrovski, G., Lyle, C., Pascanu, R., Dabney, W., and Barreto, A. Deep reinforcement learning with plasticity injection. Advances in Neural Information Processing Systems, 36, 2024.
-
- Paik, I., Oh, S., Kwak, T.-Y., and Kim, I. Overcoming catastrophic forgetting by neuron-level plasticity control. AAAI2020, Jul 2019.
-
- Sajjad, H., Durrani, N., and Dalvi, F. Neuron-level interpretation of deep nlp models: A survey. Transactions of the Association for Computational Linguistics, 10:1285– 1303, 2022.
-
- Sokar, G., Agarwal, R., Castro, P. S., and Evci, U. The dormant neuron phenomenon in deep reinforcement learning. In International Conference on Machine Learning, pp. 32145–32168. PMLR, 2023.
-
- Sutton, R. S. Reinforcement learning: An introduction. A Bradford Book, 2018.
-
- Tang, T., Luo, W., Huang, H., Zhang, D., Wang, X., Zhao, X., Wei, F., and Wen, J.-R. Language-specific neurons: The key to multilingual capabilities in large language models. arXiv preprint arXiv:2402.16438, 2024.
-
- Wang, L., Zhang, X., Su, H., and Zhu, J. A comprehensive survey of continual learning: theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
-
- Wang, X., Wen, K., Zhang, Z., Hou, L., Liu, Z., and Li, J. Finding skill neurons in pre-trained transformer-based language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11132–11152, 2022.
-
- Wolczyk, M., Zajac, M., Pascanu, R., Kucinski, ´ Ł., and Miłos, P. Disentangling transfer in continual reinforce- ´ ment learning. Advances in Neural Information Processing Systems, 35:6304–6317, 2022.
-
- Xu, H., Zhan, R., Wong, D. F., and Chao, L. S. Let’s focus on neuron: Neuron-level supervised fine-tuning for large language model. arXiv preprint arXiv:2403.11621, 2024.
-
- Yang, R., Xu, H., Wu, Y., and Wang, X. Multi-task reinforcement learning with soft modularization. Advances in Neural Information Processing Systems, 33:4767–4777, 2020.
-
- Yang, Y., Zhou, T., Jiang, J., Long, G., and Shi, Y. Continual task allocation in meta-policy network via sparse prompting. In International Conference on Machine Learning, pp. 39623–39638. PMLR, 2023年。
A. 相关工作
稳定性和可塑性之间的平衡。在深度强化学习(DRL)中,代理面临一个根本性的挑战:稳定性和可塑性困境,这一问题最早由Carpenter & Grossberg [(1988)
基于回放的方法被广泛用于通过重用过去分布的经验来增强稳定性。例如,[Chaudhry et al.] (#page-8-9) (2018b) 引入了A-GEM,它结合情景记忆确保在学习新任务时先前任务的平均损失不会增加。类似地,[Wolczyk et al.] (#page-10-3) [(2022)
保持神经元表达能力是保留可塑性的关键。[Nikishin et al.] (#page-10-4) (2022b) 提出了一种机制,定期重置代理网络的一部分以对抗可塑性损失。同样,[Nikishin et al.] (#page-10-5) [(2024)
基于模块化的方法通过解耦任务特定知识和通用知识,在平衡稳定性和可塑性方面显示出潜力。例如,[Anand & Precup] (#page-8-5) (2024) 将价值函数分解为捕捉持久知识的永久价值函数和促进快速适应的瞬态价值函数。[Yang et al.] (#page-10-6) [(2020)
神经元层面研究 最近的研究表明,并非所有神经元在不同情境下都保持活跃,这种神经元稀疏性通常与任务特定性能呈正相关(Xu et al., [2024)
尽管取得了这些成就,深度强化学习中的技能神经元探索仍然有限。现有的神经元层面方法主要集中在任务特定子网络的选择上。例如,CoTASP通过学习分层词典和元策略生成稀疏提示并提取子网络作为任务特定策略(Yang et al., [2023)
B. 预备知识
B.1. 马尔可夫决策过程 (MDP)
马尔可夫决策过程(MDP)是一种用来描述从动作中学习以达成目标的问题的框架。几乎所有强化学习问题都可以被刻画为马尔可夫决策过程。每个MDP由一组 < S, A, P, R, γ > 定义,其中S和A分别代表状态空间和动作空间。MDP的转移动态由函数 P : S × A × S → [0, 1] 定义,表示从给定状态s执行动作a转移到状态s ′ 的概率。奖励函数由 R : S × A × S → R 表示,γ ∈ (0, 1) 是折扣因子。在每个时间步t,代理观察环境的状态,记为st,并根据策略π(a|s)选择动作at。一时间步后,代理收到数值奖励rt+1并转移到新状态st+1。在最简单的情况下,当代理-环境交互自然分为子序列时,回报是奖励的总和,我们称之为剧集(Sutton, [2018)
B.2. 软演员-评论家 (SAC)
软演员-评论家(SAC)是一种离策略演员-评论家深度强化学习算法,利用最大熵来促进探索。本工作采用SAC训练一种有效平衡稳定性和可塑性的策略,因其样本效率高、性能优异且稳定性强而被选中。在此框架中,演员旨在最大化预期奖励和策略熵。演员的参数ϕ通过最小化以下损失函数进行优化:
J π ( ϕ ) = E s t ∼ D , a t ∼ π ϕ [ α log π ϕ ( a t ∣ s t ) − Q θ ( s t , a t ) ] , J_{\pi}(\phi) = E_{s_t \sim D, a_t \sim \pi_\phi} [\alpha \log \pi_\phi(a_t | s_t) - Q_\theta(s_t, a_t)], Jπ(ϕ)=Est∼D,at∼πϕ[αlogπϕ(at∣st)−Qθ(st,at)],
其中D是重放缓冲区,α是控制探索与开发权衡的温度参数,θ表示评论家网络的参数,πϕ表示演员ϕ学习的策略,Qθ表示评论家θ估计的Q值。评论家网络通过最小化平方残差误差进行训练:
J Q ( θ ) = E ( s t , a t , s t + 1 ) ∼ D [ 1 2 ( Q θ ( s t , a t ) − r t − γ V ^ ( s t + 1 ) ] , J_Q(\theta) = E_{(s_t, a_t, s_{t+1}) \sim D}[\frac{1}{2}(Q_\theta(s_t, a_t) - r_t - \gamma \hat{V}(s_{t+1})], JQ(θ)=E(st,at,st+1)∼D[21(Qθ(st,at)−rt−γV^(st+1)],
V ^ ( s t ) = E a t ∼ π ϕ [ Q θ ( s t , a t ) − α log π ϕ ( a t ∣ s t ) ] , \hat{V}(s_t) = E_{a_t \sim \pi_\phi}[Q_\theta(s_t, a_t) - \alpha \log \pi_\phi(a_t|s_t)], V^(st)=Eat∼πϕ[Qθ(st,at)−αlogπϕ(at∣st)],
其中γ表示折扣因子。
B.3. 神经元
在神经网络中,各种组件如块和层扮演不同的角色。这里,我们将单个输出维度定义为一层中的神经元。例如,在全连接层中,每个输出维度对应一个神经元。同样,在卷积层中,每个输出通道代表一个神经元。此外,按照[Sajjad et al.] (#page-10-14) (2022)使用的术语,我们将封装单一概念的神经元分类为聚焦神经元,而共同代表一个概念的一组神经元则称为群神经元。
C. 实验
C.1. 基线
EWC: 弹性权重巩固(EWC) (Kirkpatrick et al., [2017)
NPC: 神经元级别可塑性控制(NPC) (Paik et al., [2019)
ANCL: 辅助网络连续学习(ANCL)是一种创新方法,通过引入辅助网络在一个主要强调稳定性的模型中增强可塑性。具体来说,此框架引入了一个有效的调节器,可以很好地平衡可塑性和稳定性,在任务增量和类别增量学习场景中优于强大的基线。
CoTASP: 通过稀疏提示进行持续任务分配(CoTASP) (Yang et al., [2023)
CRelu: 拼接ReLU(CReLUs) (Abbas et al., [2023)
CBP: 持续反向传播(CBP) (Dohare et al., [2024)
PI: 可塑性注入(PI) (Nikishin et al., [2024)
C.2. 基准
Meta-World. Meta-World是一个开源基准,用于元强化学习和多任务学习,包含50个不同的机器人操作任务(Yu et al., [2020)
所有任务均由模拟的Sawyer机器人执行,动作空间定义为2元组:末端执行器3D位置的变化,随后是对夹爪手指施加的归一化扭矩。
观测空间的维度始终为39,尽管不同维度对应于每个任务的不同方面。通常,观测空间表示为6元组,包括末端执行器的3D笛卡尔位置、夹爪开口程度的归一化测量值、第一个物体的3D位置及其四元数、第二个物体的3D位置及其四元数、环境内的所有先前测量值以及目标的3D位置。
所有任务的奖励函数都是结构化的且多成分的,有助于每个任务组件的有效策略学习。通过这种设计,奖励函数在任务间保持相似的幅度,通常在0到10之间。我们在实验中使用的六个任务的描述如下,这些任务的外观如图[5.] (#page-13-1)所示。
- 抽屉打开:打开抽屉,抽屉位置随机。
-
- 抽屉关闭:推动并关闭抽屉,抽屉位置随机。
-
- 窗户打开:推动并打开窗户,窗户位置随机。
-
- 窗户关闭:推动并关闭窗户,窗户位置随机。
-
- 开门:打开带旋转关节的门。门的位置随机。
-
- 顶部按钮按下:从顶部按下按钮。按钮位置随机。

- 顶部按钮按下:从顶部按下按钮。按钮位置随机。





图5. 我们实验中使用的Meta-World基准任务。
Atari. Atari环境通过Stella仿真器使用Arcade Learning Environment (ALE) (Bellemare et al., [2013)
每个环境使用完整动作空间的一个子集,其中包括诸如NOOP、FIRE、UP、RIGHT、LEFT、DOWN、UPRIGHT、UPLEFT、DOWNRIGHT、DOWNLEFT、UPFIRE、RIGHTFIRE、LEFTFIRE、DOWNFIRE、UPRIGHT-FIRE、UPLEFTFIRE、DOWNRIGHTFIRE和DOWNLEFTFIRE等动作。默认情况下,大多数环境仅使用这些动作的一个较小子集,排除那些对游戏玩法没有影响的动作。
Atari环境中的观察是显示给人类玩家的RGB图像,obs type = “rgb”,对应于定义为Box(0, 255,(210, 160, 3), np.uint8)的观察空间。
具体奖励动态因环境而异,通常在游戏手册中有详细说明。
我们在实验中使用的四个游戏的描述如下(Foundation, [2024)
- 保龄球:目标是在10帧游戏中尽可能多地得分。每帧最多允许两次尝试。第一次尝试就击倒所有球瓶称为“strike”,第二次尝试击倒所有球瓶称为“spare”。两次尝试未能击倒所有球瓶则称为“open”帧。
-
- 乒乓球:你控制右侧球拍并与计算机控制的左侧球拍竞争。目标是将球远离你的球门并射入对手的球门。
-
- 银行抢劫:你扮演一名银行劫匪,试图抢夺尽可能多的银行,同时在迷宫般的城市中避免警察。你可以使用炸药摧毁警车并通过进入新城市来补充汽油。如果汽油耗尽、被警察抓住或碾过自己的炸药,生命值会减少。
-
- 外星人:你被困在一个迷宫般的宇宙飞船中,里面有三个外星人。你的目标是摧毁它们散布在整个船上的卵,同时避开外星人。你有一个火焰喷射器来抵御它们,并且偶尔可以收集一个临时赋予你杀死外星人能力的强化道具(脉冲星)。
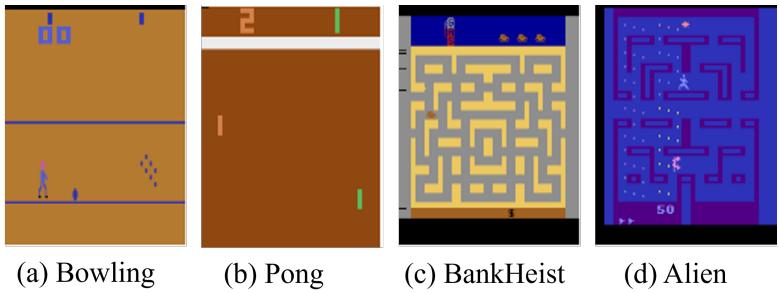
- 外星人:你被困在一个迷宫般的宇宙飞船中,里面有三个外星人。你的目标是摧毁它们散布在整个船上的卵,同时避开外星人。你有一个火焰喷射器来抵御它们,并且偶尔可以收集一个临时赋予你杀死外星人能力的强化道具(脉冲星)。
图6. 我们实验中使用的Atari基准游戏。
C.3. 实验设置
对于所有实验,我们使用CleanRL (Huang et al., [2022)
关于网络架构,我们在相同基准的所有任务中使用相同的演员和评论家网络以确保一致性。对于Meta-World基准,我们使用一个包含四个全连接层的神经网络,其隐藏大小为[768, 768, 768]。对于Atari基准,我们使用一个包含三个卷积层的卷积神经网络(CNN),其通道数分别为32、64和64,随后是三个全连接层,其隐藏大小为[768, 768]。
为了减少随机性并增强结果的可靠性,我们使用三个随机种子训练每个代理。Meta-World和Atari基准中应用的SAC算法的额外超参数详见表[6.] (#page-15-1)。
| 参数 | Meta-World的值 | Atari的值 |
|---|---|---|
| 初始收集步骤 | 10000 | 20000 |
| 折扣因子 | 0.99 | 0.99 |
| 训练环境步骤 | 106 | 1.5 × 106 , 3 × 106 |
| 测试环境步骤 | 105 | 105 |
| 回放缓冲区大小 | 106 | 2 × 105 |
| 每环境步骤更新次数(回放比率) | 2 | 4 |
| 目标网络更新周期 | 1 | 8000 |
| 目标平滑系数 | 0.005 | 1 |
| 优化器 | Adam | Adam |
| 策略学习率 | 3 × 10−4 | 10−4 |
| Q值学习率 | 10−3 | 10−4 |
| 小批量大小 | 256 | 64 |
| Alpha | 0.2 | 0.2 |
| 自动调整 | True | True |
| 成功率平均环境步骤 | 10 | - |
| 稳定阈值完成训练 | 0.9 | - |
| 回放缓冲间隔 | 10 | 10 |
| 无操作最大值 | - | 30 |
| 目标熵比例 | - | 0.89 |
| 存储经验大小 | 105 | 105 |
表6. 我们的实验中SAC的超参数。
C.4. 度量标准
对于Meta-World基准,平均成功率在20个剧集中计算。对于Atari基准,成功率被回报所取代。我们对每个游戏的回报进行归一化以获得跨游戏的汇总统计数据,如下所示:
R = r a g e n t − r r a n d o m r h u m a n − r r a n d o m , (11) R = \frac{r_{agent} - r_{random}}{r_{human} - r_{random}},\tag{11} R=rhuman−rrandomragent−rrandom,(11)
其中ragent表示在10^5步中评估的平均回报,随机分数rrandom和人类分数rhuman与[Mnih et al.] (#page-9-20) (2015)使用的分数一致,详见表[7.] (#page-15-2)。
| 游戏 | rrandom | rhuman |
|---|---|---|
| 保龄球 | 23.1 | 154.8 |
| 乒乓球 | -20.7 | 9.3 |
| 银行抢劫 | 14.2 | 734.4 |
| 外星人 | 227.5 | 6875 |
表7. Atari游戏的归一化分数。
对于Atari基准任务,整体性能通过平均回报(AR)进行评估,这类似于Meta-World基准中的ASR。它计算如下:
A R = 1 k ∑ i = 1 k 1 i ∑ i ≥ j R i , j , (12) AR = \frac{1}{k} \sum_{i=1}^{k} \frac{1}{i} \sum_{i \ge j} R_{i,j},\tag{12} AR=k1i=1∑ki1i≥j∑Ri,j,(12)
其中Ri,j表示在完成第i个任务学习后对第j个任务的平均回报(i ≥ j),k表示任务数量。更高的AR表示在平衡稳定性和可塑性方面的更好表现。
C.5. Meta-world基准上的结果
其他四任务循环任务的训练过程如图7,所示,双任务循环任务的结果如图[8,

图7. NBSP在(button-press-topdown → window-close → door-open → drawer-close)循环任务上的训练过程。
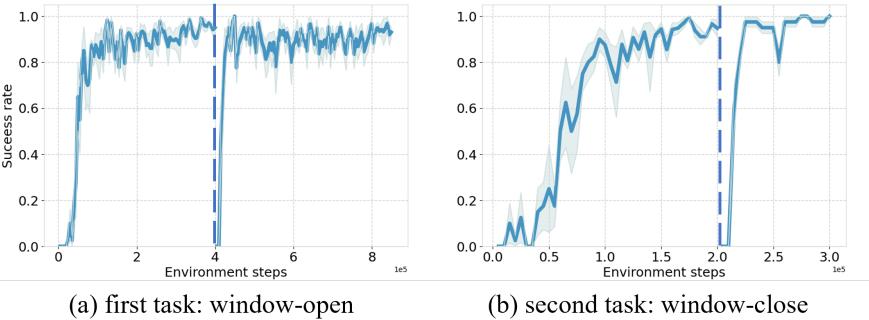
图8. NBSP在(window-open → window-close)循环任务上的训练过程。
C.6. 消融研究
梯度掩码和经验回放技术这两个关键组件的消融研究结果如表8所示,针对(window-open → window-close)循环任务,以及表[9
表8. (window-open → window-close)循环任务上梯度掩码和经验回放技术的消融研究结果。
| 组件 | 度量 | |||||||
|---|---|---|---|---|---|---|---|---|
| 梯度 掩码 | 经验 回放 | ASR | FT | |||||
| × | × | 0.63 ± 0.02 | 0.91 ± 0.10 | 0.97 ± 0.02 | ||||
| × | ✓ | 0.81 ± 0.08 | 0.41 ± 0.13 | 0.96 ± 0.01 | ||||
| ✓ | × | 0.78 ± 0.11 | 0.54 ± 0.26 | 0.98 ± 0.01 | ||||
| ✓ | ✓ | 0.90 ± 0.04 | 0.18 ± 0.01 | 0.96 ± 0.02 |
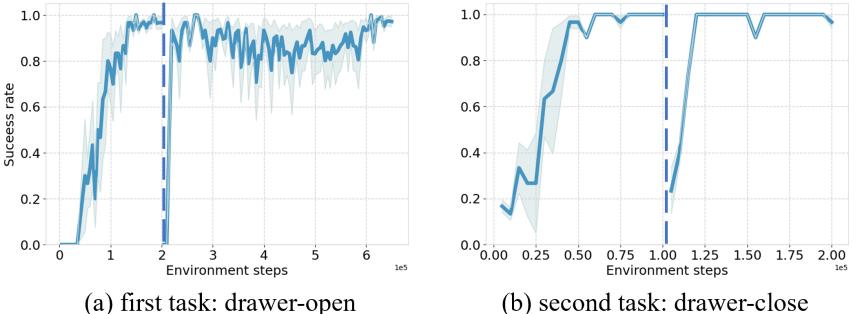
图9. NBSP在(drawer-open → drawer-close)循环任务上的训练过程。
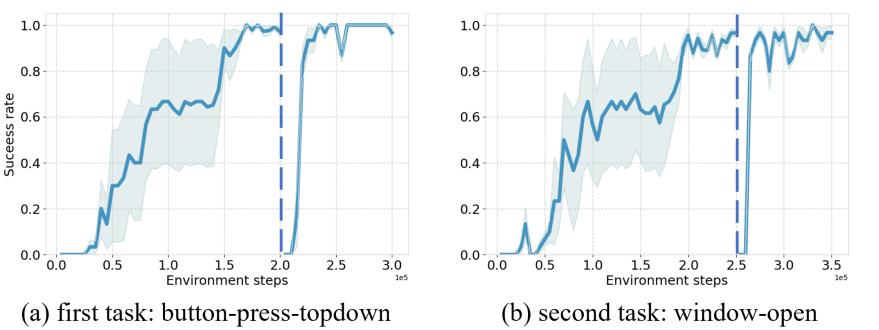
图10. NBSP在(button-press-topdown → window-open)循环任务上的训练过程。
表9. (drawer-open → drawer-close)循环任务上梯度掩码和经验回放技术的消融研究结果。
| 算法 1 识别RL技能神经元的过程 | |||||
|---|---|---|---|---|---|
1: 对每个步骤 t 进行循环
2: 通过模型前向计算激活 a(t) 和 GPM q(t)
- 3: 在步骤中累积 a(t) 和 q(t)
-
- 4: 结束 for 循环
-
- 5: 使用公式 1 和公式 [2- 6: 对每个步骤 t 进行循环
-
- 7: 通过模型前向传递计算激活 a(t) 和 GPM q(t)
-
- 8: 将 a(t) 和 q(t) 与其各自的标准 a 和 q 进行比较,并记录结果
-
- 9: 结束 for 循环
-
- 10: 使用公式 3 计算正准确性 Acc
-
- 11: 使用公式 4 推导每个神经元的分数 Score
-
- 12: 根据分数对神经元进行排名,并选择表现最好的神经元作为RL技能神经元 {NRLskill}
D. 算法
目标导向方法寻找RL技能神经元的伪代码在算法 [1.] (#page-18-1) 中给出,而带有NBSP的SAC的伪代码在算法 [2.] (#page-19-0) 中给出。与标准SAC的关键差异以蓝色突出显示。除了额外的输入外,主要修改包括采样过程和网络更新过程。
E. 局限性和未来工作
局限性。虽然提出的NBSP方法在DRL中有效平衡了稳定性和可塑性,但它确实存在一个显著的局限性。具体而言,RL技能神经元的数量必须根据学习任务的复杂性手动确定和调整,因为没有自动选择机制。
未来工作。本工作中引入的神经元分析提供了一种识别RL技能神经元的新方法,显著增强了DRL中稳定性和可塑性之间的平衡。RL技能神经元的识别为未来的研发和应用开辟了几条有希望的方向,例如:(1) 模型蒸馏:通过关注RL技能神经元,可以通过修剪较少相关的神经元来蒸馏模型,从而得到性能下降最小的更高效和紧凑的模型。(2) 偏差控制和模型操控:RL技能神经元可以通过选择性调整其激活来控制偏差和修改模型行为。这种方法在需要特定输出或行为的场景中特别有价值。
关于NBSP方法,其适用潜力超越了DRL。它还可以适应其他学习范式,如监督学习和无监督学习,以解决类似的稳定性和可塑性挑战。在未来的工作中,我们计划探索这些扩展并在各个领域验证其有效性。
算法2 应用于SAC的神经元层面稳定性与可塑性平衡(NBSP)
初始化策略参数θ,Q函数参数ϕ1, ϕ2和目标Q函数参数ϕ ′ 1 , ϕ
初始化空的重放缓冲区D 初始化重放缓冲间隔k
输入:重放缓冲区Dpre,策略掩码maskθ和Q函数参数掩码maskϕ1 , maskϕ2
′ 2
-
1: 对每个任务进行循环
-
- 2: 对每次迭代进行循环
-
- 3: 对每个环境步骤进行循环
-
- 4: 采样动作 at ∼ πθ(at|st)
5: 执行动作at并观察奖励rt和下一个状态st+1 6: 将(st, at, rt, st+1)存储在重放缓冲区D中
- 4: 采样动作 at ∼ πθ(at|st)
-
7: 结束 for 循环
-
- 8: 对每个梯度步骤进行循环
9: if step ≡ 0 ( m o d k ) ( t h e n 从 D pre 采样一批转换 ( s i , a i , r i , s i + 1 ) . \text{9:} \qquad \text{if } \text{step} \equiv 0 \pmod{\mathbf{k}} \text{ (} \mathbf{then} \text{ 从 } \mathcal{D}_{\text{pre}} \text{ 采样一批转换 } (\mathbf{s}_{\mathbf{i}}, \mathbf{a}_{\mathbf{i}}, \mathbf{r}_{\mathbf{i}}, \mathbf{s}_{\mathbf{i}+1}). 9:if step≡0(modk) (then 从 Dpre 采样一批转换 (si,ai,ri,si+1).
- 8: 对每个梯度步骤进行循环
-
10: 否则 从D采样一批转换(si , ai , ri , si+1)
-
- 11: 结束 if
-
- 12: 计算目标值:
y i = r i + γ ( min j = 1 , 2 Q ϕ j ′ ( s i + 1 , a ~ i + 1 ) − α log π θ ( a ~ i + 1 ∣ s i + 1 ) ) , w h e r e a ~ i + 1 ∼ π θ ( ⋅ ∣ s i + 1 ) y_i = r_i + \gamma \left( \min_{j=1,2} Q_{\phi_j'}(s_{i+1}, \tilde{a}_{i+1}) - \alpha \log \pi_\theta(\tilde{a}_{i+1}|s_{i+1}) \right), where \, \tilde{a}_{i+1} \sim \pi_\theta(\cdot|s_{i+1}) yi=ri+γ(j=1,2minQϕj′(si+1,a~i+1)−αlogπθ(a~i+1∣si+1)),wherea~i+1∼πθ(⋅∣si+1)
- 12: 计算目标值:
13: 使用掩码进行一步梯度下降更新Q函数:
ϕ j ← ϕ j − λ Q mask ϕ j ∇ ϕ j 1 N ∑ i ( Q ϕ j ( s i , a i ) − y i ) 2 for j = 1 , 2 , 3 \phi_j \leftarrow \phi_j - \lambda_Q \text{mask}_{\phi_j} \nabla_{\phi_j} \frac{1}{N} \sum_i \left( Q_{\phi_j}(s_i, a_i) - y_i \right)^2 \quad \text{for } j = 1, 2, 3 ϕj←ϕj−λQmaskϕj∇ϕjN1i∑(Qϕj(si,ai)−yi)2for j=1,2,3
14: 使用掩码进行一步梯度上升更新策略:
θ ← θ + λ π mask θ ∇ θ 1 N ∑ i ( α log π θ ( a i ∣ s i ) − min j = 1 , 2 Q ϕ j ( s i , a i ) ) , \theta \gets \theta + \lambda_{\pi} \text{mask}_{\theta} \nabla_{\theta} \frac{1}{N} \sum_{i} \left( \alpha \log \pi_{\theta}(a_{i}|s_{i}) - \min_{j=1,2} Q_{\phi_{j}}(s_{i}, a_{i}) \right), θ←θ+λπmaskθ∇θN1i∑(αlogπθ(ai∣si)−j=1,2minQϕj(si,ai)),
15: 使用一步梯度下降更新温度α:
α ← α − λ α ∇ α 1 N ∑ i ( − α log π θ ( a i ∣ s i ) − α H ˉ ) , \alpha \gets \alpha - \lambda_{\alpha} \nabla_{\alpha} \frac{1}{N} \sum_{i} \left( -\alpha \log \pi_{\theta}(a_{i}|s_{i}) - \alpha \bar{\mathcal{H}} \right), α←α−λα∇αN1i∑(−αlogπθ(ai∣si)−αHˉ),
16: 更新目标Q函数参数:
ϕ j ′ ← τ ϕ j + ( 1 − τ ) ϕ j ′ for j = 1 , 2 \phi_j' \leftarrow \tau \phi_j + (1 - \tau) \phi_j' \quad \text{for } j = 1, 2 ϕj′←τϕj+(1−τ)ϕj′for j=1,2
17: 结束 for 循环
18: 结束 for 循环
19: 根据算法[1] (#page-18-1)选择RL技能神经元 {NRL skill}
- 20: 使用公式[6] (#page-4-0)更新maskϕ1 ,maskϕ2和maskθ
-
- 21: 将D的一部分存储到Dpre
22: 结束 for 循环
- 21: 将D的一部分存储到Dpre
参考 Paper:https://arxiv.org/pdf/2504.08000


















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











